
本文介绍数据如何导入Serverless实例。
大量数据从HBase集群导入Serverless集群
由于Serverless实例的写入受到购买CU数的限制,如果大量的数据直接通过API写入Serverless实例可能会花费过多时间和消耗过多CU(根据购买CU量的多少,几十GB,几百GB,或者上TB的数据可以定义为大量数据)。因此需要使用LTS。
注意事项
目前HBase Serverless不支持新购。
仅支持HBase1.x以上版本数据导入(包括自建HBase和云HBase)。
Serverless实例空间不足会导致数据导入中断。原始集群的表大小是压缩后的大小,而Serverless实例空间计费是按照KV原始大小计算,请注意预留足够空间。
关于空间计费请参考Serverless 计费。
操作步骤
购买BDS实例,购买指南参见开通LTS。由于数据导入需要OSS做为中转,购买过程中请勾选购买冷存储,并选择合适的空间大小。
 说明
说明实例必须和源HBase集群(数据导出的集群)在同一个VPC内,否则需要做网络打通。
如果数据导入是临时行为,可以采用按量付费的方式,在数据导入完成后可以立刻释放BDS实例。
如果您在之前已经购买过LTS,则注意LTS版本需要升级到2.5.4或者以上版本,如果您的LTS不在此版本以上,请重新购买或者提交工单处理。
将源HBase集群信息关联到LTS中:
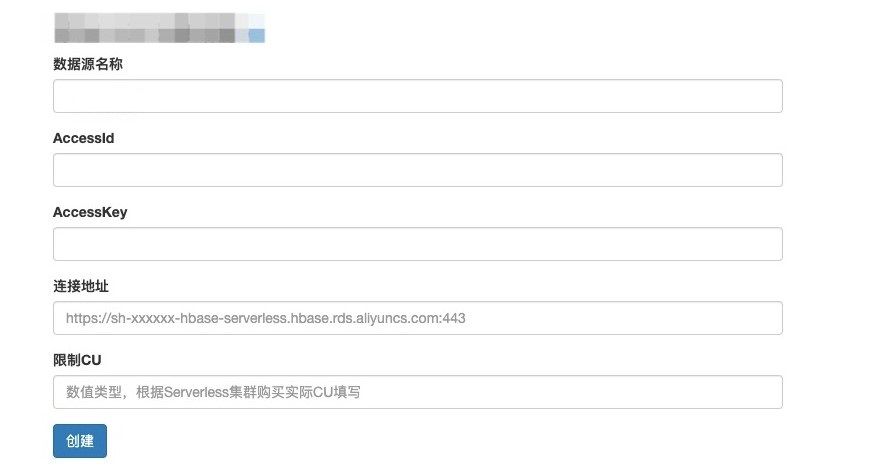
如果源HBase集群是云HBase集群,可以直接在LTS的控制台页面单击添加,如果是自建HBase集群,需要手工添加数据源,请参见HBase数据源。
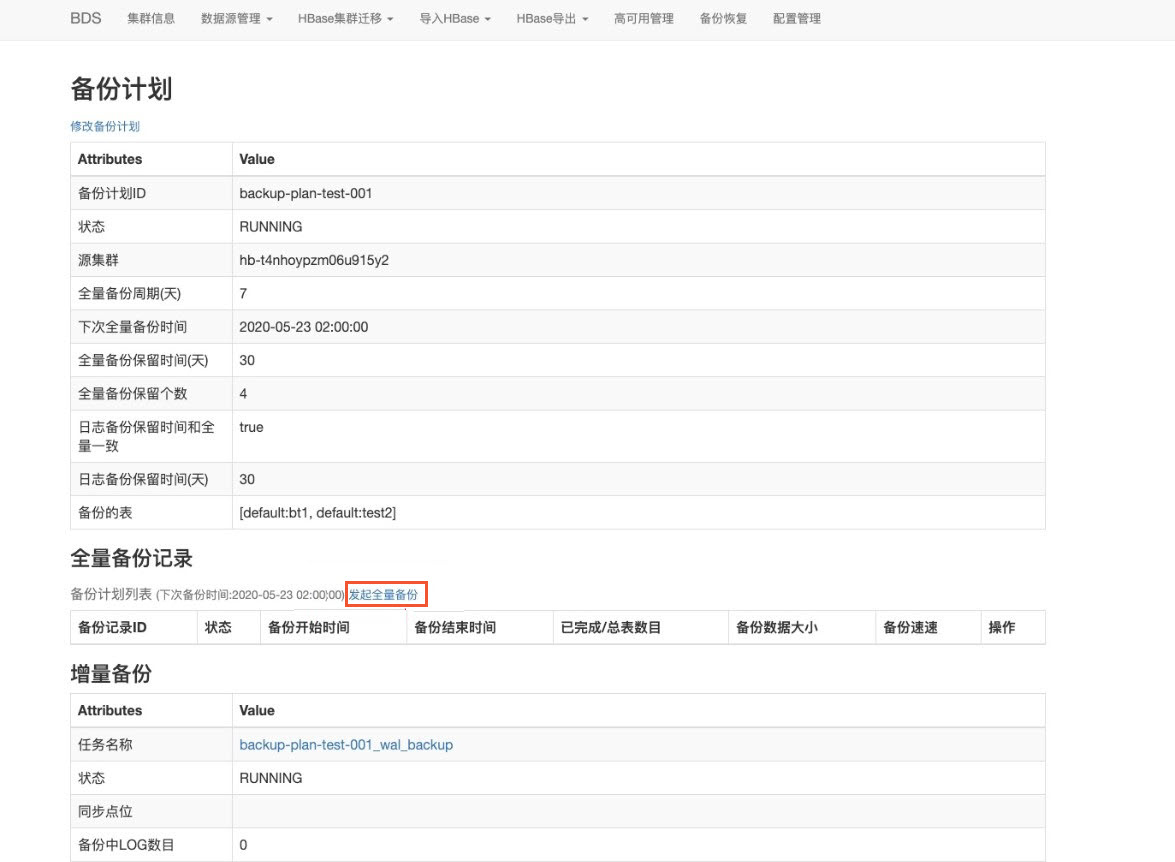
在BDS WebUI中给源集群中需要导入的表创建备份(将数据导入Serverless的原理是将源表进行备份,再将备份数据bulkload到Serverless集群)。
进入BDS系统UI入口。
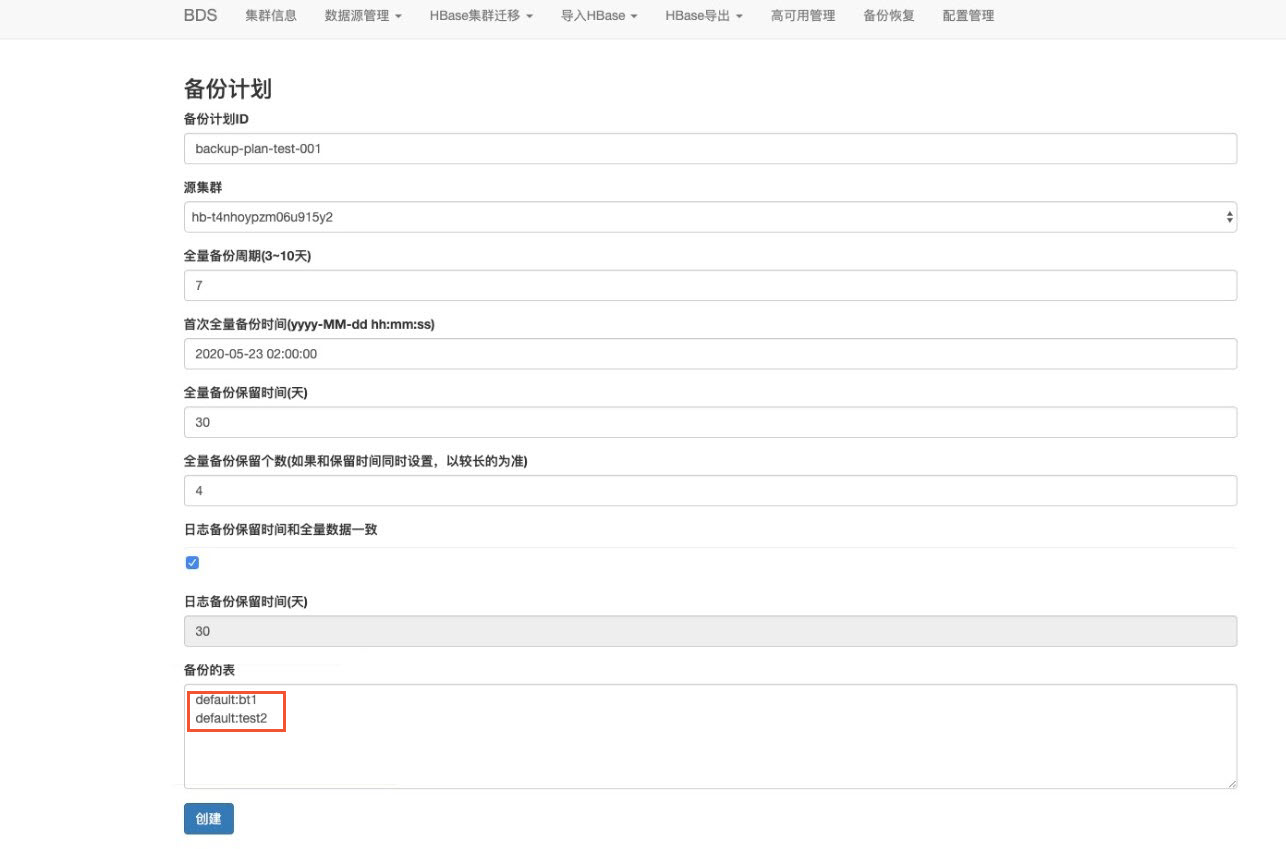
创建备份恢复计划,勾选需要备份的表(即需要导出的表)。

进行数据备份。
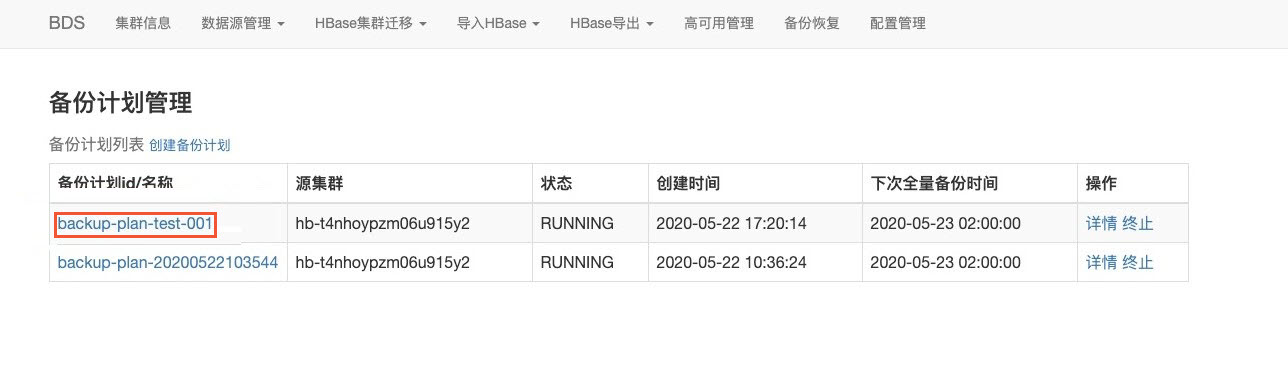
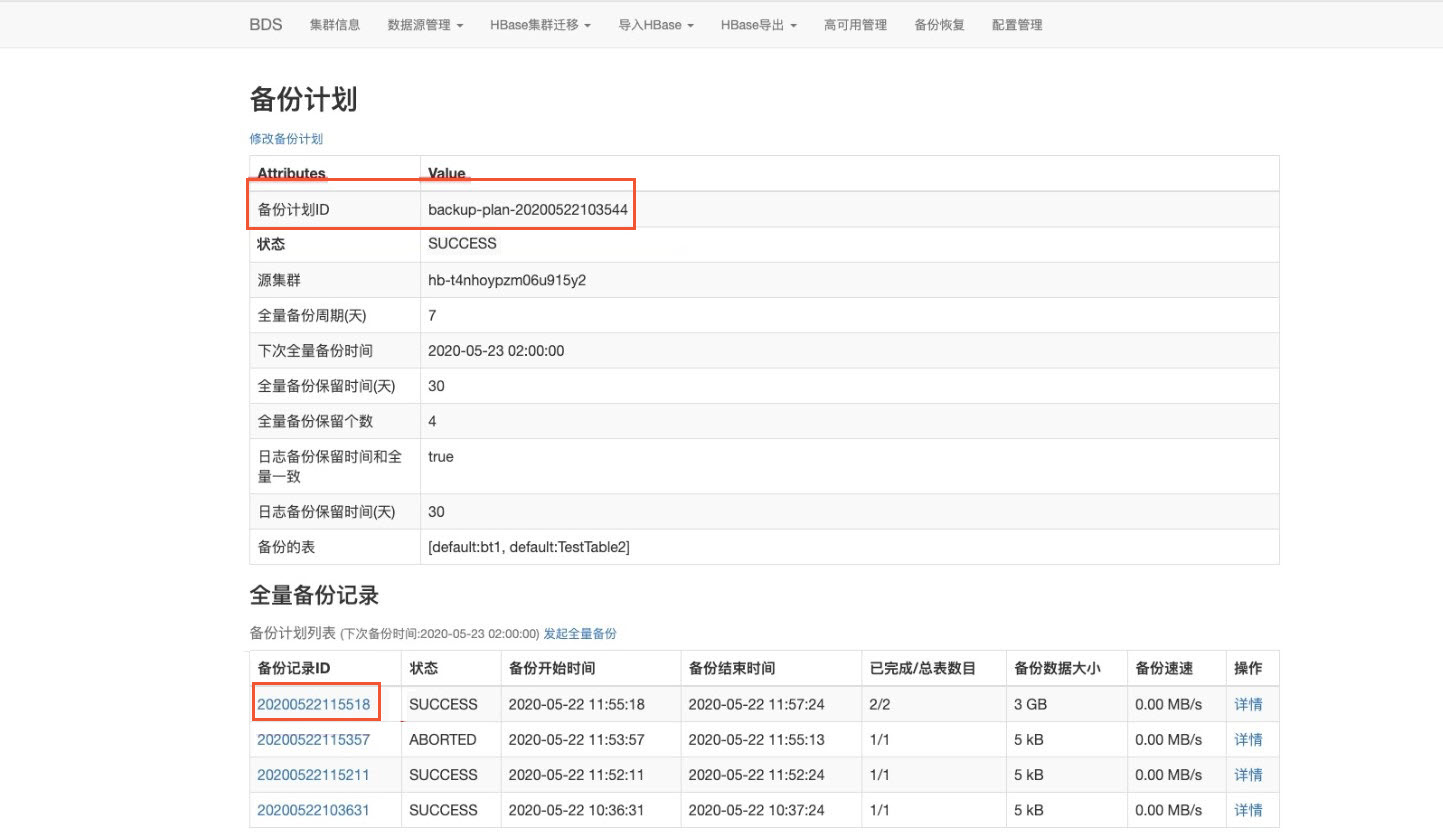
备份完成后可以获取备份计划ID和备份记录ID。

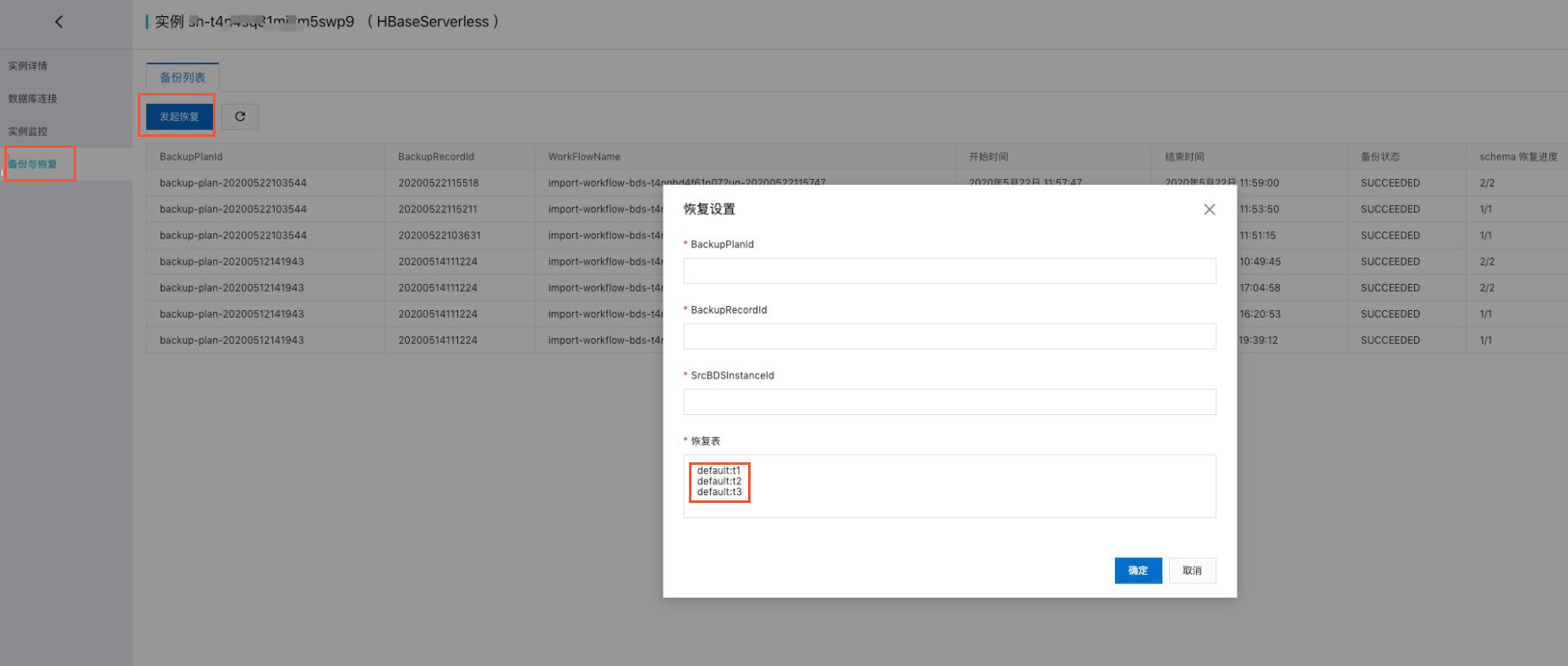
将备份的数据导入Serverless集群。
在Serverless实例的控制台界面将SrcBDSInstanceID(即BDS ID,在BDS控制台界面获得),BackplanID(即刚才备份计划ID),BackupRecordID(即刚才获得的备份记录ID),需要恢复的表(需要恢复的表用namespace:tablename 格式填入, 如果有多个用换行符隔开)填入界面。
备份计划ID,备份记录ID 可以在BDS系统UI中获取。
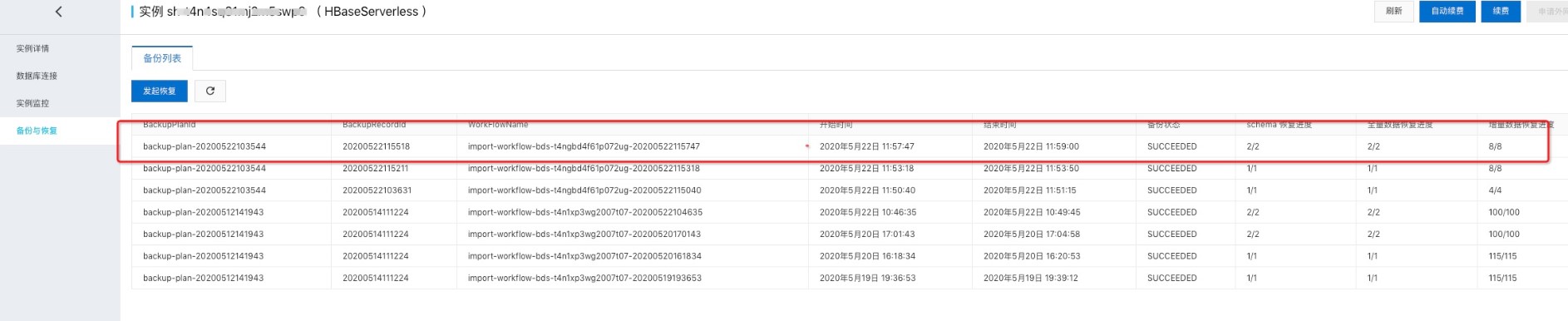
单击创建进行恢复。
说明无需事先在Serverless实例中建表,系统会根据源表属性进行自动建表。
少量数据从HBase导入Serverless集群
如果导入的数据量较少,或者有HBase数据需要实时同步到Serverless集群,可以采用此种方式。此种方式采用HBase API将数据写入Serverless集群,会受到购买的CU数量限制。例如购买了100CU,则意味着每秒只能写入100CU的数据。
准备工作
从其他系统导入Serverless集群
如果您有数据在其他系统中,例如RDS,MongoDB,ElasticSearch,TableStore等,或者您不想购买BDS实例,可以采用DataX的方式导入。DataX支持的数据源参见DataX官方文档。
准备工作
需要下载已经集成HBase Serverless插件的DataX版,单击此处下载。
使用方法
在DataX中写入HBase Serverless的所用插件为hbase11xwriter,此插件的具体配置可参见hbase11xwriter的帮助文档。
{
"job": {
"content": [
{
"reader": {
"name": "hbase11xreader",
"parameter": {
"encoding": "utf-8",
"hbaseConfig": {
"hbase.client.connection.impl" : "com.alibaba.hbase.client.AliHBaseUEConnection",
"hbase.zookeeper.quorum" : "ld-xxxx-proxy-hbaseue-pub.hbaseue.rds.aliyuncs.com:30020"
, "hbase.client.username" : "xxx",
"hbase.client.password" : "xxx"
},
"mode": "normal",
"column": [
{
"name": "rowkey",
"type": "string"
},
{
"name": "f:f0",
"type": "string"
}
],
"range": {
"endRowkey": "",
"isBinaryRowkey": true,
"startRowkey": ""
},
"table": "table1"
}
},
"writer": {
"name": "hbase11xwriter",
"parameter": {
"column": [
{
"index":1,
"name": "f:f0",
"type": "string"
}
],
"encoding": "utf-8",
"writeBufferSize" : 1048576,
"hbaseConfig": {
"hbase.client.connection.impl" : "com.alibaba.hbase.client.AliHBaseUEConnection",
"hbase.zookeeper.quorum" : "https://sh-xxxx-hbase-serverless.hbase.rds.aliyuncs.com:443",
"hbase.client.username" : "AK名",
"hbase.client.password" : "Ak密码",
"hbase.client.cu.limit" : "5"
},
"mode": "normal",
"rowkeyColumn": [
{
"index":0,
"name": "rowkey",
"type": "string"
}
],
"table": "table1",
"versionColumn": {
"index": "-1",
"value": "123456789"
}
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}上述JSON文件是从HBase增强版中将table1这张表的数据全量导入到Serverless的一个示例配置。用户主要需要关注writer部分的这几个配置:
配置名 | 说明 |
hbase.client.connection.impl | 固定为 |
hbase.zookeeper.quorum | 填写Serverless示例的连接地址,注意VPC网络和外网地址,地址以 |
hbase.client.username | AK名。 |
hbase.client.password | AK密码。 |
hbase.client.cu.limit | 限制的CU数量,可根据购买数量设置。注意由于DataX每个线程都会起一个HBase客户端,而CU的限制是客户端级别的,所以这个值需要和channel设置配合。例如想要限制写入不超过100CU,但开了5个线程,则 |
writeBufferSize | 写入时每个batch的大小,由于Serverless限制了每个batch的大小,这里设置不要超过1048576 (1 MB)。 |
channel | 线程并发数。 |
如果有任何疑问,请提交工单。