
在交易、注册拉新场景,我们会经常面临黄牛账号的困扰,影响拉新效果和新用户的权益保证。针对这种业务场景,我们基于丰富表的图数据关系,通过OneID快速识别和定位黄牛账号、判定新人拉新规范,从而进一步赋予业务更准确和可解释的防控手段。
为了方便用户能够熟悉图计算服务GraphCompute,我们提供一份完整的OneID-黄牛账号识别Demo数据、查询Query和文档指南,帮助用户快速搭建一个图计算应用,并提供百万级别数据量的黄牛账号识别和挖掘能力。
什么是GraphCompute?
GraphCompute 是一个分布式的、万亿级数据规模下、高性能、高稳定性的图查询和计算解决方案。同时,搭载智能运维和离线系统,实现湖仓一体化的数据打通,支持多版本数据快速迭代和管理能力。结合阿里巴巴在电商、安全和社交等多个行业领域的积累,为全球企业及开发者提供图技术服务
背景介绍
数字经济时代下,数据成为推动创新发展的关键要素。数据的开放,推动了多行业、跨组织的协同与创新,催生出新型的产业形态和商业模式。但随着数据价值的凸显,针对数据的攻击、窃取、滥用、劫持等活动持续泛滥,并呈现出产业化、高科技化等特性。在互联网企业,对于识别、追踪用户身份都有强烈的需求,通过用户的账号、设备之间信息关联,能够快速识别账户情况,做出更好的业务联动或者防护。在该类场景下,我们统一定义为OneID账户同人识别。
什么是OneID?
简单来说OneID是一套跨屏、跨域的自然人身份识别、追踪系统,类似于实际生活中的身份证号,对于每个互联网世界的每个自然人都通过算法赋予一个稳定的虚拟身份ID
- OneID,并且识别自然人所拥有的各类身份ID。 身份ID包括三大类:
- 账号类:业务账号,手机号,Email等等
- 设备类:设备IMEI,设备IMSI,设备IDFA,
- cookie类:Acookie等等。
OneID体系能够将稀疏的信息通过实体之间的关系汇聚起来,聚焦到自然人,譬如从重要设备ID能够关联出大量的账号ID,说明这些账号可以属于一个人或者团伙共有,并挖掘出业务平台的黄牛或者非法团伙信息。
为什么用“图”做风险挖掘?
图能够高效表达关系和行为,业界通过图计算相关技术能够沉淀归类部分图模型和关系。而我们可以通过其中的关系现象进行对应的数据建模,就能将痕迹归纳总结,应用于欺诈防控。此外,传统的欺诈检测通常关注特征空间中的离群点,而忽略了现实世界中的关系数据。在现实生活中,实体之间有着丰富的关系,图结构可以为欺诈检测提供信息增益。
【黄牛账号识别】业务落地
业务背景
某款科技公司网站,主要售卖各种AI数字化产品和解决方案,针对活动都会发放优惠券权益,但是主要希望能对网站的注册账户做OneID风控识别,帮助公司挖掘黄牛账号、薅羊毛团伙,减少无效资金损失。
通过对黄牛党或者团伙行为分析,普遍的现象是最大程度的利用手上设备资源,实现账号体系的最大化;针对有部分用户通过重复注册账号领取优惠券薅羊毛的行为进行检测,需要进行用户到用户的多度查询;
根据业务的特点进行抽象定义,最终的业务逻辑可以理解为:
1)查询的业务场景:账户A - 设备G - 账号B 二跳关系
2)需要获取多种设备关联的二跳用户后,对设备路径权重加分,最终得到
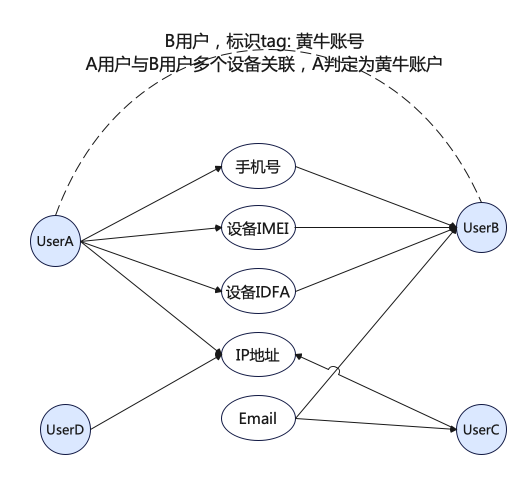
业务梳理
基于图数据在交易欺诈、垃圾注册场景下,我们就能够OneID快速识别和定位黄牛账号、新人拉新判定,从而进一步赋予业务更准确和可解释的防控手段。
首先从离线算法出发:探索的路线从图传播算法——>图聚类算法——>图表征算法,挖掘更大范围,更深层次的风险。最开始使用图传播算法,可以快速地挖掘出少量风险实例且较高的准确率效果,但是半监督的图传播算法只能从局部出发,挖掘出已知风险实体附近的少量风险实体。如何能够从全局出发,扩大风险实例的召回,这时候开始使用图聚类算法去挖掘风险团伙。除了图结构可以帮助挖掘风险外,实体的属性也可以帮助挖掘风险。充分结合账号的违规、处罚、行为特征以带来更多的信息增益,帮助挖掘更深层次的风险。
当前我们重点讲解的「黄牛账号识别」,该类风控场景就可以通过下图第一步【图传播算法】,从当前已经风险的节点往外传播影响决策能力,挖掘出高风险节点,以及对应的风险分数。
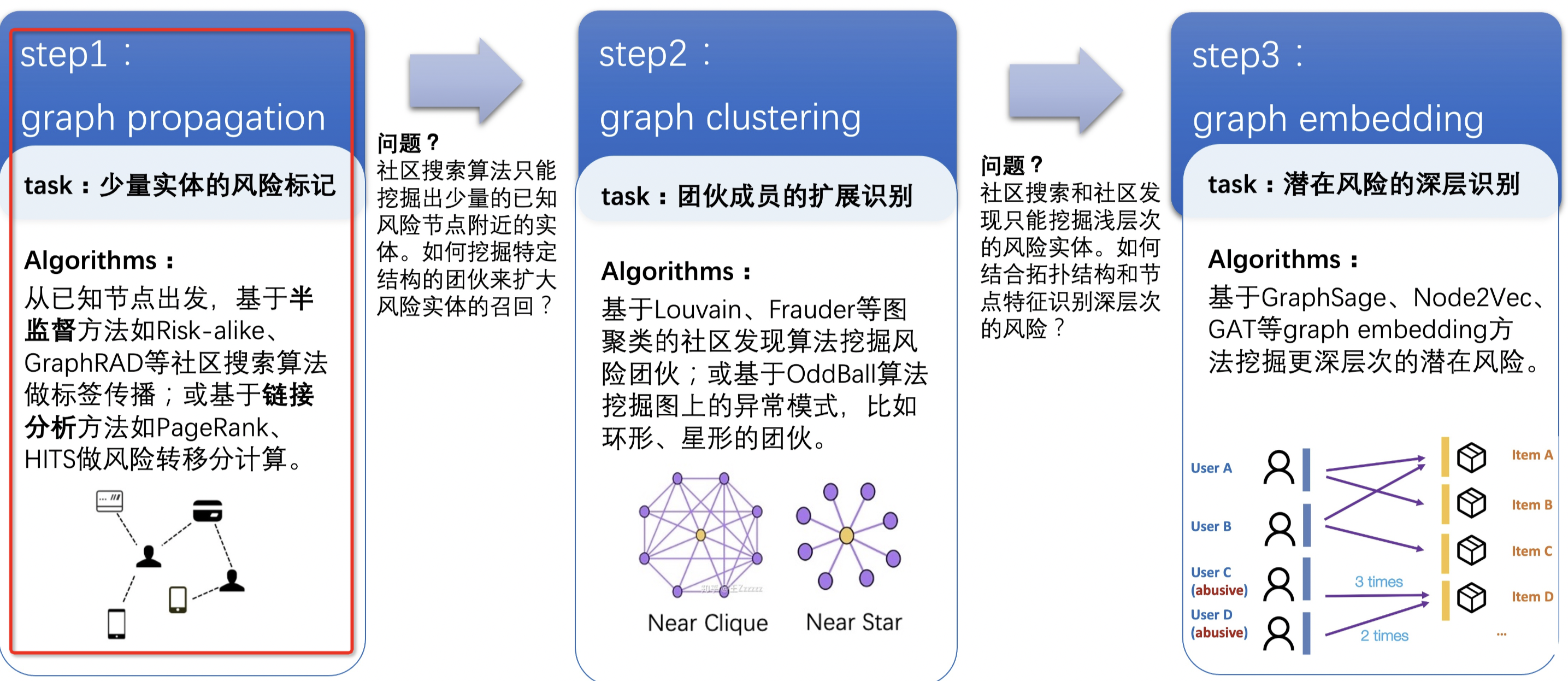
Step1:日志数据梳理
用户登录、注册信息进行日志收集,将用户的登录记录进行
定义数据:确认数据源,定义每个数据源返回的数据格式、字段
SLS日志收集,原始的数据信息包括:
用户登录信息
用户注册信息
cookie信息
数据标准化及映射:有一个专门的平台可以定义数据源数据到表中数据的映射,并允许对数据进行脚本化处理
【用户信息表】
注册账号、时间等有效信息
【设备信息表】
设备类型:手机、IP地址、email 等信息
事件触发增量写入:当事件发生,触发一个向对应表内写的增量信息
新用户注册登录后,进行数据输出,最终将进行【用户信息表】和【设备信息表】对应信息更新
持久化:引入MaxCompute,存储离线全量
Step2:离线算法选择
Community Search根据网络中给出的已知种子节点的局部信息出发,去发现给定种子节点所在的局部社区,具有更强的社区针对性,是一种图传播的方法。可以使用半监督方法,基于已有的有标记的节点,为附近的无标记的节点打上伪标签,并不断迭代预测更多的无标记节点。
在反作弊时,通常只获取到少量有标签数据。同时,需要大量的无标签数据,这些无标签数据中存在着大量的风险实例,如何从大量的无标签数据中,挖掘风险实例,是该场景需要解决的问题。这里构建半监督学习的流程,基于业务提供的风险数据作为原始输入,挖掘风险数据周边的高风险实例,并将挖掘的实例反馈给业务校验,接下来将业务校验认为有风险的实例添加到原始输入中,继续迭代,从而召回更多的风险数据。半监督方法只能挖掘有限有标签附近的样例,无法发现特定结构的团伙.
工业界比较知名的基于半监督关系网络图上的风险实体挖掘方法有亚马逊在2018年提出的GraphRAD方法和蚂蚁集团在2021年提出的Risk-alike方法,这两种方法都是基于黑种子节点的输入在图上挖掘风险。也可以使用链接分析的方法,如PageRank,从已有的有标记的节点出发,计算网络中其他节点的重要程度。
例如:
Risk_alike
输入:黑种子节点,所有的边关系
step1:构图:基于与黑种子点有2跳以内关联关系的节点构图;
step2:用louvain做社区发现得到风险团伙,并对跟团伙有两跳以内关联的节点做召回;然后用规则筛选黑节点占比>=40%且节点数量<=200的团伙;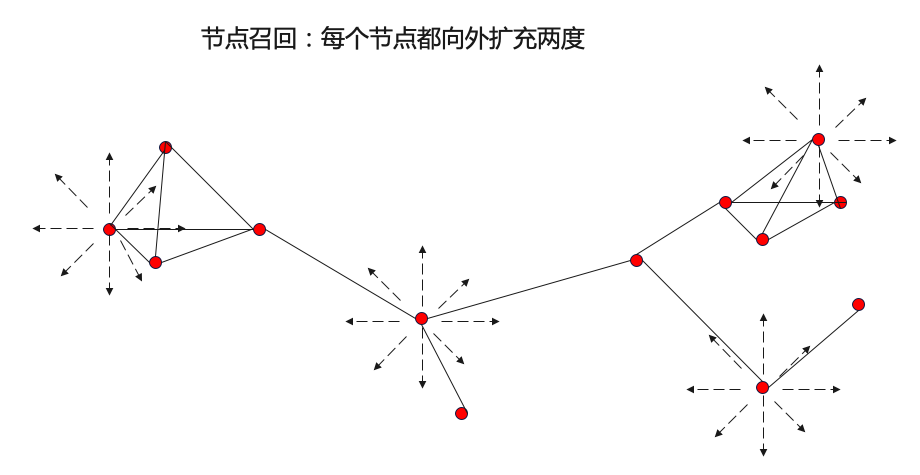
step3:基于pageRank计算每个节点的风险分并排序。从黑种子节点出发,计算每个节点对黑种子节点的重要程度,作为风险分;
step4:提纯Purify:基于louvain社区发现的结果和pageRank的结果筛选并输出挖掘的高风险节点。
输出:挖掘出的高风险节点,以及对应的风险分数。
阿里云训练平台PAI中已内置了Risk-alike、Louvain、LPA、PageRank等反作弊算法,可直接调用即可。最终结果产出:【用户信息表】注册账号、时间等有效信息、【新增】用户团伙标签 isbad = true | false
Step3:业务模型的梳理和沉淀
根据对前面业务逻辑的了解,我们设计了多种图配置的业务模型来做相应的图构建;
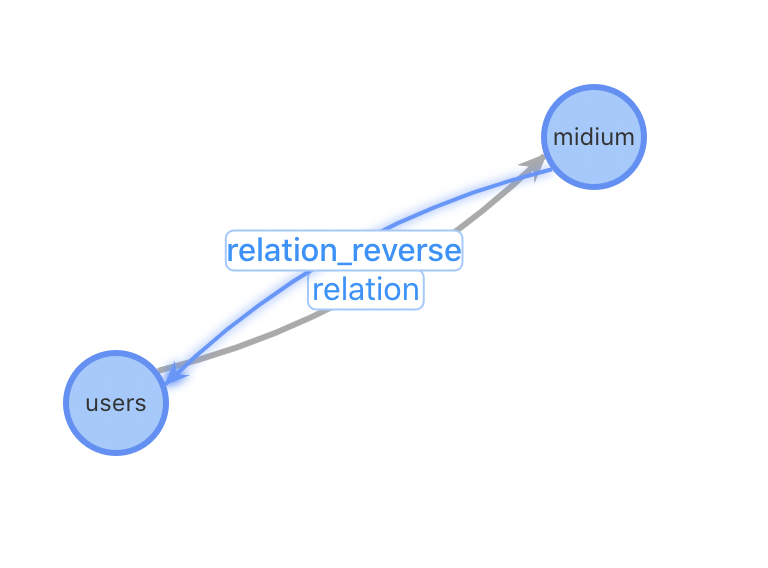
【方案一】 | 【方案二】 | 【方案三】 |
|
|
|
特点:relation异构表 与原始的数据结构最贴近、表配置量过多 | 特点:relation同构表 图配置简单,只需要2张表:User用户表和设备关联表 | 特点:增加设备作为独立节点 对于热门设备的关系变更更加友好 |
问题:设备类型不能灵活增加,设备关系表需要人工添加,不利于扩展性 | 问题:对于插入一个新用户,需要先进行一(多)次查询找到相关的用户关系才能进行插入 | 问题:牺牲一些查询性能,增加了设备到用户查询 |
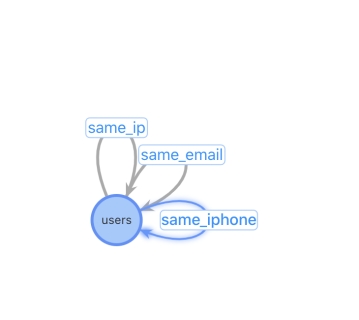
Step4:业务模型优化方案
基于业务考量,最终业务配置模型选择了【方案三】来支持,主要的考虑如下:
总结一:进行起点为指定medium类型的快速检索,通过type类型进行过滤和统计计算更方便
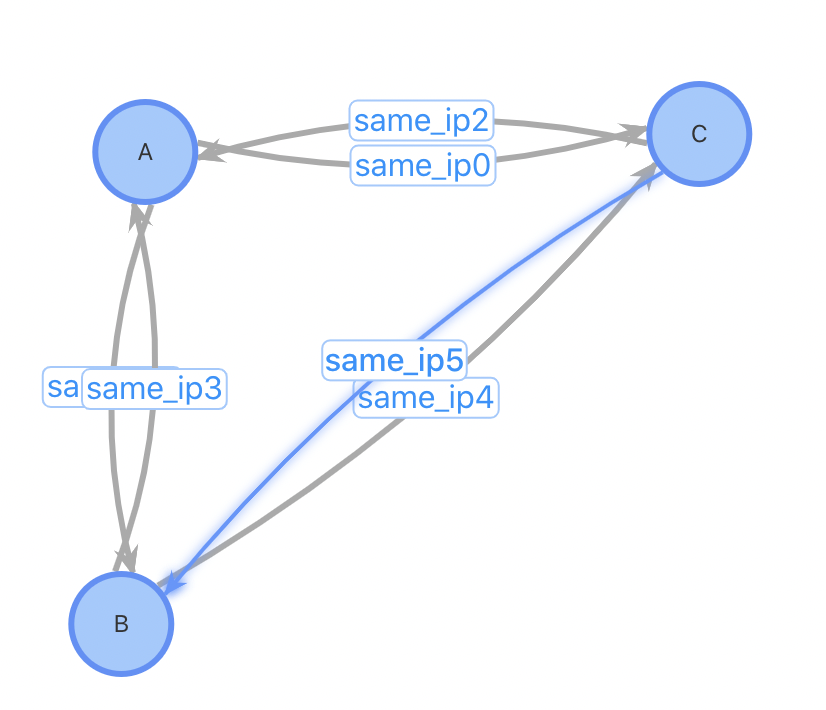
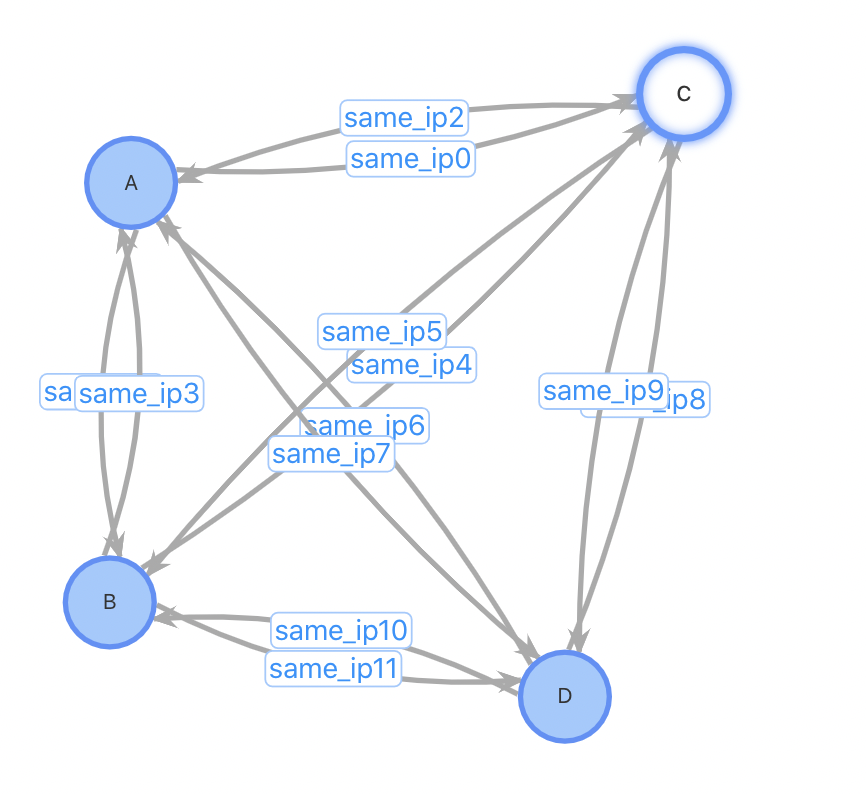
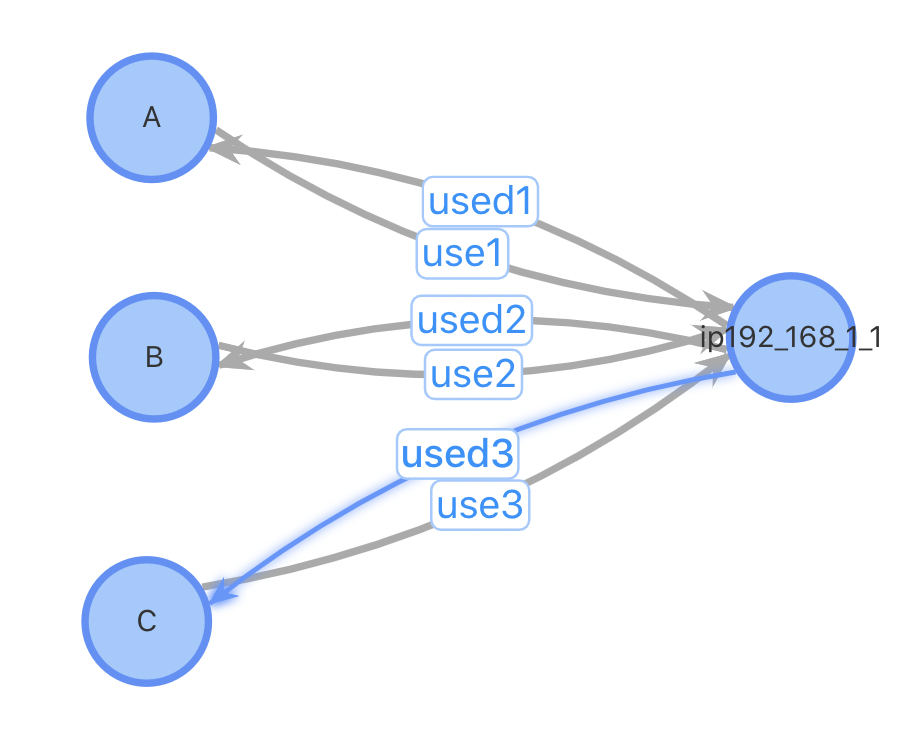
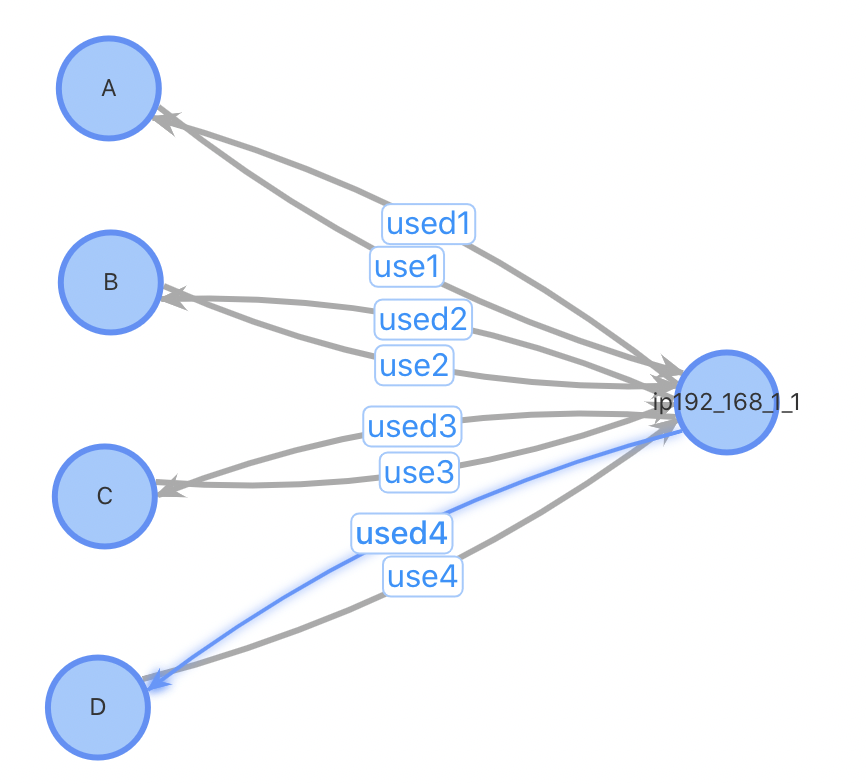
总结二:插入性能优;对于插入一个新用户,设计1、2需要先进行一(多)次查询找到相关的用户关系才能进行插入,设计3不需要这个步骤;设计1、2需要进行一次点插入和多次边插入,设计3只需1次点插入和2次边插入。对于某些热门的IP,一个使用热门IP的新用户插入需要插入数万条边,对系统的开销会很大。考虑以下case:插入用户D,已有3位用户ABC使用与D相同的IP
方案1、2:插入用户点D,查询与D使用同IP的所有用户,插入边。插入前,3条点数据,6条边数据;插入后4个点,12条边数据
方案3:插入用户点D,如果该IP不存在表中,插入IP点192.168.1.1,插入用户D到IP点之间的正反向边。插入前,4条点数据,6条边数据;插入后4(5)个点,8条边数据。
|
|
|
|
主要问题在于牺牲查询性能:用户到用户的跳数从1跳增加到2跳,综合考虑总结如下:通过【方案三】可以更好的简化离线更新链路的逻辑,同时对于性能影响不会太大。
GraphCompute搭建
Step1:图模型确定
根据前面的业务梳理和沉淀,我们最终按照【方案三】进行图配置,包括节点表User、medium设备表、relation 用户设备关系表。
Step2:选择适合自己的数据源方式
请根据自己的业务特点进行选择:
已是或者未来需要MaxCompute,源数据托管到MaxCompute,同时业务数据需要做24小时实时计算更新图数据 - 请参考【方案一:MaxCompute数据源 + API数据】 --- 最佳推荐方式
数据直接托管到图计算GraphCompute,支持业务数据通过API方式,支持24小时实时数据更新 - 请参考【方案二:API数据源】
已是MaxCompute资深用户,源数据托管到MaxCompute,每天定时产出MaxCompute分区,无需对图数据做24小时增量更新 - 可选择【MaxCompute数据源】
Step3:【黄牛账号识别】- 创建数据源
当前我们的快速接入采用【方案一:MaxCompute源数据表 + API数据】、【方案二:API数据源】
【方案一:MaxCompute源数据表 + API数据】
该方案依靠MaxCompute已有项目和源表数据。
如果没有现成的数据,可以选择直接使用我们提供的Demo数据源(已经定义好了节点和关系数据)。
如果业务数据已经存在CSV或者MaxCompute中,可以选择自己的MaxCompute源数据。
用户源表:
使用【igraph_mock.anti_cheating_demo_user_vertex】,节点表中包括100000个用户,其中有1%的风险账户(isbad=TRUE)
可参考的MaxCompute建表语句:
isbad字段可以根据需要添加,用于标示一些已知的黄牛用户。
根据需要可以加入更多的用户信息字段,例如名字、性别、注册时间等以满足其他业务逻辑的需要。
CREATE TABLE IF NOT EXISTS anti_cheating_demo_user_vertex ( user_id BIGINT COMMENT '用户账号id' ,isbad BOOLEAN COMMENT '是否为风险账号' ) COMMENT '用户顶点表' PARTITIONED BY (ds STRING COMMENT '日期分区');
媒介表
使用【igraph_mock.anti_cheating_demo_medium_vertex】,关系表中包括100000个媒介,其中0.3%的媒介被超过1个用户使用。
可参考的MaxCompute建表语句:
常见的medium_type包括电话号码、邮箱、IP、设备等,本例中只包括电话号码和邮箱。
weight用于表示媒介的重要性,一般来说同一种设备的weight可以使用同样的值。例如:多个用户使用同一IP不需要特定区分。
CREATE TABLE IF NOT EXISTS anti_cheating_demo_medium_vertex ( medium_id BIGINT COMMENT '媒介id' ,medium_type STRING COMMENT '媒介类型' ,weight double COMMENT '权重' ) COMMENT '媒介顶点表' PARTITIONED BY (ds STRING COMMENT '日期分区');
用户媒介关系表
使用【igraph_mock.anti_cheating_demo_medium_edge】,关系表中包括100000个媒介,其中0.3%的媒介被超过1个用户使用
可参考的MaxCompute建表语句:
score主要用于表示用户使用媒介的频繁程度/重要性,可以根据业务逻辑进行赋值,如没有特殊业务逻辑可以默认设置为1。
CREATE TABLE IF NOT EXISTS anti_cheating_demo_user_medium_edge
(
user_id BIGINT COMMENT '用户账号id'
,medium_id BIGINT COMMENT '媒介id'
,score double COMMENT '权重'
)
COMMENT '用户媒介关系边表'
PARTITIONED BY (ds STRING COMMENT '日期分区');【方案二:API数据源】
该方案依靠用户服务端SDK或者控制台写入窗口进行数据写入和更新。
控制台写入窗口可参考:【图运维 - 选择User、Relation后右键 - 增量数据写入。
【MaxCompute源表操作指南】
业务可参看如下步骤自行创建MaxCompute数据表:
在DataWorks创建数据表,每一种点表和边表需要有一张自己单独的数据表。
进入DataWorks,左上角选择数据开发。
进入业务流程->MaxCompute->表,右键新建表,并输入表的名字。
在弹出的新建表对话框中,引擎类型默认为MaxCompute,输入表名称即可。
设置表的属性。
项目名及表名(重要):
不可更改,记下项目名(MaxCompute引擎实例)及表名,需要给图计算账号授权。
基本属性中文名:可以设置表的中文名字和描述。
物理模型设计:
分区类型:请选择分区表。
生命周期:设置生命周期意味着表的每个分区会保留xx天后被自动删除,请按照需要勾选 。
表结构设计:请逐列添加表的列属性,主要包括列名、类型和是否为主键。字段类型的选择请尽量贴合字段本身的属性(例如:在精度要求不高的情况下使用float代替double类型、对于数字类型的ID使用int类型代替string类型),这样有助于减少数据表构建索引的大小,节约数据回流生效的时间。
警告注意:图计算目前字段类型有所限制,仅支持MaxCompute 1.0、2.0的基础数据类型,不支持复杂类型(ARRAY、MAP、STRUCT),具体字段类型定义及取值范围请参考2.0数据类型版本。
Step4:【黄牛账号识别】- 创建图计算服务
Step4-1:购买实例链接
地域:为了减少网络延迟,请尽可能选择靠近您的位置。
用户名/密码:用于请求时的访问验证。
规格:请根据您的数据量及请求的复杂程度选择规格。
推荐选择独享通用型
如果您的业务计算需求较为复杂或对返回性能的要求较高,建议增加分片数
规格参考:
一般百万级数据量级,可参考如下配置即可。
推荐选择独享通用型规格族,规格为本地SSD型(4核CPU、16 GB内存、240 GB磁盘),副本数设为2,分片数设为1。
如果数据量过大,可增加【分片数】。
如果线上查询流量加大,可以增加【副本数】。
购买完毕之后需要等待【15分钟】实例初始化完毕。
购买活动:企业认证用户新客首购可以参加免费一个月活动。
Step4-2: 创建业务的图模型
根据前面【Step1】中已总结完该场景的业务图模型,我们这里就可以直接创建;在右侧列表选择“图列表”,并点击新增,输入图的名字及描述。
Step4-3: 创建节点表
创建节点表【User】
左上角选择“新增点”并输入点的名称。
选择数据来源为【MaxCompute数据源+API更新】
输入MaxCompute项目名和表名
用户源表:使用【项目名:igraph_mock,表名:anti_cheating_demo_user_vertex】
点击【导入字段】会自动为您导入MaxCompute中的对应表字段名及类型映射。
选择您的pkey并根据字段内的数据调整字段类型,请注意GraphCompute的表类型与MaxCompute有些不同。请尽可能选择合适的类型int取值范围(例如:INT8 INT32 INT64),这将大大加速您的请求响应速度。
索引类型:一般直接选择【KV】完成配置后,字段列表显示user_id(INT64,起点字段)和isbad(STRING)。
如果您有倒排需求请选择【inverted INDEX】,并使用"添加索引"增加索引字段,可以提供全局统计和查询能力,比如需要按照一些属性做全局查询:例如「查询所有风险用户」等场景。
如果您需要添加额外字段,可以使用“添加字段”。
如果您需要启用done分区自动回流,请打开扫描DONE分区开关,具体用法详见done分区指南。
创建节点表【medium】
媒介源表:使用【项目名:igraph_mock,表名:anti_cheating_demo_medium_vertex】
配置方式与User节点相同,数据来源选择MaxCompute数据源+API更新,字段包括medium_id(INT64,起点字段)、medium_type(STRING)和weight(DOUBLE),索引类型选择KV。
Step4-4:创建关系表
创建用户到媒介的正向边
选中user点,鼠标右键-弹出【新增边】,选择边的入点并输入边的名称。
选择数据来源“MaxCompute数据源+API更新”.
输入项目名+表名并导入字段。
关系源表:使用【项目名:igraph_mock,表名:anti_cheating_demo_user_medium_edge】。
选择起点字段及终点字段并根据字段内的数据调整字段类型。
pkey起点字段:user_id
skey终点字段:medium_id
如果您需要添加额外字段,可以使用“添加字段”。
如果您需要启用done分区自动回流,请打开扫描DONE分区开关,具体用法详见done分区指南。
单击提交。
创建媒介到用户的反向边
选择数据来源“MaxCompute数据源+API更新”。
输入项目名+表名并导入字段。
关系源表:使用【项目名:igraph_mock,表名:anti_cheating_demo_user_medium_edge】。
选择起点字段及终点字段并根据字段内的数据调整字段类型。
pkey起点字段:medium_id
skey终点字段:user_id
Step4-5:图模型发布
节点User表 、设备medium 和关系Relation表创建号,即可依次点击【保存】、【发布】。
Step4-6: 数据索引构建
图模型发布完成后就可以进行图计算的索引构建工作,点击【一键回流】功能即可触发海量数据的索引构建。
分区选择:根据业务数据需要,自行选择一个可用分区。
增量时间戳:数据切换上线时,回追增量数据的起始时间。
在弹出的对话框中,为medium、user_medium、medium_user分别选择分区和增量时间戳,然后单击全部触发。
数据索引构建的耗时主要决定于数据量级的大小,一般百万级数据量,需要等待15-20分钟即可完成。通过【图运维】中图模型的节点和关系都绿色即可进行判断。
Step4-7: 判定账户风险
通过团伙大小等相关业务逻辑进行判定。
GraphCompute查询
通过前面的步骤,图计算应用及数据已经准备完成,下面就可以进行图数据的查询和分析;可以通过【图探索】-进行探索式交互或者控制台Gremlin语句查询。
探索式查询提供图形化的节点关系可视化,支持输入节点ID查询并以图谱形式展示关联关系。 | 控制台查询页面提供Gremlin语句输入框,查询结果以JSON树形结构展示。 |
查询用例
直接查询
//查询某个用户的信息判断是否为风险用户
g("anti_cheating").V("-889411487137524591").hasLabel("user")
间接查询
//查询某个媒介关联到风险用户的个数
g("anti_cheating").V("-3161643561846490971").hasLabel("medium")
.outE().inV()
.filter("isbad=\"true\"").count()
//查询与某用户使用相同媒介的风险用户个数
g("anti_cheating").V("-189711352665847917").hasLabel("user").
.outE().outE().inV()
.filter("isbad=\"true\"").count()
使用权重进行枝剪
//对于部分超级媒介可能同时有数十万用户使用,例如某高校的ip,
//此时建议使用sample(n).by("score"),随机选择n条关联用户进行检查,按照score字段分越高,越有可能被选取到
g("anti_cheating").V("-189711352665847917").hasLabel("user").
.outE().sample(10).by("score").outE().inV()
.filter("isbad=\"true\"").count()
使用权重计算风险得分
g("anti_cheating").withSack(supplier(normal,"0.0"),Splitter.identity,Operator.sum).
V("2532895489060363835").hasLabel("user").outE().sack(Operator.assign).by("to_double(score)").
inV().sack(Operator.mult).by("to_double(weight)").outE().inV()
.filter("isbad=\"true\"").barrier().sack()【GraphCompute】技术价值
当前市面上有很多不同类型的图产品可以选择,而且每种产品都有独特的优势;根据各个行业的企业和场景不一样,业务需要了解产品的差异能力,这样对于选择性更有目的性;GraphCompute超强的实时写性能,专攻海量图数据存储和快速查询;通过引擎索引和算子优化逻辑,极好的保障图查询的稳定性;数据限制逻辑、自研算子、数据导入有极强的容错机制,重复输入做最新数据的覆盖;一站式智能运维能力,既提供复杂分布式图引擎能力,也简化了用户的运维成本。
图计算服务的方案优势:
1、低成本
图计算Proxy-Search多行架构让集群负载更高,提高资源利用率,节省机器资源50%;同时集群负载QPS更高1倍。
2、高性能
节点拆分、多种kkv类型,在数据构建时已经将数据进行分类、同时提供可定制的截断逻辑保证查询性能;iGraph在热点key的处理经验丰富,多级cache 能够比较好的防御这类问题,同时可以支持动态扩容等;相比开源方案,查询耗时性能RT降低100%~500%
3、秒级百万更新能力
在风控领域中,OneID- 同人防控能力是通常金融、互联网企业都需要和建设的风控规则,需要实时判定用户是否违规。该类场景需要:整体数据更新量庞大,同时对图数据的查询性能要求较高,聚焦OLTP能力;GraphCompute通过最终一致性方案能够保证单节点百万QPS更新量,生效时间在1-2s,保证风控数据的实效性到秒级,从而提升识别准确率;
4、数仓一体化对接能力
离线处理平台对接,风控安全业务都会由算法、数据团队建设完整的大数据分析,基于阿里云MaxCompute数仓,我们能够无缝对接数据源,同时支持数仓快速迭代,将数仓全量数据的迭代周期最快从T天级到小时级别。