本文介绍基于Flink创建Paimon DLF Catalog,读取MySQL CDC业务数据写入DLF,进而使用MaxCompute的外部项目进行数据湖联邦查询分析,再将结果写回到DLF。本文使用新版本DLF,区别于旧版DLF1.0。新版本DLF更多信息参见数据湖构建。
前提条件
操作步骤
步骤一:源数据准备
如有其他MySQL测试数据,可跳过此步骤。
此步骤模拟业务系统实时更新的数据,通过Flink以Paimon的格式写入湖上。
登录到RDS MySQL控制台,左上角选择地域。
在左侧导航栏,选择实例列表。在实例列表页面,单击目标实例ID,进入实例详情页。
在左侧导航栏,单击数据库管理。
单击新建数据库。配置如下参数:
参数
是否必填
说明
示例
数据库(DB)名称
必填
长度为2~64个字符。
以字母开头,以字母或数字结尾。
由小写字母、数字、下划线或中划线组成。
数据库名称在实例内必须是唯一的。
数据库名称中如果包含
-,创建出的数据库的文件夹的名字中的-会变成@002d。
mysql_paimon支持字符集
必填
请按需选择字符集。
utf8授权账号
选填
选中需要访问本数据库的账号。本参数可以留空,创建数据库后再绑定账号。
此处仅会显示普通账号。高权限账号拥有所有数据库的所有权限,无需授权。
默认备注说明
选填
用于备注该数据库的相关信息,便于后续数据库管理,最多支持256个字符。
创建flink测试库。单击数据库管理页面,右上角登录数据库,在左侧导航栏选择数据库实例,选中已创建的数据库,在右侧SQLConsole页面执行下列语句,创建测试表并写入测试数据。
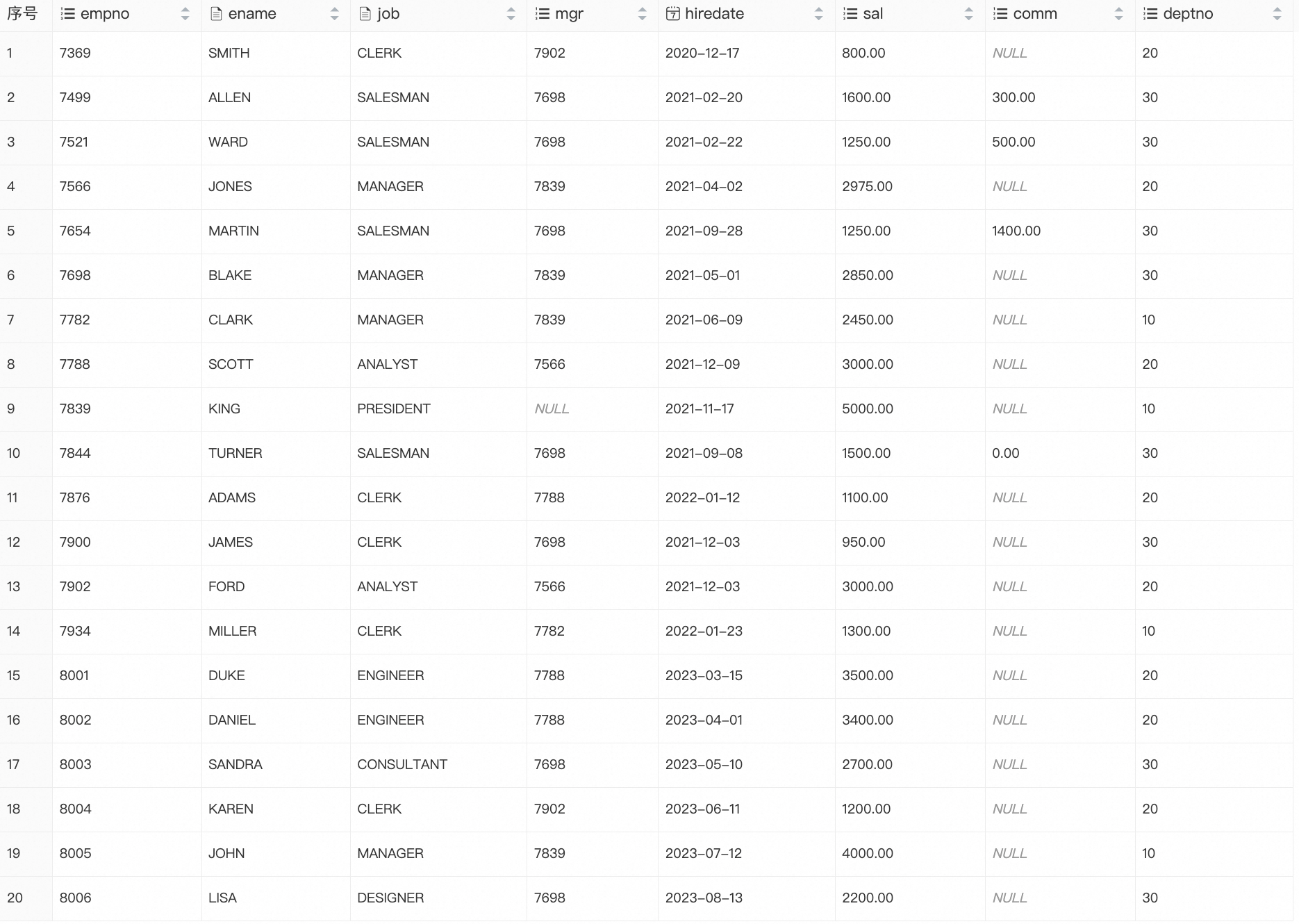
CREATE TABLE emp ( empno INT PRIMARY KEY, ename VARCHAR(20), job VARCHAR(20), mgr INT, hiredate DATE, sal DECIMAL(10,2), comm DECIMAL(10,2), deptno INT ); INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,'2020-12-17', 800.00,NULL,20), (7499,'ALLEN','SALESMAN',7698,'2021-02-20',1600.00,300.00,30), (7521,'WARD','SALESMAN',7698,'2021-02-22',1250.00,500.00,30), (7566,'JONES','MANAGER',7839,'2021-04-02',2975.00,NULL,20), (7654,'MARTIN','SALESMAN',7698,'2021-09-28',1250.00,1400.00,30), (7698,'BLAKE','MANAGER',7839,'2021-05-01',2850.00,NULL,30), (7782,'CLARK','MANAGER',7839,'2021-06-09',2450.00,NULL,10), (7788,'SCOTT','ANALYST',7566,'2021-12-09',3000.00,NULL,20), (7839,'KING','PRESIDENT',NULL,'2021-11-17',5000.00,NULL,10), (7844,'TURNER','SALESMAN',7698,'2021-09-08',1500.00,0.00,30), (7876,'ADAMS','CLERK',7788,'2022-01-12',1100.00,NULL,20), (7900,'JAMES','CLERK',7698,'2021-12-03', 950.00,NULL,30), (7902,'FORD','ANALYST',7566,'2021-12-03',3000.00,NULL,20), (7934,'MILLER','CLERK',7782,'2022-01-23',1300.00,NULL,10), (8001,'DUKE','ENGINEER',7788,'2023-03-15',3500.00,NULL,20), (8002,'DANIEL','ENGINEER',7788,'2023-04-01',3400.00,NULL,20), (8003,'SANDRA','CONSULTANT',7698,'2023-05-10',2700.00,NULL,30), (8004,'KAREN','CLERK',7902,'2023-06-11',1200.00,NULL,20), (8005,'JOHN','MANAGER',7839,'2023-07-12',4000.00,NULL,10), (8006,'LISA','DESIGNER',7698,'2023-08-13',2200.00,NULL,30);查询测试表数据。
SELECT * FROM emp;返回结果:
步骤二:同步源数据至DLF
若DLF中已有测试数据,可跳过此步骤。
新建Catalog。
登录数据湖构建(DLF)控制台,进入DLF版本,在左上角选择对应地域。
点击左侧导航栏数据目录,单击新建Catalog。
进入数据湖构建页面,填写如下参数:
参数
是否必填
说明
Catalog 类型
必填
默认为Paimon Catalog,选择Paimon Catalog时,湖表存储格式为Paimon,新业务推荐使用该类型。
Catalog 名称
必填
自定义Catalog名称,以字母开头,1-256位,a-ZA-Z0-9_,例如db_dlf_oss。
描述
选填
自定义描述。
存储类型
必填
标准存储。
存储冗余类型
必填
本地冗余:本地冗余为数据存储在单 AZ (可用区);当本地冗余存储该 AZ(可用区)不可用时,会导致相关数据不可访问,推荐使用同城冗余;
同城冗余:为同 Region 内多 AZ(可用区)冗余机制,当某单个 AZ 不可用时,依然能保证数据可用;Catalog 创建后同城冗余不可变更为本地冗余,同城冗余相对本地冗余数据有更好的可用性,价格也更高,数据有更高可行性要求的推荐使用同城冗余。
智能存储分层
必填
开启后,系统将根据配置的生命周期规则,自动对Catalog下所有表进行冷热分层。请根据业务需求填写如下参数:
低频、归档、冷归档,分别有 30 天、60 天、180 天的最小保留天数限制(如果提前删除也将按最小限制天数收费)。
通过生命周期转存储类型时,会产生对应的请求次数费用,请谨慎设置。
冷归档为本地冗余存储类型,其数据冗余在某个特定的可用区内,当该可用区不可用时,会导致相关数据不可访问,如业务需要更高的可用性保障,强烈建议使用同城冗余存储类型(标准、低频、归档)来存储和使用数据。
转储为冷归档后,访问前需要先进行解冻,在解冻配额内解冻时延为 2~5 小时,解冻完成前无法访问数据,请慎重操作。
创建Paimon Catalog。
登录Flink控制台,单击目标工作空间名称。
在左侧菜单栏,选择数据管理。
在右侧Catalog列表界面,单击创建Catalog,在弹出的创建 Catalog对话框里,选择Apache Paimon,单击下一步并配置如下参数:
参数
是否必填
说明
metastore
必填
元数据存储类型。本示例中选择
dlf。catalog name
必填
选择需要关联版本的DLF Catalog。
创建MySQL catalog。
登录Flink控制台。
添加白名单。
单击目标工作空间的操作列详情,复制网段信息。
在RDS MySQL控制台,单击左侧导航栏,选择实例列表。在实例列表页面,单击目标实例ID,进入实例详情页。
单击左侧导航栏白名单与安全组,在右侧白名单设置页签,单击修改。
在弹出的修改白名单分组对话框,组内白名单位置添加
步骤ii中复制的网段信息,单击确定。
在Flink控制台,单击目标工作空间名称,在左侧菜单栏,选择数据管理。
在右侧Catalog列表界面,单击创建catalog,在弹出的创建 Catalog对话框里,选择MySQL,单击下一步并配置如下参数:
参数
是否必填
说明
catalog name
必填
自定义MySQL Catalog名称。
hostname
必填
MySQL数据库的IP地址或者Hostname。跨VPC或公网访问时需要打通网络,详情请参见网络连通性。
port
默认
连接到服务器的端口,默认为3306。
default database
必填
默认数据库名称。例如
mysql_paimon。username
必填
连接MySQL数据库服务器时使用的用户名。可在实例详情页,单击账号管理查看。
password
必填
连接MySQL数据库服务器时使用的密码。可在实例详情页,单击账号管理查看。
读MySQL写Paimon。基于Flink读MySQL数据写入到DLF的Paimon表。
登录Flink控制台,单击目标工作空间名称。
在左侧导航栏,选择,在作业草稿页签,单击
 ,新建文件夹。
,新建文件夹。右键文件夹,选择新建流作业,在弹出的新建作业草稿对话框,填写文件名称并选择引擎版本。
在文件中写入并执行如下SQL语句。注意根据实际命名修改代码中的相关命名。
CREATE TABLE IF NOT EXISTS `paimon_catalog`.`default`.`emp` WITH ( 'bucket' = '4', 'changelog-producer' = 'input' ) AS TABLE `mysql-paimon-catalog`.`mysql_paimon`.`emp`;(可选)单击右上方的深度检查,确认作业Flink SQL语句中是否存在语法错误。
单击右上角部署,在弹出的部署新版本对话框中填写备注、作业标签和部署目标等信息,然后单击确定。
在左侧导航栏,,选择,单击目标作业名称,进入作业部署详情页面。
在目标作业部署详情页右上角,单击启动,选择无状态启动后,单击启动。
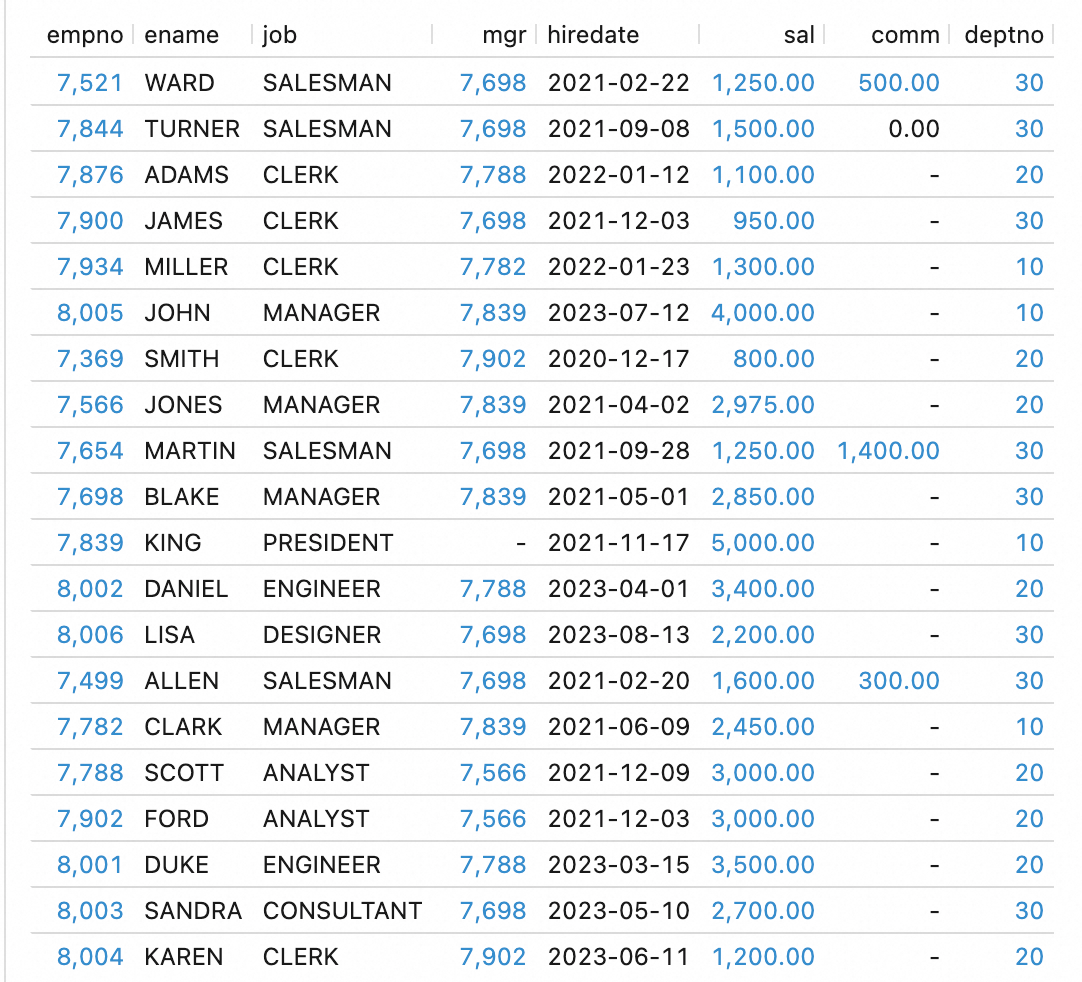
查询Paimon数据。在左侧导航栏,选择页面的查询脚本页签,单击
,新建查询脚本。运行如下代码:SELECT * FROM `<paimon_catalog_name>`.`default`.`emp`;返回结果如下:
查看表。登录DLF控制台,查看同步过来的表详情:

步骤三:MaxCompute创建Paimon_DLF外部数据源
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择管理配置 > 外部数据源。
在外部数据源页面,单击创建外部数据源。
在新增外部数据源对话框,根据界面提示配置相关参数。参数说明如下:
参数
是否必填
说明
外部数据源类型
必填
选择DLF+OSS。
外部数据源名称
必填
可自定义命名。命名规则如下:
以字母开头,且只能包含小写字母、下划线和数字。
不能超过128个字符。
例如
paimon_dlf。外部数据源描述
选填
根据需要填写。
地域
必填
默认为当前地域。
DLF Endpoint
必填
默认为当前地域的DLF Endpoint。
OSS Endpoint
必填
默认为当前地域的OSS Endpoint。
RoleARN
必填
RAM角色的ARN信息。此角色需要包含能够同时访问DLF和OSS服务的权限。
您可以登录RAM访问控制台,在左侧导航栏选择身份管理>角色,单击对应的RAM角色名称,即可在基本信息区域获取ARN信息。
示例:
acs:ram::124****:role/aliyunodpsdefaultrole。外部数据源补充属性
选填
特殊声明的外部数据源补充属性。指定后,使用此外部数据源的任务可以按照参数定义的行为访问源系统。
说明支持的具体参数请关注后续官网文档更新说明,具体参数将随产品能力演进逐步放开。
单击确认,完成外部数据源的创建。
在外部数据源页面,单击数据源操作列的详情可查看数据源详细信息。
步骤四:MaxCompute创建Paimon_DLF外部项目
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择管理配置 > 项目管理。
在项目管理页面,单击外部项目页签,然后单击新建项目。
在新增项目对话框,根据界面提示配置参数。参数说明如下:
参数
是否必填
说明
项目类型
必填
默认为外部项目。
地域
必填
默认为当前地域,此处无法修改。
项目名称(全网唯一)
必填
字母开头,包含字母、数字及下划线(_),长度在3-28个字符。
MaxCompute外部数据源类型
选填
默认为Paimon_DLF。
MaxCompute外部数据源
选填
选择已有:会出现已经创建过的外部数据源。
新建外部数据源:即可新建并使用新的外部数据源。
MaxCompute外部数据源名称
必填
选择已有:在下拉列表中选择已经创建好的外部数据源名称。
新建外部数据源:则会使用新建的外部数据源名称。
认证和鉴权
必填
任务执行者身份,如未创建服务关联角色,需要先创建才可以使用此模式。
关联服务角色
必填
默认生成。
Endpoint
必填
默认生成。
数据目录
必填
DLF数据目录。
计算资源付费类型
必填
包年包月或按量付费。
默认Quota
必填
选择已有Quota.
描述
选填
自定义项目描述。
单击确认,完成项目创建。
步骤五:数据分析
选择连接工具登录外部项目。
列出外部项目中的schema。
-- 打开session级别支持schema语法开关。 SET odps.namespace.schema=true; SHOW schemas; -- 返回结果。 ID = 20250919****am4qb default system OK在外部项目中列出schema下的表。
USE schema default; SHOW tables; -- 返回结果。 ID = 20250919****am4qb acs:ram::<uid>:root emp OK读取DLF中的Paimon表。
SELECT * FROM emp; -- 返回结果。 +------------+------------+------------+------------+------------+------------+------------+------------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +------------+------------+------------+------------+------------+------------+------------+------------+ | 7521 | WARD | SALESMAN | 7698 | 2021-02-22 | 1250 | 500 | 30 | | 7844 | TURNER | SALESMAN | 7698 | 2021-09-08 | 1500 | 0 | 30 | | 7876 | ADAMS | CLERK | 7788 | 2022-01-12 | 1100 | NULL | 20 | | 7900 | JAMES | CLERK | 7698 | 2021-12-03 | 950 | NULL | 30 | | 7934 | MILLER | CLERK | 7782 | 2022-01-23 | 1300 | NULL | 10 | | 8005 | JOHN | MANAGER | 7839 | 2023-07-12 | 4000 | NULL | 10 | | 7369 | SMITH | CLERK | 7902 | 2020-12-17 | 800 | NULL | 20 | | 7566 | JONES | MANAGER | 7839 | 2021-04-02 | 2975 | NULL | 20 | | 7654 | MARTIN | SALESMAN | 7698 | 2021-09-28 | 1250 | 1400 | 30 | | 7698 | BLAKE | MANAGER | 7839 | 2021-05-01 | 2850 | NULL | 30 | | 7839 | KING | PRESIDENT | NULL | 2021-11-17 | 5000 | NULL | 10 | | 8002 | DANIEL | ENGINEER | 7788 | 2023-04-01 | 3400 | NULL | 20 | | 8006 | LISA | DESIGNER | 7698 | 2023-08-13 | 2200 | NULL | 30 | | 7499 | ALLEN | SALESMAN | 7698 | 2021-02-20 | 1600 | 300 | 30 | | 7782 | CLARK | MANAGER | 7839 | 2021-06-09 | 2450 | NULL | 10 | | 7788 | SCOTT | ANALYST | 7566 | 2021-12-09 | 3000 | NULL | 20 | | 7902 | FORD | ANALYST | 7566 | 2021-12-03 | 3000 | NULL | 20 | | 8001 | DUKE | ENGINEER | 7788 | 2023-03-15 | 3500 | NULL | 20 | | 8003 | SANDRA | CONSULTANT | 7698 | 2023-05-10 | 2700 | NULL | 30 | | 8004 | KAREN | CLERK | 7902 | 2023-06-11 | 1200 | NULL | 20 | +------------+------------+------------+------------+------------+------------+------------+------------+查询emp表中“每个部门薪水最高和最低的员工完整信息”。
WITH ranked AS ( SELECT e.*, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rn_desc, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal ASC) AS rn_asc FROM emp e ) SELECT * FROM ranked WHERE rn_desc = 1 OR rn_asc = 1 ORDER BY deptno, sal DESC; -- 返回结果。 +-------+--------+-----------+------+------------+------+------+--------+------------+------------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | rn_desc | rn_asc | +-------+--------+-----------+------+------------+------+------+--------+------------+------------+ | 7839 | KING | PRESIDENT | NULL | 2021-11-17 | 5000 | NULL | 10 | 1 | 4 | | 7934 | MILLER | CLERK | 7782 | 2022-01-23 | 1300 | NULL | 10 | 4 | 1 | | 8001 | DUKE | ENGINEER | 7788 | 2023-03-15 | 3500 | NULL | 20 | 1 | 8 | | 7369 | SMITH | CLERK | 7902 | 2020-12-17 | 800 | NULL | 20 | 8 | 1 | | 7698 | BLAKE | MANAGER | 7839 | 2021-05-01 | 2850 | NULL | 30 | 1 | 8 | | 7900 | JAMES | CLERK | 7698 | 2021-12-03 | 950 | NULL | 30 | 8 | 1 | +-------+--------+-----------+------+------------+------+------+--------+------------+------------+
步骤六:将分析结果写回DLF
在上一步骤中的外部项目中创建表,用来接收SQL分析结果。
CREATE TABLE emp_detail ( empno INT, ename VARCHAR(20), job VARCHAR(20), mgr INT, hiredate DATE, sal DECIMAL(10,2), comm DECIMAL(10,2), deptno INT );将步骤五的分析结果写入到新表。
WITH ranked AS ( SELECT e.*, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rn_desc, ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal ASC) AS rn_asc FROM emp e ) insert into emp_detail SELECT empno,ename,job,mgr, hiredate,sal,comm,deptno FROM ranked WHERE rn_desc = 1 OR rn_asc = 1 ORDER BY deptno, sal DESC;查询新表。
SELECT * FROM emp_detail; -- 返回结果。 +------------+------------+------------+------------+------------+------------+------------+------------+ | empno | ename | job | mgr | hiredate | sal | comm | deptno | +------------+------------+------------+------------+------------+------------+------------+------------+ | 7839 | KING | PRESIDENT | NULL | 2021-11-17 | 5000 | NULL | 10 | | 7934 | MILLER | CLERK | 7782 | 2022-01-23 | 1300 | NULL | 10 | | 8001 | DUKE | ENGINEER | 7788 | 2023-03-15 | 3500 | NULL | 20 | | 7369 | SMITH | CLERK | 7902 | 2020-12-17 | 800 | NULL | 20 | | 7698 | BLAKE | MANAGER | 7839 | 2021-05-01 | 2850 | NULL | 30 | | 7900 | JAMES | CLERK | 7698 | 2021-12-03 | 950 | NULL | 30 | +------------+------------+------------+------------+------------+------------+------------+------------+登录DLF控制台,左侧导航栏单击数据目录,可查看新建的表
emp_detail。