
通义灵码提供了企业代码补全增强的能力,在开发者使用通义灵码 代码生成时,可以结合企业上传的代码库作为上下文进行行间代码补全,使代码补全更加贴合企业代码规范、业务特点。本文将分享如何构建高质量的企业代码库,以及开发者在前端和后端开发场景的使用实践。
适用版本与支持语言
适用版本 | 支持后端 | 支持前端 |
企业标准版 | Java、C#、C/C++、Go、Python | JavaScript、TypeScript、Vue、React |
企业专属版 |
管理员如何准备高质量企业代码库
为确保代码数据的有效处理,我们建议您遵循以下指导原则来准备代码库。这将有助于提升检索的效率与准确性。
代码库的选择和准备指导
下文将介绍在两类不同场景下您应该如何进行代码库的准备:
场景一 日常工程开发,提升研发效率
在企业开发中,为了提高代码复用和开发效率,可以利用多种代码仓库来支持检索增强功能。以下是几种主要的代码仓库选择方式:
后端场景的代码库准备
【推荐】挑选高频代码片段或文件:选择在当前开发工程中频繁出现或被多次使用的代码片段。这些代码片段通常具有高度引用性和重复使用的特点,适合作为知识库的内容。将满足上述条件的某个工程内的代码片段或代码文件整理成一个独立的代码库,并上传到一个独立的知识库中,以便于管理和调用。
当前项目的工程代码:也可以将整个当前项目工程放入知识库,可以实现跨整个代码库的全面检索,从而提高代码复用和开发效率。但如果工程中存在干扰性代码或大量质量不高的代码,则会影响代码补全增强的效果。
前端场景的代码库准备
重要上传使用组件库的代码仓库,而不是组件源代码仓库。并且覆盖的使用场景越全越好。
【推荐】前端模板页面代码库:通过拼装企业自定义组件,将那些通用性强且与具体业务紧密相关的前端页面封装成模板。这类模板页面代表了最高质量的实践案例,例如登录页、注册页、账户展示、转账等。如果您的企业已经建立了这样的模板库,建议优先将其上传到企业代码知识中。
当前项目的工程代码库:当前项目的代码库是包含了与当前开发任务最相关的代码,对于那些编写得当、结构清晰且具有良好实践的工程代码,将其上传到企业的代码知识库,可以实现跨整个代码库的全面检索,从而提高代码复用和开发效率。但请注意,如果当前项目代码库中存在干扰性代码或大量质量不高的代码,则会影响代码补全增强的效果。
场景二 特定业务场景下,确保代码一致性,减少重复开发
在企业级应用开发中,某些业务逻辑需要保持一致性以确保系统的稳定性和可维护性。在缺乏统一标准的情况下,不同开发者可能会采用不同的实现方式,导致业务逻辑不一致,增加代码维护的复杂性,并可能引发系统稳定性问题。
场景案例一:企业框架和中间件实现的逻辑复用
某企业在其商品售卖系统中,库存管理需要采用统一的分布式锁机制。通过将企业自研的业务框架整合到代码知识库中,开发者在IDE端编写相关业务逻辑时,能够方便地召回并复用这些标准化的代码片段,从而提升开发效率,减少重复开发,提高代码质量,并保证业务逻辑的一致性。
代码库的选择和准备:
明确目标业务模式和具体实现机制:
识别关键业务模块:确定系统中需要统一实现的关键业务逻辑模块,例如库存管理、订单处理、支付系统等。
细化具体业务的实现机制:例如,在库存管理中,可能涉及到库存扣减、库存查询、库存锁定等不同场景,每个场景可能需要不同的实现机制。
选择相关业务框架内的代码文件并放入企业代码知识库:
从业务框架中筛选出实现关键业务逻辑的核心代码,整理并放入到独立的代码知识库中。例如,库存扣减需要使用分布式锁机制确保并发安全,那么选择实现分布式锁的核心代码模块。
/** * 使用企业自研的分布式锁框架进行并发控制 */ @Service public class InventoryService { @Autowired private DistributedLockFramework lockFramework; @Autowired private InventoryRepository inventoryRepository; /** * 扣减库存,使用分布式锁确保并发安全 * @param productId 产品ID * @param quantity 扣减数量 * @return 是否扣减成功 */ public boolean deductInventory(Long productId, int quantity) { String lockKey = "inventory:" + productId; return lockFramework.withLock(lockKey, 30, TimeUnit.SECONDS, () -> { Inventory inventory = inventoryRepository.findByProductId(productId); if (inventory == null || inventory.getQuantity() < quantity) { return false; } inventory.setQuantity(inventory.getQuantity() - quantity); inventoryRepository.save(inventory); return true; }); } }
场景案例二:企业核心业务逻辑复用
某企业希望建立一种统一的个性化推荐策略应用于其商品推荐系统。通过将自主研发的业务架构融入代码知识库,当开发人员在集成开发环境(IDE)中编写相关功能时,能够轻松访问并重复利用这些已标准化的代码模块。这样做不仅能够加速软件开发过程,避免不必要的重复工作,还能提升代码的整体质量,同时确保整个系统内业务逻辑的一致性和稳定性。
代码库的选择和准备:
明确目标业务模块和具体行为:
识别关键业务模块:首先需要确定系统中哪些关键业务逻辑模块需要统一实现,例如商品推荐系统。
细化具体的行为:其次,需要具体的业务行为和核心操作步骤:例如,在个性化推荐策略中,可能包括获取用户行为数据、提取用户兴趣特征、获取候选商品池、计算商品得分并进行排序、以及返回得分最高的商品等几个核心步骤。这些步骤的实现通过固定的代码组合来完成。
选择相关业务框架内的代码文件并放入企业代码知识库:
从业务框架中挑选出实现关键业务逻辑的核心代码,整理后存放到独立的代码知识库中。以推荐系统的个性化推荐机制为例,以下是一个代码示例:
/** * 推荐引擎服务 * 实现了基于用户行为和商品特征的个性化推荐机制 */ @Service public class RecommendationService { @Autowired private UserBehaviorRepository userBehaviorRepo; @Autowired private ProductRepository productRepo; /** * 为指定用户生成个性化推荐列表 * @param userId 用户ID * @param limit 推荐数量 * @return 推荐的商品ID列表 */ public List<Long> generateRecommendations(Long userId, int limit) { // 获取用户行为数据 List<UserBehavior> behaviors = userBehaviorRepo.findRecentByUserId(userId, 100); // 提取用户兴趣特征 Map<String, Double> userInterests = extractUserInterests(behaviors); // 获取候选商品池 List<Product> candidateProducts = productRepo.findRecentlyActive(1000); // 计算商品得分并排序 List<ScoredProduct> scoredProducts = candidateProducts.stream() .map(product -> new ScoredProduct(product, calculateScore(product, userInterests))) .sorted(Comparator.comparing(ScoredProduct::getScore).reversed()) .collect(Collectors.toList()); // 返回得分最高的商品 return scoredProducts.stream() .limit(limit) .map(sp -> sp.getProduct().getId()) .collect(Collectors.toList()); } // 其他辅助方法... }
重要对提取出的目标业务模块的代码进行适当的注释说明,以便开发者后续在IDE端可以通过行间注释方便召回代码片段。
场景案例三:参考旧项目,以提升新项目研发效率
企业在进行新项目研发时,通过复用旧项目中的核心相似模块代码,提高了开发效率,减少从零开始编写所有代码所需的时间和成本,确保新项目的质量更加可靠。
代码库的选择和准备:
明确目标业务和场景识别关键业务模块:
确定相似功能:首先明确旧项目和新项目之间的相似功能和实现部分。例如,如果旧项目和新项目都涉及用户管理、商品展示和订单处理等功能,这些模块可以作为重点。
评估代码质量:确保旧项目的代码已经经过充分测试,并且是稳定可靠的。清理不必要的文件和配置,确保代码库中的内容是干净和可复用的。
细化具体业务行为及核心动作:
提取核心功能:在旧项目中,针对已明确可复用的模块,提取出关键的核心功能模块代码。例如:
用户管理:用户注册、登录、信息修改等。
商品展示:商品列表、详情页、搜索功能等。
订单处理:创建订单、支付处理、订单状态更新等。
重要对提取出核心功能模块的代码进行适当的注释说明,以便开发者后续在IDE端可以通过行间注释方便召回代码片段。
选择相关业务框架内的代码文件并放入企业代码知识库。将旧项目的代码按照模块化结构重新整理,根据新项目各模块负责团队的分工实现代码隔离,并建立独立的模块代码库:
代码知识库隔离:根据项目的功能模块,将准备好的旧项目代码上传到相应的代码知识库中。例如,将用户管理模块、商品展示模块、订单处理模块等分别存放在不同的独立知识库下。
权限管理:设置合适的访问权限,确保只有相关开发团队对该模块的知识库可见,避免在IDE端进行代码补全时造成不必要的干扰。
代码文件的规范
支持语言及框架:
后端:Java、C#、C/C++、Go、Python。
前端:JavaScript、Typescript、Vue、React。
上传限制:仅适用于源代码文件,代码库中应仅上传实际编写的源代码文件。例如,对于Java应上传
.java文件,对于C#应上传.cs文件,对于JavaScript应上传.js或.jsx文件等。请避免上传以下内容:
测试数据与代码:请勿上传测试脚本、测试用例或任何不包含业务逻辑的测试相关代码。
Mock方法:排除所有由模拟方法和工具生成的代码,除非这些代码包含对业务逻辑的具体实现。
构建产物:
前端:排除通过构建工具(如Webpack、Gulp等)生成的文件,这些文件通常位于
dist或build目录下。后端:排除编译生成的DLL文件及其他所有编译输出。
注释要求如下。
对希望被检索到的函数,在函数头部应添加详尽的注释。
注释应提供充分的信息以区分不同的函数,建议参考注释模板或根据企业规范进行相应调整。
/** * 更新指定订单状态。 * * @param orderId 订单的唯一标识符。 * @param newStatus 新的订单状态。 * @return boolean 表示更新是否成功。 */
函数名称规范要求。
如果函数注释较为简单,则函数名称必须能够准确描述其功能。
使用清晰且具描述性的命名方式,例如:
exportOrdersToPDF、updateOrderStatus而不是func1。
上传指南
打包压缩文件:将代码文件打包为
.zip、.gz或.tar.gz格式。代码包大小限制:每个代码包的大小不得超过100 MB。
开发者如何使用企业代码生成增强
后端场景使用实践
通过自然语言注释生成代码。
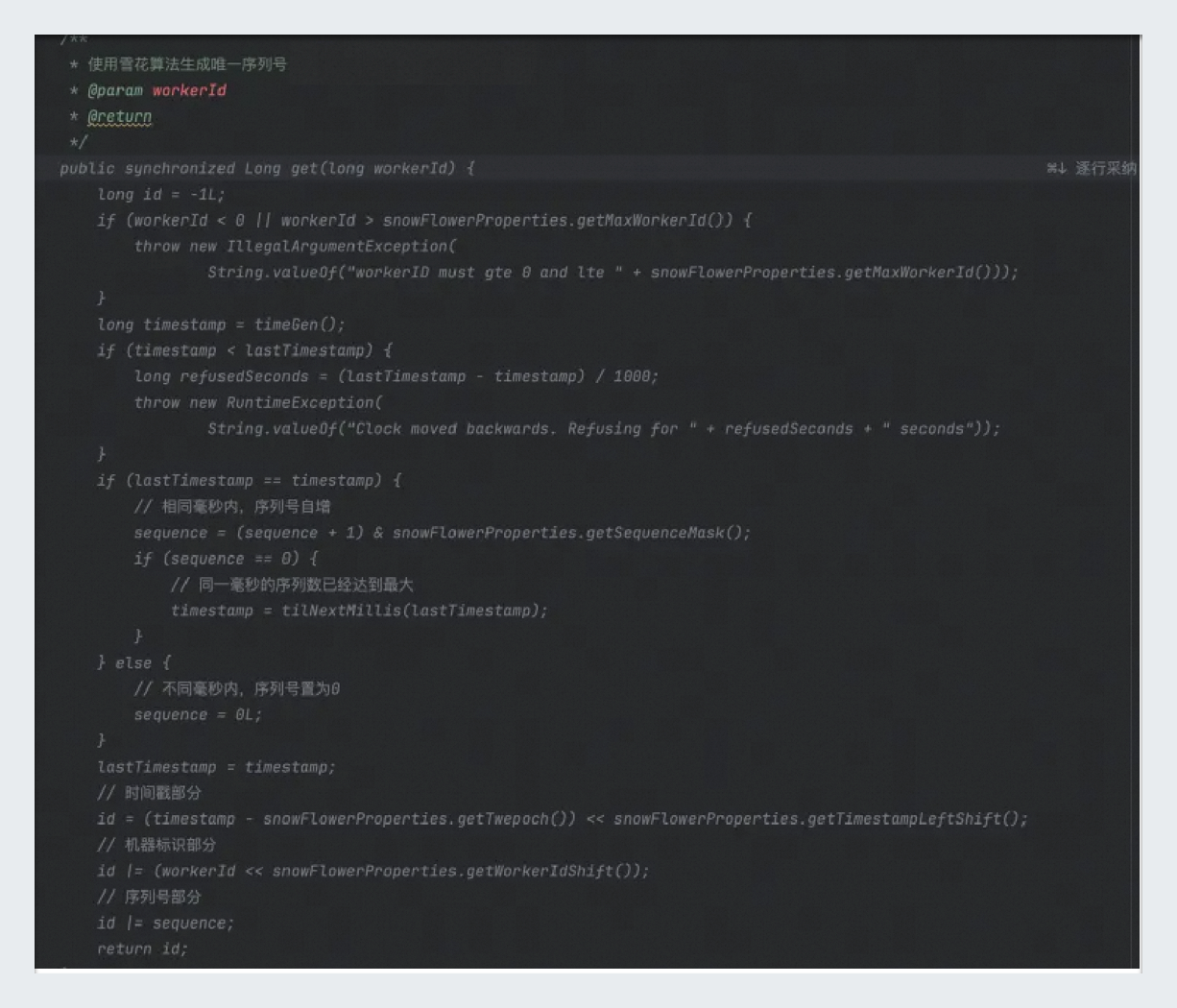
企业代码库代码上传:上传包含所需功能代码的压缩包至企业代码库,例如雪花算法的代码,并确保目标函数遵循注释规范,注释位于函数头部。更详细代码库准备指南请参见上述管理员如何准备高质量企业代码库。
/** * 使用雪花算法生成唯一序列号 * @param workerId * @return */ public synchronized Long getSnowFlowerId(long workerId){ long id = -1L; if (workerId < 0 || workerId > snowFlowerProperties.getMaxWorkerId()) { throw new IllegalArgumentException( String.valueOf("workerID must gte 0 and lte " + snowFlowerProperties.getMaxWorkerId())); } // ... 算法实现代码 ... return id; }输入注释:在集成开发环境(IDE)中定位到某Java类内,输入与期望召回的函数相匹配的注释。注释格式可以灵活,但应确保含义的准确性和一致性。
第一种方式
//请通过雪花算法生成唯一编号的代码,返回生成的id第二种方式
/** * 使用雪花算法生成唯一序列号 * @param wId * @return */注释说明。
注释长度要求:在编写代码时,注释应尽量避免过于简短,建议长度至少15个字符,过短的注释将无法触发召回。
注释语义要求:确保注释的语义准确且有意义,最好包含关键词与返回值说明,以便通义灵码准确地理解和匹配相应的代码。
多语言支持:支持中英文注释,代码库中的注释和实际编码时的注释可以使用不同的语言。
参数名称灵活性:参数名称可以灵活处理,通义灵码会根据提供的参数自动调整以匹配召回的代码。如下反例。
//雪花算法问题:没有提供足够的信息,注释长度过短。//生成唯一序列号问题:没有使用具体关键词,可能会影响理解和匹配效果。
代码生成:首次回车后,通义灵码将提供基于注释生成补全建议;再次回车后,通义灵码将根据企业代码库中的代码进行补全。
 说明
说明如果您的注释中包含参数,通义灵码将自动调整生成代码中的参数,确保命名一致性。
如果需要刷新缓存获取新的补全建议,macOS可以使用
⌥(option)P手动触发行间补全,Windows可以使用AltP手动触发。
通过函数签名生成代码。
代码库代码上传:上传包含所需功能代码的压缩包至企业代码库,并确保这些函数具有清晰且独特的标识,以便于检索和识别。更详细代码库准备指南请参见上述管理员如何准备高质量企业代码库。
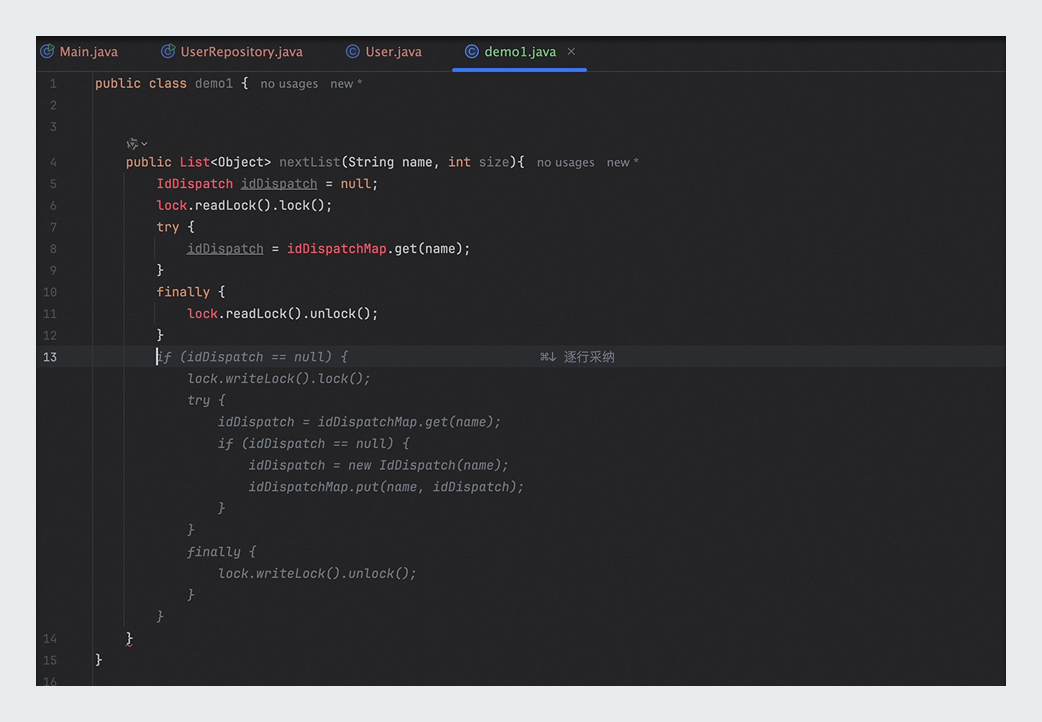
输入函数签名:在集成开发环境(IDE)中定位到某Java类内,键入目标函数的签名部分。参数名称可以灵活处理,通义灵码会根据提供的参数自动调整以匹配召回的代码。
public List<Object> nextList(String name, int size)函数签名说明。
函数名称:使用较为清晰的函数名称,需要具备一定语义作为相似性依据。
参数和返回值:类型和顺序需要与目标函数保持一致,但参数名称可以灵活处理,通义灵码会根据提供的参数自动调整以匹配召回的代码。如下反例。
public List<Object> func1(String name, int size)// 问题:函数名语义不清晰,无法准确反映函数功能public List<String> nextList(int orderId)// 问题:参数类型和返回值类型,与目标函数不匹配
代码补全:首次回车后,通义灵码将提供代码补全建议;再次回车后,通义灵码将根据企业代码库中的代码进行自动补全。
 说明
说明通义灵码将根据您提供的参数名,自动调整生成代码中的参数名,确保命名一致性。
如果需要刷新缓存获取新的补全建议,macOS可以使用
⌥(option)P手动触发行间补全,Windows可以使用AltP手动触发。
前端场景使用实践
通过标签补全前端自研组件代码。
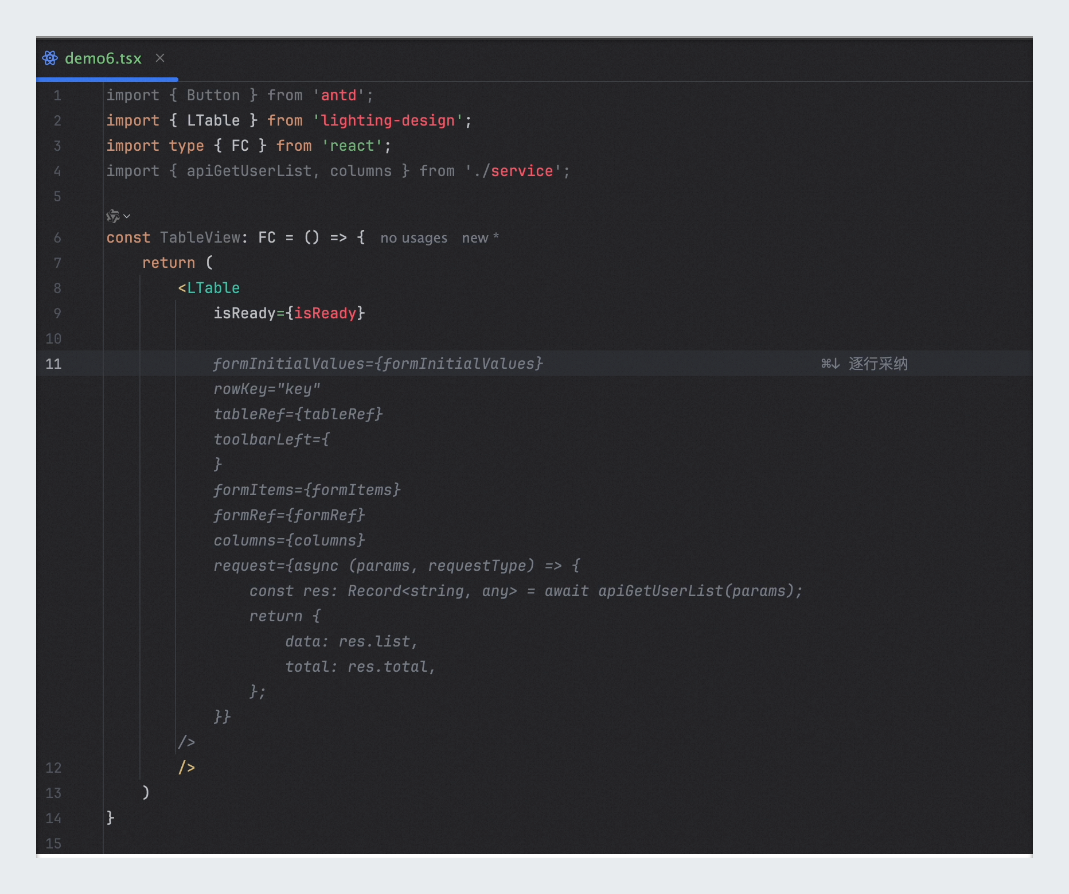
代码库代码上传:在开始之前,您需要确保所有必要的前端组件代码已经上传到企业代码库中。如下是React框架示例。
<LTable isReady={isReady} formInitialValues={formInitialValues} rowKey="key" tableRef={tableRef} toolbarLeft={ <Button type="primary">新增</Button> } formItems={formItems} formRef={formRef} columns={columns} request={async (params, requestType) => { const res: Record<string, any> = await apiGetUserList(params); return { data: res.data, total: res.total, }; }} />编写组件代码: 在您的IDE中打开相应的.jsx文件,并开始编写代码。输入基础HTML标签或自定义组件标签,例如
<LTable />。代码自动补全: 当您输入的代码达到一定长度,并且能够与企业组件库中的代码匹配时,IDE将自动触发代码补全功能,为您生成完整的组件代码。您也可以通过回车,主动触发代码补全。
 重要
重要请在完整的组件标签内触发您的补全。
通过自然语言注释生成代码。
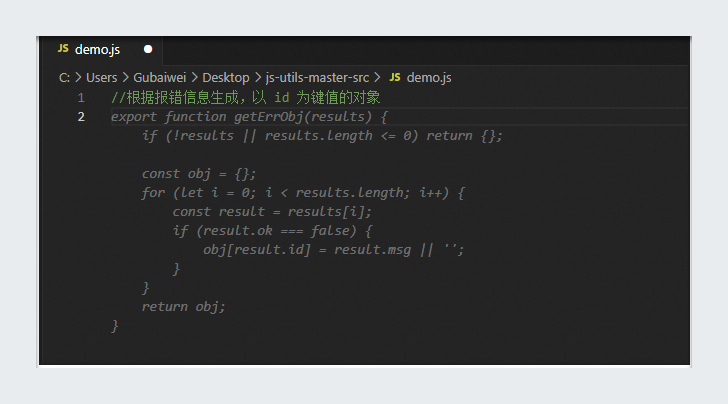
代码库代码上传:上传包含所需功能代码的压缩包至企业代码库,并确保每个函数都遵循注释规范,注释位于函数头部。 更详细代码库准备指南见管理员如何准备高质量企业代码库章节。如下是JavaScript示例。
/** * 根据报错信息生成,以id为键值的对象 * @param {Array<validator,Result>} results * @return {Record<string,string>} */ function getErrObj(results) { // ... 函数实现代码 ... }输入注释:在IDE中,在JavaScript文件内输入特定的注释内容,如下示例。
//根据报错信息生成以 id 为键值的对象注释说明。
注释长度要求:在编写代码时,注释应尽量避免过于简短,建议长度至少15个字符,过短的注释将无法触发召回。
注释语义要求:确保注释的语义准确且有意义,最好包含关键词与返回值说明,以便通义灵码准确地理解和匹配相应的代码。
多语言支持:支持中英文注释,代码库中的注释和实际编码时的注释可以使用不同的语言。
参数名称灵活性:参数名称可以灵活处理,通义灵码会根据提供的参数自动调整以匹配召回的代码。
代码生成:首次回车后,通义灵码将提供基于注释生成补全建议;再次回车后,通义灵码将根据企业代码库中的代码进行补全。
如果您的注释中包含参数,通义灵码将自动调整生成代码中的参数名,确保命名一致性。
如果需要刷新缓存获取新的补全建议,macOS可以使用
⌥(option)P手动触发行间补全,Windows可以使用AltP手动触发。
常见问题
在重新安装后,即使重启IDE或重新登录,仍无法成功召回知识库中的代码。
解决方案:
在macOS系统中,请执行以下命令以重启进程并清除缓存。
ps -ef|grep lingma|grep start|awk '{print $2}'|xargs -I {} kill -9 {}如果是Windows系统,请在进程管理器中结束Lingma进程。