
本文档指导开发者通过智能工作流实现智能媒体处理,帮助用户将媒体处理功能流程化、模块化,并自定义处理流程。
场景一:直播翻译
通过智能工作流对直播流进行语音识别后,实时生成中英文翻译结果,并将每句话的中间结果与最终结果回调至HTTP业务服务器。
整体拓扑配置
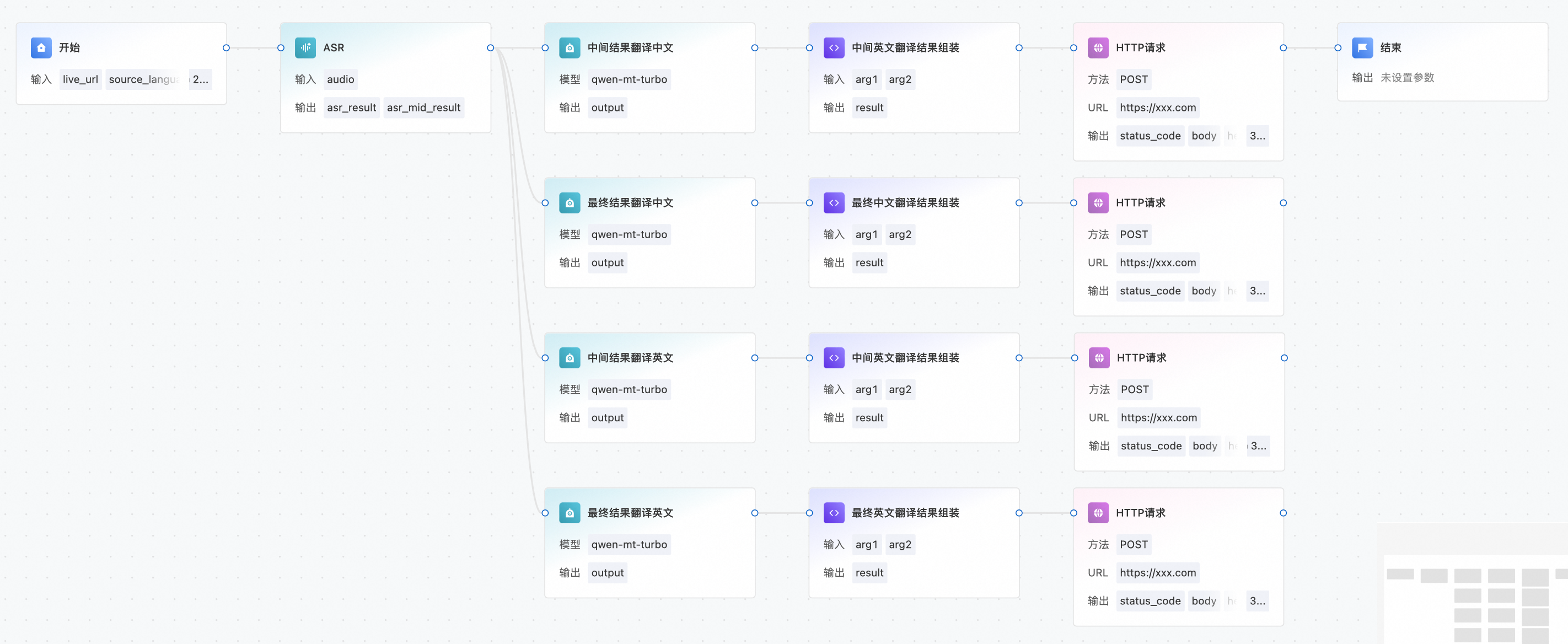
包含开始、ASR、LLM、代码执行、HTTP请求、结束六个节点。
节点配置详情如下:
开始节点

启动工作流时,可传入如下参数作为开始节点入参:
{
"live_url": {
"Url": "rtmp://test.com/test_app/test_stream?auth_key=test",
"MaxIdleTime": 20
},
"source_language_id": "es"
}参数名 | 必填项 | 说明 |
live_url | 是 | 需以Object格式传入,其中:
|
source_language_id | 是 | 源语种信息,取值可从以下列表中获取。 |
中文普通话:zh
英文:en
西班牙:es
日语:ja
韩语:ko
法语:fr
泰语:th
俄语:ru
德语:de
广西方言:guangxi
葡萄牙语:pt
粤语:yue
繁体粤语:yue_hant
闽南语:minnan
波兰语场景:pl
意大利语场景:it
乌克兰语场景:uk
荷兰语:nl
阿拉伯语:ar
印尼语:id
土耳其语:tr
越南语:viASR节点
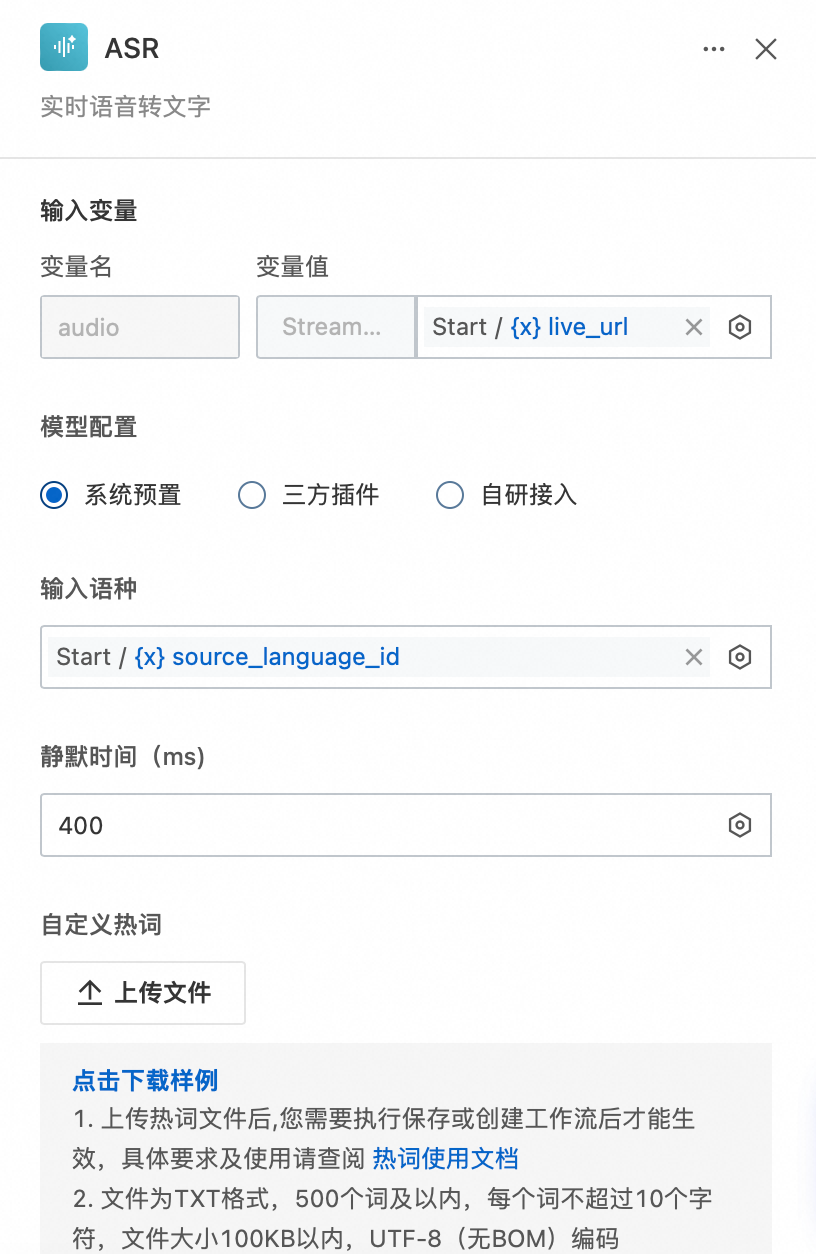
输入变量引用开始节点live_url参数,输入语种引用开始节点source_language_id参数,其他参数保持默认或根据需求进行自定义配置。
LLM节点
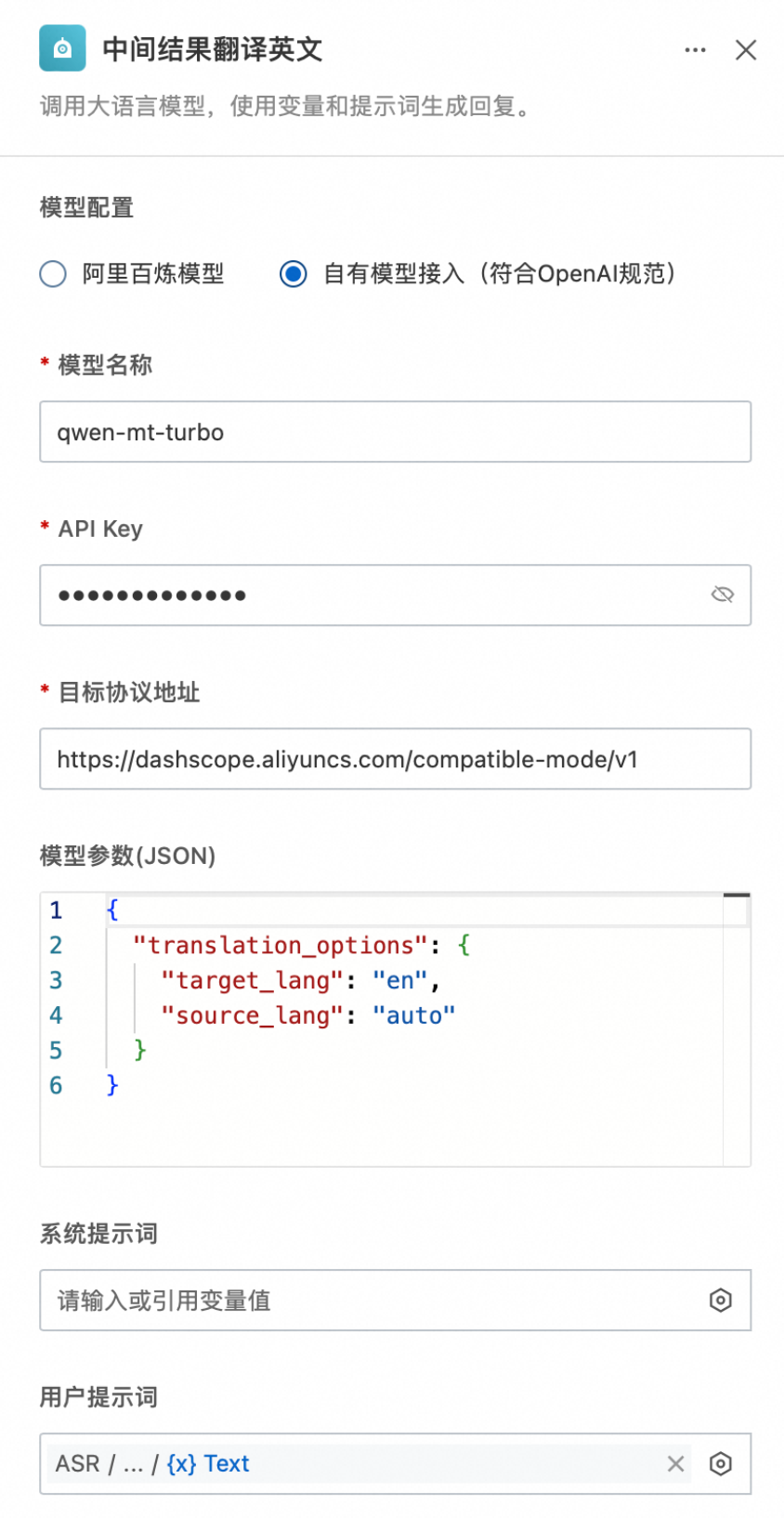
此处以自有模型接入(符合OpenAI规范)方式配置qwen-mt-turbo模型,API Key获取请参考获取API Key,模型参数中需设置翻译的源语种(可设为auto)及目标语种,用户提示词可直接引用ASR的中间结果或最终结果。
代码执行节点
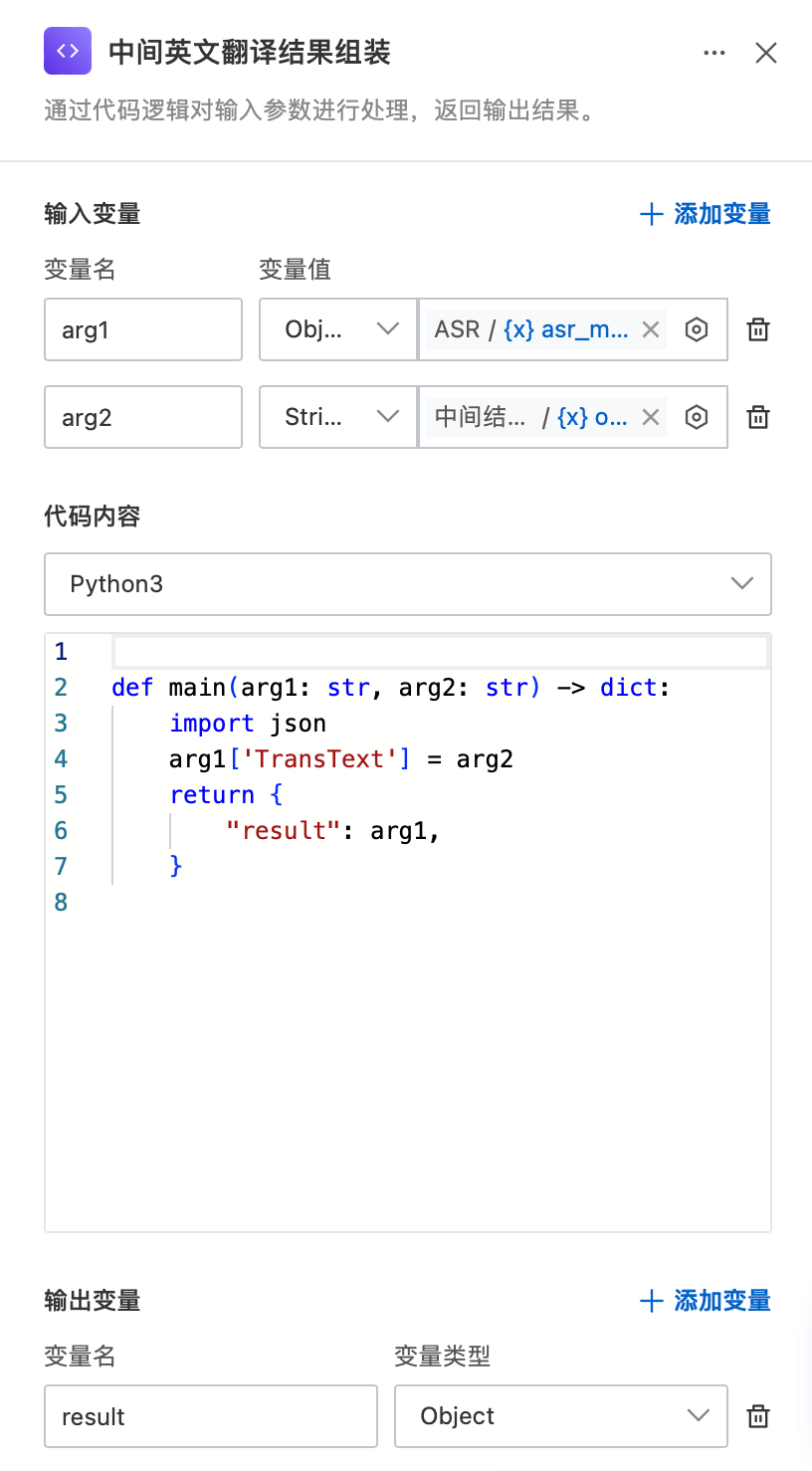
为将ASR识别结果与大模型翻译结果合并后回调至业务服务器,需使用Python脚本通过代码执行节点进行结果组装:将大模型输出设置到ASR结果的TransText字段,最终返回JSONObject作为回调数据。
HTTP请求节点
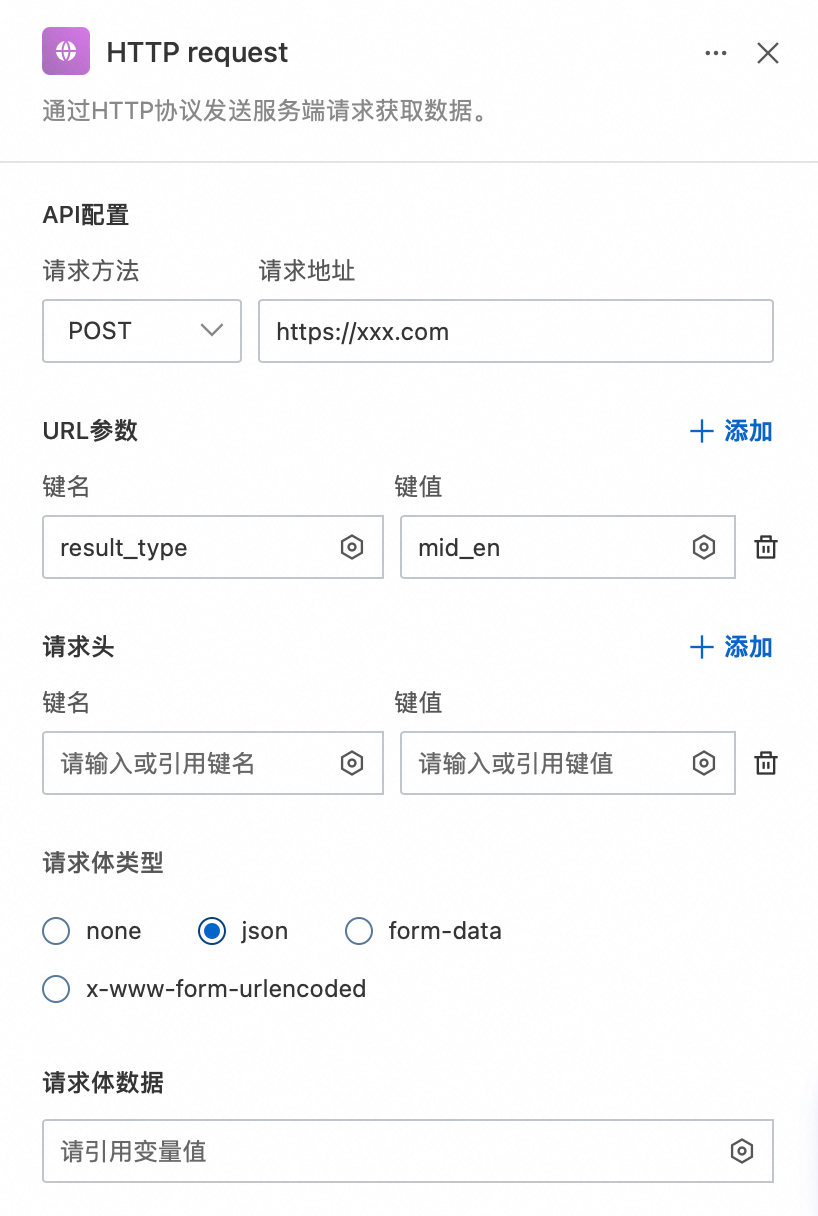
此处需要配置:
API配置:回调服务器公网地址。
URL参数:result_type=mid_en(可自定义回调类型)。
请求体类型:json。
请求体数据:引用回调数据输出的JSON结果。
场景二:RTC字幕识别
通过智能工作流对RTC房间内指定的音频流进行ASR识别,识别结果通过DataChannel回调至客户端显示字幕。
整体拓扑配置

包含开始、ASR、RTC推流、结束四个节点。
节点配置详情如下:
开始节点
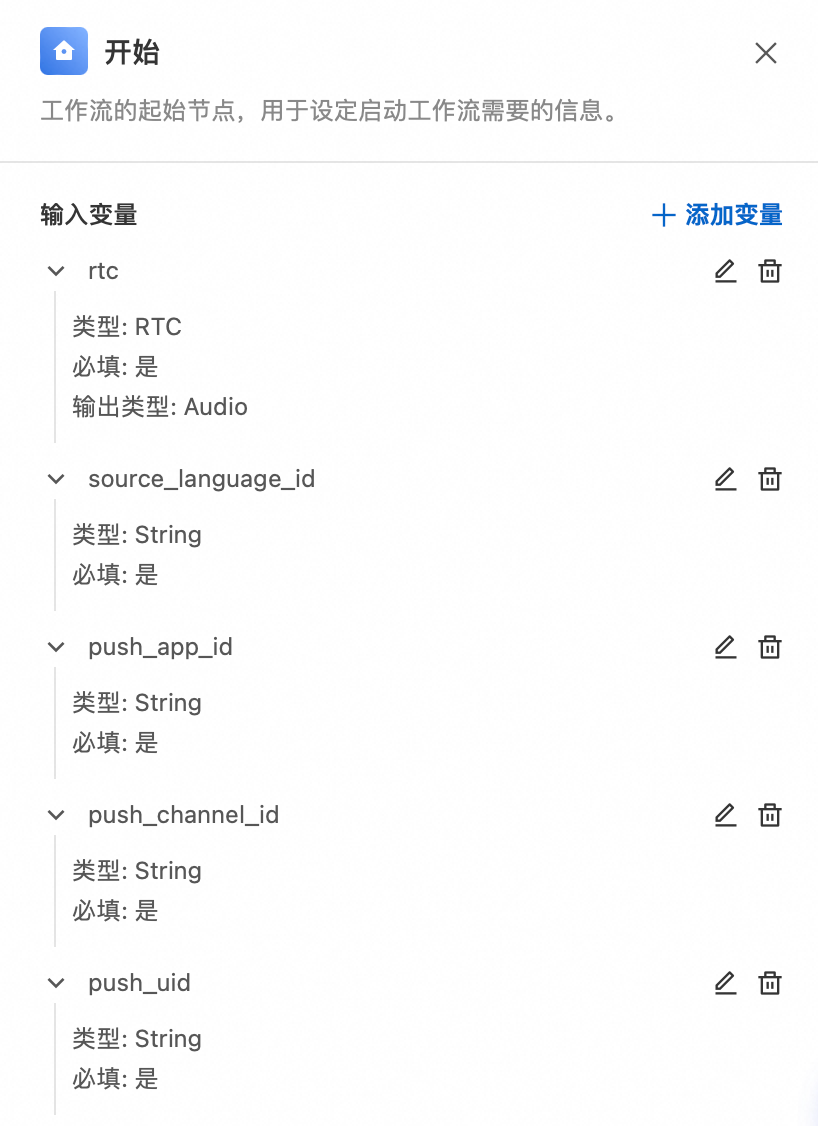
变量说明如下:
rtc:启动时需传入RTC参数,其中包含AppId(应用ID)、ChannelId(频道ID)、UserId(用户ID),并选择输出音频流。
source_language_id:需要识别的源语种。
push_app_id:DataChannel回调的RTC应用Id。
push_channel_id:DataChannel回调的RTC频道Id。
push_uid:DataChannel回调的RTC用户Id。
变量示例:
{
"rtc": {
"AppId": "xxx",
"ChannelId": "rtcaitest1",
"UserId": "userA"
},
"source_language_id": "zh",
"push_app_id": "app_id",
"push_channel_id": "channel_id",
"push_uid": "user_id"
}ASR节点
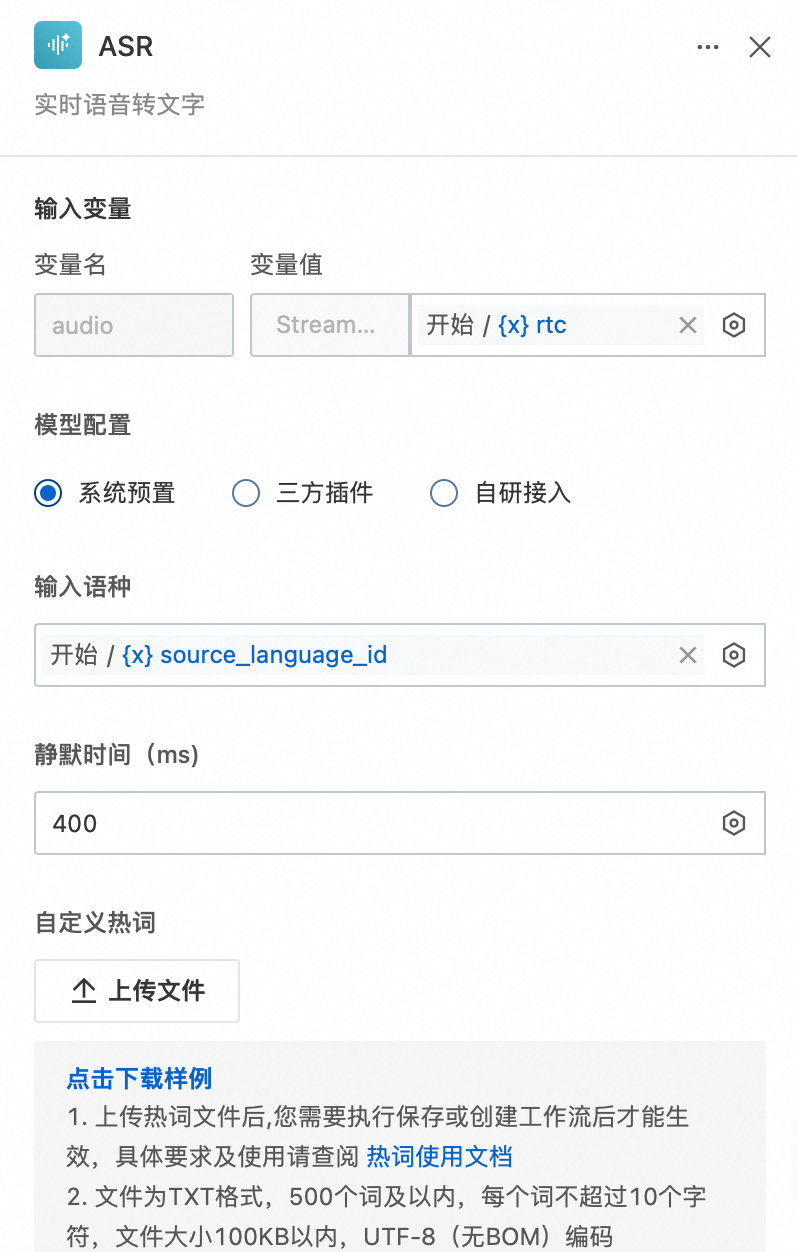
输入变量引用开始节点输入直播流的音频,输入语种引用开始节点source_language_id参数,其他参数保持默认或根据需求进行自定义配置。
RTC推流节点
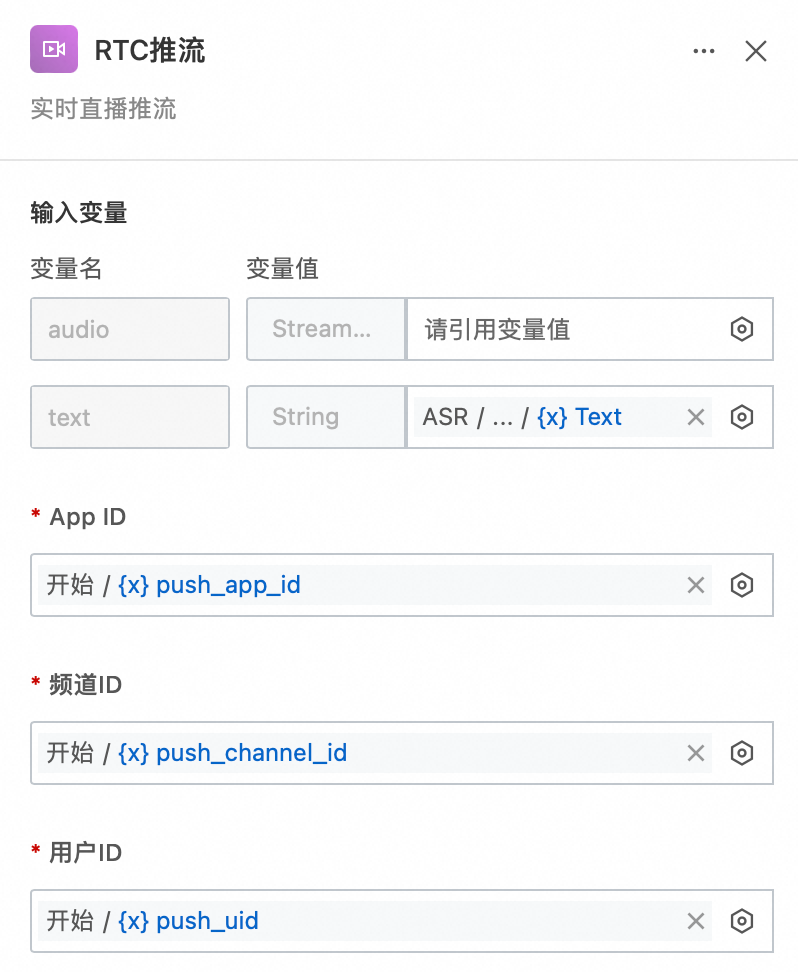
输入变量text需引用ASR输出文本,App ID、频道ID、用户ID分别对应开始节点的push_app_id、push_channel_id、push_uid字段,表示DataChannel推流角色信息。