Hologres自V4.0版本开始支持全局二级索引,适用于在非主键列上进行高效Key-Value查询的场景。与主键索引不同,二级索引不要求数据唯一,但可显著提升特定列的查询效率。
前提条件
Hologres实例为V4.0及以上版本。如果您的实例是V4.0以下版本请参见实例升级。
使用限制
全局二级索引列仅支持 TEXT、INTEGER、BIGINT 和 VARCHAR 数据类型。
不支持修改全局二级索引。
索引列和INCLUDE列不允许重复列。
原表必须有主键。
全局二级索引的索引列和与 INCLUDE 列之和最多 512 列。
仅普通内表支持创建全局二级索引。物理分区表和逻辑分区表都不支持创建全局二级索引。
全局二级索引中的列,原表不支持删除和修改列。
创建了全局二级索引的原表不支持修改Table Group和Resharding。
全局二级索引默认只支持使用标准存储(热存)。
全局二级索引的存储方式(行存、列存、行列共存)和原表一致,详情如下:
原表使用行存,那么它的全局二级索引默认使用行存。
原表使用列存,那么它的全局二级索引默认使用列存。
原表使用行列共存,那么它的全局二级索引默认使用行列共存。
创建全局二级索引
语法
CREATE GLOBAL INDEX [ IF NOT EXISTS ] index_name ON [schema_name.]table_name (index_column_name [, ...]) [ INCLUDE (include_column_name[, ...]) ]参数说明
参数
是否必填
说明
index_name
是
全局二级索引的索引名称。
schema_name
否
原表的Schema名称。若未填写,将使用默认的Schema名称。
table_name
是
原表的表名。
index_column_name
是
全局二级索引的索引列。推荐设置为非主键点查的过滤列。
include_column_name
否
全局二级索引中需要包含的列。
使用说明
提交创建SQL后,系统将开始构建索引。待索引构建完成且可见后,
CREATE GLOBAL INDEX才会执行完成。由于构建索引相当于写入了多份数据,因此构建索引会影响写入性能。原表的数据量越多,写入性能受到的影响越大;此外,索引中包含的列越多,影响亦越大。
在创建全局二级索引时,不支持指定Schema,所创建的全局二级索引将与原表位于同一Schema。
查询中涉及的列,全局二级索引必须要完全覆盖(出现在索引列或者包含列中),才能使用索引。
删除全局二级索引
语法
DROP INDEX [schema_name.]index_name参数说明
参数名称
是否必填
说明
schema_name
否
局二级索引的Schema名称。若未填写,将使用默认Schema。
index_name
是
全局二级索引的索引名称。
查看全局二级索引
查看当前数据库下的全局二级索引
SELECT n.nspname AS table_namespace, t.relname AS table_name, i.relname AS index_name FROM pg_class t JOIN pg_index ix ON t.oid = ix.indrelid JOIN pg_class i ON i.oid = ix.indexrelid JOIN pg_am am ON am.oid = i.relam JOIN pg_namespace n ON n.oid = t.relnamespace WHERE t.relkind = 'r' -- 只查普通表 AND am.amname = 'globalindex'查看全局二级索引占用的存储
其中
global_index_name为全局二级索引的索引名称。SELECT pg_relation_size('schema_name.global_index_name');查看全局二级索引包含的列
SELECT pg_catalog.pg_get_indexdef('global_index_name'::regclass, 0, true);
使用示例
假设希望订单应用程序需要高频查询某种订单优先级的数据的功能。示例orders表如下所示:
字段名 | 类型 | 含义 |
O_ORDERKEY | BIGINT | 订单号(主键)。 |
O_CUSTKEY | INT | 客户编号(外键关联CUSTOMER表)。 |
O_ORDERSTATUS | CHAR(1) | 订单状态(''F''=已完成, ''O''=未完成, ''P''=处理中)。 |
O_TOTALPRICE | DECIMAL(15,2) | 订单总金额。 |
O_ORDERDATE | DATE | 订单创建日期。 |
O_ORDERPRIORITY | TEXT | 订单优先级(''1-URGENT'', ''2-HIGH''等)。 |
O_CLERK | TEXT | 处理订单的员工编号。 |
O_SHIPPRIORITY | INT | 发货优先级(数值越大优先级越高)。 |
O_COMMENT | TEXT | 订单备注信息。 |
创建示例orders表的SQL如下所示。
CREATE TABLE ORDERS
(
O_ORDERKEY BIGINT NOT NULL PRIMARY KEY,
O_CUSTKEY INT NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY TEXT NOT NULL,
O_CLERK TEXT NOT NULL,
O_SHIPPRIORITY INT NOT NULL,
O_COMMENT TEXT NOT NULL
) WITH (
orientation='row,column',
segment_key='O_ORDERDATE',
distribution_key='O_ORDERKEY',
bitmap_columns='O_ORDERSTATUS,O_ORDERPRIORITY,O_CLERK,O_SHIPPRIORITY',
dictionary_encoding_columns='o_comment:off,o_orderpriority,o_clerk'
);
COMMENT ON TABLE ORDERS IS '订单主表,记录订单基本信息和状态';
COMMENT ON COLUMN ORDERS.O_ORDERKEY IS '订单号(主键)';
COMMENT ON COLUMN ORDERS.O_CUSTKEY IS '客户编号(外键关联CUSTOMER表)';
COMMENT ON COLUMN ORDERS.O_ORDERSTATUS IS '订单状态(''F''=已完成, ''O''=未完成, ''P''=处理中)';
COMMENT ON COLUMN ORDERS.O_TOTALPRICE IS '订单总金额';
COMMENT ON COLUMN ORDERS.O_ORDERDATE IS '订单创建日期';
COMMENT ON COLUMN ORDERS.O_ORDERPRIORITY IS '订单优先级(''1-URGENT'', ''2-HIGH''等)';
COMMENT ON COLUMN ORDERS.O_CLERK IS '处理订单的员工编号';
COMMENT ON COLUMN ORDERS.O_SHIPPRIORITY IS '发货优先级(数值越大优先级越高)';
COMMENT ON COLUMN ORDERS.O_COMMENT IS '订单备注信息';若需要高频查询某种订单优先级的数据的SQL,如下所示:
SELECT O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_ORDERPRIORITY, O_CLERK, O_SHIPPRIORITY, O_COMMENT FROM ORDERS WHERE O_ORDERPRIORITY='1-URGENT'您可以使用
EXPLAIN进行SQL语句执行计划检查:EXPLAIN SELECT O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_ORDERPRIORITY, O_CLERK, O_SHIPPRIORITY, O_COMMENT FROM ORDERS WHERE O_ORDERPRIORITY='1-URGENT'返回结果如下。
QUERY PLAN Gather (cost=0.00..1.00 rows=1 width=53) -> Local Gather (cost=0.00..1.00 rows=1 width=53) -> Index Scan using Clustering_index on orders (cost=0.00..1.00 rows=1 width=53) Bitmap Filter: (o_orderpriority = '1-URGENT'::text) Query Queue: init_warehouse.default_queue Optimizer: HQO version 4.0.0通过增加
O_ORDERPRIORITY列的索引,进行更加高效的查询。基于上述返回的计划中查看上述查询使用了Bitmap Index。由于Bitmap Index对于查询性能的提升较为有限,若您需要追求更高的QPS,可以在
orders表增加O_ORDERPRIORITY列的索引。CREATE GLOBAL INDEX idx_orders ON orders(O_ORDERPRIORITY) INCLUDE ( O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_CLERK, O_SHIPPRIORITY, O_COMMENT );添加索引后,再次运行
EXPLAIN语句检查执行计划:QUERY PLAN Local Gather (cost=0.00..1.76 rows=3035601 width=99) -> Index Scan using Clustering_index on idx_orders (cost=0.00..1.54 rows=3035601 width=99) Shard Prune: Eagerly Shards selected: 1 out of 20 Cluster Filter: (o_orderpriority = '1-URGENT'::text) Query Queue: init_warehouse.default_queue Optimizer: HQO version 4.0.0此时可以看到计划中
Index Scan using Clustering_index on的对象已经是全局二级索引idx_orders了,且使用了Shard裁剪了,此时QPS可以得到有效提升。使用Fixed Plan,更进一步提升QPS。
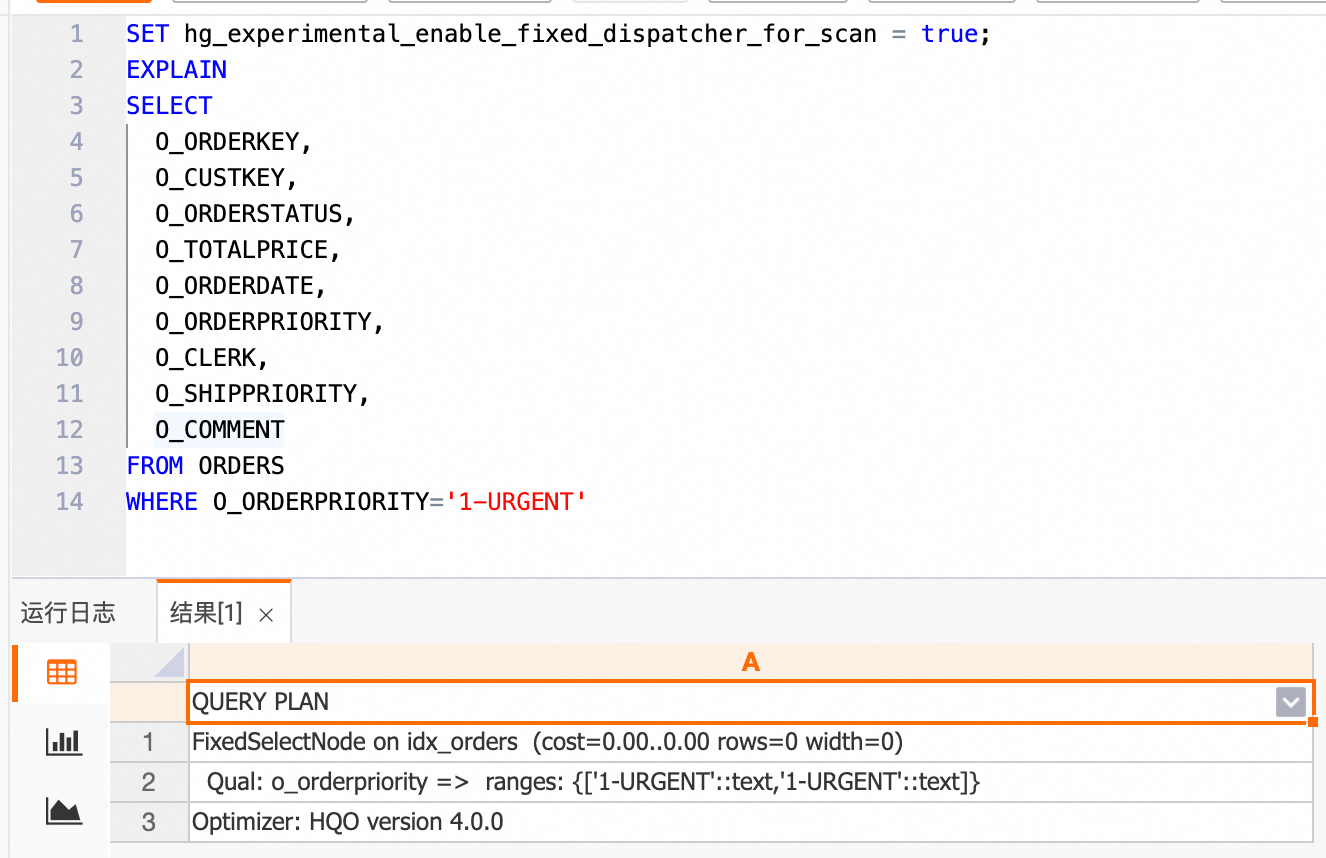
SET hg_experimental_enable_fixed_dispatcher_for_scan = true;查看执行计划,可以看到使用Fixed Plan的点查优化。