
LLM(Large Language Model)是指大型语言模型,是一种采用深度学习技术训练的具有大量参数的自然语言处理模型。您可以基于ModelScope模型库和函数计算GPU实例的浅休眠(原闲置)计费功能低成本快速搭建LLM应用实现智能问答。
使用资格申请
操作步骤
本教程使用的LLM模型为ChatGLM3-6B。更多开源LLM,请参见ModelScope官网。
前提条件
-
已开通函数计算服务。具体操作,请参见开通函数计算服务。
-
已开通文件存储NAS服务。具体操作,请参见欢迎使用NAS文件系统。
-
已注册ModelScope账号,并绑定阿里云账号。具体操作,请参见ModelScope官网。
创建应用
登录函数计算控制台,在左侧导航栏,单击应用。
如果您首次使用函数计算的应用中心,或您的账号下没有创建任何应用,在左侧导航栏,单击应用后,将自动进入创建应用页面。
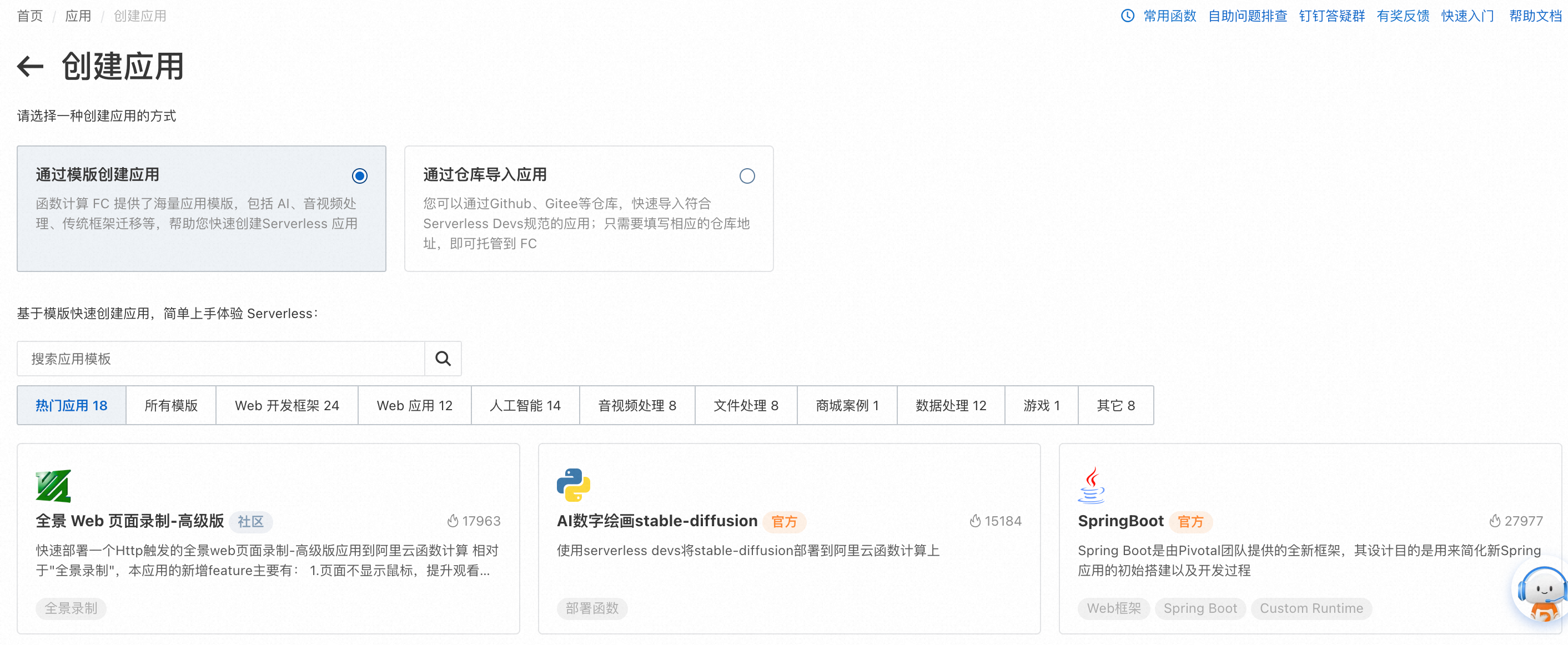
如果您之前使用过应用中心,在左侧导航栏,单击应用,然后在应用页面单击创建应用。
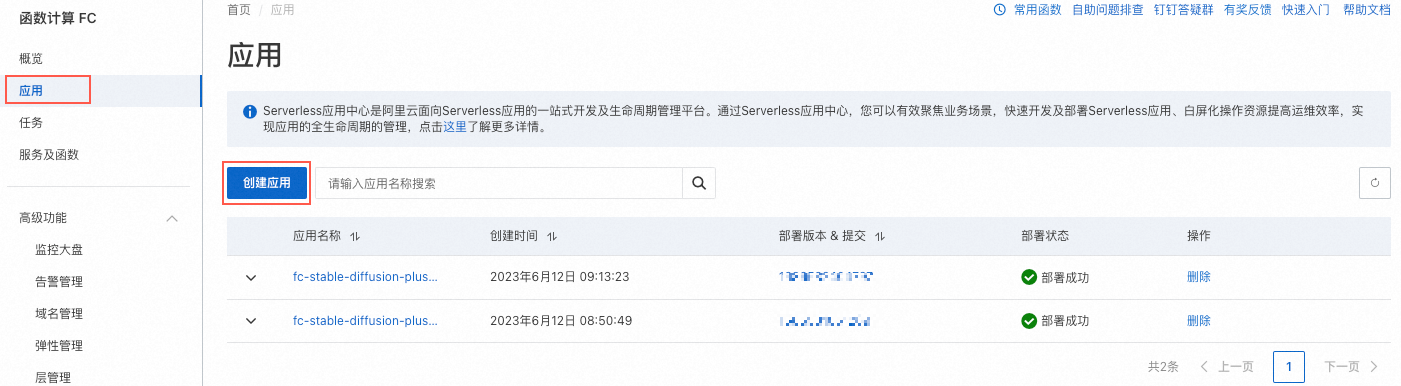
-
在创建应用页面,选择通过模板创建应用,然后在应用列表中搜索
ModelScope并选择ModelScope 应用模板,光标移至该卡片,然后单击立即创建。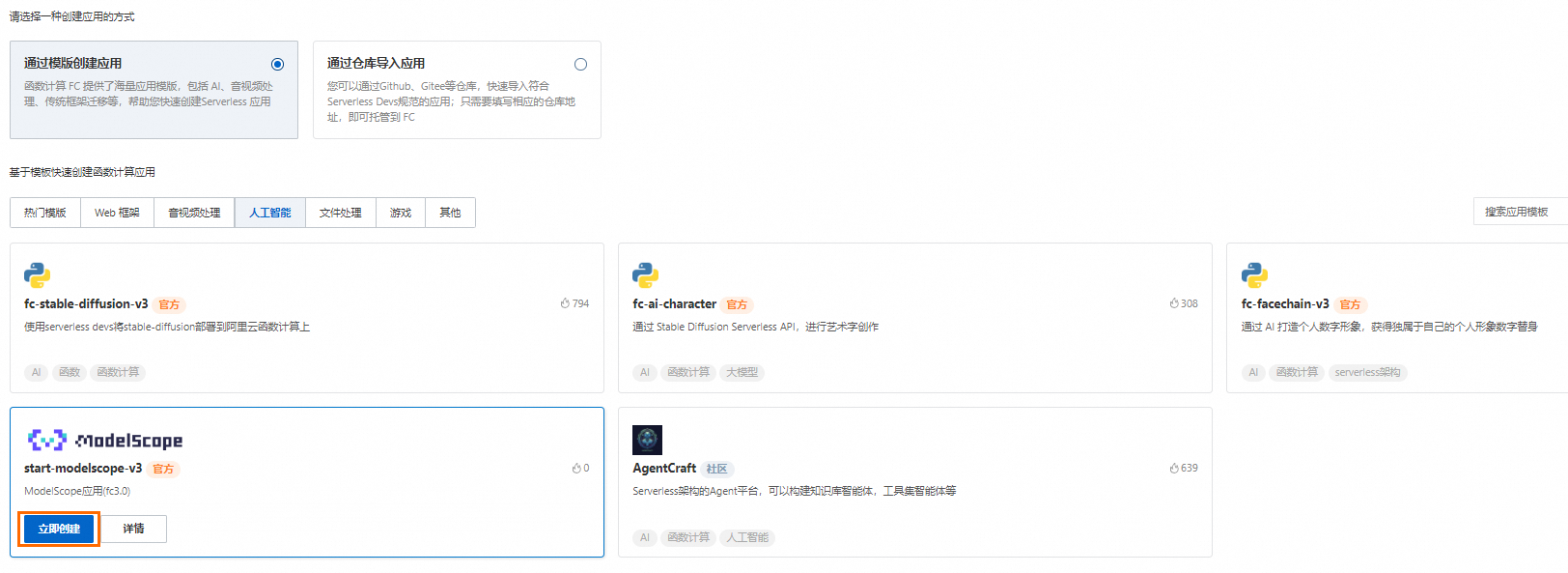
-
在创建应用页面,设置以下配置项,然后单击创建并部署默认环境。
主要配置项说明如下,其余配置项保持默认值即可。
配置项
说明
示例值
基础配置
部署类型
选择部署应用的方式。
直接部署
角色名称
首次登录用户,需要单击前往授权配置角色。

如果已有角色权限不足,也需要单击前往授权为角色授予所需权限。

AliyunFCServerlessDevsRole
高级配置
地域
选择部署应用的地域。目前支持华东1(杭州)和华东2(上海)地域。
重要如果部署异常,例如AIGC公共镜像拉取耗时长,拉取失败,请切换到其他地域重试。
华东2(上海)
服务角色ARN
同配置项角色名称,需创建并选择已授权角色。
AliyunFCDefaultRole
模型ID
ModelScope的模型ID。
ZhipuAI/chatglm3-6b
模型版本
ModelScope的模型版本。
v1.0.2
模型任务类型
ModelScope的模型任务类型。
chat
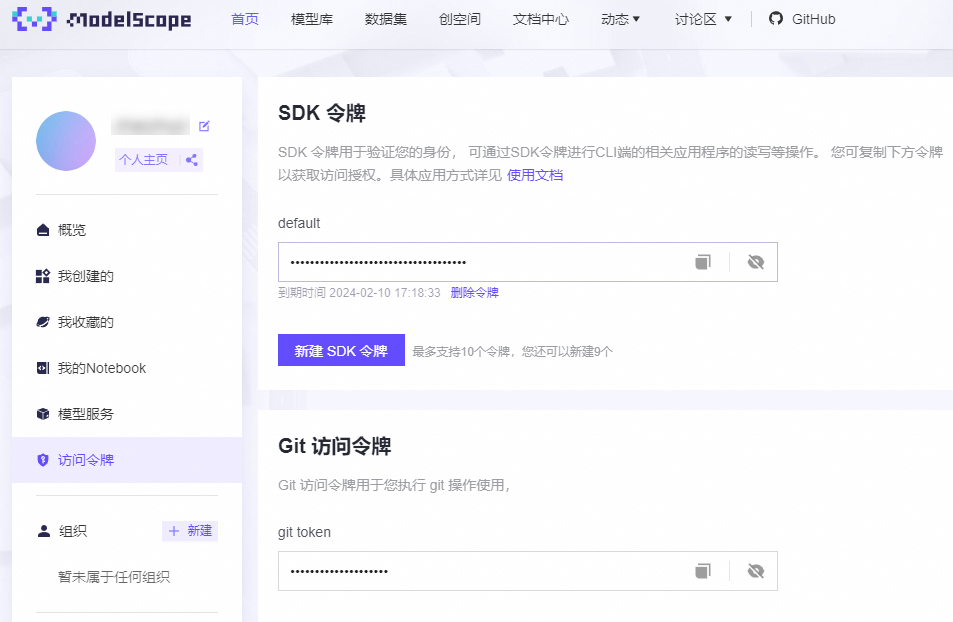
Access Token
ModelScope的访问令牌。ModelScope账号与阿里云账号绑定后,在ModelScope官网首页获取。

57cc1b0a-08e8-4224-******
GPU实例类型
函数实例所使用的卡型。
fc.gpu.tesla.1
显存大小
函数实例的显存大小(MB)。
16384
内存大小
函数实例的内存大小(MB)。
32768
模型缓存
ModelScope的模型缓存地址。
www.modlescope.cn
重要由于本教程使用函数计算的GPU浅休眠(原闲置)实例,因此GPU实例类型和显存大小必须指定为fc.gpu.tesla.1和16384。
-
为应用开启浅休眠(原闲置)预留模式。
-
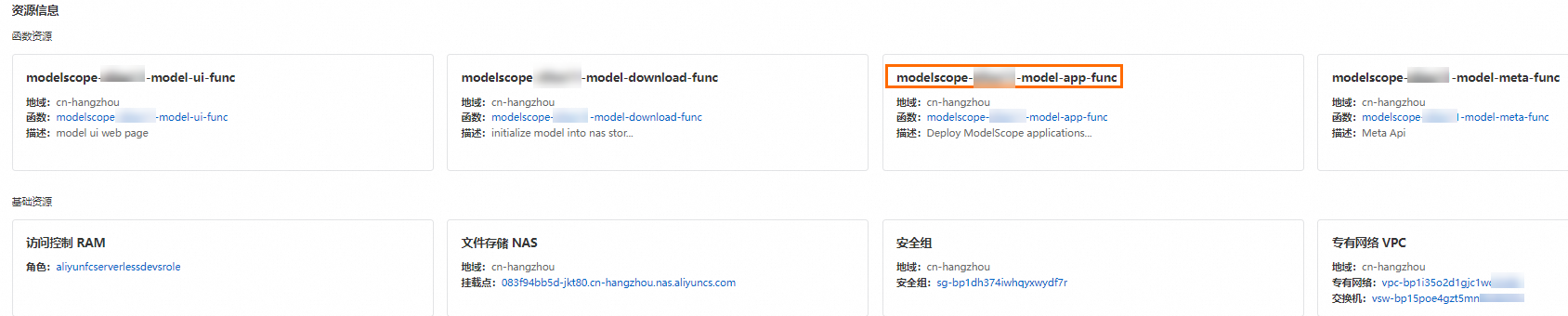
应用部署完成后,在资源信息区域单击model_app_func函数名称跳转至函数详情页。
-
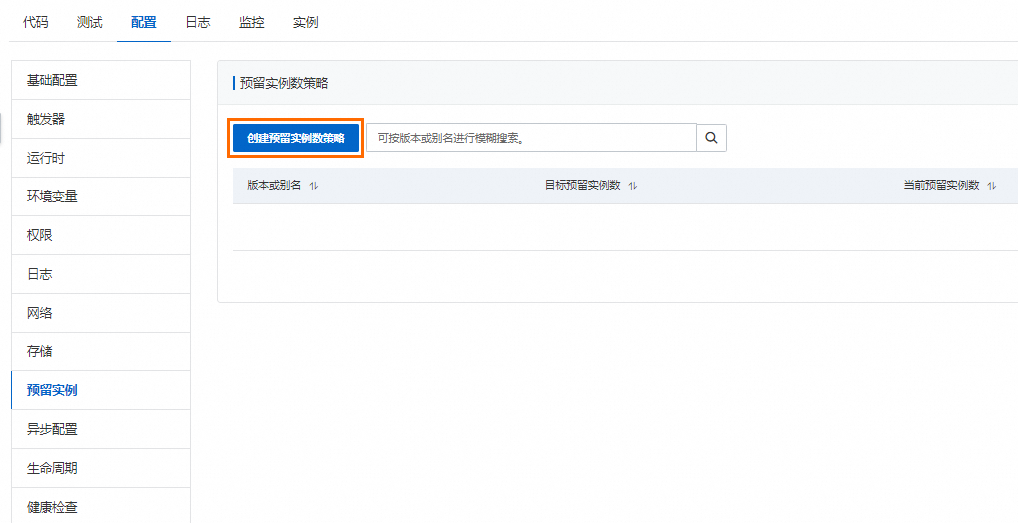
在函数详情页,选择弹性管理页签,版本或别名选择LATEST,然后单击创建规则。
-
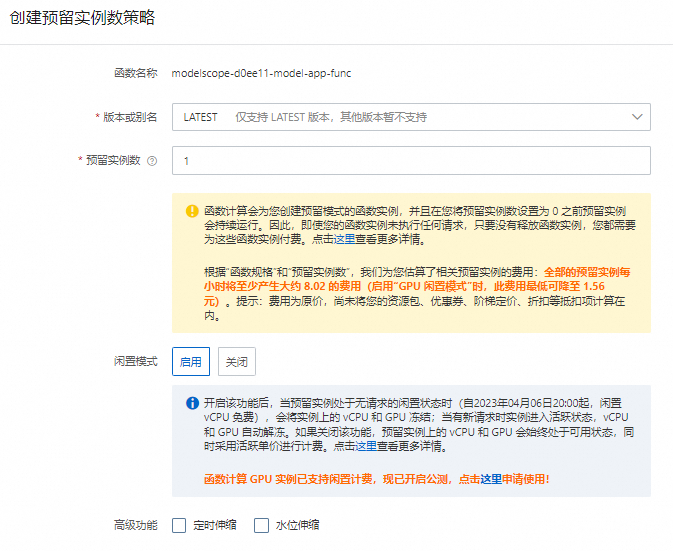
在创建弹性伸缩限制规则页面,最小实例数设置为1,启用浅休眠(原闲置)模式,然后单击创建。
等待容器实例成功启动后,可以看到当前预留实例数为1,且显示已开启浅休眠(原闲置)模式字样,表示浅休眠(原闲置)预留实例已成功启动。
-

使用LLM应用
-
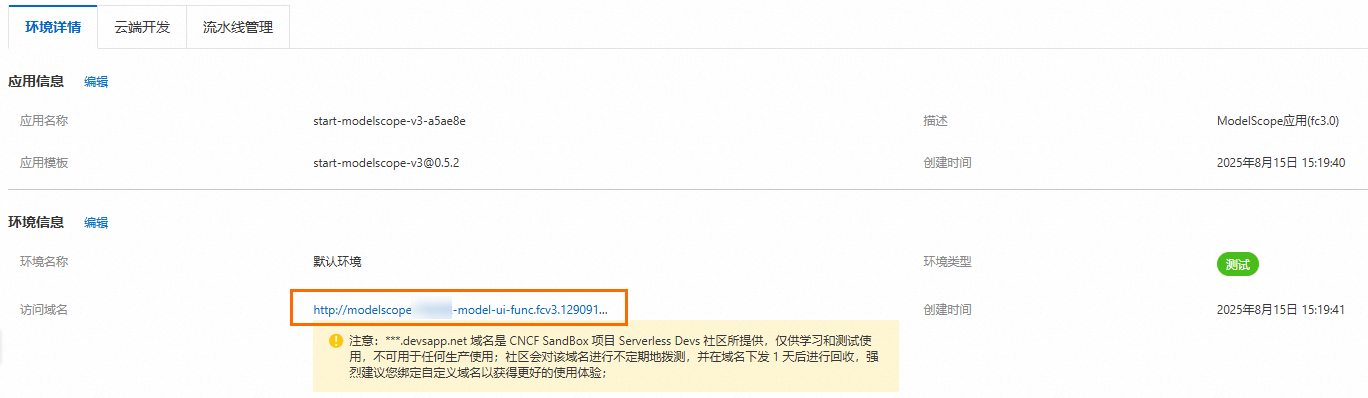
在应用页面,点击域名地址,即可使用LLM应用。
-
输入文本信息,然后单击Submit,您可以看到模型的回答结果。
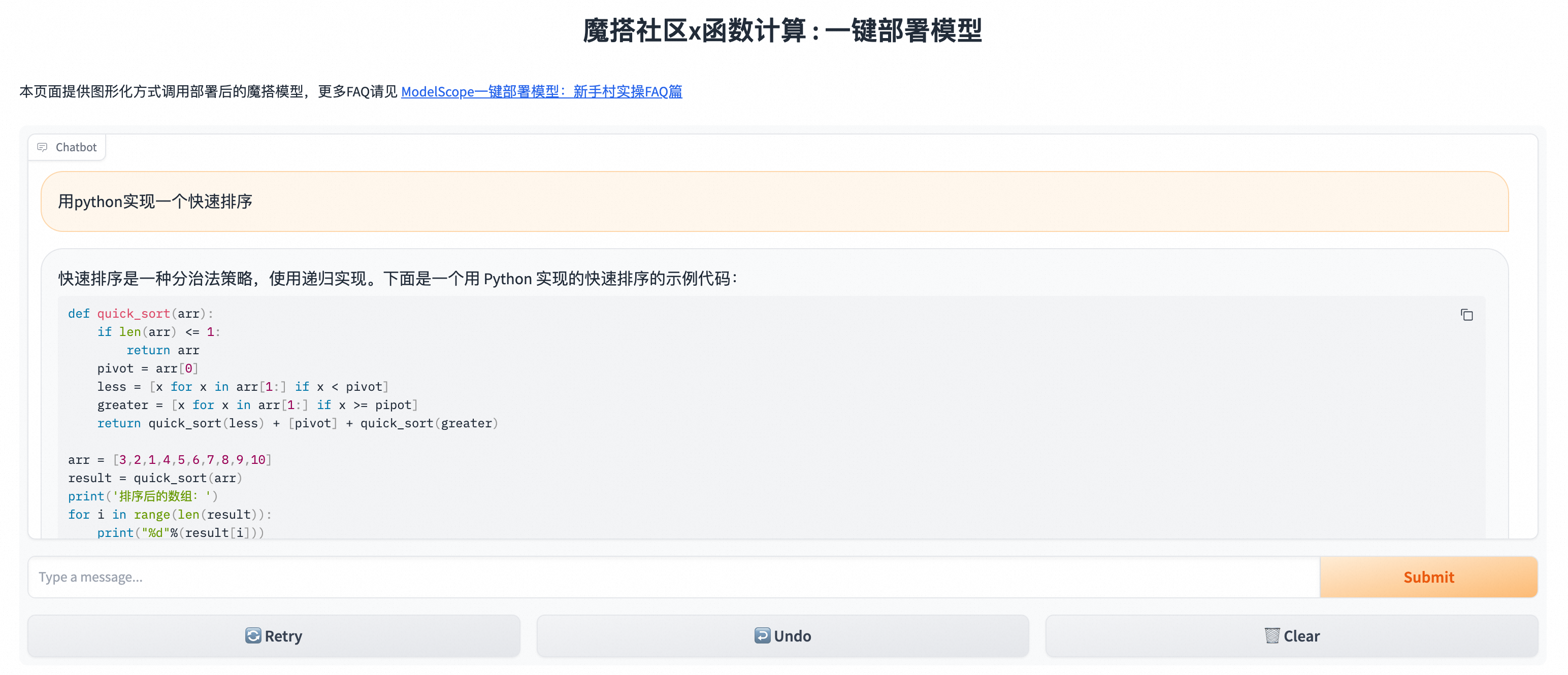
函数计算平台会在您调用结束后,自动将GPU实例置为浅休眠(原闲置)模式,无需您手动操作,并且会在下次调用到来之前,将该实例唤醒,置为活跃模式进行服务。
删除资源
如您暂时不需要使用此应用,请及时删除对应资源。如您需要长期使用此应用,请忽略此步骤。
-
返回函数计算控制台概览页面,在左侧导航栏,单击应用。
-
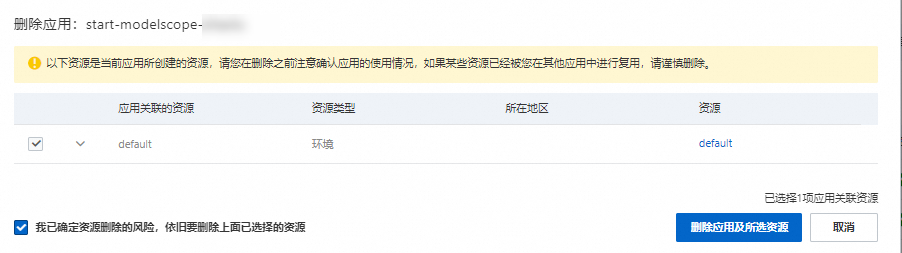
单击目标应用右侧操作列的删除应用,在弹出的删除应用对话框,勾选我已确定资源删除的风险,依旧要删除上面已选择的资源,然后单击删除应用及所选资源。
费用说明
套餐领取
为了方便您体验本文提供的LLM应用,首次开通用户可以领取试用套餐并开通函数计算服务。更多信息,请参见试用额度。试用套餐不支持抵扣磁盘使用量的费用,超出512 MB的磁盘使用量将按量付费。
资源消耗评估
函数计算配置vCPU为2核、内存为16 GB、GPU显存为16 GB、磁盘大小为512 MB。1个浅休眠(原闲置)预留实例使用1小时,通过多次与LLM进行对话,1小时内累计的活跃函数时间为20分钟。产生的资源计费可参考以下表格内容:
|
计费项 |
活跃时间(20分钟)计费 |
浅休眠(原闲置)时间(40分钟)计费 |
|
|
vCPU资源 |
|
|
|
|
内存资源 |
|
|
|
|
GPU资源 |
|
|
|
更多关于函数计算的计费信息,请参见计费概述。
LLM模型列表
由于当前社区以及多种层出不穷的微调模型,本表格仅列举了当前热度较高的常用LLM基础模型,在其之上的微调模型同样是可以部署至函数计算平台,并开启浅休眠(原闲置)预留模式。
如果您有任何反馈或疑问,欢迎加入钉钉用户群(钉钉群号:64970014484)与函数计算工程师即时沟通。
|
家族 |
LLM模型 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
更多开源LLM模型请参考ModelScope。 |
|
相关文档
-
本文介绍LLM应用在使用过程中如果遇到报错,请参见ModelScope一键部署模型:新手村实操FAQ篇。
-
关于GPU实例浅休眠(原闲置)模式计费详情以及计费示例,请参见GPU计费。