
配置Hologres Catalog后,您可以在实时计算开发控制台直接读取Hologres元数据,无需再手动注册Hologres表,从而提高作业开发的效率且保证数据的正确性。本文为您介绍如何配置、查看、使用及删除Hologres Catalog。
前提条件
已完成独享Hologres实例的创建,同时在实例中已完成数据库的创建。具体操作可参见创建数据库。
使用限制
不支持修改Catalog。如果需要修改,要先删掉已创建的Catalog重新创建。
Hologres实例必须为独享实例,不支持共享集群实例,原因是实时计算Flink版仅支持读写Hologres内表。
创建Hologres Catalog
Catalog创建完成后,配置信息不支持修改。如果需要修改,要删掉已创建的Catalog重新创建。
UI方式
如果您需要设置Hologres连接器支持的参数,可以采用SQL方式创建Hologres Catalog。
进入数据管理页面。
登录实时计算管理控制台,单击目标工作空间操作列下的控制台。
单击数据管理。
单击创建Catalog,选择Hologres后,单击下一步。
填写参数配置信息。
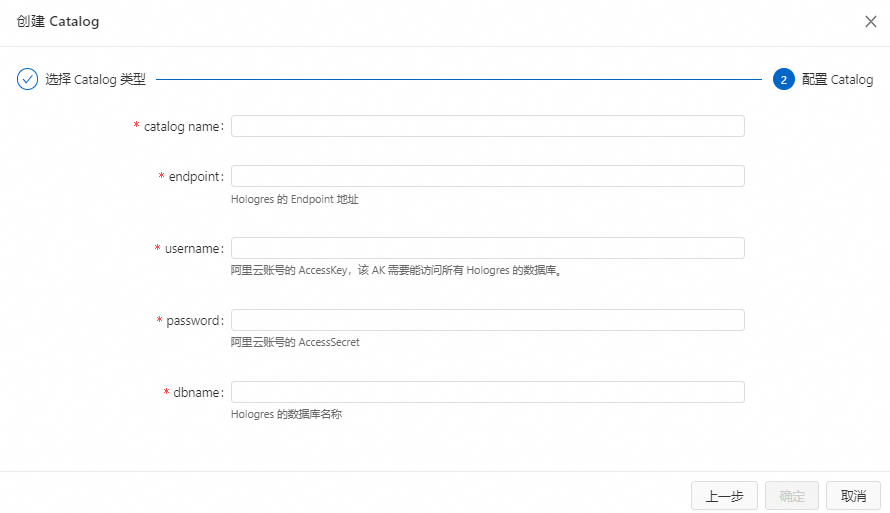
参数
说明
是否必填
备注
catalogname
Hologres Catalog名称。
是
仅支持小写字母a-z和数字0-9,不含大写字母、中划线(-)、下划线(_)等特殊字符。
endpoint
Hologres实例的网络端口。
是
Hologres实例与Flink工作空间在同一VPC:进入,在目标实例的详情页面的网络信息区域获取对应的指定VPC网络信息。
其他网络类型请参见如何获取Hologres的Endpoint地址?。
username
自定义账号的用户名,格式为
BASIC$<user_name>。阿里云账号或RAM用户的AccessKey ID。
是
当前配置的用户需要能够访问对应的Hologres数据库,Hologres数据库权限及用户管理详情请参见Hologres权限模型和用户管理。
AK取值的获取方式详情请参见如何查看AccessKey ID和AccessKey Secret信息?。
重要为了避免您的AK或密码信息泄露,建议您通过项目变量的方式填写其取值,详情请参见项目变量。
自定义账户所创建的Catalog仅显示拥有相应权限的数据库;使用AK/SK创建,则可以显示该实例下所有数据库。
password
自定义账号的密码。
阿里云账号或RAM用户的AccessKey Secret。
是
dbname
Hologres的数据库名称。
是
在目标Hologres实例中已完成数据库的创建,否则创建Catalog会报错。
单击确定。
创建完成后,元数据下即可查看新建的Catalog。
SQL方式
在数据查询文本编辑区域,输入配置Hologres Catalog的命令。
语法:
CREATE CATALOG <catalogname> WITH ( 'type' = 'hologres', 'endpoint' = '<endpoint>', 'username' = '<AccessKey>', 'password' = '<AccessSecret>', 'dbname' = '<dbname>' );示例:
简单示例
实时消费示例
CREATE CATALOG holocatalog WITH ( 'type' = 'hologres', 'endpoint' = 'hgpostcn-cn-******-cn-hangzhou-vpc-st.hologres.aliyuncs.com:80', 'username' = 'LTAI********************', 'password' = '${secret_values.ak_holo}', 'dbname' = 'holo_test' );需要开启Binlog,且支持消费Binlog数据。
CREATE CATALOG holocatalog WITH ( 'type' = 'hologres', 'endpoint' = 'hgpostcn-cn-******-cn-hangzhou-vpc-st.hologres.aliyuncs.com:80', 'username' = 'LTAI********************', 'password' = '${secret_values.ak_holo}', 'dbname' = 'holo_test', 'binlog' = 'true', -- 创建catalog时可以设置源表、维表和结果表支持的with参数,之后在使用此catalog下的表时会默认添加这些默认参数。 'cdcmode' = 'true', 'connectionpoolname' = 'the_conn_pool', 'table_property.binlog.level' = 'replica', --也可以在创建catalog时传入持久化的hologres表属性,之后创建表时,默认都开启binlog。 'table_property.binlog.ttl' = '259200' );参数详情如下表所示。
参数
说明
是否必填
备注
catalogname
Hologres Catalog名称。
是
仅支持小写字母a-z和数字0-9,不含大写字母、中划线(-)、下划线(_)等特殊字符。
type
类型。
是
固定值为hologres。
endpoint
Hologres的Endpoint地址。
是
Hologres实例与Flink工作空间在同一VPC:进入,在目标实例的详情页面的网络信息区域获取对应的指定VPC网络信息。
其他网络类型请参见如何获取Hologres的Endpoint地址?。
username
阿里云账号的AccessKey。
是
详情请参见如何查看AccessKey ID和AccessKey Secret信息?。
说明为了避免您的AK信息泄露,建议您通过变量的方式填写password取值,详情请参见项目变量。
当前配置的AccessKey对应的用户需要能够访问对应的Hologres数据库,Hologres数据库权限请参见Hologres权限模型。
password
阿里云账号的AccessSecret。
是
dbname
Hologres的数据库名称。
是
在目标Hologres实例中已完成数据库的创建,否则创建Catalog会报错。
ignore-non-persisted-options
在使用Hologres Catalog时创建带有不可持久化选项的表时,是否忽略非可持久化选项。
否
参数取值如下:
true(默认值):可以成功创建出表,而忽略所有非可持久化选项。
false:会报创建表失败的错误。
说明Hologres Catalog表选项的可持久化意味着当再次从Catalog读取该表的相关信息时,可以重新获取您在DDL中定义的一致的信息。目前仅支持endpoint、username、password和dbname可持久化选项。
catalog.table.metadata-columns
通过此catalog来指定一个源表时,表的Schema可以按需添加Hologres Binlog源表的元数据列。多个元数据列使用英文分号';'分隔,例如:
hg_binlog_event_type;hg_binlog_timestamp_us。否
默认不添加元数据列,当配置该参数时,返回的表Schema会额外添加指定的元数据列,这些列只适用于Hologres Binlog源表,所以该Catalog返回的表只能用作数据源表,不可以用作结果表或维表。目前支持6种meta-column,详情请参见 Hologres Binlog字段组成。
说明仅实时计算引擎VVR 8.0.11及以上版本支持该参数。
其他Hologres连接器支持的参数
在创建Catalog时可以填入一些参数,包括WITH参数,之后使用此Catalog中的表时,将会默认配置这些参数。
否
使用此功能,需要
ignore-non-persisted-options参数配置为true。输入创建Catalog的代码后,单击右上角的运行完成Catalog的创建。
查看Hologres Catalog
Hologres Catalog配置成功后,您可以通过以下步骤查看Hologres元数据。
进入数据管理页面。
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
单击数据管理。
在Catalog列表页面,查看Catalog名称和类型。
单击查看,可以查看目标Catalog下的数据库和表。如果Schema为public,则表名称前面就省略了Schema的前缀,即直接显示tableName。
使用Hologres Catalog
注意事项:
如果Schema为public,在填写${schema_name.table_name}时,可以省略模式名称的前缀,直接填写tableName,即${table_name}。
通过Hologres Catalog读取出来的表支持消费update数据,读取出来的Hologres表的ignoredelete属性默认为false,mutatetype属性默认为insertorupdate。ignoredelete和mutatetype属性含义详情请参见宽表Merge和局部更新功能。
创建Hologres表
要创建的表信息:Hologres Catalog为holocatalog、数据库为holodb、表为holotable。
在已注册的Hologres数据服务下创建表时,WITH参数中connector为必填参数,且取值为hologres,可省略endpoint等其他参数。
目前不支持直接在Hologres表中添加或修改支持的WITH参数。对于这些参数,您可以通过SQL hints的方式在INSERT语句中添加或修改。
具体的操作如下:
UI方式
进入数据管理页面。
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
单击数据管理。
进入目标数据库。
单击目标Catalog名称对应操作列的查看。
单击目标数据库名称对应操作列的查看。
创建Hologres表。
单击创建表。
在使用内置连接器连接页签,选择实时数仓Hologres连接器,单击下一步。
填写建表语句并配置相关参数信息。代码示例如下。
语法
示例
CREATE TABLE `${catalog_name}`.`${db_name}`.`${table_name}` ( ... ) WITH ( 'connector' = 'hologres' );CREATE TABLE `holocatalog`.`holo_test`.`product` ( id INT, name STRING ) WITH ( 'connector' = 'hologres' );单击确定。
SQL命令方式
在数据查询文本编辑区域,输入以下建表语句。
通常,有以下几种方式创建Hologres表:
使用
USE CATALOG HoloName命令使用USE语句直接引用Hologres Catalog。
语法
示例
USE CATALOG ${catalog_name}; CREATE TABLE `${db_name}`.`${schema_name.table_name}`( ... ) WITH ( 'connector' = 'hologres' );USE CATALOG holocatalog; CREATE TABLE `holodb`.`holotable` ( id INT, name STRING ) WITH ( 'connector' = 'hologres' );使用DDL语句
在DDL语句中直接引用Hologres Catalog。
语法
示例
CREATE TABLE `${catalog_name}`.`${db_name}`.`${schema_name.table_name}`( ... ) WITH ( 'connector' = 'hologres' );CREATE TABLE `holocatalog`.`holodb`.`holotable` ( id INT, name STRING ) WITH ( 'connector' = 'hologres' );在DDL语句中可以设置物理表属性。
CREATE TABLE `holocatalog`.`holodb`.`holotable` ( id INT, name STRING ) WITH ( 'connector' = 'hologres', 'table_property.orientation' = 'column', 'table_property.distribution_key' = 'a', 'table_property.clustering_key' = 'b:desc', 'table_property.bitmap_columns' = 'a,b', 'table_property.segment_key' = 'c', 'table_property.time_to_live_in_seconds' = '86400', 'table_property.binlog.level' = 'replica', 'table_property.binlog.ttl' = '86400' );输入建表语句后,单击右上角的运行完成表的创建。
创建Hologres表时,允许在WITH参数中设置表属性(部分属性无法修改),合理的表属性设置可以有助于系统高效地组织和查询数据。
物理表属性:当前支持的表属性与Hologres侧是一致的,Catalog侧仅是加上了
table_property.前缀用以区分。参数详情请参见建表概述和订阅Hologres Binlog。参数
说明
使用示例
是否支持修改
table_property.orientation
表存储格式。
'table_property.orientation' = 'row,column'
不支持修改
table_property.table_group
Table Group。
'table_property.table_group' = 'table_group_xxx'
table_property.distribution_key
分布键。
'table_property.distribution_key' = 'a,b'
table_property.clustering_key
聚簇索引。
'table_property.clustering_key' = 'a,b:desc'
able_property.event_time_column(原table_property.segment_key)
分段键。
'table_property.event_time_column' = 'c,d'(或者 'table_property.segment_key' = 'c,d')
table_property.bitmap_columns
位图索引。
'table_property.bitmap_columns' = 'a:on,b:off'
支持修改
table_property.dictionary_encoding_columns
比特编码。
'table_property.dictionary_encoding_columns' = 'a:on,b:off,c:auto'
table_property.time_to_live_in_seconds
表数据声明周期。
'table_property.time_to_live_in_seconds' = '864000'
table_property.binlog.level
是否开启Binlog。
'table_property.binlog.level' = 'replica'
table_property.binlog.ttl
Binlog的TTL。
'table_property.binlog.ttl' = '86400'
宽容模式参数:在使用Hologres Catalog创建表时,可以通过参数enableTypeNormalization设置是否打开类型宽容模式。
维度
说明
使用场景
在CTAS等场景中,需要调整已有字段数据类型的精度(如从VARCHAR(10)到VARCHAR(20))或者修改数据类型(如从SMALLINT修改为INT)。
注意事项
宽容模式应该在首次启动CTAS作业时开启,如果在首次启动时未开启宽容模式,需要删除下游表并且将作业无状态重启才能生效。
开启宽容模式后,在上游发生数据类型修改事件时,只要所修改类型与原类型的归一化类型相同,则视作类型修改成功,CTAS作业正常运行。否则属于不兼容的情况,CTAS作业会抛出异常。
参数取值
false(默认值):根据类型映射正常创建Hologres物理表。
true:启用类型宽容模式,在创建Hologres物理表时,会使用类型归一化后精度更高的数据类型。目前类型归一化规则如下:
TINYINT、SMALLINT、INT和BIGINT归一化为BIGINT。
CHAR、VARCHAR和STRING归一化为STRING。
FLOAT和DOUBLE归一化为DOUBLE。
其他数据类型按照原本的类型映射规则创建,详情请参见类型映射。
修改Hologres表
目前Hologres Catalog支持的修改表操作及示例如下:
操作 | 语法及示例 |
修改表属性 | 仅部分表属性支持修改,详情参考创建Hologres表。
|
重命名表 |
|
增加列 |
|
修改列名 |
|
修改列注释 |
|
读写Hologres表
读取Hologres表数据写入到结果表中。
Flink默认以批模式读取Hologres源表数据,不会实时消费新写入的数据。要实时消费Hologres数据,您可以采用以下任一方案。
在创建Hologres Catalog时配置:在创建Catalog时采用SQL方式,开启Binlog并消费Binlog数据,具体请参考实时消费示例。然后读取Hologres数据,代码示例如下。
语法
示例
INSERT INTO ${other_sink_table} SELECT ... FROM `${catalog_name}`.`${db_name}`.`${schema_name.table_name}`;INSERT INTO sink_table SELECT id, name FROM `holocatalog`.`holodb`.`holotable`;更改读取模式为流模式:通过Table Hint方式将读取模式更改为流模式,在SQL中添加
/*+ OPTIONS('binlog'='true') */参数。代码示例如下。INSERT INTO sinktable SELECT id, name FROM `holocatalog`.`holodb`.`holotable` /*+ OPTIONS ('binlog' = 'true') */;
将源表数据写入到Hologres表中。
语法
示例
INSERT INTO `${catalog_name}`.`${db_name}`.`${schema_name.table_name}` SELECT ... FROM ${other_source_table}INSERT INTO `holocatalog`.`holodb`.`holotable` SELECT id, name FROM source_table;
作为CTAS的目标端Catalog
语法
CREATE TABLE IF NOT EXISTS `${catalog_name}`.`${db_name}`.`${schema_name.table_name}` WITH ( 'connector' = 'hologres' ) AS TABLE ${other_source_table};示例
CREATE TABLE IF NOT EXISTS `holocatalog`.`holodb`.`holotable` WITH ( 'connector' = 'hologres' ) AS TABLE source_table;
CTAS支持在WITH参数中设置物理表属性,在创建目标表时,同时在表上设置对应的属性。具体支持的表属性参数详情,请参见创建Hologres表。
当从源端同步数据过程中,为保证数据能够写入Hologres,Hologres Catalog会在以下情况被迫改写目标端的Schema:
上游Schema使用DECIMAL类型的列作为主键。
由于Hologres不支持DECIMAL类型作为主键,因此Hologre默认会改写该列类型为BIGINT。如果该改写不满足您的需求,则您也可以使用CTAS语法将引用的类转换为STRING类型,并重新建立主键。
上游Schema中包含类型TIME、TIMESTAMP或TIMESTAMP_LTZ且精度大于6。
由于Hologres支持的时间类型精度为6,因此为了确保数据能够写入到Hologres中,Flink会隐式地丢弃高于Hologres所支持的最高精度的部分。
作为CDAS的目标端Catalog
语法
CREATE DATABASE IF NOT EXISTS `${catalog_name}`.`${db_name}` WITH ( 'sink.parallelism' = '5' -- 设置每张结果表的并发数。 ) AS DATABASE ${other_source_database};示例
CREATE DATABASE IF NOT EXISTS `holocatalog`.`holodb` WITH ( 'sink.parallelism' = '5' -- 设置每张结果表的并发数。 ) AS DATABASE source_database;
WITH参数设置:
支持声明结果表的参数:当作业启动时,这些参数将被应用到需要同步的下游表中。具体支持调节的参数可参见实时数仓Hologres结果表。
支持指定schemaname:将数据同步到Hologres目标库的指定Schema中。参数信息如下。
参数
说明
是否必填
备注
schemaname
schema名称。
否
默认值为public。
不支持设置物理表属性:每张目标表可能需要设置不同的表属性,WITH参数不支持为每张表分别设置属性。
如果您需要设置表属性,需要先手动创建目标表,再去启动CDAS作业。物理表属性的详细信息请参见创建Hologres Catalog。
删除Hologres Catalog
删除Hologres Catalog不会影响已运行的作业,但对未上线或者需要暂停恢复的作业均产生影响,请您谨慎操作。
UI方式
进入数据管理页面。
登录实时计算管理控制台。
单击目标工作空间操作列下的控制台。
单击数据管理。
在Catalog列表页面,单击目标Catalog名称对应操作列下的删除。
在弹出的对话框中,单击删除。
删除完成后,在左侧元数据区域查看目标Catalog是否已删除。
SQL命令方式
在数据查询文本编辑区域,输入以下命令。
DROP CATALOG ${catalog_name}其中,${catalog_name}为您要删除的在实时计算开发控制台上显示的Hologres Catalog名称。
选中删除Catalog的命令,鼠标右键选择运行。
在左侧元数据区域,查看目标Catalog是否已删除。
常见问题
相关文档
Hologres WITH参数信息:WITH参数
Hologres Catalog相关实践场景: