
本文为您介绍如何使用实时数仓Hologres、人工智能平台PAI以及大模型DeepSeek部署企业专属问答知识库。
背景信息
企业专属问答知识库部署需要如下组件或服务:
Hologres是阿里巴巴自研一站式实时数仓产品,不仅支持海量数据多维分析(OLAP)、高并发低延迟的在线数据服务(Serving),还与达摩院自研高性能向量计算软件库Proxima深度整合,支持高性能、低延时、简单易用的向量计算能力。详情请参见Proxima向量计算。
PAI-EAS:是阿里云的模型在线服务平台,支持用户将模型一键部署为在线推理服务或AI-Web应用,可以一键部署LLM推理、AIGC等热门服务应用。PAI-EAS适用于实时推理、近实时异步推理等多种AI推理场景,具备Serverless自动扩缩容和完整运维监控体系能力。
DeepSeek:是深度求索公司推出的基于专家混合架构(MoE)的大语言模型,支持高效推理和检索任务,支持用户高效快速地构建和扩展大模型应用。PAI-EAS模型在线服务现已支持一键部署DeepSeek模型。
LangChain:是一个开源框架,可以将大模型、向量数据库、定制语料结合,高效完成专属问答知识库的搭建。Hologres现已被LangChain作为向量数据库集成,详情请参见LangChain-Hologres。
Hologres自研工具帮助您进行专属问答知识库的部署,仅通过该工具即可将Hologres作为向量实时存储和检索引擎,将Hologres、PAI、DeepSeek、定制语料、LangChain串联,快速完成企业专属问答知识库的搭建。自研工具详情请参见GitHub。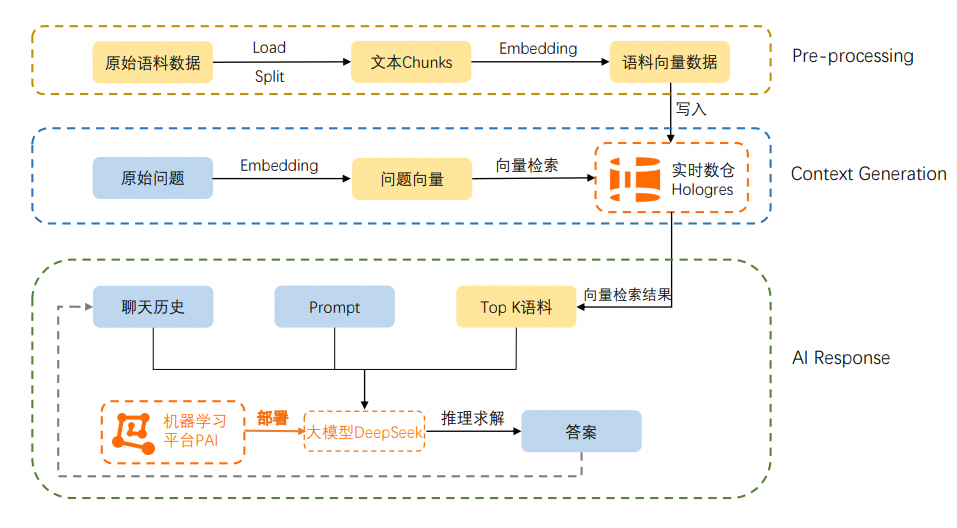
案例效果
基于Hologres+PAI+DeepSeek成功搭建企业专属问答知识库后,系统将调用经过Hologres提示词微调的DeepSeek大模型,并结合特定语料,精简而准确地提供问答结果。您可以将其嵌入不同的业务场景中,如智能问答客服、AI导购、企业知识库等。效果图如下:
该案例的优势如下:
提升大模型回答准确率:将特定领域语料库向量化存储至Hologres,使大模型更好地理解和回答特定领域的专业问题,确保回答的相关性。
高效知识更新:Hologres具备高性能写入能力,支持大模型语料数据的超高QPS写入与更新,您无需对大模型进行重新训练,仅需在Hologres中对知识进行增、删或改写,即可确保大模型的知识新鲜度,减少资源及技术投入。
简化模型部署:通过模型在线服务PAI-EAS一键部署大模型推理服务,无需考虑复杂的环境依赖、预处理及后处理逻辑、框架类型等一系列使用和部署落地模型时的问题。
提升问答速度:Hologres的高性能向量引擎支持高吞吐量和低延迟的向量查询,能够减少“打字机”效应,提升问答响应速度。
前提条件
已购买Hologres实例并创建数据库。详情请参见购买Hologres和创建数据库。
已开通PAI并创建工作空间。详情请参见开通PAI并创建默认工作空间。
已完成基础环境准备。
准备一台ECS机器(您也可以在本地进行),进行如下环境准备工作:
说明ECS实例的VPC和交换机需与Hologres实例保持一致。
使用Anaconda或Virtualenv等工具准备好虚拟环境。安装Anaconda,详情请参见Anaconda。
说明本文中以Anaconda工具为例。
创建虚拟环境,并安装3.11或以上版本的Python:
conda create --name myenv python=3.11 conda activate myenv
步骤一:使用PAI部署DeepSeek大模型
使用PAI-EAS模型在线服务即可快速部署DeepSeek。详情请参见一键部署DeepSeek-V3、DeepSeek-R1模型。
完成大模型部署后,获取VPC访问地址和Token,用于后续config文件的配置。
进入目标工作空间后,在任务管理页面的部署任务页签中单击目标服务名称。
在服务详情页签的基本信息区域单击查看调用信息。
在调用信息对话框的VPC地址调用页签,获取访问地址和Token。
步骤二:安装项目依赖并配置资源连接信息
使用本文工具搭建问答知识库,需要克隆alibabacloud-hologres-connectors项目,安装问答知识库相关依赖,并在holo-llm-deepseek目录下的config文件中设置各资源的连接信息、embedding模型信息等配置项。
运行如下命令克隆本文所需代码与样例数据。本文的工具位于其中的
holo-llm-deepseek目录下。git clone https://github.com/aliyun/alibabacloud-hologres-connectors.git切换到对应的虚拟环境,并进入alibabacloud-hologres-connectors/holo-llm_deepseek目录,执行如下命令安装问答知识库相关依赖。
pip install -r requirements.txt进入
holo-llm-deepseek目录,在config文件中配置资源连接信息。cd alibabacloud-hologres-connectors/holo-llm-deepseek vim config/config.json具体配置项如下,其中
embedding、query_topk、prompt_template均会对大模型微调效果产生影响,请谨慎修改配置值。配置项
说明
eas_config
大模型服务的调用信息,包括:
url:DeepSeek模型的API地址。格式为:已获取的VPC访问地址/v1/chat/completions。token:DeepSeek模型的API地址对应的Token。stream_mode:是否打开流式输出,默认开启。DeepSeek模型可能会输出较长的思考过程,建议打开流式输出。temperature、top_p、top_k、max_tokens:为DeepSeek模型相关参数,取值请参考PAI Model Gallery页面中对应模型的模型介绍。例如:DeepSeek-R1-Distill-Qwen-7B模型对应的模型介绍为模型介绍,您可在BladeLLM 加速部署区域获取目标参数值。
holo_config
Hologres的连接信息,包括:
HOLO_ENDPOINT:Hologres实例的网络地址。您可进入Hologres管理控制台的实例详情页获取指定VPC的网络地址。HOLO_PORT:Hologres实例的端口。您可进入Hologres管理控制台的实例详情页,在网络信息区域获取指定VPC的端口。HOLO_DATABASE:Hologres实例的数据库名称。HOLO_USER:当前阿里云账号的AccessKey ID。您可以单击AccessKey 管理,获取AccessKey ID。HOLO_PASSWORD:AccessKey ID对应的AccessKey Secret。
embedding
将语料数据进行向量化处理的embedding模型信息,包括:
model_id:embedding模型路径。本文使用通义实验室在魔搭平台的CoROM中文通用文本表示模型,路径为:
iic/nlp_corom_sentence-embedding_chinese-base。model_dimension:模型的向量维度。本文使用的embedding模型对应生成768维的向量数据,即
model_dimension值设置为768,详情请参见CoROM。
query_topk
Hologres向量检索返回的数据条数。
本文定义为
4,您可以结合大模型允许的字符数上限、大模型微调效果等参数进行设置。prompt_template
用于大模型微调的Prompt模板。
config文件中已有默认模板,您无需调整。
步骤三:专属语料数据处理
针对提前准备的语料数据(语料数据位于holo-llm-deepseek目录下的data/example.csv文件中),需要进行向量化处理并导入Hologres。使用本文的开源工具,在holo-llm-deepseek目录下执行如下命令。
# 语料向量数据导入前,先清理数据库中的历史数据
python main.py -l --clear
# 将holo-llm-deepseek/data/example.csv中的语料数据向量化处理后导入Hologres
python main.py -l首次使用会自动下载Embedding模型(约400 MB),需要较长时间,第二次调用则不需要此过程。
本文针对Hologres提供的专业语料示例如下:
您可以在Hologres实例对应数据库下的langchain_embedding表中查询embedding后的向量数据:
SELECT * FROM langchain_embedding limit 1;返回结果示例如下:
id | vector | metadata | document |
fd3675db-1319-4cef-8e45-9ac141627b59 | {0.395261,0.123794,0.761932,0.413286,...} | {"source": "data/example_data.csv", "row": 3} | title: ... content: ... |
步骤四:大模型微调效果验证
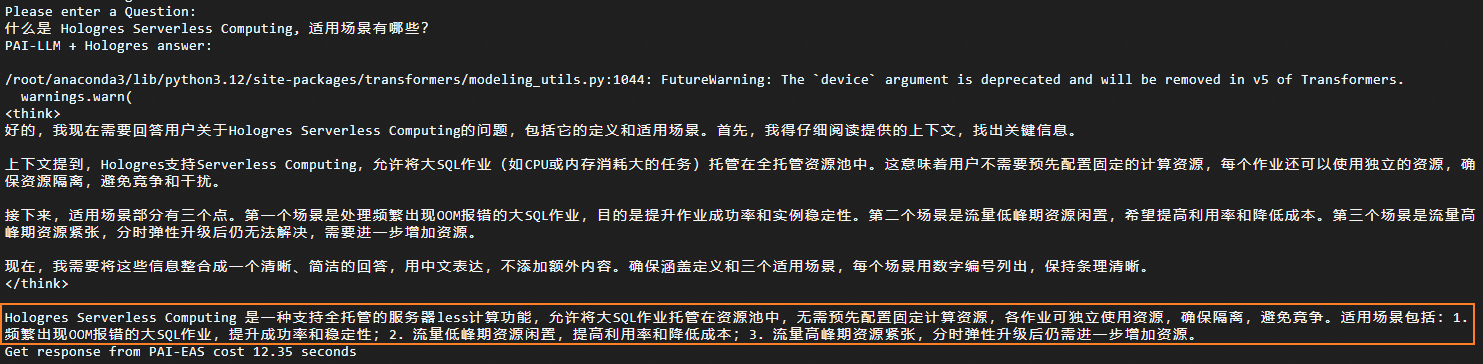
此处将分别展示调用原生DeepSeek大模型和经过Hologres提示词微调的DeepSeek大模型的效果,以便您进行对比和评估。
对比项 | 调用原生Deepeek大模型 | 调用经过Hologres提示词微调的DeepSeek大模型 |
调用命令 | | |
输入问题 | 什么是 Hologres Serverless Computing,适用场景有哪些? | 什么是 Hologres Serverless Computing,适用场景有哪些? |
大模型回答示例 |
|
|
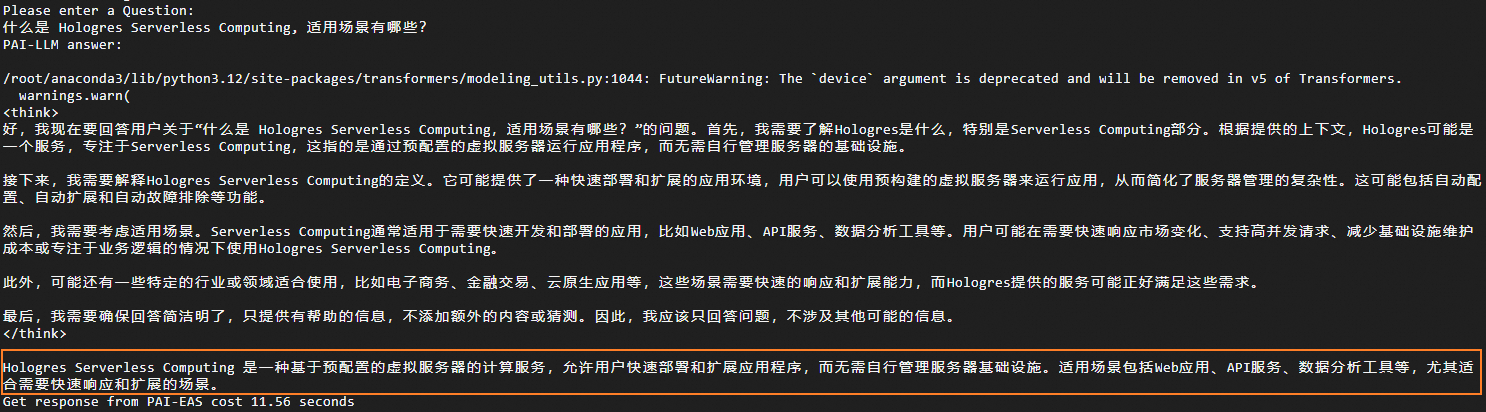
调用原生DeepSeek大模型时,由于该模型的训练语料存在时间截断的问题,导致其数据的实时性和新鲜度不足,从而使得模型提供的回答较为宽泛,无法给出精确的结果。而调用经过Hologres提示词微调的DeepSeek大模型时,Hologres高效的向量引擎能够有效整合特定领域的语料信息,使得模型的回答结果更加准确。
该问题相关的语料数据请参见Hologres语料数据。
相关文档
如果您希望使用实时数仓Hologres、人工智能平台 PAI以及大模型LLaMA2部署企业专属问答机器人,请参见基于Hologres、PAI和LLaMA2搭建企业专属问答知识库。