
本文介绍如何使用智能语音交互语音对话的Python SDK,包括SDK的安装方法及SDK代码示例等。
前提条件
交互模式
Python SDK和Demo支持按键开始/按键结束交互的模式:
push to talk (./demo_push_to_talk/test_voice_chat.py)
使用Demo测试
编辑入口类,修改如下参数。
参数
说明
ws_url
域名地址。生产环境网关URL:
wss://nls-gateway-cn-beijing.aliyuncs.com/ws/v1appkey
语音对话服务接入的key。详情请参见创建项目。
token
访问系统的令牌。具体获取操作,请参见通过控制台获取Token。
运行程序。
# 执行示例 python3 test_voice_chat.py开始对话。
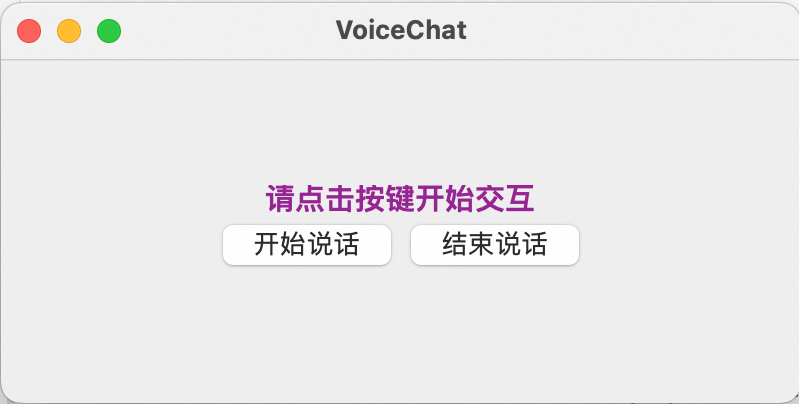
本文以Mac为例,拉起如下对话框之后进行交互:
单击开始说话,启动识别。
单击结束说话,结束识别。
语音播报过程中,单击「开始说话」停止播放,重新开始收音。
下载安装
接口说明
aliyun.tongyi.voice_chat.py:服务入口
Conversation()方法说明:
create_conversation:创建交互,设置回调。
""" 创建一个语音对话会话。 此方法用于初始化一个新的语音聊天会话,设置必要的参数以准备开始与模型的交互。 :param url: (str) API的URL地址。 :param voice_chat_callback: (VoiceChatCallback) 回调对象,用于处理来自服务器的消息。 :param appkey: (str) 应用程序密钥,用于身份验证。 :param token: (str) 访问令牌,用于授权请求。 :param model_id: (str) 模型ID,指定要使用的AI模型。 :param voice: (str) 语音类型,定义合成语音的音色。 :param prompt: (str) 提示信息,提供给AI模型作为对话的起始点。 :param max_end_silence: 最大结束静音时间,可选参数。 """ def create_conversation(self, url: str, voice_chat_callback: VoiceChatCallback, appkey: str, token: str, model_id: str, voice: str, prompt: str)start:启动voice_chat对话服务. 返回on_started回调。注意on_started会回调dialog_id。
""" 初始化WebSocket连接并发送启动请求 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def start(self, dialog_id):start_speech:通知服务端开始上传音频,注意需要在Listening状态才可以调用。
""" 开始上传语音数据 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def start_speech(self, dialog_id):send_audio_data:通知服务端上传音频。
""" 上传语音数据 :param speechData: bytes 语音数据 """ def send_audio_data(self, speechData):stop_speech:通知服务端结束上传音频。
""" 结束上传语音数据 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def stop_speech(self, dialog_id):interrupt:通知服务端,客户端需要打断当前交互,开始说话。
""" 结束交互,发送RequestToSpeak给服务端 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def interrupt(self, dialog_id):local_responding_started:通知服务端,客户端开始播放TTS音频。
""" 客户端开始播放tts音频 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def local_responding_started(self, dialog_id):local_responding_ended:通知服务端,客户端结束播放tts音频。
""" 客户端播放tts音频结束 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def local_responding_ended(self, dialog_id):stop:结束当前轮次voice_chat对话。
""" 结束当前轮次voice_chat对话 :param dialog_id: 对话ID,用于标识特定的对话会话 """ def stop(self, dialog_id):get_dialog_state:获得当前对话服务状态。DialogState枚举。
""" :return dialog_id: dialog_state.DialogState """ get_dialog_state(self)class VoiceChatCallback:回调函数。
class VoiceChatCallback: """ 语音聊天回调类,用于处理语音聊天过程中的各种事件。 """ def on_started(self, dialog_id: str) -> None: """ 通知对话开始 :param dialog_id: 回调对话ID """ pass def on_stopped(self) -> None: """ 通知对话停止 """ pass def on_state_changed(self, state: 'dialog_state.DialogState') -> None: """ 对话状态改变 :param state: 新的对话状态 """ pass def on_speech_audio_data(self, data: bytes) -> None: """ 合成音频数据回调 :param data: 音频数据 """ pass def on_error(self, error) -> None: """ 发生错误时调用此方法。 :param error: 错误信息 """ pass def on_connected(self) -> None: """ 成功连接到服务器后调用此方法。 """ pass def on_responding_started(self): """ 回复开始回调 """ pass def on_responding_ended(self): """ 回复结束 """ pass def on_speech_content(self, payload): """ 语音识别文本 :param payload: text """ pass def on_responding_content(self, payload): """ 大模型回复文本。 :param payload: text """ pass def on_request_accepted(self): """ 打断请求被接受。 """ pass def on_close(self, close_status_code, close_msg): """ 连接关闭时调用此方法。 :param close_status_code: 关闭状态码 :param close_msg: 关闭消息 """ pass
DialogState:对话状态说明
语音对话服务包括以下三种状态:
状态 | 说明 |
LISTENING | 表示机器人正在监听用户输入。用户可以发送音频。 |
THINKING | 表示机器人正在思考。 |
RESPONDING | 表示机器人正在生成语音或语音回复中。 |
时序图
