
布隆过滤器(Bloomfilter,简称BF)是一种高效的概率型数据结构,MaxCompute支持使用Bloomfilter index处理大规模数据点查场景,减少查询过程中不必要的数据扫描,从而提高整体的查询效率和性能。本文为您介绍Bloomfilter index的使用说明及示例。
背景信息
大规模点查是一种常见的数仓使用场景,通常会通过指定不定列的值对大量数据进行检索,得到条件匹配的结果。在大数据场景下,结果数据可能分散在海量的文件中,因此高性能的大规模点查需要极强的检索能力。
MaxCompute是按照表或分区读取数据,存储层谓词下推能力会根据表或分区下文件的本地元数据信息(参考ANALYZE)过滤数据,如果数据分散,则根据本地元数据信息过滤数据(例如基于某列的MIN或MAX值进行过滤)的效果就比较有限。
如果查询的列是固定的,可以使用聚簇表,并将Clustering Key作为过滤条件,这样可以快速排除掉不需要读取的分桶,在分桶内也可以过滤掉不需要读取的数据,加快查询速度。如果在条件字段上聚合或者和其他表进行关联等操作,可以利用聚簇附带的Shuffle Removal能力,进一步发挥聚簇表优势,但是聚簇表在以下几方面仍有不足:
对于Hash聚簇表,只有当查询条件包含了所有的Clustering Key之后才能进行数据过滤;对于Range聚簇表,只有当查询条件中包含了Clustering Key的前缀过滤条件,并且按照Clustering Key的顺序从左到右进行匹配时,才能有较好的过滤效果,如果不包含前缀过滤条件则效果不佳。
如果查询条件不包含Clustering Key,则没有过滤效果,因而对于查询无固定条件的表来说,聚簇表可能无效。
数据写入时需要按照指定的字段进行Shuffle,会导致成本增加,如果遇到个别倾斜的Key,会导致任务长尾。
因此MaxCompute引入布隆过滤器索引(Bloomfilter index)应对大规模数据点查的场景。
前提条件
已创建MaxCompute项目。具体操作请参见创建MaxCompute项目。
项目已支持Schema Evolution操作。若您的项目未支持Schema Evolution操作,需要在项目级别设置
setproject odps.schema.evolution.enable=true;,以确保后续操作成功执行。否则会出现类似于Failed to run ddltask - Schema evolution DDLs is not enabled in project:default的报错。
功能介绍
点查本质上是检索某一个元素是否存在于一个集合中,而Bloomfilter可以用极高的效率实现该目标,因而在数据库以及数据湖技术中都引入了Bloomfilter index,以便支持更细粒度的数据或文件裁剪。
不同于数据库中的索引(如BTree、RTree等)用来具体定位到某一行记录,大数据下基于索引构建、维护代价的考虑,更多的是引入更轻量级的索引,而空间效率和查询效率都非常高的Bloomfilter很适合在点查场景进行文件的裁剪,因此MaxCompute中也引入了该索引。
相对聚簇表,Bloomfilter index的优势如下:
高效。能以极小的代价过滤无效数据。
扩展性高。可以对表的一列或者多列建立BF索引,并且可以和聚簇索引配合使用,即可以对非Clustering Key建立BF索引。
在高基数、数据分布紧凑的场景下有很好的过滤效果。
Bloomfilter index的优缺点
优点
效率高,插入和查询操作的资源消耗都比普通索引低。
节省空间,采用位数组,232=4294967296,可以看到42亿长度的位数组只需占用512 MB的内存空间。
说明位数组占用的内存空间计算方式:
4294967296/8/1024/1024=512 MB。
缺点
有一定误判率,可能会把不属于该集合的元素误判为存在于该集合,但是对大多数场景而言,消耗一点资源读取无数据的文件并不影响整体效率,且结果不影响最终的业务准确性。
Bloomfilter index适用场景
以表中的一列或多列作为条件进行点查过滤,则在有明显过滤效果的查询列上构建Bloomfilter index。
对聚簇表Clustering Key之外的字段进行点查过滤,则在查询列上构建Bloomfilter index。
聚簇表的Clustering Key、Sorted Key、Zorder函数排序后,在插入的数据列上再构建Bloomfilter index,可以获得进一步的过滤效果。
Bloomfilter index使用限制
只适合等值判断(包括
=、in),不支持>、>=、<、<=等范围查询及IS NULL、IS NOT NULL查询。过滤效果的好坏依赖于数据分布,如果数据分布比较离散,即使使用Bloomfilter index,也可能无法有效地过滤数据。
不支持在DECIMAL、INTERVAL_DAY_TIME、INTERVAL_YEAR_MONTH,或复杂类型STRUCT、MAP、ARRAY、JSON上建立Bloomfilter index。
使用说明
生成Bloomfilter index、使用Bloomfilter index、查看Bloomfilter index、删除Bloomfilter index及更改Bloomfilter index属性的方法如下:
生成Bloomfilter index
创建Bloomfilter index
语法如下:
CREATE BLOOMFILTER INDEX <index_name>
ON TABLE <table_name>
FOR COLUMNS(<column_name>)
IDXPROPERTIES('numitems'='xxx', 'fpp' = 'xx')
[COMMENT 'idxcomment'];参数说明如下:
参数 | 描述 |
index_name | 指定的索引名称。 |
table_name | 索引所在的表名。 |
column_name | 要创建索引的列名。 |
numitems | Bloomfilter中存储的元素数量的预估值,用于指定Bloomfilter的容量大小,以便在创建时分配足够的内存空间来存储预期数量的元素。该设置会影响Bloomfilter中使用的总位数,对过滤质量很重要。
该值必须大于0,您可根据构建索引列的非重复值数量进行预估,最大不能超过1000万。 |
fpp | 误判率。取值范围为 |
目前仅支持一次对表中的一个列创建Bloomfilter index,您可以为表的多个列分别创建Bloomfilter index。
聚合Bloomfilter index
对于增量数据不需要任何额外操作,执行数据的插入语句即可聚合Bloomfilter index。
语法如下:
INSERT OVERWRITE TABLE <table_name> [PARTITION <partition_spec>]
SELECT ......参数说明如下:
参数 | 描述 |
table_name | 索引所在的表名。 |
partition_spec | 需要插入数据的分区信息,不允许使用函数等表达式,只能是常量。格式为 |
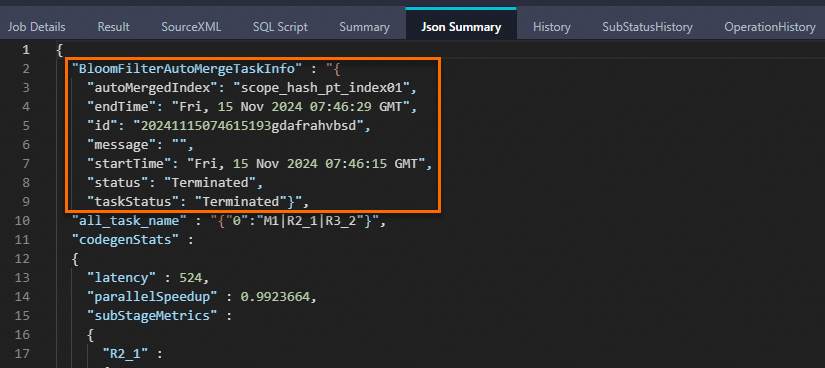
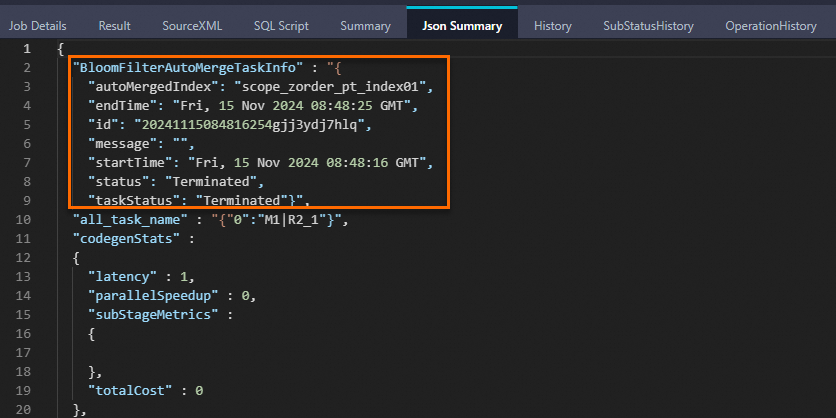
在构建了Bloomfilter index的表中插入新数据,会增量生成数据文件的本地Bloomfilter索引数据,支持存储层谓词下推,然后启动BloomfilterAutoMergeTask自动聚合成新的Bloomfilter index索引文件,支持在planning阶段进行过滤,更准确地启动任务所需资源。此时Logview中Json Summary出现如下关键字则说明Bloomfilter index聚合成功: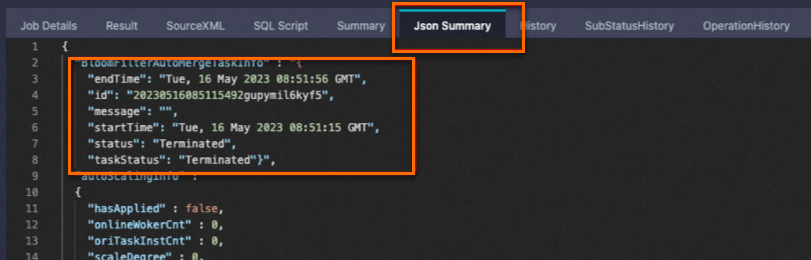
此时,您可通过Logview中的SubStatusHistory查看Bloomfilter index聚合所耗费的时间:
无论Bloomfilter index聚合任务成功与否,写入数据的任务都会正常完成。
Bloomfilter index因为系统原因聚合失败,会导致新增数据无法在planning阶段过滤数据,新增数据的本地Bloomfilter索引数据仍然能够支持存储层谓词下推进行过滤。您可以通过执行计划判断是否利用到了Bloomfilter index,如果没有,可以对查询时索引不生效的分区索引进行REBUILD。
动态分区暂时不支持自动Merge,需要在数据写入完成后,手动对更新的分区进行REBUILD。
如果上图中自动Merge任务状态返回显示执行失败,则需要显式执行如下Merge命令,支持一次同时对多个分区的BloomFilter索引进行REBUILD操作。
ALTER TABLE <table_name> [PARTITION <partition_spec>] REBUILD BLOOMFILTER INDEX;示例一:
ALTER TABLE table_name PARTITION (pt>='20210101') REBUILD BLOOMFILTER INDEX;示例二:
ALTER TABLE table_name PARTITION (pt>'20210101' AND pt<'20210303') REBUILD BLOOMFILTER INDEX;
使用Bloomfilter index
在查询前执行如下语句,启用布隆过滤器索引功能:
SET odps.sql.enable.bloom.filter.index=true;Bloomfilter index生效后,query中会增加一个job进行文件裁剪,裁剪后的文件即为任务需要读取的数据。
如果没有设置该参数(Beta发布期间默认值为false,后续会根据线上使用情况将默认值置为true),则无法在planning阶段裁剪文件,但此时仍可以利用存储层谓词下推能力,基于Bloomfilter本地索引数据进行数据的过滤。
如果Bloomfilter index的过滤效果不显著(例如:结果文件分散在多个文件中,无法通过裁剪明显过滤文件),则设置该参数需要多执行一个索引检索任务,有可能导致任务性能回退,此时可以置为false。
Bloomfilter index生效的任务示例如下:
SET odps.sql.enable.bloom.filter.index=true;
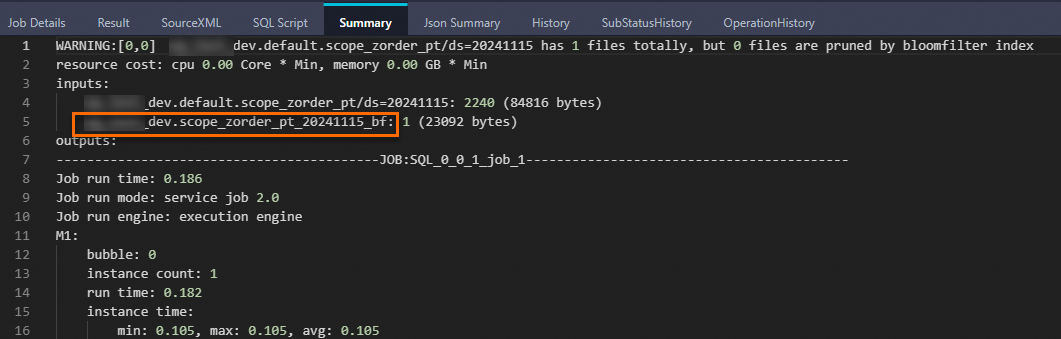
SELECT * FROM bloomfilter_index_test WHERE key=392 AND value="val_392";查看Logview可知,下图中的job_1即为使用Bloomfilter index进行文件裁剪的job(称为index job)。
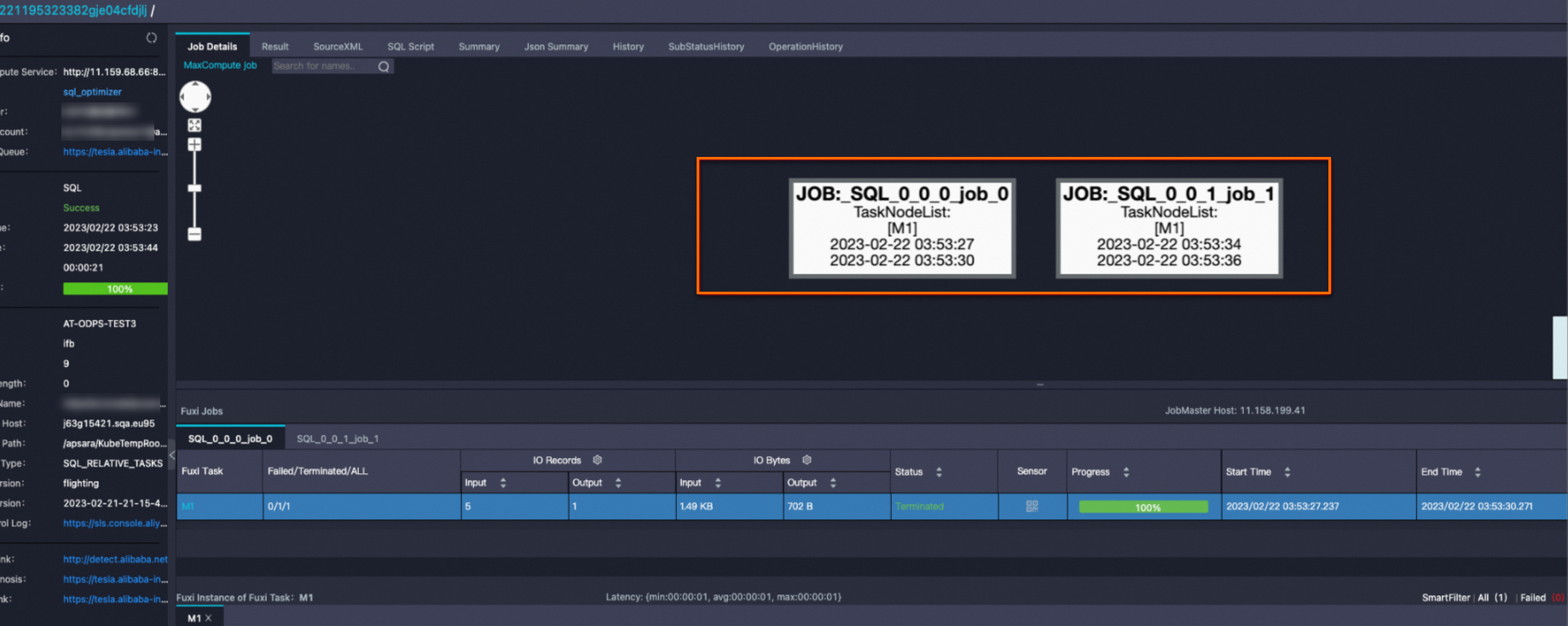
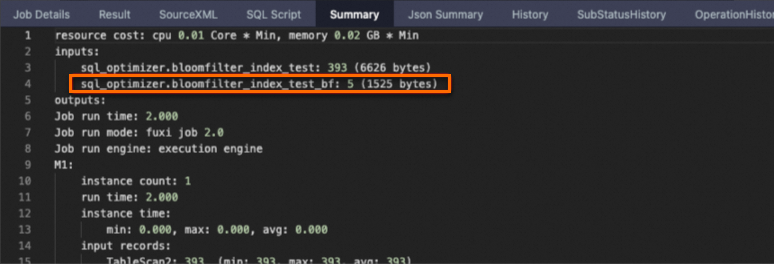
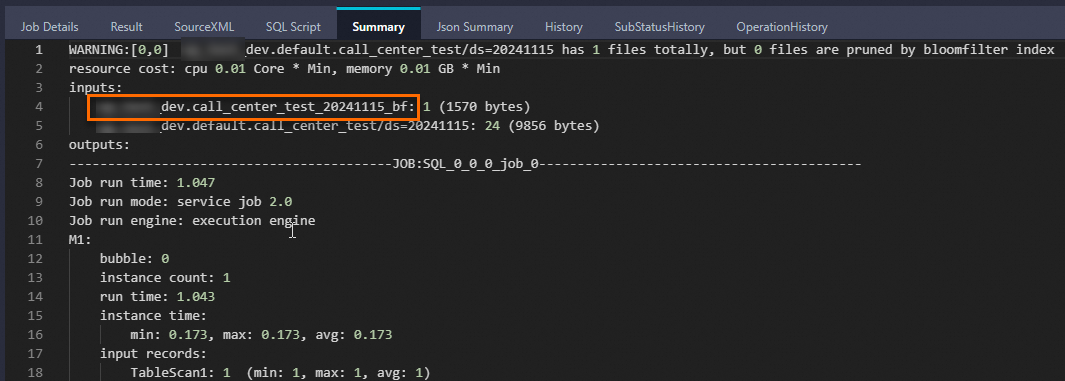
Summary中携带bf后缀的是虚拟表,对应Bloomfilter index文件。
海量数据下生成的BF文件可能会非常大,因此MaxCompute启动了一个分布式作业进行文件的裁剪。
查看表的Bloomfilter index
SHOW INDEXES ON <table_name>;参数说明如下。
table_name:索引所在的表名。
删除Bloomfilter index
DROP INDEX [IF EXISTS] <idx_name> ON TABLE <table_name>;参数说明如下。
idx_name:索引名称。
table_name:索引所在的表名。
更改Bloomfilter index属性
ALTER INDEX <idx_name> ON <table_name>
SET IDXPROPERTIES('comment' = 'a', 'fpp' = '0.01');参数说明如下。
idx_name:索引名称。
table_name:索引所在的表名。
使用示例
示例1:基于普通分区表创建Bloomfilter index
数据准备。
SET odps.namespace.schema=true; SELECT * FROM bigdata_public_dataset.TPCDS_10G.call_center;创建分区测试表call_center_test。
CREATE TABLE IF NOT EXISTS call_center_test( cc_call_center_sk BIGINT NOT NULL, cc_call_center_id CHAR(16) NOT NULL, cc_rec_start_date DATE, cc_rec_end_date DATE, cc_closed_date_sk BIGINT, cc_open_date_sk BIGINT, cc_name VARCHAR(50), cc_class VARCHAR(50), cc_employees BIGINT, cc_sq_ft BIGINT, cc_hours CHAR(20), cc_manager VARCHAR(40), cc_mkt_id BIGINT, cc_mkt_class CHAR(50), cc_mkt_desc VARCHAR(100), cc_market_manager VARCHAR(40), cc_division BIGINT, cc_division_name VARCHAR(50), cc_company BIGINT, cc_company_name CHAR(50), cc_street_number CHAR(10), cc_street_name VARCHAR(60), cc_street_type CHAR(15), cc_suite_number CHAR(10), cc_city VARCHAR(60), cc_county VARCHAR(30), cc_state CHAR(2), cc_zip CHAR(10), cc_country VARCHAR(20), cc_gmt_offset DECIMAL(5,2), cc_tax_percentage DECIMAL(5,2) ) PARTITIONED BY (ds STRING );创建索引。
CREATE BLOOMFILTER INDEX call_center_test_idx01 ON table call_center_test FOR columns(cc_call_center_sk) IDXPROPERTIES('fpp' = '0.03', 'numitems'='1000000') COMMENT 'cc_call_center_sk index';导入数据。
将公共数据集中的
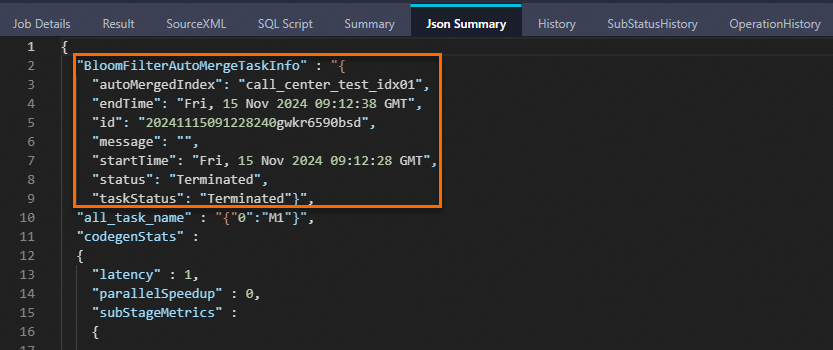
bigdata_public_dataset.TPCDS_10G.call_center表数据导入至call_center_test。SET odps.namespace.schema=true; INSERT OVERWRITE TABLE call_center_test PARTITION (ds='20241115') SELECT * FROM bigdata_public_dataset.TPCDS_10G.call_center LIMIT 10000;Logview中Json Summary出现如下关键字则说明Bloomfilter index聚合成功:
查询数据。
SET odps.sql.enable.bloom.filter.index=true; SELECT * FROM call_center_test WHERE cc_call_center_sk =10 AND ds='20241115';返回结果如下:
+-------------------+-------------------+-------------------+-----------------+-------------------+-----------------+---------------+------------+--------------+------------+------------+----------------+------------+----------------------------+---------------------------------------------------------------------------------------+-------------------+-------------+------------------+------------+-----------------+------------------+----------------+----------------+-----------------+------------+---------------+------------+------------+---------------+---------------+-------------------+------------+ | cc_call_center_sk | cc_call_center_id | cc_rec_start_date | cc_rec_end_date | cc_closed_date_sk | cc_open_date_sk | cc_name | cc_class | cc_employees | cc_sq_ft | cc_hours | cc_manager | cc_mkt_id | cc_mkt_class | cc_mkt_desc | cc_market_manager | cc_division | cc_division_name | cc_company | cc_company_name | cc_street_number | cc_street_name | cc_street_type | cc_suite_number | cc_city | cc_county | cc_state | cc_zip | cc_country | cc_gmt_offset | cc_tax_percentage | ds | +-------------------+-------------------+-------------------+-----------------+-------------------+-----------------+---------------+------------+--------------+------------+------------+----------------+------------+--------------+-------------+---------------------------------------------------------------------------------------+-------------------+-------------+------------------+------------+-----------------+------------------+----------------+----------------+-----------------+------------+---------------+------------+------------+---------------+---------------+-------------------+------------+ | 10 | AAAAAAAAKAAAAAAA | 1998-01-01 | 2000-01-01 | NULL | 2451050 | Hawaii/Alaska | large | 187 | 95744 | 8AM-8AM | Gregory Altman | 2 | Just back responses ought | As existing eyebrows miss as the matters. Realistic stories may not face almost by a | James Mcdonald | 3 | pri | 3 | pri | 457 | 1st | Boulevard | Suite B | Midway | Walker County | AL | 31904 | United States | -6 | 0.02 | 20241115 | +-------------------+-------------------+-------------------+-----------------+-------------------+-----------------+---------------+------------+--------------+------------+------------+----------------+------------+----------------------------+---------------------------------------------------------------------------------------+-------------------+-------------+------------------+------------+-----------------+------------------+----------------+----------------+-----------------+------------+---------------+------------+------------+---------------+---------------+-------------------+------------+Logview中显示如下信息,表示Bloomfilter index已经生效,携带
bf后缀的是虚拟表,对应Bloomfilter index文件。
查看表的Bloomfilter index。
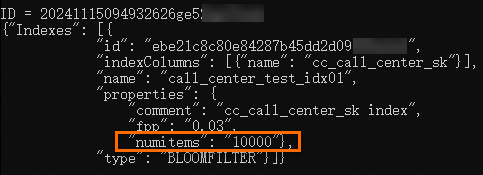
SHOW INDEXES ON call_center_test;返回结果如下:
ID = 20241115093930589g9biyii**** {"Indexes": [{ "id": "aabdaeb10a7b4e99a94716dabad8****", "indexColumns": [{"name": "cc_call_center_sk"}], "name": "call_center_test_idx01", "properties": { "comment": "cc_call_center_sk index", "fpp": "0.03", "numitems": "1000000"}, "type": "BLOOMFILTER"}]} OK更改Bloomfilter index属性。
由上一步可知,原始
numitems属性值为1000000,执行以下命令,将其属性值更改为10000。-- 更改属性 ALTER INDEX call_center_test_idx01 ON call_center_test SET IDXPROPERTIES('fpp' = '0.03', 'numitems'='10000'); -- 查看属性 SHOW INDEXES ON call_center_test;返回结果如下:
示例2:基于Hash Cluster分区表创建Bloomfilter index
数据准备。
创建scope_tmp表。
CREATE TABLE if NOT EXISTS scope_tmp( phone STRING, card STRING, machine STRING, geohash STRING);在MaxCompute客户端(odpscmd)中使用Tunnel命令向scope_tmp表中上传数据。以scope2.csv文件为例,假设scope2.csv文件位于MaxCompute客户端(odpscmd)的
bin目录下,Tunnel命令如下:Tunnel upload scope2.csv scope_tmp;
创建分区测试表scope_hash_pt。
CREATE TABLE scope_hash_pt ( phone STRING, card STRING, machine STRING, geohash STRING ) PARTITIONED BY (ds STRING) clustered by (phone) sorted by (card) into 512 buckets;为分区表scope_hash_pt创建索引。
CREATE BLOOMFILTER INDEX scope_hash_pt_index01 ON TABLE scope_hash_pt FOR columns(card) IDXPROPERTIES('fpp' = '0.03', 'numitems'='1000000') COMMENT 'card index';导入数据。
INSERT OVERWRITE TABLE scope_hash_pt PARTITION (ds='20241115') SELECT * FROM scope_tmp;Logview中Json Summary出现如下关键字则说明Bloomfilter index聚合成功:
查询scope_hash_pt表的数据。
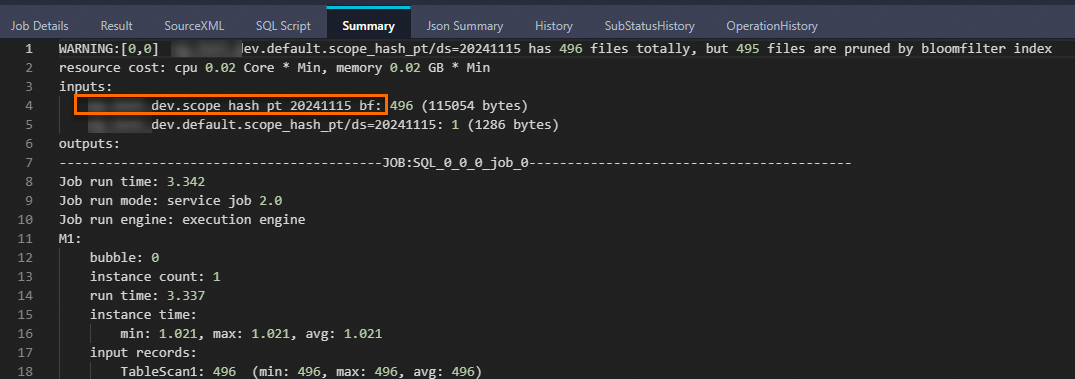
SET odps.sql.enable.bloom.filter.index=true; SELECT * FROM scope_hash_pt WHERE card='073415764266290' and ds='20241115';返回结果如下:
+-------------+-----------------+----------------+------------+------------+ | phone | card | machine | geohash | ds | +-------------+-----------------+----------------+------------+------------+ | 1576426**** | 073415764266290 | 51133960245770 | fWbDDsf | 20241115 | +-------------+-----------------+----------------+------------+------------+Logview中显示如下信息,表示Bloomfilter index已经生效,携带
bf后缀的是虚拟表,对应Bloomfilter index文件。
示例3:基于Zorder数据重分布的分区表创建Bloomfilter index
数据准备。具体操作请参见Hash BloomFilter数据准备。
创建分区测试表scope_zorder_pt。
CREATE TABLE scope_zorder_pt( phone STRING, card STRING, machine STRING, geohash STRING, zvalue BIGINT ) PARTITIONED BY (ds STRING) ;创建索引。
CREATE BLOOMFILTER INDEX scope_zorder_pt_index01 ON TABLE scope_zorder_pt FOR COLUMNS (card) IDXPROPERTIES('fpp' = '0.05', 'numitems'='1000000') COMMENT 'idxcomment';导入数据。
下载以下两个JAR包,并将其存放在本地(假设存放路径为
D:\)。执行以下命令将其上传为JAR资源。
-- 添加资源 ADD JAR D:\odps-zorder-1.0-SNAPSHOT.jar; ADD JAR D:\odps-zorder-1.0-SNAPSHOT-jar-with-dependencies.jar;创建函数,命令如下:
CREATE FUNCTION zorder AS 'com.aliyun.odps.zorder.evaluateZValue2WithSize' USING ' odps-zorder-1.0-SNAPSHOT-jar-with-dependencies.jar';使用函数写入数据至分区测试表scope_zorder_pt。
-- ORDER BY放开LIMIT限制 SET odps.sql.validate.orderby.limit=false; --写入数据 INSERT OVERWRITE TABLE scope_zorder_pt PARTITION (ds='20241115') SELECT *,zorder(HASH(phone), 100000000, HASH(card), 100000000) AS zvalue FROM scope_tmp ORDER BY zvalue;Logview中Json Summary出现如下关键字则说明Bloomfilter index聚合成功:
查询数据。
SET odps.sql.enable.bloom.filter.index=true; SELECT * FROM scope_zorder_pt WHERE card='073415764266290' AND ds='20241115';返回结果如下:
+-------------+-----------------+----------------+------------+---------------------+------------+ | phone | card | machine | geohash | zvalue | ds | +-------------+-----------------+----------------+------------+---------------------+------------+ | 1576426**** | 073415764266290 | 51133960245770 | fWbDDsf | 3590549286038929408 | 20241115 | +-------------+-----------------+----------------+------------+---------------------+------------+Logview中显示如下信息,表示Bloomfilter index已经生效,携带
bf后缀的是虚拟表,对应Bloomfilter index文件。
费用说明
索引构建后会占用存储空间,并且是由存储在Pangu上的存储计量进行统计,因此这部分计量按普通存储收费。
索引的构建和使用会触发额外的计算任务,一次查询首先基于索引文件计算查询所需数据所在的文件信息,然后基于索引计算结果,进一步在查询执行计划阶段过滤减少输入数据量,并最终计算得到结果。索引计算和查询都会产生计算费用。
使用索引,可以让预付费客户的作业运行得更快,同时,构建和运行索引计算的资源也是基于用户的预付费资源,所以商业化不会对预付费作业的费用产生影响。
SQL操作触发的索引相关任务说明如下:
SQL操作
触发任务
索引相关任务的输入数据量
计费情况
CREATE
DDL操作不会触发索引构建任务。
无
不收费
REBUILD
索引构建。
已有索引:执行REBUILD操作会触发索引重建。
无现有索引:执行REBUILD操作会触发索引新建。
由于重建索引时,索引列和其他列同时进行读写操作,所以输入数据量为重建索引查询条件过滤后的全量数据。
索引计费方式:
SQL后付费单价*复杂度1*索引相关任务输入数据量。SQL查询计费方式:采用正常SQL后付费逻辑。
INSERT
对新插入的数据构建索引。
SELECT部分的查询。
SELECT查询的表中,带有索引的列的数据量。
SELECT
使用索引计算的查询任务,输出下一步SELECT部分用于过滤数据的信息。
基于已构建的索引执行SELECT查询。
索引文件的数据量。