
Google在2024年02月21日正式推出了首个开源模型族Gemma,并同时上架了2b和7b两个版本。您可以使用函数计算的GPU实例以及函数计算的闲置模式低成本快速部署Gemma模型服务。
前提条件
操作步骤
部署Gemma模型服务的过程中将产生部分费用,包括GPU资源使用、vCPU资源使用、内存资源使用、磁盘资源使用和公网出流量以及函数调用的费用。具体信息,请参见计费概述。
创建应用
请根据下列步骤,获取ACR仓库的域名和仓库地址。
登录容器镜像服务控制台,选择函数所在的地域,点击目标企业版实例卡片中的管理。
在左侧导航栏点击访问控制,然后选择公网页签。如果访问入口的开关处于关闭状态,请打开开关。如果您希望任何公网机器均可登录您的仓库,请删除所有公网白名单。否则,请根据您的情况设定公网白名单。完成后,请保存该ACR实例的域名地址。
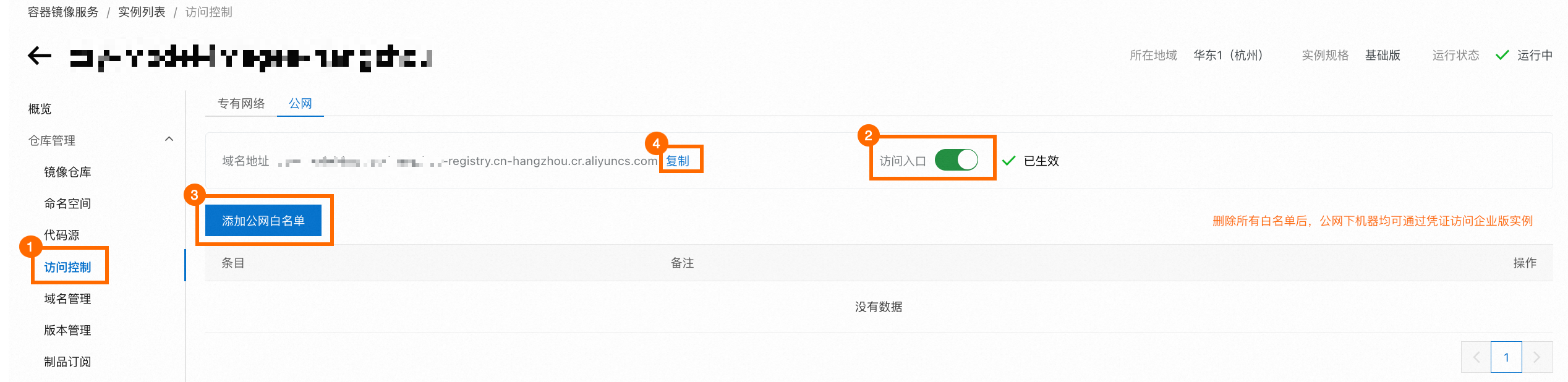
在左侧导航栏点击ACR 镜像仓库,然后点击目标仓库的仓库名称,进入仓库详情页面。
请保存该仓库的公网地址。

下载Gemma模型权重。您可以选择从Hugging Face或ModelScope平台下载,本文以从ModelScope下载Gemma-2b-it模型为例,详情请参见Gemma-2b-it。
重要如果您使用Git下载模型,请先安装Git扩展LFS后,执行
git lfs install初始化Git LFS,然后再执行git clone进行下载。否则,由于模型过大,可能导致下载的模型不完整,无法正常使用Gemma服务。创建Dockerfile文档和模型服务代码文件
app.py。Dockerfile
FROM registry.cn-shanghai.aliyuncs.com/modelscope-repo/modelscope:fc-deploy-common-v17 WORKDIR /usr/src/app COPY . . RUN pip install -U transformers RUN pip install -U accelerate CMD [ "python3", "-u", "/usr/src/app/app.py" ] EXPOSE 9000app.py
from flask import Flask, request from transformers import AutoTokenizer, AutoModelForCausalLM model_dir = '/usr/src/app/gemma-2b-it' app = Flask(__name__) tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto") @app.route('/invoke', methods=['POST']) def invoke(): request_id = request.headers.get("x-fc-request-id", "") print("FC Invoke Start RequestId: " + request_id) text = request.get_data().decode("utf-8") print(text) input_ids = tokenizer(text, return_tensors="pt").to("cuda") outputs = model.generate(**input_ids, max_new_tokens=1000) response = tokenizer.decode(outputs[0]) print("FC Invoke End RequestId: " + request_id) return str(response) + "\n" if __name__ == '__main__': app.run(debug=False, host='0.0.0.0', port=9000)关于函数计算支持的所有HTTP Header,请参见函数计算公共请求头。
完成后代码目录结构如下所示。
. |-- app.py |-- Dockerfile `-- gemma-2b-it |-- config.json |-- generation_config.json |-- model-00001-of-00002.safetensors |-- model-00002-of-00002.safetensors |-- model.safetensors.index.json |-- README.md |-- special_tokens_map.json |-- tokenizer_config.json |-- tokenizer.json `-- tokenizer.model 1 directory, 12 files依次执行以下命令构建并推送镜像。其中
{REPO_ENDPOINT}是步骤1中目标镜像仓库的公网地址,{REGISTRY}是ACR实例的域名地址。IMAGE_NAME={REPO_ENDPOINT}:gemma-2b-it docker login --username=mu****@test.aliyunid.com {REGISTRY} docker build -f Dockerfile -t $IMAGE_NAME . docker push $IMAGE_NAME重要当使用Apple芯片的Mac系统构建镜像时,请将第3行的
docker build命令替换为使用以下命令,以构建兼容函数计算的镜像。docker build --platform linux/amd64 -f Dockerfile -t $IMAGE_NAME .创建函数。
待上一步创建的函数的状态变更为函数已激活时,您可以为其开启闲置预留模式。

在函数详情页面选择配置页签,在左侧导航栏,选择预留实例,然后单击创建预留实例数策略。
在创建预留实例数策略面板中,版本或别名选择LATEST,预留实例数设置为1,闲置模式选择启用,然后单击确定。

待当前预留实例数变更为1,且您可以看到已开启闲置模式的字样,表示GPU闲置预留实例已成功启动。

使用Google Gemma服务
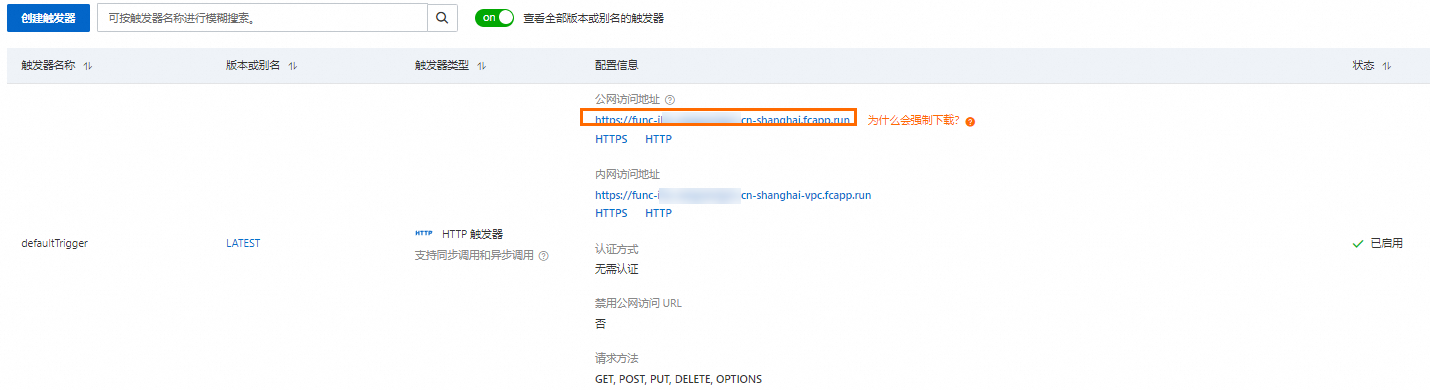
在函数详情页面,选择配置页签,然后在左侧导航栏,选择触发器,在触发器页面获取触发器的URL。

执行以下命令调用函数。
curl -X POST -d "who are you" https://func-i****-****.cn-shanghai.fcapp.run/invoke预期输出如下。
<bos>who are you? I am a large language model, trained by Google. I am a conversational AI that can understand and generate human language, and I am able to communicate and provide information in a comprehensive and informative way. What can I do for you today?<eos>在函数详情页面,选择实例页签,在实例页面单击目标实例ID右侧操作列的实例指标,在实例详情页面的实例指标页签查看指标情况。
您可以看到在没有函数调用发生时,该实例的显存使用量会降至零。而当有新的函数调用请求到来时,函数计算平台会迅速恢复并分配所需的显存资源。从而达到降本效果。
说明查看指标的实例,需要先启用日志功能,具体请参见配置日志功能。
函数调用结束后,函数计算会自动将GPU实例置为闲置模式,您无需手动操作。在下次调用到来之前,函数计算将该实例唤醒,置为活跃模式进行服务。
删除资源
如您暂时不需要使用此函数,请及时删除对应资源。如果您需要长期使用此应用,请忽略此步骤。
返回函数计算控制台概览页面,在左侧导航栏,单击函数。
单击目标函数右侧操作列的,在弹出的对话框中,勾选我确认要删除以上资源,并同时删除此函数。我已知晓这些资源删除后将无法找回,然后单击删除函数。
费用说明
相关文档
关于Google发布的开源模型族Gemma的更多详情,请参见gemma-open-models。
关于GPU实例闲置模式计费详情以及计费示例,请参见计费概述。