
Kafka连接器支持读取Protobuf格式的数据。
Protobuf格式
Protobuf(Protocol Buffers)是由Google开发的一种高效、跨语言、结构化的数据序列化格式。相比于 JSON 和 XML,它具有以下显著优势:
体积小:序列化后的数据更紧凑,节省存储与网络传输资源。
速度快:序列化与反序列化效率高,适合高性能场景。
结构化定义:通过
.proto文件定义数据结构,接口清晰,易于维护。跨语言支持强 :支持主流编程语言,便于多系统间数据交互。
因此,Protobuf 被广泛应用于高频通信、微服务、实时计算等场景,是 Kafka 中推荐使用的高效数据格式之一。
使用限制
仅支持通过proto2语法定义的Protobuf文件生成的源代码。
仅支持Protocol Buffers 21.7及以下版本。
步骤一:编译Protobuf文件
创建名为order.proto的Protobuf文件。
syntax = "proto2"; // proto 的package名称 package com.aliyun; // java package名称,如果不指定会默认用proto的package option java_package = "com.aliyun"; // 是否编译成多个文件 option java_multiple_files = true; // java的封装类的类名 option java_outer_classname = "OrderProtoBuf"; message Order { optional int32 orderId = 1; optional string orderName= 2; optional double orderPrice = 3; optional int64 orderDate = 4; }使用Protocol Buffers工具生成源代码。
创建一个Maven空项目,将Protobuf文件放到resources目录下。
目录示例
KafkaProtobuf ‒ src -java -resources -order.proto ‒ pom.xmlpom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.aliyun</groupId> <artifactId>KafkaProtobuf</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.21.7</version> <!-- 版本号需与生成代码时使用的 Protobuf 版本一致 --> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.3.1</version> <!-- 请根据你的 Kafka 版本进行调整 --> </dependency> <dependency> <groupId>com.github.javafaker</groupId> <artifactId>javafaker</artifactId> <version>1.0.2</version> </dependency> </dependencies> <build> <finalName>KafkaProtobuf</finalName> <plugins> <!-- Java 编译器--> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.13.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <!-- 我们使用maven-shade 创建一个包含所有必须依赖的 fat jar --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.5.3</version> </plugin> </plugins> </build> </project>在java目录下会生成三个类,分别是Order具体类,OrderOrBuilder接口类和OrderProtobuf外部封装类。
# 终端进入项目目录下使用命令生成源代码 protoc --java_out=src/main/java src/main/resources/order.proto序列化和反序列化测试。
package com.aliyun; public class OrderTest { public static void main(String[] args) { // 创建一个Order对象并设置字段值 Order order = Order.newBuilder() .setOrderId(8513) .setOrderName("flink") .setOrderPrice(99.99) .setOrderDate(System.currentTimeMillis()) .build(); // 序列化为字节数组 byte[] serializedBytes = order.toByteArray(); System.out.println("序列化后字节长度:"+ serializedBytes.length); // 反序列化为新的Order对象 Order deserializedOrder; try { deserializedOrder = Order.parseFrom(serializedBytes); } catch (Exception e) { System.err.println("反序列化失败: " + e.getMessage()); return; } System.out.println("原始对象: \n" + order); // 验证反序列化后的对象与原始对象的字段值是否一致 if (order.getOrderId() == deserializedOrder.getOrderId() && order.getOrderName().equals(deserializedOrder.getOrderName()) && order.getOrderPrice() == deserializedOrder.getOrderPrice() && order.getOrderDate() == deserializedOrder.getOrderDate()) { System.out.println("序列化和反序列化测试通过!"); } else { System.out.println("序列化和反序列化测试失败!"); } } }
步骤二:构建测试数据,写入Kafka
本示例以云消息队列Kafka为操作环境。
下载SSL根证书。如果是SSL接入点,需下载该证书。
username和password为实例的用户名和密码。
如果实例未开启ACL,您可以在云消息队列 Kafka 版控制台的实例详情页面配置信息区域获取默认用户的用户名和密码。
如果实例已开启ACL,请确保要使用的SASL用户为PLAIN类型且已授权收发消息的权限,详情请参见使用ACL功能进行访问控制。
package com.aliyun;
import org.apache.kafka.clients.CommonClientConfigs;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.config.SaslConfigs;
import org.apache.kafka.common.config.SslConfigs;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.Future;
import com.github.javafaker.Faker; // 引入Faker库生成随机测试数据集
public class ProtoBufToKafkaTest {
public static void main(String[] args) {
Properties props = new Properties();
// 设置接入点,请通过Kafka控制台获取对应Topic的接入点
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "<bootstrap_servers>");
// 接入协议,使用SASL_SSL协议接入。
props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_SSL");
// 设置SSL根证书的路径(绝对路径),该文件不能被打包到Jar当中
props.put(SslConfigs.SSL_TRUSTSTORE_LOCATION_CONFIG, "../only.4096.client.truststore.jks");
// 根证书store的密码,保持不变。
props.put(SslConfigs.SSL_TRUSTSTORE_PASSWORD_CONFIG, "KafkaOnsClient");
// SASL鉴权方式,保持不变。
props.put(SaslConfigs.SASL_MECHANISM, "PLAIN");
// 云消息队列 Kafka 版消息的序列化方式。key/value的序列化方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArraySerializer");
// 请求的最长等待时间。单位毫秒。
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 30 * 1000);
// 设置客户端内部重试次数。
props.put(ProducerConfig.RETRIES_CONFIG, 5);
// 设置客户端内部重试间隔。单位毫秒。
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 3000);
// Hostname校验改成空。
props.put(SslConfigs.SSL_ENDPOINT_IDENTIFICATION_ALGORITHM_CONFIG, "");
props.put("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"aliyun_flink\" password=\"123456\";");
// 构造Producer对象,注意,该对象是线程安全的,一般来说,一个进程内一个Producer对象即可。
// 如果想提高性能,可以多构造几个对象,但不要太多,最好不要超过5个。
KafkaProducer<String, byte[]> producer = new KafkaProducer<>(props);
String topic = "test";
// 新增:创建一个列表用于存储三条消息
List<ProducerRecord<String, byte[]>> messages = new ArrayList<>();
for (int i = 0; i < 3; i++) {
byte[] value = getProtoTestData();
ProducerRecord<String, byte[]> kafkaMessage = new ProducerRecord<>(topic, value);
messages.add(kafkaMessage);
}
try {
// 批量发送消息
List<Future<RecordMetadata>> futures = new ArrayList<>();
for (ProducerRecord<String, byte[]> message : messages) {
Future<RecordMetadata> metadataFuture = producer.send(message);
futures.add(metadataFuture);
}
producer.flush();
// 同步获取Future对象的结果
for (Future<RecordMetadata> future : futures) {
try {
RecordMetadata recordMetadata = future.get();
System.out.println("Produce ok:" + recordMetadata.toString());
} catch (Throwable t) {
t.printStackTrace();
}
}
} catch (Exception e) {
// 客户端内部重试之后,仍然发送失败,业务要应对此类错误。
System.out.println("error occurred");
e.printStackTrace();
}
}
private static byte[] getProtoTestData() {
// 使用Faker生成随机数据
Faker faker = new Faker();
int orderId = faker.number().numberBetween(1000, 9999); // 随机生成订单ID
String orderName = faker.commerce().productName(); // 随机生成订单名称
double orderPrice = faker.number().randomDouble(2, 10, 1000); // 随机生成订单价格
long orderDate = System.currentTimeMillis(); // 当前时间作为订单日期
// 按照定义的数据结构,创建一个对象。
Order order = Order.newBuilder()
.setOrderId(orderId)
.setOrderName(orderName)
.setOrderPrice(orderPrice)
.setOrderDate(orderDate)
.build();
// 发送数据序列化:将对象数据转化为字节数据输出
return order.toByteArray();
}
}运行测试代码,向Kafka的test Topic写入三条Protobuf格式的数据。
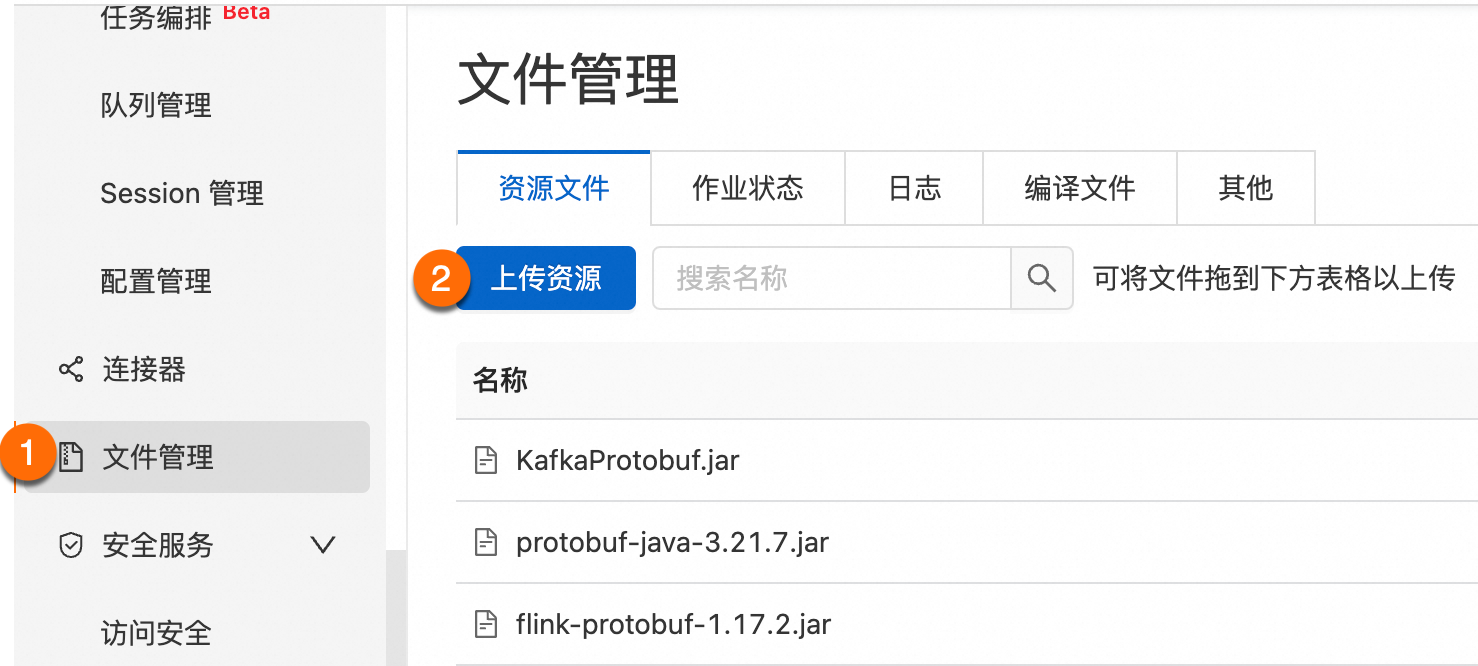
步骤三:编译打包上传
需要上传protobuf-java-3.21.7.jar和编译打包好的KafkaProtobuf.jar。
仅VVR 8.0.9及以上版本使用内置的Protobuf数据格式。如果低于此版本,需要额外添加flink-protobuf-1.17.2.jar依赖文件。
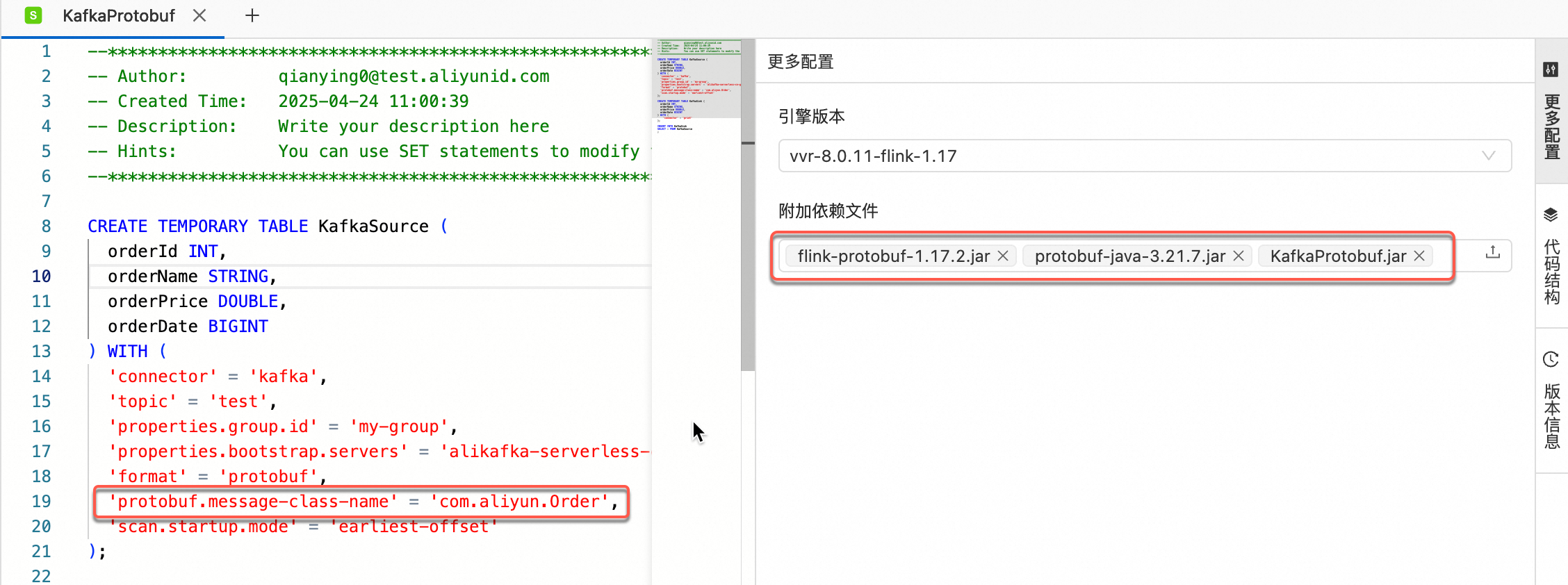
步骤四:Flink SQL读取数据
SQL示例参考。
添加
protobuf.message-class-name参数指定消息体对应的message类,更多protobuf参数详情请参见Flink-Protobuf。CREATE TEMPORARY TABLE KafkaSource ( orderId INT, orderName STRING, orderPrice DOUBLE, orderDate BIGINT ) WITH ( 'connector' = 'kafka', 'topic' = 'test', 'properties.group.id' = 'my-group', -- 消费者组ID 'properties.bootstrap.servers' = 'alikafka-serverless-cn-gh647pzkq03-1000-vpc.alikafka.aliyuncs.com:9092,alikafka-serverless-cn-gh647pzkq03-2000-vpc.alikafka.aliyuncs.com:9092,alikafka-serverless-cn-gh647pzkq03-3000-vpc.alikafka.aliyuncs.com:9092', // 填入对应的Kafka broker地址。 'format' = 'protobuf', -- value部分时使用的数据格式 'protobuf.message-class-name' = 'com.aliyun.Order', -- 指定消息体对应的message类 'scan.startup.mode' = 'earliest-offset' -- 从Kafka最早分区开始读取。 ); CREATE TEMPORARY TABLE KafkaSink ( orderId INT, orderName STRING, orderPrice DOUBLE, orderDate BIGINT ) WITH ( 'connector' = 'print' ); INSERT INTO KafkaSink SELECT * FROM KafkaSource ;附加文件依赖引用。
SQL调试。
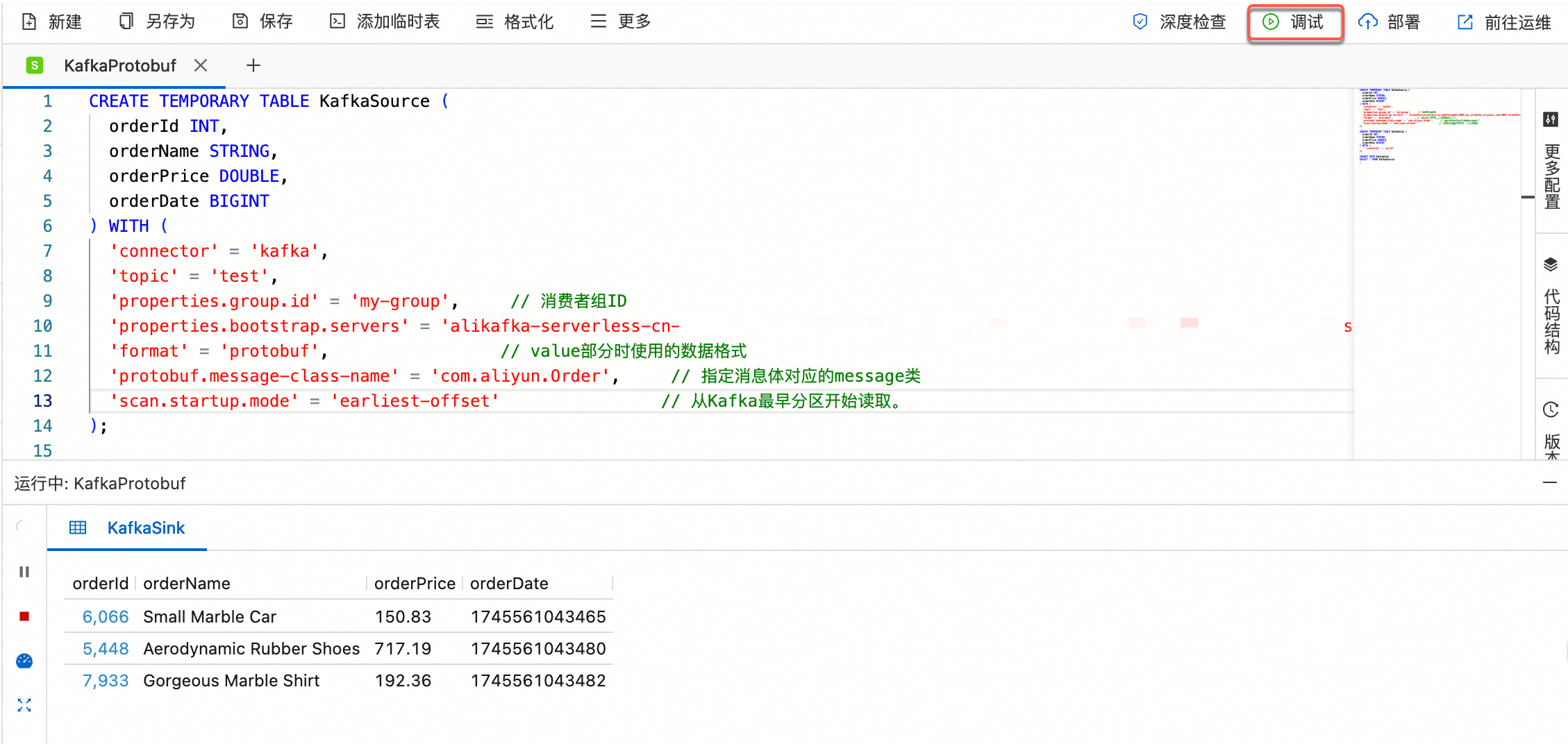
作业部署运行后查看输出。
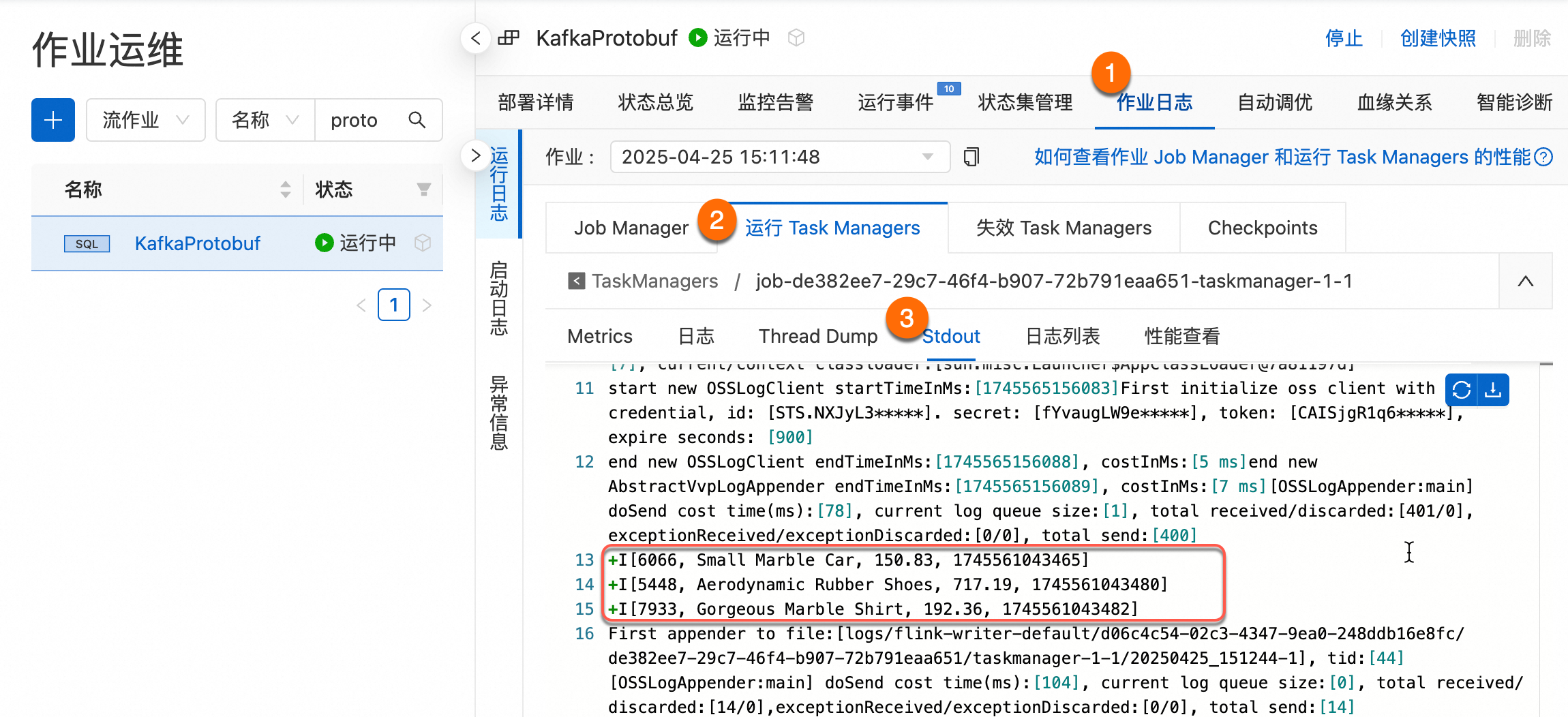
常见问题
调试检查报错
Bad return type。问题原因:采用了proto3语法编译生成的源代码。
解决方案:改为proto2语法编译后重新打包上传。
上游读取后,下游写入Kafka其他Topic,日志信息中出现大量warning报
CORRUPT_MESSAGE。问题原因:阿里云消息队列Kafka(非专业高写版创建的Local存储的Topic)不支持幂等和事务写入,您将无法使用Kafka结果表提供的精确一次语义exactly-once semantic功能。
解决方案:需要在结果表中添加配置项
properties.enable.idempotence=false以关闭幂等写入功能。作业运行时日志报错:
NoClassDefFoundError。问题原因:上传的protobuf-java的Jar包的版本和Protocol Buffers编译的不一致。
解决方案:检查附加依赖文件的版本是否一致,是否有文件缺少,编译打包的完整性。
作业检查报错:
Could not find any factory for identifier 'protobuf' that implements one of 'org.apache.flink.table.factories.EncodingFormatFactory。问题原因:仅支持VVR 8.0.9及以上版本使用内置的Protobuf数据格式。
解决方案:检查是否有添加
flink-protobuf依赖。