
本文将为您介绍如何快速创建音视频智能体。
服务开通
为了使用阿里云AI实时互动服务,您需要满足以下条件:
请先确保已开通 AI 实时互动功能。若尚未开通,请前往开通服务,已开通用户可直接使用。
说明若出现“您当前购买数量超过还可购买的数量余量,请重新选择数量!”,表明服务已经开通。
第一步 创建音视频工作流
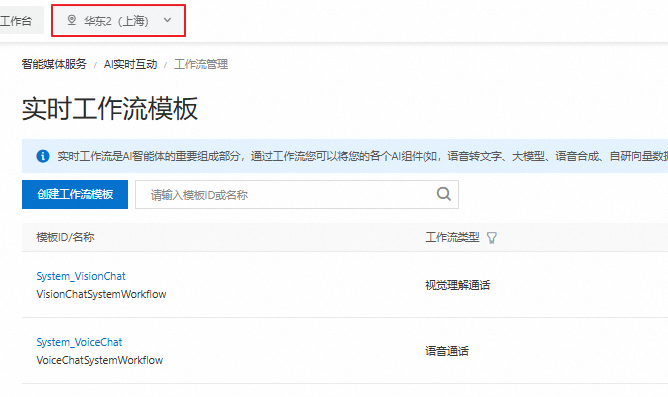
登录智能媒体服务控制台,单击创建工作流模板。
按需选择语音通话、数字人通话、视觉理解通话或视频通话,并配置工作流节点。
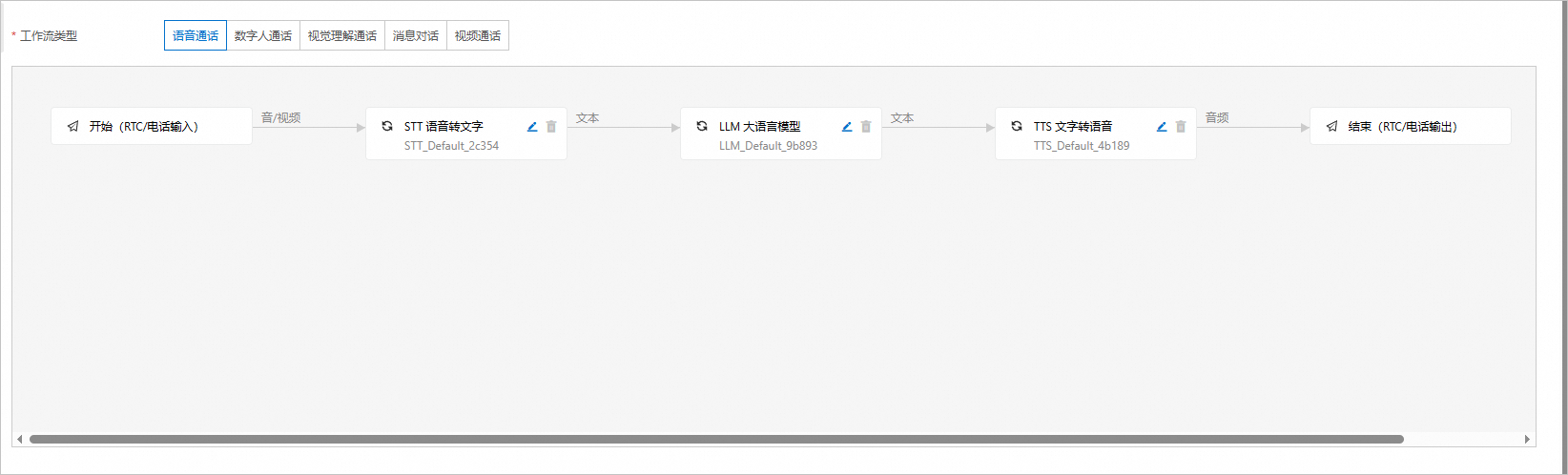
STT 语音转文字
该节点负责将语音输入转换成可读的文字格式,支持多语种识别。
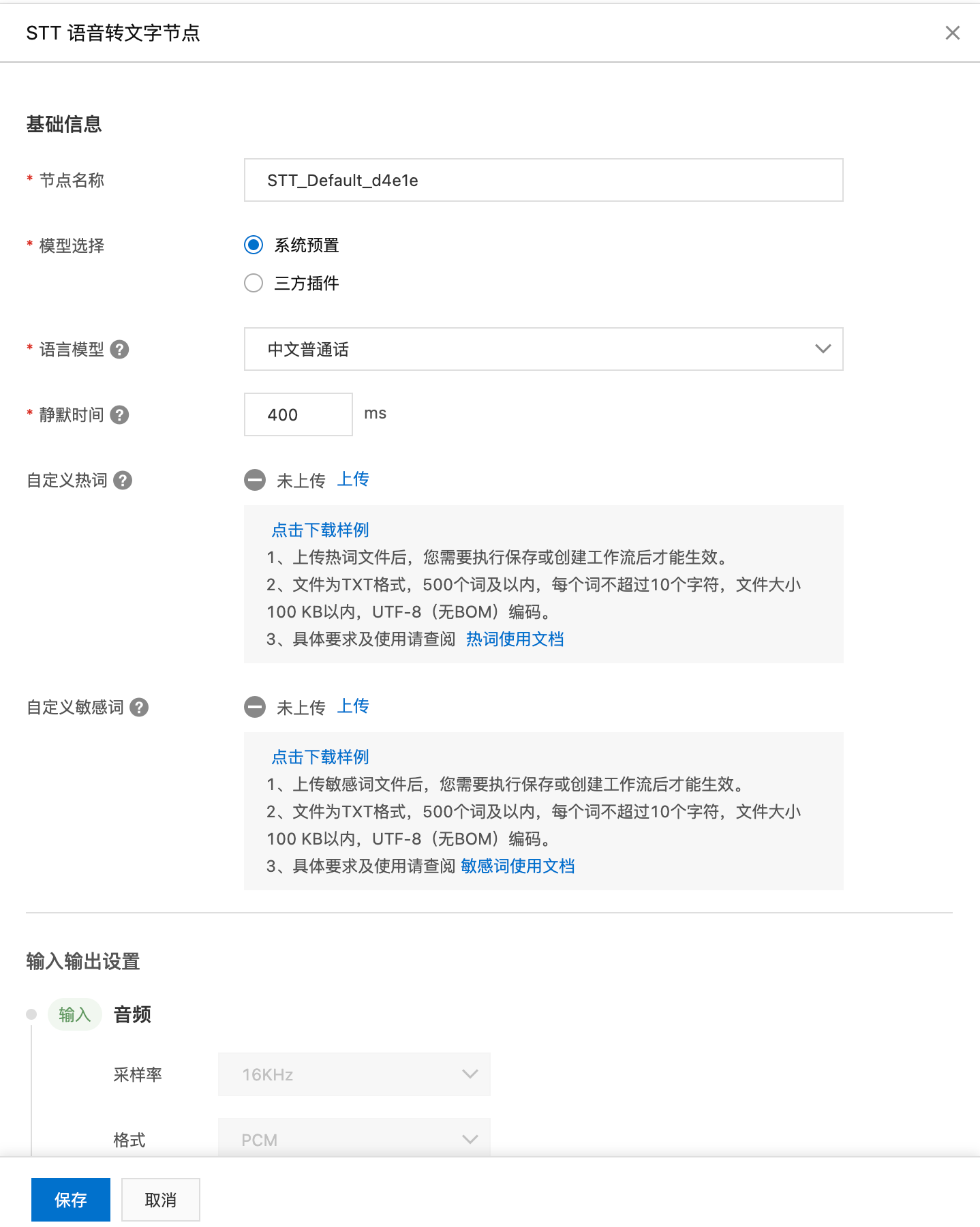
LLM 大语言模型
基于STT转换得到的文字输入,LLM可以使用大型预训练语言模型来理解和生成自然语言文本。
目前AI实时互动支持您接入通义千问(系统预置)、阿里百炼平台、阿里通义星尘以及自研接入(OpenAI规范)。
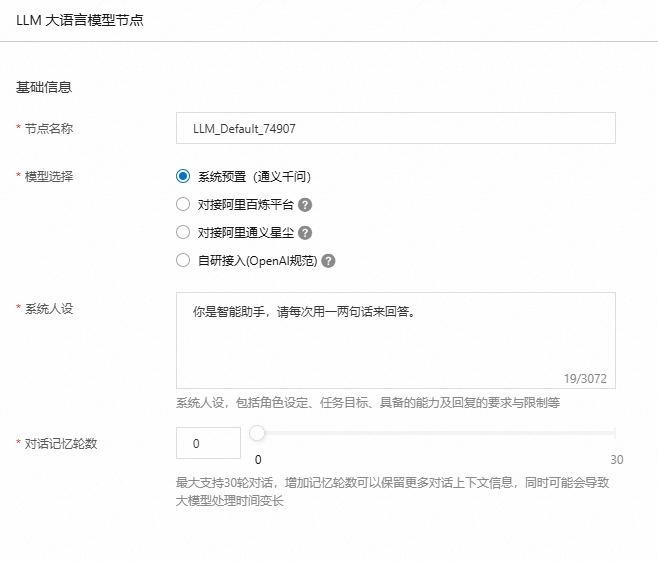
阿里百炼平台
阿里云的大模型服务平台阿里百炼是一站式的大模型开发及应用构建平台。选择对接阿里百炼平台提供的语言模型和服务时,您可以选择对接阿里百炼模型中心或应用中心。
模型中心:进入阿里百炼模型广场选择适合您的模型,复制模型Code获取作为ModelId。
应用中心:需要先在阿里百炼大模型服务平台创建智能体应用,完成后,获取AppId。
进入百炼API-KEY管理页面,创建并复制API-Key。

说明如何接入阿里百炼大模型,请参见阿里云百炼✖AI实时互动最佳实践。
阿里通义星尘
阿里通义星尘产品提供定制深度个性化智能体的能力,能够快速创造一个拥有自己独特的人设、风格的智能体,结合数字人语音实时交互能力,可以在指定的不同的场景中进行丰富的互动。
ModelId:目前阿里通义星尘有
xingchen-lite、xingchen-base、xingchen-plus、xingchen-plus-v2、xingchen-max五种模型供您选择。API-KEY:请前往星尘控制台创建API KEY并获取。

自研接入(OpenAI规范)
AI实时互动也支持接入您自研的大模型,您可以按照OpenAI规范接入您的大模型。
OpenAI规范:如果您选择按照OpenAI规范接入,您需要填入以下参数:
名称
描述
示例值
ModelId
OpenAI标准model字段,表示模型名称
abc
API-KEY
OpenAI标准api_key字段,表示API鉴权信息
AUJH-pfnTNMPBm6iWXcJAcWsrscb5KYaLitQhHBLKrI
目标模型HTTPS地址
OpenAI标准base_url字段,表示目标服务请求地址
http://www.abc.com
更多自研LLM接入详情,请参见LLM标准接口。
TTS 文字转语音
该节点负责将处理后的文本转换回语音格式,以便用户听到系统的响应。
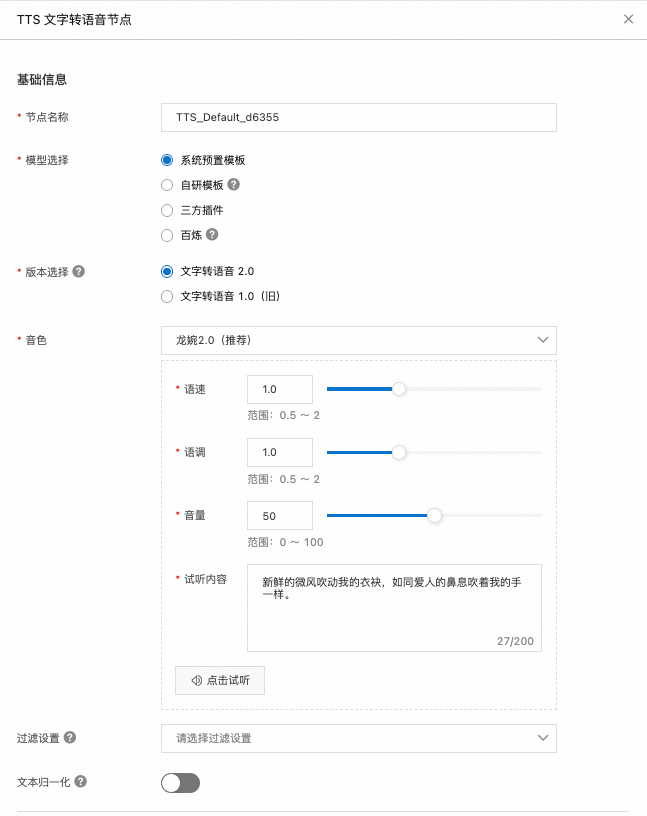
您可以选择适合您应用场景的文字转语音模型,包括:系统预置模板、自研模板、三方插件或百炼。
系统预置模板:选择预置模板时,您需要配置语音音色,各类型智能语音效果示例请参见智能语音效果示例。
自研模板:您可以通过规范协议将您的自研大模型加入到工作流当中。详情请参见TTS标准接口。
三方插件:当前仅支持选择MiniMax语音模型,目前有多个版本供您选择,推荐您使用最新版本。具体详情,请参见MiniMax语音模型。
百炼:如果您的业务需要应用自定义音色场景,建议您接入阿里百炼应用平台。接入详情,请参见声音复刻。
在TTS节点,您也可以对LLM输入的内容进行过滤。
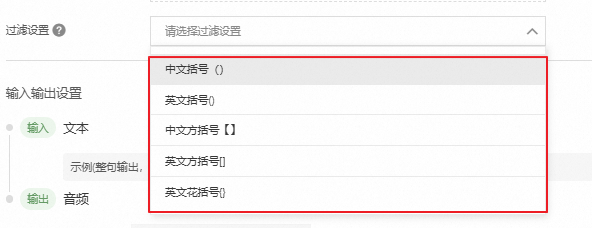
文本归一化:将文本中的数字、符号等转换为统一标准格式,提升合成语音的质量。如"120°转为“幺二零。
数字人
该节点负责生成与处理后的文本和音频相对应的动作、表情和口型同步的数字人视频流。
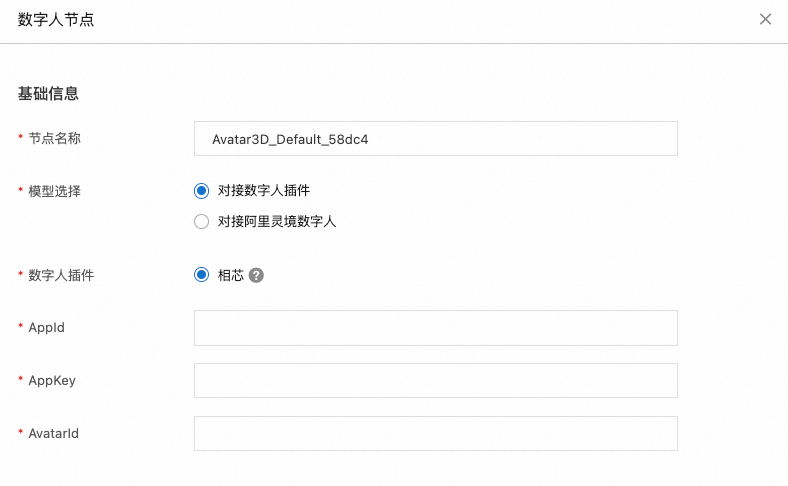
当前支持在数字人节点中对接数字人插件、对接阿里灵境数字人:
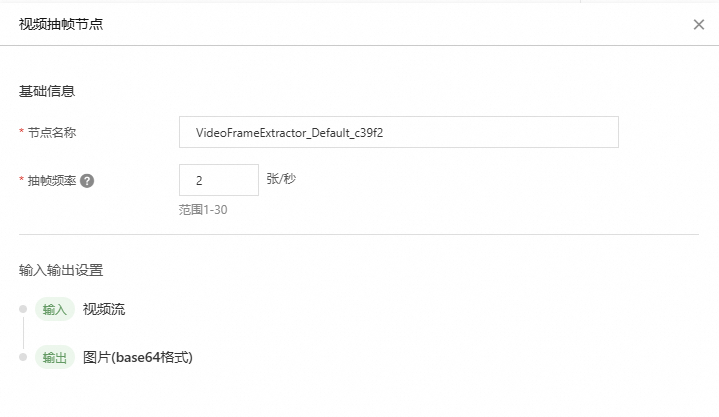
视频抽帧
该节点负责从视频中抽取单帧或多帧的图片。
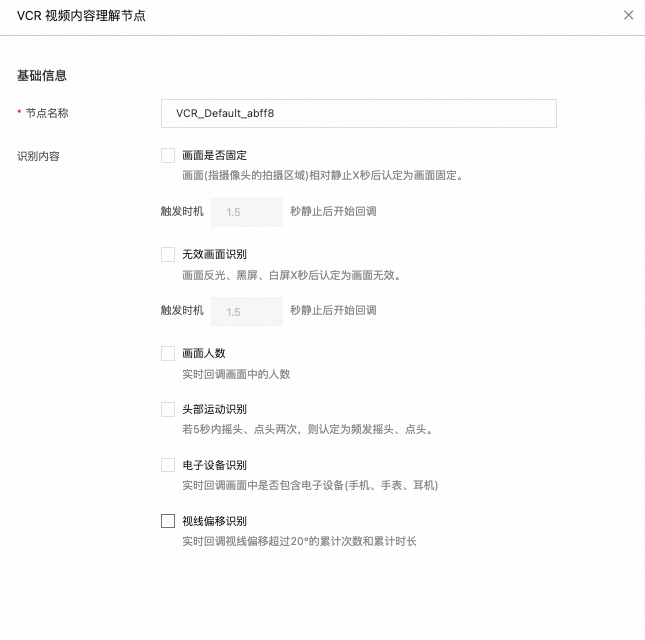
视频内容理解
该节点负责识别视频内容中,是否存在特定行为。
MLLM多模态大模型
基于前置节点对数据的处理,MLLM可以对输入的图片与文字进行理解,生成自然语言文本。您也可以通过选择不同类型的模型来控制模型的输入。

目前AI实时互动支持您接入通义千问(系统预置)、阿里百炼平台、阿里通义星尘以及自研大模型。
阿里百炼平台 阿里云的大模型服务平台阿里百炼是一站式的大模型开发及应用构建平台。选择对接阿里百炼平台提供的语言模型和服务时,您可以选择对接阿里百炼模型中心或应用中心。
模型中心:进入阿里百炼模型广场选择适合您的模型,复制模型Code获取作为ModelId。
应用中心:需要先在阿里百炼大模型服务平台创建智能体应用,完成后,获取AppId。
进入百炼API-KEY管理页面,创建并复制API-Key。
说明如何接入阿里百炼大模型,请参见阿里云百炼✖AI实时互动最佳实践。
通义星尘
通义星尘产品提供定制深度个性化智能体的能力,能够快速创造一个拥有自己独特的人设、风格的智能体,结合数字人语音实时交互能力,可以在指定的不同的场景中进行丰富的互动。
ModelId:目前通义星尘有
xingchen-lite、xingchen-base、xingchen-plus、xingchen-plus-v2、xingchen-max五种模型供您选择。API-KEY:请前往星尘控制台创建API KEY并获取。
自研模型
AI实时互动也支持接入您自研的大模型,您可以按照OpenAI规范接入您的大模型。
OpenAI规范:如果您选择按照OpenAI规范接入,您需要填入以下参数:
名称
类型
必填
描述
示例值
ModelId
String
是
OpenAI标准model字段,表示模型名称
abc
API-KEY
String
是
OpenAI标准api_key字段,表示API鉴权信息
AUJH-pfnTNMPBm6iWXcJAcWsrscb5KYaLitQhHBLKrI
目标模型HTTPS地址
String
是
OpenAI标准base_url字段,表示目标服务请求地址
http://www.abc.com
单次调用图片数上限
Integer
是
由于部分多模态大模型单次请求可接收图片帧数量有上限,您可以设置此参数来适配不同的大模型。在请求您的MLLM服务时,会自动按照该值对视频进行抽帧采样。
15
更多自研接入,请参考MLLM标准接口。
单击保存,完成音视频工作流创建。
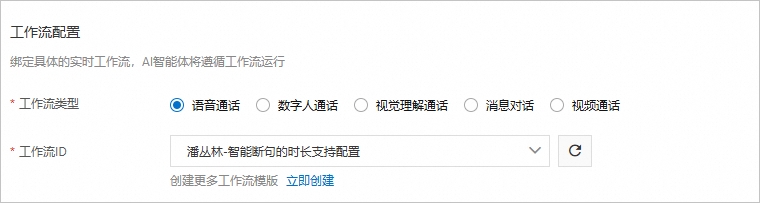
第二步 创建音视频智能体

第三步 体验智能体
消息对话智能体创建完成后,您可以通过扫描体验二维码来进行智能体的体验。
在控制台生成Demo体验二维码。

请使用钉钉、微信或浏览器扫描二维码,或将体验地址复制到浏览器中,以体验H5版本的Demo。

集成音视频智能体
您需要提前准备好以下参数,方便您进行集成。如何将音视频智能体集成到您的项目中,请参见音视频通话智能体集成。
Region ID:智能媒体服务控制台上工作流、智能体所在区域。
地域名称
Region Id
华东1(杭州)
cn-hangzhou
华东2(上海)
cn-shanghai
华北2(北京)
cn-beijing
华南1(深圳)
cn-shenzhen
新加坡
ap-southeast-1
ARTC应用的AppId和AppKey


AccessKey ID和AccessKey Secret:获取详情,请参见创建AccessKey。