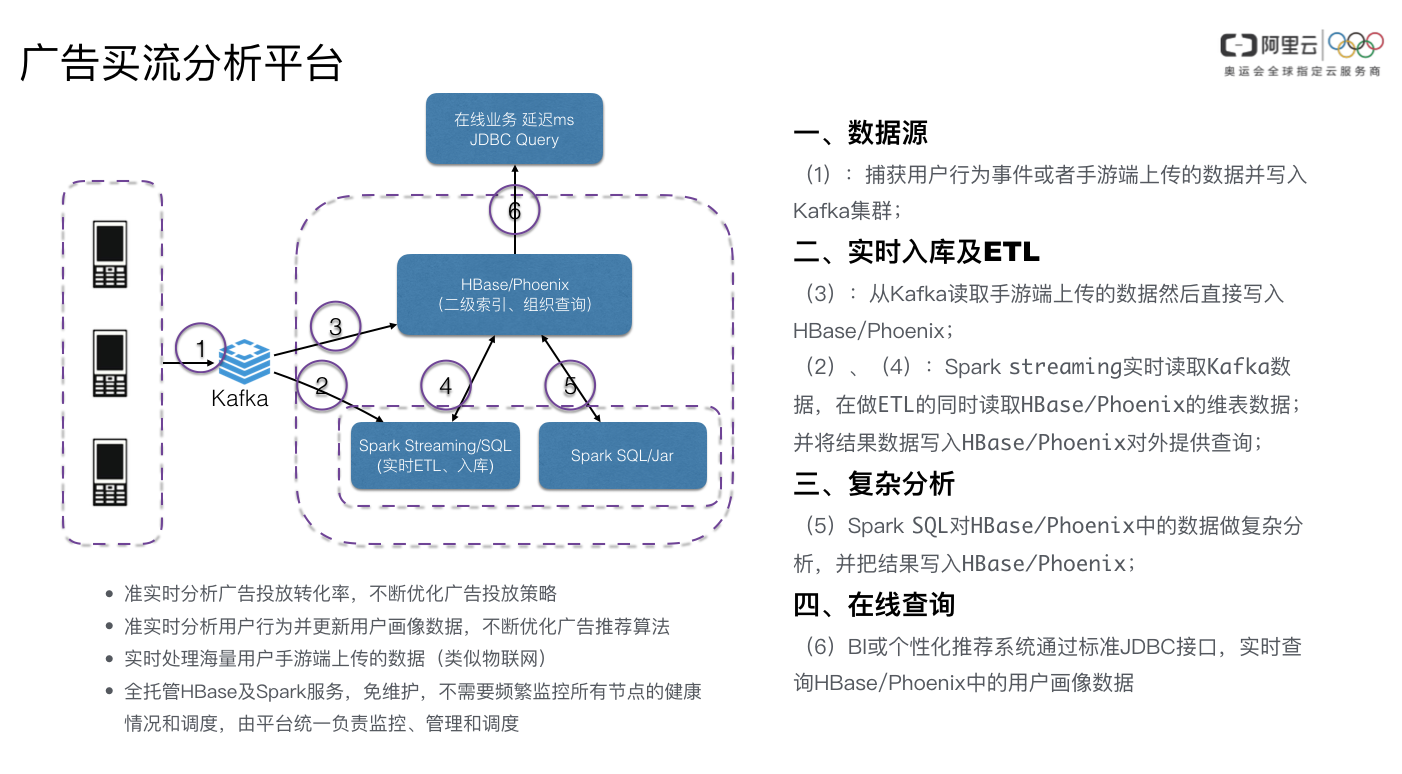
本文介绍Phoenix与Spark的使用场景,差异对比分析供用户选择。
使用场景
- ApsaraDB Phoenix是ApsaraDB HBase提供的SQL层,主要为了解决
高并发、低延迟、简单查询场景,当然也可以解决一定的分析需求。必须命中索引且命中后返回的数据较少,如果是join,则join任意一则返回的数据量在10w以下,且另一侧必须命中索引。为了保障集群稳定性,一些复杂的sql及耗时的sql会被平台拒绝运行。 - ApsaraDB Spark是ApsaraDB HBase提供的分析引擎,满足
低并发,高延迟,复杂计算场景。不管怎么复杂的SQL,都可以完成。另外Spark可以支持sql、scala、java、python语言,支持流、OLAP、离线分析、数据清洗、支持多源(HBase、MongoDB、Redis、OSS等)。 Spark Streaming支持准实时的在线流,不在此讨论访问内。
差异对比
| 对比项目 | Phoenix | Spark |
|---|---|---|
| SQL复杂度 | 简单查询,必须命中索引且命中后返回的数据较少,如果是join,则join任意一则返回的数据量在10 w以下,且另一侧必须命中索引。为了保障集群稳定性,一些复杂的SQL及耗时的SQL会被平台拒绝运行。 | 全部支持执行完成,支持Spark映射到Phoenix,做到Spark在简单SQL查询能到Phoenix同样的性能,不过Spark定位为分析的场景,与Phoenix纯TP有本质的区别。 |
| 集群 | HBase共享一个集群,本质是HBase提供的SQL。 | Spark需要单独购买集群。 |
| 并发 | 单机1 w~5 w左右。 | Spark最高不超过100。 |
| 延迟 | 延迟在ms级别,一些命中较多的数据的SQL会到秒。 | 一般延迟在300 ms以上,大部分SQL需要秒,分钟,甚至小时。 |
| 更新 | Phoenix支持。 | Spark不支持。 |
| 支持业务 | 在线业务。 | 离线业务或者准在线业务。 |
简单查询、高并发、低延迟、 在线业务选择Phoenix。复杂计算、低并发、高延迟、离线业务、准在线业务选择Spark。
案例
通过以下案例我们可以看出,spark主要做流ETL及数据的二次加工,在线的查询通过Phoenix完成。