
Function AI的模型服务提供了一个全托管的大模型组件,允许用户快速部署和管理AI模型。vLLM 是一款为大语言模型(LLM)设计的高性能、高吞吐量的推理引擎。本文将指导您如何在Function AI中创建一个模型服务,并选用vLLM推理引擎来部署大语言模型。
前提条件
您创建Function AI项目,用于承载即将创建的模型服务。具体操作请参见创建项目。
(可选)如果您计划使用自定义模型,请提前准备好模型文件,并将模型存储在对象存储 OSS或打包成镜像。
(可选)了解推理框架的基本特性,以便更好地进行参数配置。
操作步骤
1. 新建模型服务
登录Function AI 控制台,在左侧导航栏,选择项目,在项目列表单击目标项目名称进入项目。
在项目概览页面,依次单击。
2. 基础配置
进入创建模型服务页面后,首先进行基础配置。
参数名称 | 参数说明 | 示例 |
地域 | 选择服务部署的地域,服务部署成功后地域不可修改。 | 华东1(杭州) |
名称 | 自定义服务名称。 | test-model |
描述 | 服务的描述信息,便于识别和管理。 | description |
部署类型 | 选择模型部署方式。
| 基于推理模型框架部署 |
3. 模型配置与vLLM引擎选择
继续在创建模型服务页面,选择模型并配置推理框架为vLLM。
3.1 模型选择
您可以选择使用平台预设的模型,或指定自定义模型。
预设模型
在模型选择配置项中,选择预设模型。
从下拉列表中选择您希望部署的模型。本文以Qwen2.5-0.5B-Instruct模型为例。
选择预设模型后,系统通常会自动从ModelScope社区拉取模型,并填充模型来源为ModelScope,同时自动填写对应的ModelScope ID(例如:
Qwen/Qwen2.5-0.5B-Instruct)。
自定义模型
在模型选择配置项中,选择自定义模型,需配置模型来源。
ModelScope
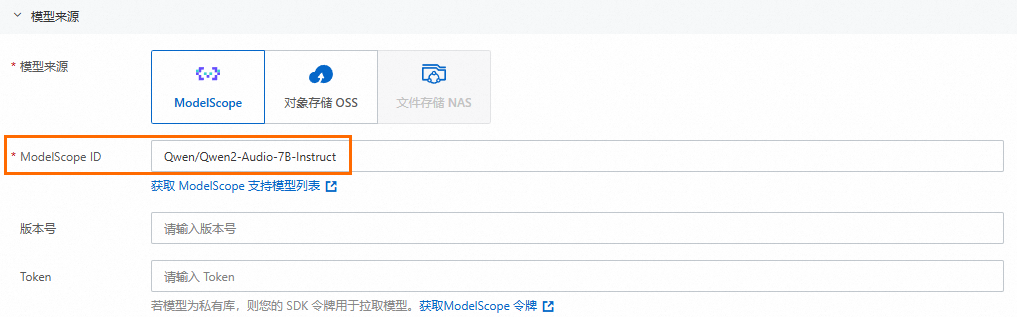
支持从ModelScope社区拉取其他未在预设列表中的模型,此时,需要您手动输入以下参数:
ModelScope ID:模型ID。
版本号:模型版本,可选。
Token:SDK令牌,仅私有模型需要,您可以登录魔搭社区获取访问令牌。
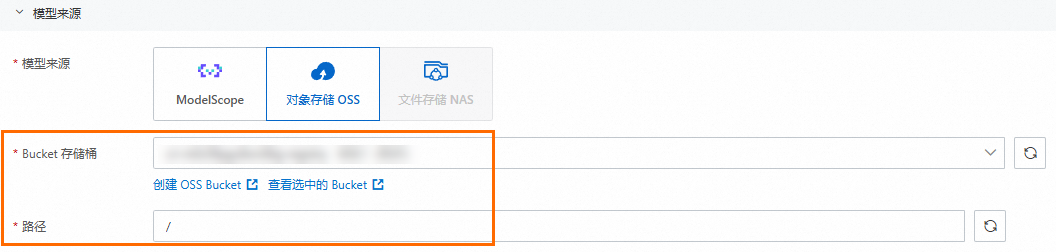
对象存储OSS
如果您的模型文件存储在对象存储OSS中,根据界面提示,选择Bucket 存储桶并设置路径。
3.2 模型存储
加载模型至NAS文件存储系统提高整体性能。
自动配置:对于预设模型,通常选择自动配置即可。系统自动选择以Alibaba-Fc-V3-Component-Generated开头的通用型NAS文件系统,如果当前账号下没有符合条件的NAS,系统自动创建。
手动配置:手动选择NAS文件系统和NAS挂载路径。更多信息,请参见配置NAS文件系统。
3.3 推理框架选择
vLLM是一款为大语言模型(LLM)设计的高性能、高吞吐量的推理引擎。本文以选择vLLM推理框架为例,进行演示。
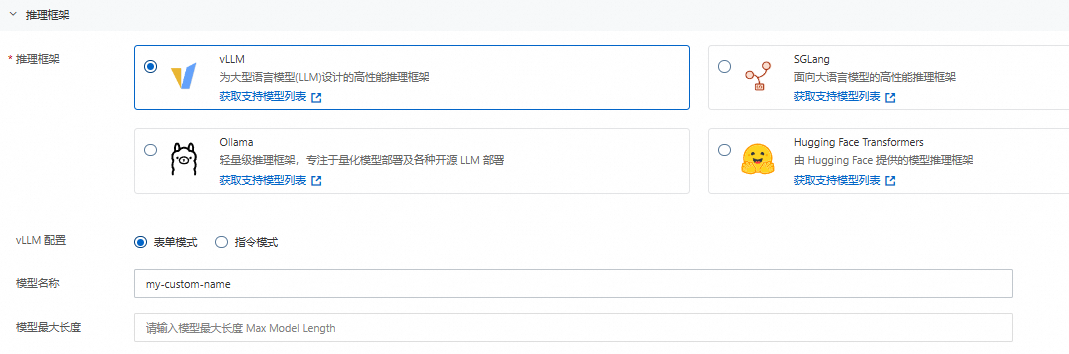
推理框架选择vLLM,然后选择vLLM配置模式。
表单模式:自定义模型名称并根据模型和应用场景设置能够处理的最大序列长度。
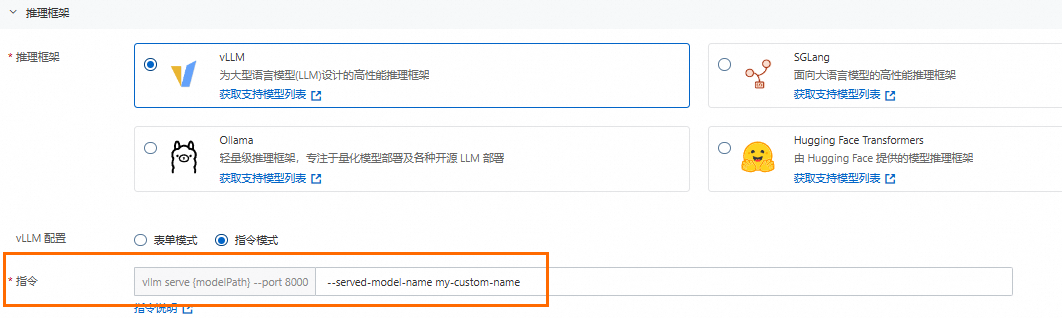
指令模式:面向更熟悉引擎启动参数的用户,指令说明请参见推理引擎参数。
4. 资源配置
4.1 选择GPU规格
根据模型的算力需求和成本预算选择合适的GPU规格,每种规格会清晰列出其GPU显存大小、vCPU核数、内存容量以及预估的单位时间费用。平台通常会提供多种规格选项。

预估费用主要供您在选型时参考,此处的GPU费用采用Serverless计费方式,最终费用以实际业务使用量为准。不同规格的库存状态也会实时显示,请根据实际可选状态进行选择。
4.2. 设置快照
对于模型托管场景,平台推荐开启快照功能,提前锁定弹性资源以获得更优的性能和响应速度。函数计算提供毫秒级和秒级快照唤醒加速,毫秒级快照冷启动效率<=1毫秒,秒级快照冷启动效率在2秒~,具体值和模型大小相关。更多信息,请参见快照简介。
快照类型:秒级快照
快照数:1
设置快照后,无论是否处理请求,都需要为启动快照少量付费,启动快照的费用远远小于弹性实例的费用,详见计费概述。
5. 角色配置
选择一个具备访问云资源(如模型存储、镜像仓库等)权限的RAM角色。通常可以选择系统默认提供的角色,如 AliyunDevsDefaultRole,或根据实际权限需求选择自定义角色。确保该角色拥有拉取模型、镜像以及其他必要操作的权限。
6. 创建并查看服务
完成以上所有配置后,仔细检查各项参数,确认无误后,单击预览&部署按钮。
在弹出的对话框,预览部署本服务涉及的资源,确认无误后单击确认部署。
系统开始创建并部署模型服务。您将被引导至服务详情页,此时可以查看服务的部署状态,例如部署中或运行中。
等待服务状态变为运行中,即表示模型服务已成功部署并基于vLLM推理引擎运行。
后续操作
获取服务访问凭证与API:服务部署成功后,您可以在服务详情页找到API Endpoint以及调用服务所需的认证信息。
进行推理测试:使用API工具或SDK调用模型服务,验证模型推理功能是否正常。
监控与管理:利用Function AI平台提供的监控功能,查看服务的运行状态、资源使用情况和日志信息。
更新与调整:根据业务需求,您可以随时返回服务配置页面,调整模型版本、资源配置或推理参数。