
Flink Advisor作业智能诊断服务能够帮您监控作业健康状况,分析和诊断错误日志、异常运行和风险情况,并提供可理解和可操作的诊断建议,全面保障您的业务稳定可靠运行。本文为您介绍如何使用作业智能诊断服务。
背景信息
Flink Advisor作业智能诊断服务实时监控作业的健康状况并计算健康分数。健康分满分为100,平台会统计和分析最近半小时内作业情况,根据作业命中诊断风险的个数及风险等级进行相应扣分。从开发到运维全流程,它提供了作业看护和诊断能力。全量实时分析Flink作业全生命周期过程中产生的日志、事件、指标以及配置,并依据阿里云技术专家排查Flink作业高频问题的运维经验,提供作业开发态报错日志诊断、运行态健康分及异常态根因诊断。针对诊断结果给出相应的优化和建议,减少您的数据分析耗时和修复时间,保障作业运行的稳定性和健康度。可以实现的功能如下图所示。
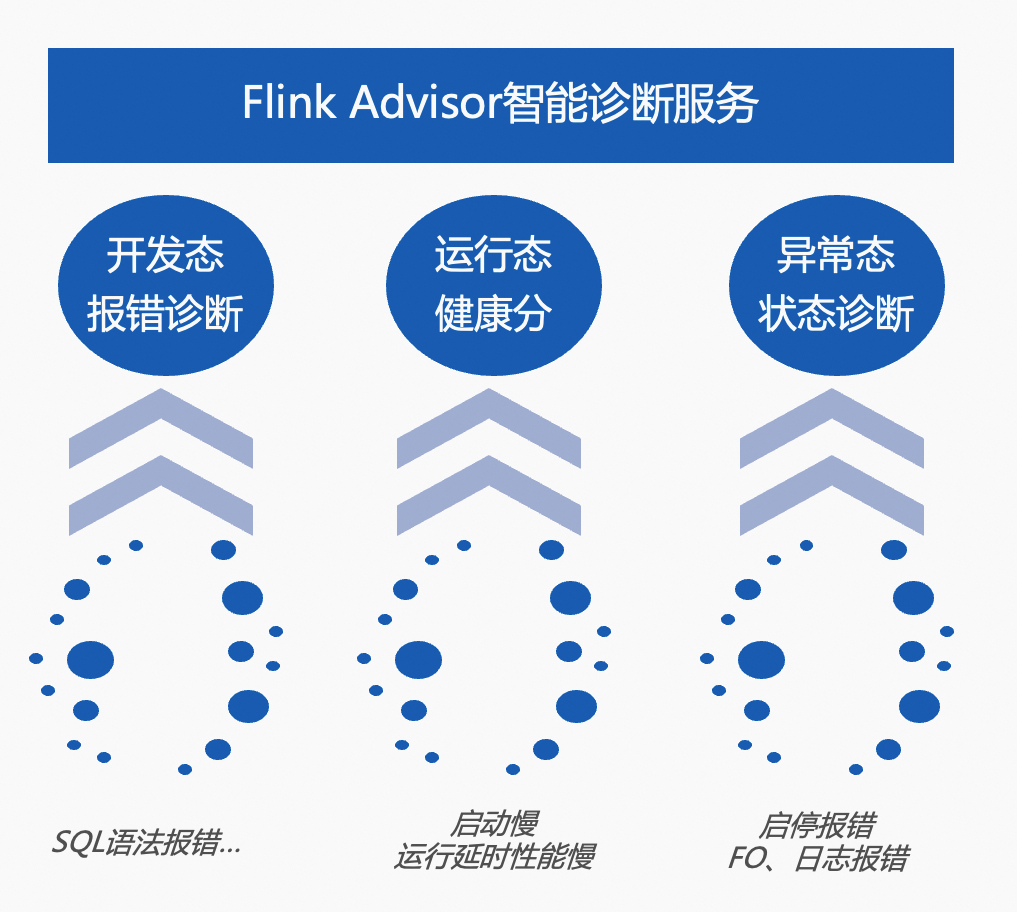
使用限制
仅流作业支持作业智能诊断功能,批作业不支持作业智能诊断功能。
异常日志自动分析
开发态异常
在实时计算管理控制台,单击目标工作空间操作列下的控制台。
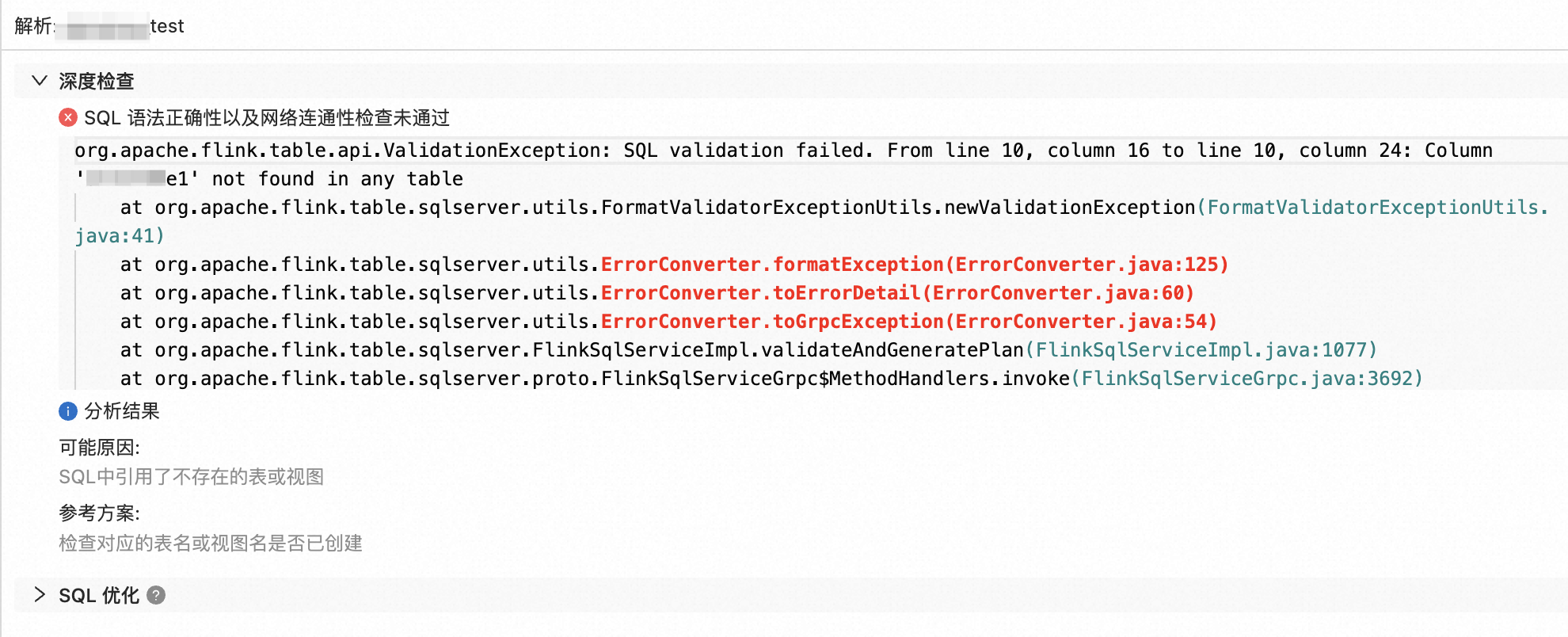
在页面,编写SQL后,单击深度检查。
深度检查能够检查作业的SQL语义、网络连通性以及作业使用的表的元数据信息。同时,您可以单击结果区域的SQL优化,展开查看SQL风险问题提示以及对应的SQL优化建议。
在下方结果区域,查看问题、可能原因和参考方案。
 说明
说明如果深度检查无法直接帮您提供问题原因和优化建议,您可以鼠标选中相关问题内容,单击在帮助文档中搜索,在帮助文档中查找相关信息。
运行态异常
在实时计算管理控制台,单击目标工作空间操作列下的控制台。
在页面,单击目标作业名称。
在作业日志页签左侧,切换运行日志、启动日志和异常信息后,查看运行态日志分析。

详情请参见查看启动和运行日志、查看运行异常日志和查看历史作业实例日志。
对作业进行智能诊断
进入智能诊断页面。
在实时计算管理控制台,单击目标工作空间操作列下的控制台。
在页面,单击目标作业名称。
进入智能诊断页面。
您通过以下任意一种方式进入:
在作业列表页面,单击目标作业健康分按钮。

作业健康分颜色和含义详情如下表。
颜色
含义
健康分范围
绿色
表示作业健康状态良好,没有发现潜在风险,但可能存在一些配置建议。
大于80分
黄色
表示作业可能存在一些问题或潜在的风险,需要留意和进行检查。
60分~80分
红色
表示存在严重问题,需要立即处理,否则可能会导致作业停止,影响业务正常运行。
小于60分
单击目标作业名称后,单击智能诊断页签。

单击开始诊断。
Flink Advisor建立了丰富的面向Flink错误日志的日志知识库,具体的诊断类型、阶段、诊断项及处理方法详情请参见Flink Advisor诊断项。
查看诊断结果和优化建议。
对于系统提供的优化建议,您可以直接单击对应的立刻应用。
Flink Advisor诊断项
类型 | 阶段 | 诊断项 | 诊断内容 |
异常(影响作业当前运行) | 启动 | 启动文件分析 | 如果作业需要的OSS中的JAR包不存在,则作业会无法启动。请您重新上传JAR包后再启动作业。 |
资源分析 | 如果剩余可用资源不足,则作业无法启动。请您调小作业资源配置或对集群进行扩容解决。 | ||
如果绑定CNI失败,则作业无法启动。请您检查对应vSwitch IP是否用完。 | |||
如果弹性网卡ENI的IP用量超过网络上限,则作业无法启动。建议您扩容弹性网卡后重试。 | |||
拓扑网络分析 | 如果TaskManager与JobManager的网络不通,则作业状态显示异常。 | ||
如果最近10分钟内存在弹性网卡挂载超时,则作业启动慢。建议您耐心等待。 | |||
上下游网络分析 | 如果TCP端口探测正常,但Connector无法连通,作业无法启动。建议您检查上下游服务网络配置是否正确。 | ||
上下游权限探测 | 如果上游数据源无法连通,则作业无法启动。建议您检查上游服务权限配置。 | ||
如果下游数据源无法连通,则作业无法启动。建议您检查下游服务权限配置。 | |||
启动速度分析 | 如果作业JAR包过大,则作业启动慢。建议您压缩JAR包后重新上传或耐心等待。 | ||
JobGraph检查 | 由于产品老版本存在配置文件丢失的隐患,因此作业FailOver后可能会无法恢复。请手动重启(停止后再启动)作业解决。 | ||
Session集群检查 | 由于产品老版本存在Session集群异常的隐患,因此作业状态可能会显示异常。 | ||
运行 | HA状态检查 | 如果作业未开启HA,则作业FailOver无法正常恢复。请重新上线作业并手动重启(停止后再启动)作业解决。 | |
Checkpoint检查 | 由于产品老版本存在CheckPoint功能异常的隐患,因此Checkpoint可能会失败。 | ||
上下游权限探测 | 如果TCP端口探测正常,但Connector无法连通,作业无法启动。建议您检查上下游服务权限配置。 | ||
作业运行状态检查 | 作业的TaskManager发生内存溢出,导致作业Failover,请检查作业配置,尝试调大TaskManager内存。 | ||
停止 | 停止速度分析 | 由于产品老版本过低的隐患,因此停止作业会比较慢。如果出现作业停止比较慢的情况,请通过手动重启(停止后再启动)作业解决。 | |
风险(不影响作业当前运行) | 配置 | JobGraph检查 | 虽然作业当前状态正常,但系统检测到产品老版本存在配置文件丢失的隐患,FailOver后无法恢复。请手动重启(停止后再启动)作业解决。 |
HA状态检查 | 虽然作业当前状态正常,但系统检测到由于作业未开启HA,会导致FailOver后无法恢复,请重新上线作业并手动重启(停止后再启动)作业解决。 | ||
版本检查 | 虽然作业当前状态正常,但检测使用的版本存在重大缺陷。 | ||
运行 | Checkpoint检查 | 作业当前状态虽正常,但检测到由于产品老版本存在Checkpoint异常的稳定性隐患。 | |
作业当前状态虽正常,但检测到Checkpoint已长时间未做成功。 | |||
停止速度分析 | 作业当前状态虽正常,但检测到由于产品老版本存在停止作业慢的隐患,请通过手动重启(停止后再启动)作业解决。 | ||
作业运行环境分析 |
| ||
作业运行版本检测 | 版本已到EOS(服务与支持中止),可能存在稳定性问题或无法得到有效的产品支持。详情请参见如何查看当前作业的Flink版本?。 |
相关文档
Job Manager和运行Task Managers的性能查看详情,请参见查看作业性能。
如果您希望系统能够自动或者定时完成资源调节,而无需手动进行调节,可以配置自动调优,详情请参见配置自动调优。
提升Flink SQL作业性能详情,请参见高性能Flink SQL优化技巧。