当您需要对Hologres中分区父表的多个分区子表进行操作(例如执行INSERT、DELETE或UPDATE)时,可以通过DataWorks的for-each节点的循环遍历功能实现,简化复杂的循环处理逻辑,数据更新成功后即可在父表中查看所有分区数据。
背景信息
Hologres兼容原生PostgreSQL生态,支持分区表,在对分区表执行INSERT、DELETE或UPDATE操作时,需要对子表执行,不能在父表中操作然后自动路由到子表。因此对于分区表的操作通常建议使用DataWorks调度节点周期性执行,例如通过DataWorks周期性导入MaxCompute数据最佳实践。
但是对于回刷历史数据等一次性涉及多个分区子表操作的场景,调度需要执行多个SQL较为麻烦,因此本文将会介绍如何使用DataWorks的for-each节点实现多分区操作。
您可通过for-each节点循环遍历赋值节点传递的结果集,详情请参见配置for-each节点。
使用限制
您需要购买DataWorks标准版及以上版本,才可以在Hologres SQL节点中使用赋值参数功能。
使用示例
本文以MaxCompute数据写入Hologres多个分区子表为例,通过for-each节点实现多分区操作的流程如下:
准备表和数据。
在MaxCompute中创建MaxCompute分区表,并插入数据。
--创建一张MaxCompute分区表sale_detail。 CREATE TABLE IF NOT EXISTS odps_sale_detail ( shop_name STRING, customer_id STRING, total_price DOUBLE ) PARTITIONED BY ( sale_date STRING); ---- 向源表增加分区20240110并写入数据 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240110'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240110') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 向源表增加分区20240111 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240111'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240111') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 向源表增加分区20240112并写入数据 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240112'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240112') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 向源表增加分区20240113并写入数据 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240113'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240113') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 向源表增加分区20240114并写入数据 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240114'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240114') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 向源表增加分区20240115并写入数据 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240115'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240115') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3); -- 向源表增加分区20240116并写入数据 ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20240116'); INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20240116') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3);在Hologres中创建外部表和分区父表。
-- 创建外部表 IMPORT FOREIGN SCHEMA <maxCompute_projectname> LIMIT to( odps_sale_detail) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'error',if_unsupported_type 'error'); -- 创建Hologres分区父表(内部表) BEGIN ; CREATE TABLE IF NOT EXISTS holo_sale_detail( shop_name TEXT, customer_id TEXT , total_price FLOAT8, sale_date TEXT ) PARTITION BY LIST(sale_date); COMMIT;
DataWorks工作空间绑定Hologres数据源。
需要在DataWorks中绑定Hologres数据源,详情请参见创建Hologres数据源。
添加Hologres SQL节点获取分区。
在DataWorks数据开发模块创建Hologres SQL节点,输入相应的SQL以获取分区值,作为for-each节点的输入。创建Hologres SQL节点的详情请参见Hologres SQL节点。
示例SQL:获取20240112~20240116共计5个分区值。
SELECT distinct sale_date FROM odps_sale_detail WHERE sale_date > '20240111';返回结果:
+------------+ | sale_date | +------------+ | 20240112 | | 20240113 | | 20240114 | | 20240115 | | 20240116 | +------------+为该节点设置输出参数。
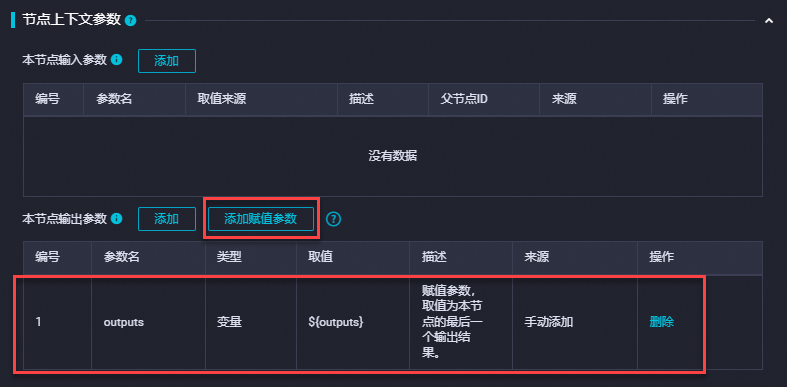
在调度配置 > 节点上下文参数 > 本节点输出参数区域单击添加赋值参数,选择默认的outputs参数即可。详情请参见特殊场景:赋值参数。
配置for-each节点,循环操作分区数据,具体操作可参考配置for-each节点。
添加for-each节点。
在for-each节点内新增一个Hologres SQL节点,设置其上游为start节点,下游为end节点,并在Hologres SQL节点中输入对应的数据导入逻辑。示例SQL如下:
说明您需要先创建对应的子表,并插入数据。for-each节点会将上一步中Hologres SQL节点的分区结果赋值给脚本中的参数,然后循环执行,直到输出值全部匹配完成。
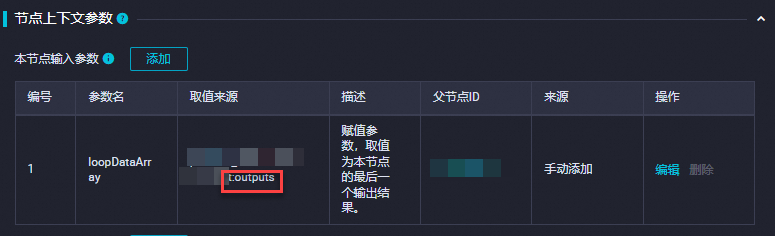
--建子表 CREATE TABLE IF NOT EXISTS public.holo_sale_detail_${dag.foreach.current} PARTITION OF public.holo_sale_detail FOR VALUES IN('${dag.foreach.current}'); --导入数据 INSERT INTO public.holo_sale_detail_${dag.foreach.current} SELECT * FROM odps_sale_detail where sale_date ='${dag.foreach.current}';在for-each节点的编辑页面,单击右侧的调度配置,在调度依赖区域配置本节点依赖的上游节点。并在节点上下文 > 本节点输入参数区域单击默认参数名loopDataArray后的编辑。从取值来源列表中,选择上游赋值节点的outputs参数。
保存并提交for-each节点。
说明如果您使用的是标准模式的工作空间,提交成功后,请单击右上方的发布。具体操作请参见发布任务。
测试并查看测试结果,具体操作可参见测试并查看测试结果。
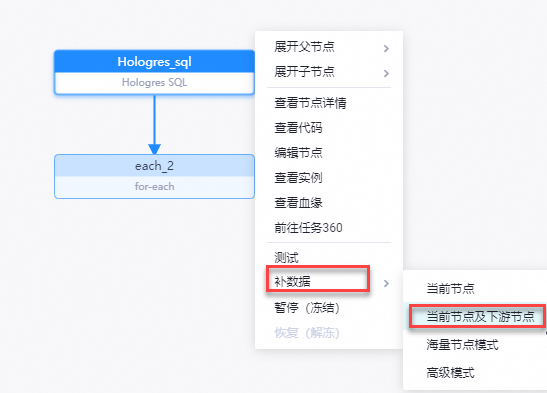
在周期任务页面相应节点的右侧的DAG图中,右键单击赋值节点(即第一个节点),选中补数据 > 当前节点及下游节点。
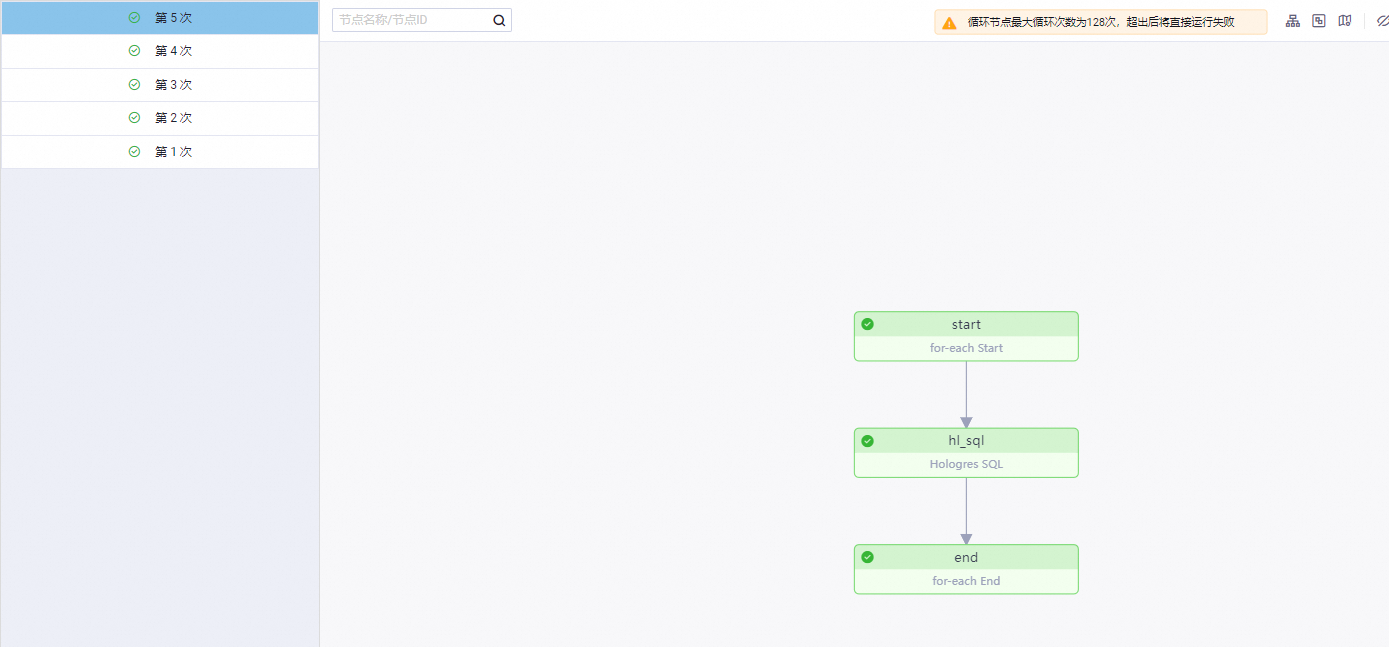
待补数据实例运行成功后,在补数据实例页面,右键单击遍历节点(即第二个节点),选中查看内部节点,即可看到作业中循环了5次执行。
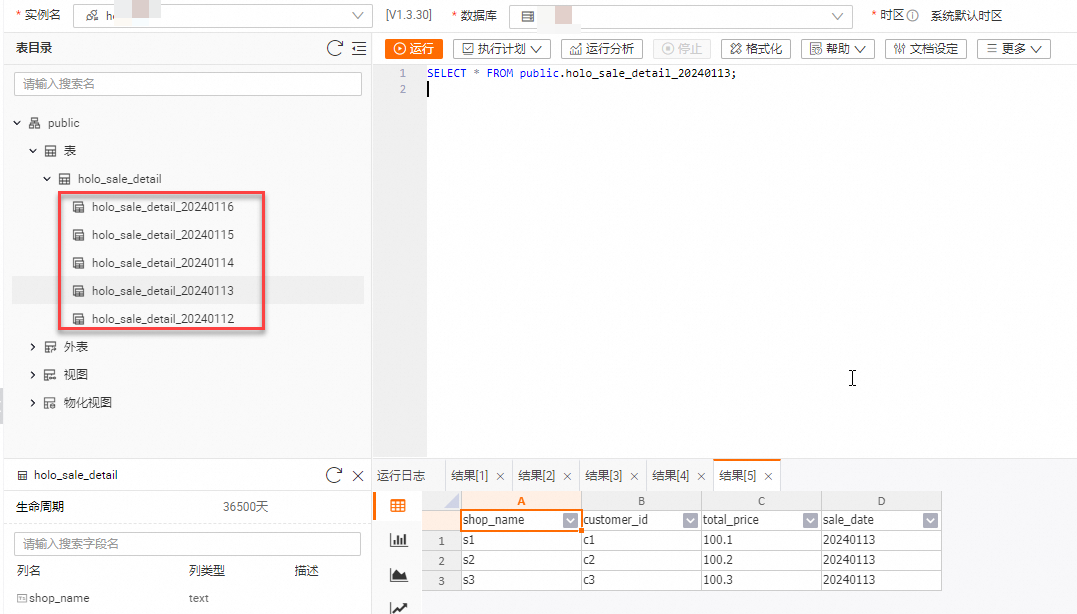
在Hologres中可查看新的子表已创建成功并写入了数据。
失败处理
如果在执行for-each过程中,某一次循环出错,则剩余任务都会停止运行。您可以前往for-each节点内部查看失败详情。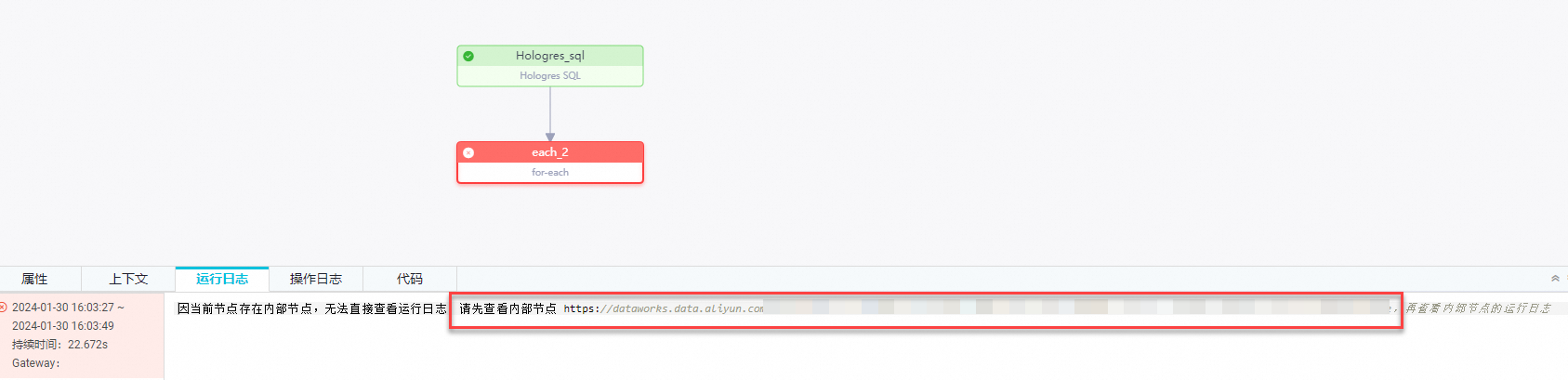
失败处理完成后,您可以对任务执行重跑,即可重新运行失败任务。