本文为您介绍产生数据膨胀的原因及处理措施。
问题现象
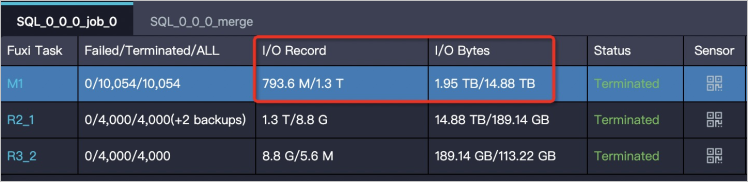
在Logview中查看Fuxi Task的输出数据量比输入数据量大很多。输入、输出数据量可以通过Fuxi Task的I/O Record和I/O Bytes属性获取。
如下图所示,输入数据量为1 GB,经过处理后输出数量变为1 TB。在一个Instance下处理1 TB的数据,运行效率会大大降低。
产生原因&处理措施
产生该问题的可能原因及对应的处理措施如下。
| 产生原因 | 描述 | 处理措施 |
|---|---|---|
| 代码存在缺陷 | 代码缺陷,例如:
|
修正代码。 |
| 聚合操作引起的数据膨胀 |
大多数聚合操作是具备递归性的,会对中间结果进行合并(MERGE)。通常中间结果数据量不大,而且大多数聚合操作的计算复杂度比较低,即使数据量不小,也能较快完成。所以通常情况下,聚合操作的问题不大。但某些聚合操作,例如
collect_list、median,需要把全量中间数据都保留下来,在配合其他聚合用法时,可能会产生数据膨胀,例如:
|
避免使用聚合的特殊用法。 |
join操作引起的数据膨胀
|
例如,对两个表执行join操作,左表是人口数据,数据量很大。右表是张维表,记录每种性别对应的一些信息。虽然只有两种性别,但是每种性别都包含数百行数据。如果直接按照性别执行join,可能会让左表数据膨胀数百倍。
|
对右表的行做聚合操作后,再与左表执行join操作,即可规避数据膨胀问题。
|