您可以根据按量模式和预留模式的实例总数及对应的实例扩容速度的限制信息配置弹性伸缩规则。在预留模式下,您可以通过定时伸缩和水位伸缩两种方式解决预留实例利用不充分的问题。
实例伸缩行为
在处理函数调用请求时,函数计算会优先使用已有的可用实例。若当前实例已经满载,函数计算会创建新的实例来处理请求。随着调用请求量的增加,函数计算会持续创建新的实例,直到有足够的实例处理请求或者达到您设置的实例数上限。在实例扩容的过程中,将受到扩容速度限制,具体请参见各地域实例扩容速度限制。
当函数调用请求增加时,按量模式和预留模式的实例伸缩行为如下。配置预留实例后,可以提前准备好函数实例,从而避免实例冷启动带来的请求延时问题。
按量模式实例伸缩
当实例总数或者实例扩容速度超过限制后,函数计算将返回流控错误(HTTP Status为429)。下图展示在一个调用量快速增长的场景下,函数计算的流控行为。
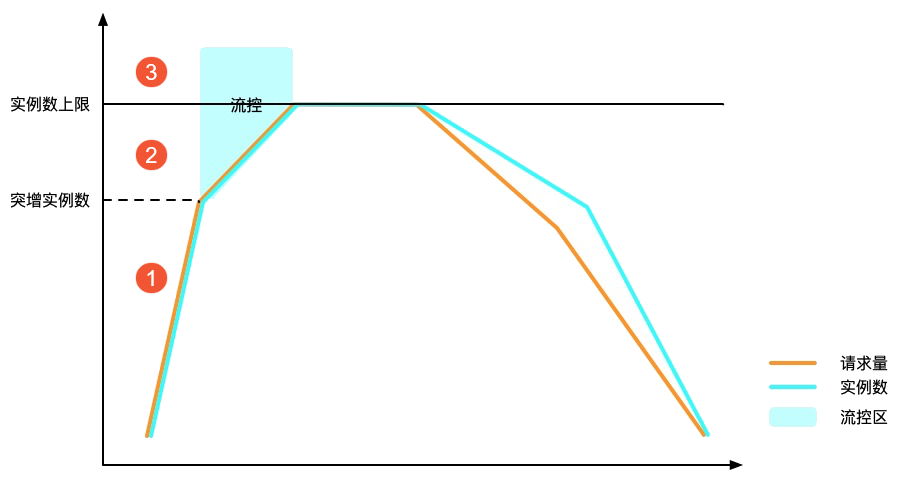
图示中①:在达到突增实例数前,函数计算立即创建实例,这个过程中有冷启动,但没有流控错误。
图示中②:达到突增实例数后,实例数的增长受速度限制,部分请求会收到流控错误。
图示中③:实例数超过限制后,部分请求收到流控错误。
预留模式实例伸缩
当突发的调用量较大时,大量的实例创建会受到流控限制导致请求失败,实例的冷启动也会增加请求延时。为避免这些问题,您可以使用函数计算的预留实例,即提前准备好函数实例。
与按量模式实例相同的负载场景下,使用预留实例后的流控行为如下。
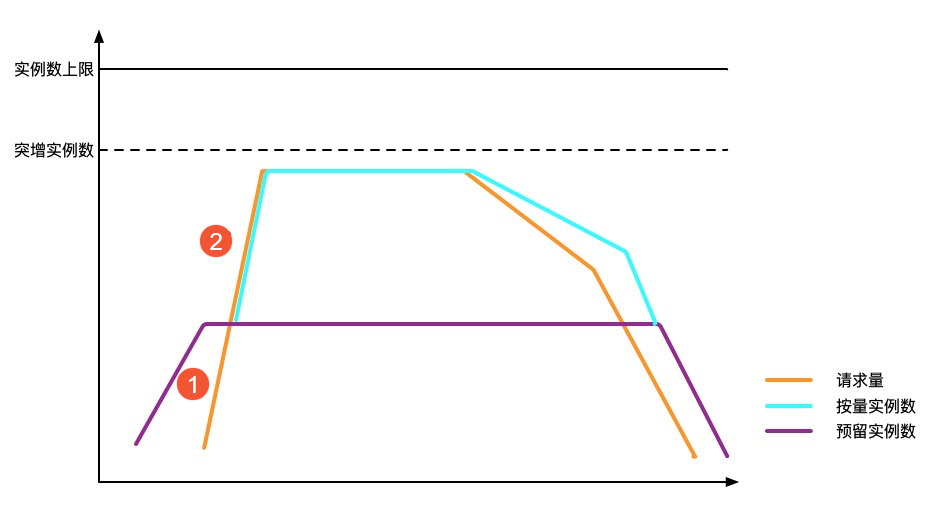
图示中①:在预留实例被用满之前,请求立即被执行,这个过程既没有冷启动,也没有流控错误。
图示中②:在预留实例被用满后,按量实例达到突增实例数之前,函数计算立即创建实例,这个过程中有冷启动,但没有流控错误。
各地域实例扩容速度限制
地域 | 突增实例数 | 实例增长速度 |
华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华南1(深圳) | 300 | 300/分钟 |
其他 | 100 | 100/分钟 |
相同地域下,预留模式和按量模式的实例扩容速度限制一致。
GPU实例的扩容速度小于CPU实例,建议配合预留模式使用。
如果您对扩容速度有更高的需求,请加入钉钉用户群(钉钉群号64970014484)申请。
预留实例自动弹性伸缩
为预留实例配置固定的预留值可能会导致预留实例利用不充分的问题,您可以通过配置定时伸缩和水位伸缩两种方式解决该问题。
如果同时设置了定时伸缩和水位伸缩,最终会以这些伸缩规则得到的最大值作为预留实例数。
定时伸缩
适用场景
函数有明显的周期性规律或可预知的流量高峰。当函数调用并发大于定时预留值时,超出的部分会分配至按量模式的函数实例。
配置示例
配置两个定时操作:在函数调用流量到来前,通过第一个定时配置将预留实例扩容至较大的值;当流量减小后,通过第二个定时配置将预留实例缩容到较小的值。具体如下图所示。
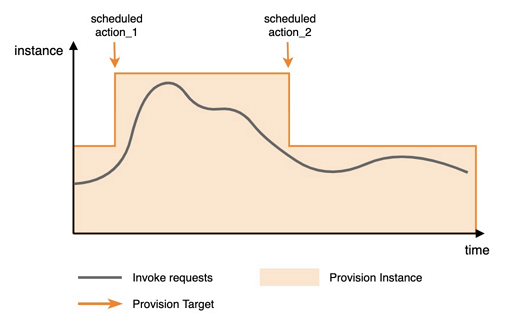
在使用PutProvisionConfig API配置定时伸缩的请求参数时可参考以下信息。为函数function_1配置定时伸缩策略,指定时区为Asia/Shanghai,即北京时间,配置的生效区间为2024-08-01 10:00:00至2024-08-30 10:00:00(北京时间),在每天20:00(北京时间)将预留函数实例扩容至50,在每天22:00(北京时间)再将预留函数实例收缩至10。
"scheduledActions": [
{
"name": "scale_up_action",
"startTime": "2024-08-01T10:00:00",
"endTime": "2024-08-30T10:00:00",
"target": 50,
"scheduleExpression": "cron(0 0 20 * * *)",
"timeZone": "Asia/Shanghai"
},
{
"name": "scale_down_action",
"startTime": "2024-08-01T10:00:00",
"endTime": "2024-08-30T10:00:00",
"target": 10,
"scheduleExpression": "cron(0 0 22 * * *)",
"timeZone": "Asia/Shanghai"
}
]Cron表达式说明
水位伸缩
适用场景
函数计算系统周期性采集预留的函数实例并发利用率或实例的资源利用率指标,使用指标并结合您配置的最小预留实例数、最大预留实例数来控制预留模式函数实例的伸缩,使预留的函数实例量更好的贴合资源的真实使用量。
配置示例
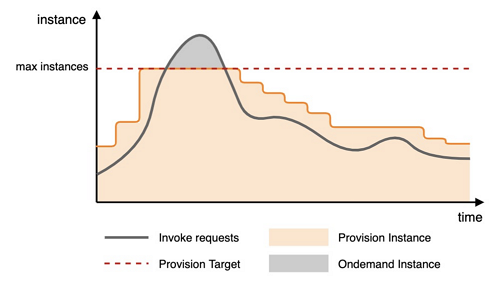
以预留实例并发利用率指标伸缩为例:当流量不断增加时,触发扩容阈值,预留模式的函数实例开始扩容,当达到设置的最大值时停止扩容,超出部分的请求分配至按量模式函数实例;当流量不断减小时,触发缩容阈值,预留模式的函数实例开始缩容。具体如下图所示。
使用预留模式的水位伸缩时,必须开启实例级别指标功能,否则会报错
400 InstanceMetricsRequired。关于开启实例级别指标的方法,请参见配置实例级别指标。预留实例的并发利用率只统计预留模式的并发情况,不包含按量模式的数据。
预留实例的并发利用率为预留模式函数实例正在响应的请求并发值与所有预留函数实例最大可响应并发值的占比,数值范围为[0,1]。
在使用PutProvisionConfig API配置水位伸缩的请求参数时可参考以下信息。为function_1函数配置水位伸缩策略,指定的时区为Asia/Shanghai,即北京时间,配置的生效区间为2024-08-01 10:00:00至2024-08-30 10:00:00(北京时间),追踪预留模式函数实例并发利用率ProvisionedConcurrencyUtilization指标,并发利用率追踪值为60%,超过60%时开始扩容,扩容上限为100;并发利用率低于60%时开始缩容,缩容下限为10。
"targetTrackingPolicies": [
{
"name": "action_1",
"startTime": "2024-08-01T10:00:00",
"endTime": "2024-08-30T10:00:00",
"metricType": "ProvisionedConcurrencyUtilization",
"metricTarget": 0.6,
"minCapacity": 10,
"maxCapacity": 100,
"timeZone": "Asia/Shanghai"
}
]扩缩容计算原理
缩容时会通过缩容系数来实现相对保守的缩容过程,缩容系数取值范围为(0,1]。缩容系数为系统参数,用于减缓缩容速度,防止缩容过快,您无需设置。扩缩容目标值对计算结果向上取整得到最终结果,计算逻辑如下。
扩容目标值=当前预留模式的函数实例数×(当前指标值/设置的利用率阈值)
缩容目标值=当前预留模式的函数实例数×缩容系数×(1-当前指标值/设置的利用率阈值)
计算示例:
当前指标值为80%,设置的利用率阈值为40%,当前预留模式的函数实例数为100,经过计算100×(80%/40%)=200。预留模式的函数实例数会扩容到200(不能超出设置的最大预留实例数),以保证扩容后利用率阈值维持在40%附近。
最大可响应并发值
不同的实例并发数,函数实例可响应的最大并发值计算逻辑如下:
单实例单并发
最大可响应并发值=函数实例数量
单实例多并发
最大可响应并发值=函数实例数量×单实例并发度
关于实例并发度的应用场景、优势、配置及影响,请参见设置实例并发度。