
本文为您介绍Flink批处理的一些基本原理和配置调优。
背景信息
作为支持流处理和批处理的统一计算框架,Flink能够同时处理两种不同的数据模式。尽管Flink在流处理和批处理模式下共享许多核心执行机制,但两种模式在作业执行机制、配置参数和性能调优方面存在一些关键差异。本文将专门针对Flink批处理作业,为您介绍其独特的执行机制、配置参数。通过深入理解这些差异,您将能够更加高效地对作业进行调优,以及排查和解决在使用Flink批处理作业中遇到的问题。
实时计算Flink版也对Flink批处理进行了专门的支持,提供了作业开发、作业运维、作业编排、资源队列管理、数据结果探查等能力,您可以通过Flink批处理快速入门快速地了解上手。
批处理作业和流作业的比较
在介绍Flink批处理作业的配置参数和调优方法之前,首先需要了解Flink批处理与流处理作业在执行机制上的差异。
执行模式
流处理作业:流处理模式专注于处理持续不断的无界数据流,其核心在于实现低延迟的数据处理。在这种模式下,数据会以流水线模式在节点间即时传递并被处理。因此,流处理作业所有节点的子任务会同时部署和执行。
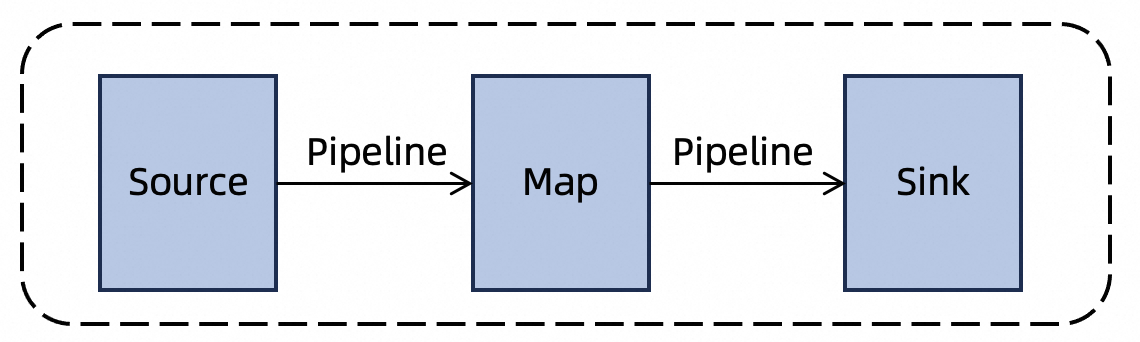
批处理作业:批处理模式专注于处理有界数据集,重点在于提供高吞吐量的数据处理。在这种执行模式下,作业通常由多个阶段组成,互不依赖的阶段可以并行执行,以提高资源利用率;对于存在数据依赖的阶段,下游任务需等待上游任务完成后才能启动。
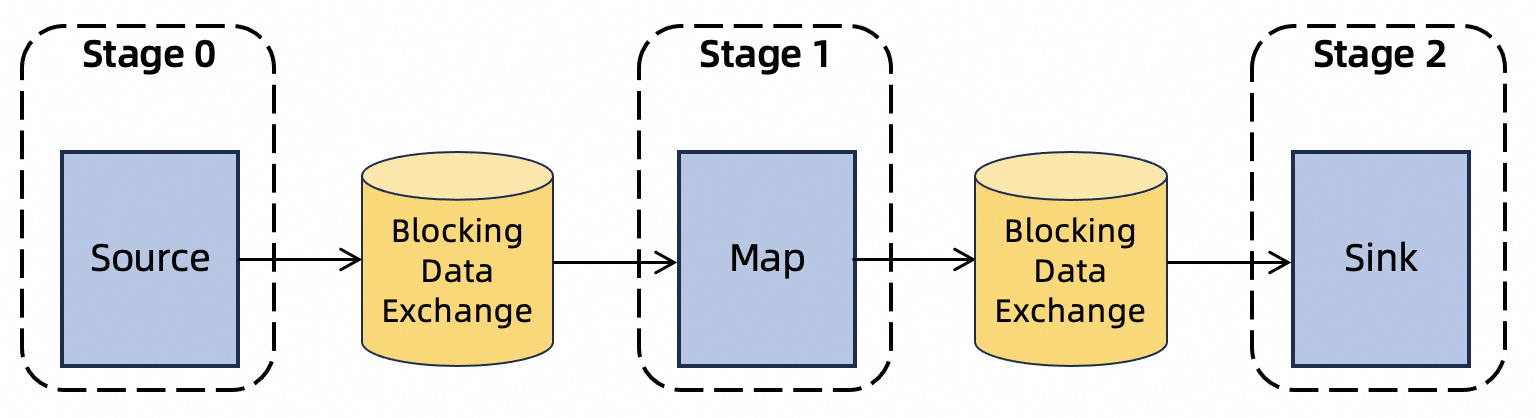
数据传输
流处理作业:为了实现低延迟,流处理作业的中间数据保留在内存中并直接通过网络进行传输,不会持久化。如果下游节点处理能力不足,则可能会导致上游节点遭遇反压。
批处理作业:批处理作业的中间结果会写入到外部存储系统中以供下游使用。默认情况下,这些结果文件存储在TaskManager的本地磁盘;如果使用远端Shuffle服务,则数据文件会存储在远端Shuffle服务中。
资源需求
流处理作业:流处理作业在启动时需要预先分配所有资源,以确保所有子任务能够同时部署并运行。
批处理作业:批处理作业在运行时不需要一次性获取所有资源。Flink可以分批调度输入数据已经就绪的任务,从而能够更高效地利用现有资源,即使在资源受限(甚至单Slot)的情况下也能顺利执行。
任务失败重启
流处理作业:流处理作业在遇到故障时可以从最近的检查点或保存点恢复,这样作业进度回退的程度较小。但因为中间结果不持久化,恢复时需要重新启动所有任务。
批处理作业:批处理作业的中间结果数据会落盘,因此当任务出错重启时,这些中间结果能够被再次利用,这意味着只需重启失败的任务以及它的下游任务即可,无需全局回溯。这样可以减少因故障而需要重新执行的任务数,提高恢复效率。不过由于批处理作业没有检查点机制,这些重启的任务需要从头开始运行。
关键配置参数及调优方式
本章节将为您介绍Flink批处理作业的关键配置。
资源配置
CPU和Memory
在作业的资源配置窗口中,您可以为作业设置单个JobManager和TaskManager的CPU和内存资源,以下是一些配置建议:
JobManager资源配置:建议为JobManager分配1个CPU核心和至少4 GiB的内存资源,以确保其顺利执行作业调度与管理。
TaskManager资源配置:建议根据Slot数量分配相应的资源。具体来说,建议为每个Slot配备1个CPU核心和4 GiB内存。如果一个TaskManager拥有n个Slot,那么总共应为其分配n个CPU核心和4n*GiB内存。
实时计算引擎中的批处理作业默认为每个TaskManager分配一个Slot。为了降低调度和管理TaskManager的开销,您可以考虑将每个TaskManager的Slot数量增加到2或4。
然而需要注意的是,每个TaskManager的可用磁盘空间是有限的,与其分配的CPU核心数是成比例的。具体来说,会给每个CPU核心配额20 GiB的磁盘空间。TaskManager最低磁盘空间为20 GiB,最大磁盘空间为200 GiB。
因此增加每个TaskManager上的Slot数量意味着更多的任务将在同一TaskManager节点上运行,这可能会加剧本地磁盘空间的紧张状况,甚至可能导致磁盘空间不足。如果磁盘空间不足,则会导致作业失败并重启。
对于规模较大或拓扑结构复杂的作业,JobManager和TaskManager可能需要更高规格的资源配置。在这些情况下,应根据作业的具体需求适当提高资源配置,以确保作业能够高效且稳定地运行。
此外,如果您在作业执行过程中遇到资源相关的问题,可以参考此文档进行故障诊断和解决:
Apache Flink Memory Troubleshooting。
为了保证作业稳定运行,每个JobManager和TaskManager至少需要配置0.5个CPU核心和2 GiB内存。
最大Slot个数
配置Flink作业允许分配的最大slot数量。由于Flink批处理作业在资源受限的情况下也可以运行,在资源受限的环境中,通过设置最大Slot数量,可以限制Flink批处理作业所使用的最大资源量。这有助于避免批处理作业占用过多资源,从而影响其他作业的运行。详情请参见批处理作业 TaskManager 数量可能超过并发度。
并行度配置
在作业的资源配置中,支持为作业设置全局并行度或自动推断并行度。
全局并行度:全局并行度决定作业中任务的最大并行执行数量。您可以直接在页面上填写作业的并行度,作业将使用该值作为全局默认并行度。
自动推断:配置自动推断后,Flink批处理作业将通过分析每个节点的消费总数据量和每个子任务期望处理的平均数据量来自动推导并行度,帮助您优化并行度配置。
此外,实时计算引擎VVR 8.0及以上版本提供了以下配置项(作业运行参数配置区域配置),使您能够对自动并行度推导进行更精细的调优:
在实时计算引擎VVR 8.0及以上版本中,Flink批处理作业默认开启自动推导并行度功能,并使用您配置的全局并行度作为自动推导并行度的上限。建议您使用实时计算引擎VVR 8.0及以上版本,以获得Flink批处理作业更优的性能表现。
配置项 | 说明 | 默认值 |
execution.batch.adaptive.auto-parallelism.enabled | 是否启用自动并行度推导。 | true |
execution.batch.adaptive.auto-parallelism.min-parallelism | 允许自动设置的并行度最小值。 | 1 |
execution.batch.adaptive.auto-parallelism.max-parallelism | 允许自动设置的并行度的最大值。如果未配置此参数,将采用全局并行度作为默认值。 | 128 |
execution.batch.adaptive.auto-parallelism.avg-data-volume-per-task | 期望每个任务平均处理的数据量大小。Flink将根据此配置和节点实际需要处理的数据量来动态决定节点并行度。 | 16MiB |
execution.batch.adaptive.auto-parallelism.default-source-parallelism | Source算子的默认并行度。目前Flink无法很好的感知到Source节点要读取的数据量,因此需要您自行配置其并行度。如果未配置,会取全局并行度。 | 1 |
常见问题
批处理作业 TaskManager 数量可能超过并发度
在批处理作业中,TaskManager(TM)是按需动态创建和释放的。例如:
作业并发度为 16,每个 TM 只分配 1 个 slot;
第一个算子启动时会创建 16 个 TM;
若部分子任务提前结束,对应的 TM 会在空闲一段时间后自动退出;
当后续算子开始执行时,系统会重新申请新的 TM,导致实际创建的 TM 总数(如 17、18、19…)超过原始并发度。
这不是异常,而是批处理作业弹性调度的正常行为。
如需严格限制 TM 总数,可配置最大Slot个数来限制TM的数量。
并行度与Slot数的区别
并行度:定义作业中每个算子可以同时运行的子任务数量,是处理能力的理论上限。
Slot:是 Flink 的资源单元,一个 Slot 可运行一个子任务。
流作业:默认开启 Slot 共享,启动时一次性申请等于全局并行度的 Slot 数,确保所有任务立即运行。
批处理作业:无需预占全部资源,实际并行数受当前可用 Slot 限制,即使全局并行度更高。
示例:一个并行度为 4 的流作业需要 4 个 Slot;批处理作业在集群只有 4 个空闲 Slot 时,最多只能运行 4 个子任务。其余任务等待 Slot 释放后再执行。
批处理作业运行卡住如何定位
您可以参见查看作业性能文档了解如何监控TaskManager的内存、CPU和线程使用情况。
内存问题排查:首先检查内存使用情况,判断是否存在内存不足导致的频繁垃圾回收(GC)。如果确认存在内存不足,应增加TaskManager的内存配置,以减少因频繁垃圾回收导致的性能问题。
CPU使用分析:检查是否存在个别线程占用了大量CPU资源,这可能是导致作业卡顿的原因。
线程栈跟踪:利用线程栈信息,分析当前节点运行的瓶颈所在。
报错No space left on device
当您在实时计算引擎中运行批处理作业时,如果遇到No space left on device的报错,这通常意味着TaskManager用于存储中间结果文件的本地磁盘空间已被耗尽。每个TaskManager的可用磁盘空间是有限的,与其分配的CPU核心数是成比例的。
解决建议:
减少每个TaskManager上的Slot数量,可以降低单个节点上的并行任务数,从而减少对本地磁盘空间的需求。
提高TaskManager的CPU核心数,从而提高TaskManager的磁盘空间大小。
相关文档
利用实时计算Flink版关键功能进行数据批处理快速入门,请参见Flink批处理快速入门。
运行参数配置方法,请参见如何配置自定义的作业运行参数?