
公用表表达式(COMMON TABLE EXPRESSION)简称CTE,是一个临时命名的结果集,用于简化SQL。MaxCompute支持标准SQL的CTE功能,可以有效提高SQL语句的可读性与执行效率。本文为您介绍CTE的功能、命令格式及使用示例。
功能介绍
CTE可以被认为是在单个DML语句的执行范围内定义的临时结果集。CTE类似于派生表,它不作为对象存储,并且仅在查询期间持续。开发过程中结合CTE,可以提高SQL语句可读性,便于轻松维护复杂查询。
CTE是一个STATEMENT级别的子句表达式,以WITH开头,后跟表达式名称。包括以下两类:
NON RECURSIVE CTE:非递归CTE,即CTE不使用递归,不迭代访问自己。
RECURSIVE CTE:递归CTE,表示CTE可以迭代访问自身的场景,能够实现SQL的递归查询功能,通常用来遍历分层数据。
支持MATERIALIZE CTE(物化CTE)功能:定义CTE时,可在SELECT语句中使用MATERIALIZE HINT将CTE的计算结果缓存到一个临时表中,后续访问CTE时,可直接从缓存中读取结果,从而避免了多层CTE嵌套场景下出现内存超限问题,进而提升CTE语句性能。
NON RECURSIVE CTE(非递归CTE)
命令格式
WITH
<cte_name> [(col_name[,col_name]...)] AS
(
<cte_query>
)
[,<cte_name> [(col_name[,col_name]...)] AS
(
<cte_query2>
)
,……]参数说明
参数 | 是否必填 | 说明 |
cte_name | 是 | CTE的名称,不能与当前 |
col_name | 否 | CTE输出列的列名称。 |
cte_query | 是 | 一个 |
使用示例
假设现有如下代码:
INSERT OVERWRITE TABLE srcp PARTITION (p='abc')
SELECT * FROM (
SELECT a.key, b.value
FROM (
SELECT * FROM src WHERE key IS NOT NULL ) a
JOIN (
SELECT * FROM src2 WHERE value > 0 ) b
ON a.key = b.key
) c
UNION ALL
SELECT * FROM (
SELECT a.key, b.value
FROM (
SELECT * FROM src WHERE key IS NOT NULL ) a
LEFT OUTER JOIN (
SELECT * FROM src3 WHERE value > 0 ) b
ON a.key = b.key AND b.key IS NOT NULL
) d;顶层的UNION两侧各为一个JOIN,JOIN的左表是相同的查询语句。通过写子查询的方式,只能重复这段代码。
使用CTE的方式重写以上语句,命令示例如下:
WITH
a AS (SELECT * FROM src WHERE key IS NOT NULL),
b AS (SELECT * FROM src2 WHERE value > 0),
c AS (SELECT * FROM src3 WHERE value > 0),
d AS (SELECT a.key, b.value FROM a JOIN b ON a.key=b.key),
e AS (SELECT a.key, c.value FROM a LEFT OUTER JOIN c ON a.key=c.key AND c.key IS NOT NULL)
INSERT OVERWRITE TABLE srcp PARTITION (p='abc')
SELECT * FROM d UNION ALL SELECT * FROM e;重写后,a对应的子查询只需写一次,便可在后面进行重用。您可以在CTE的WITH子句中指定多个子查询,像使用变量一样在整个语句中反复重用。除重用外,不必反复嵌套。
RECURSIVE CTE(递归CTE)
命令格式
WITH RECURSIVE <cte_name>[(col_name[,col_name]...)] AS
(
<initial_part> UNION ALL <recursive_part>
)
SELECT ... FROM ...;参数说明
参数 | 是否必填 | 说明 |
RECURSIVE | 是 | Recursive CTE子句必须以 |
cte_name | 是 | CTE的名称,不能与当前 |
col_name | 否 | CTE输出列的列名称。若不显式地指定输出列名,则系统也支持自动推断。 |
initial_part | 是 | 用于计算初始数据集,它不可以递归地引用cte_name指向CTE自身。 |
recursive_part | 是 | 用于计算后续迭代的结果,可以通过递归地引用cte_name,定义如何使用上一个迭代结果来递归地计算下一个迭代结果。 |
UNION ALL | 是 | initial_part和recursive_part之间必须通过UNION ALL来连接。 |
使用限制
RECURSIVE CTE不能用于IN/EXISTS/SCALAR的SUB-QUERY。
RECURSIVE CTE的默认递归操作次数限制为10次,支持设置
odps.sql.rcte.max.iterate.num来修改这个默认值,最大上限为100(若设置值超过100,仍按照100来处理)。RECURSIVE CTE不支持在迭代计算过程中记录中间结果,即发生失败时则会重新从头开始计算。使用时建议控制递归次数,若整个计算过程耗时很长,建议通过创建临时表来把中间的计算结果落盘。
RECURSIVE CTE不支持在查询加速(MCQA)执行。若在MCQA模式中使用RECURSIVE CTE,当设置了
interactive_auto_rerun=true,任务可以回退到普通模式执行,否则任务会失败。
使用示例
示例1:定义一个名称为cte_name的RECURSIVE CTE。
-- 方式1:定义一个名称为cte_name的递归CTE,包含名为a,b的两个输出列 WITH RECURSIVE cte_name(a, b) AS ( SELECT 1L, 1L -- intial_part:即迭代0数据集 UNION ALL -- 将cte的initial_part和recursive_part之间使用UNION ALL连接到一起 SELECT a+1, b+1 FROM cte_name WHERE a+1 <= 5) -- recursive_part:其中cte_name指向的是上一个迭代的计算结果 SELECT * FROM cte_name ORDER BY a LIMIT 100; -- 输出递归CTE结果,即将所有迭代的数据union all到一起 -- 方式2:定义一个名称为cte_name的递归CTE,不显示指定输出列名称 WITH RECURSIVE cte_name AS ( SELECT 1L AS a, 1L AS b UNION ALL SELECT a+1, b+1 FROM cte_name WHERE a+1 <= 5) SELECT * FROM cte_name ORDER BY a LIMIT 100;说明在recursive_part中为了避免递归操作陷入无限循环,需要设置迭代终止的条件。示例中使用
WHERE a + 1 <= 5来作为迭代是否应该结束的判据,如果WHERE条件不满足会导致本轮迭代生成的数据集为空,则迭代终止。当未显式地指定输出列名时,系统也支持进行自动推断。例如方式2中,使用initial_part的输出列名作为RECURSIVE CTE的输出列名。
返回结果如下:
+------------+------------+ | a | b | +------------+------------+ | 1 | 1 | | 2 | 2 | | 3 | 3 | | 4 | 4 | | 5 | 5 | +------------+------------+示例2:RECURSIVE CTE不能被用于IN/EXISTS/SCALAR的SUB-QUERY中,如下query在编译的时候会报错。
WITH RECURSIVE cte_name(a, b) AS ( SELECT 1L, 1L UNION ALL SELECT a+1, b+1 FROM cte_name WHERE a+1 <= 5) SELECT x, x in (SELECT a FROM cte_name) FROM VALUES (1L), (2L) AS t(x);返回结果如下:
-- 返回报错,在第5行存在一个in sub-query,且在sub-query中引用了RECURSIVE CTE cte_name FAILED: ODPS-0130071:[5,31] Semantic analysis exception - using Recursive-CTE cte_name in scalar/in/exists sub-query is not allowed, please check your query, the query text location is from [line 5, column 13] to [line 5, column 40]示例3:创建employees表,描述某个公司的员工和他的管理者的对应关系,并插入数据。
CREATE TABLE employees(name STRING, boss_name STRING); INSERT INTO TABLE employees VALUES ('zhang_3', null), ('li_4', 'zhang_3'), ('wang_5', 'zhang_3'), ('zhao_6', 'li_4'), ('qian_7', 'wang_5');定义一个名为
company_hierarchy的RECURSIVE CTE,以获取此表所描述的组织架构。该RECURSIVE CTE包含3个输出字段,分别是员工的名字、他的管理者的名字以及他在公司组织架构中的level。WITH RECURSIVE company_hierarchy(name, boss_name, level) AS ( SELECT name, boss_name, 0L FROM employees WHERE boss_name IS NULL UNION ALL SELECT e.name, e.boss_name, h.level+1 FROM employees e JOIN company_hierarchy h WHERE e.boss_name = h.name ) SELECT * FROM company_hierarchy ORDER BY level, boss_name, name LIMIT 1000;第二行initial_part,对应着employees中boss_name是null的记录,并且给这些记录的level字段赋值为0。
第四行recursive_part,将employees和company_hierarchy进行
JOIN操作,JOIN的条件是e.boss_name = h.name,即从employees表中获取这些记录,这些记录对应的员工的管理者是上一个迭代获取的员工记录。
返回结果如下:
+------+-----------+------------+ | name | boss_name | level | +------+-----------+---------------+ | zhang_3 | NULL | 0 | | li_4 | zhang_3 | 1 | | wang_5 | zhang_3 | 1 | | zhao_6 | li_4 | 2 | | qian_7 | wang_5 | 2 | +------+-----------+------------+整体计算过程可分解如下:
迭代0:获取初始数据集,通过条件
boss_name IS NULL对employees中的记录进行过滤,得到一条记录。'zhang_3', null, 0迭代1:执行如下query,其中company_hierarchy对应于上面迭代0的计算结果。
SELECT e.name, e.boss_name, h.level+1 FROM employees e JOIN company_hierarchy h WHERE e.boss_name = h.name执行后获取到了level = 1的两条记录,他们的管理者都是zhang_3。
'li_4', 'zhang_3', 1 'wang_5', 'zhang_3', 1迭代2:执行的过程和迭代1类似,但是company_hierarchy对应于迭代1的结果数据集。执行后获取了
level = 2的两条记录,它们的管理者是li_4或者wang_5。'zhao_6', 'li_4', 2 'qian_7', 'wang_5', 2迭代3:因为employees表中没有员工的管理者是zhao_6或者qian_7,因此返回空集,导致Recursive-CTE的递归计算结束。
示例4:假设向示例2的employees表中多插入一条记录,则返回报错。
INSERT INTO TABLE employees VALUES('qian_7', 'qian_7');这条记录声明qian_7的主管是他自己,这时再运行前面定义的RECURSIVE CTE,就会出现死循环。注意,系统对最大迭代次数有一定限制(请参见使用限制),这个query最终会失败并结束。
返回结果如下:
-- 返回报错 FAILED: ODPS-0010000:System internal error - recursive-cte: company_hierarchy exceed max iterate number 10
MATERIALIZE CTE
背景介绍
对于NON RECURSIVE CTE,MaxCompute在生成执行计划的时候,所有的CTE都会被展开。
示例如下:
WITH
v1 AS (SELECT SIN(1.0) AS a)
SELECT a FROM v1 UNION ALL SELECT a FROM v1;返回结果如下:
+------------+
| a |
+------------+
| 0.8414709848078965 |
| 0.8414709848078965 |
+------------+在执行层面相当于如下SQL,即函数sin(1.0)会被执行两次。
SELECT a FROM (SELECT SIN(1.0) AS a)
UNION ALL
SELECT a FROM (SELECT SIN(1.0) AS a);在有多层嵌套CTE的复杂场景下,若所有的CTE被展开成最基本的叶子节点,所生成的结果是一个巨大的语法树。在生成执行计划时可能因语法树节点过多导致失败,并可能引发内存超限。示例如下:
WITH
v1 AS (SELECT 1L AS a, 2L AS b, 3L AS c),
v2 AS (SELECT * FROM v1 UNION ALL SELECT * FROM v1 UNION ALL SELECT * FROM v1),
v3 AS (SELECT * FROM v2 UNION ALL SELECT * FROM v2 UNION ALL SELECT * FROM v2),
v4 AS (SELECT * FROM v3 UNION ALL SELECT * FROM v3 UNION ALL SELECT * FROM v3),
v5 AS (SELECT * FROM v4 UNION ALL SELECT * FROM v4 UNION ALL SELECT * FROM v4),
v6 AS (SELECT * FROM v5 UNION ALL SELECT * FROM v5 UNION ALL SELECT * FROM v5),
v7 AS (SELECT * FROM v6 UNION ALL SELECT * FROM v6 UNION ALL SELECT * FROM v6),
v8 AS (SELECT * FROM v7 UNION ALL SELECT * FROM v7 UNION ALL SELECT * FROM v7),
v9 AS (SELECT * FROM v8 UNION ALL SELECT * FROM v8 UNION ALL SELECT * FROM v8)
SELECT * FROM v9;为了解决上述场景中的问题,MaxCompute提供了MATERIALIZE CTE能力,支持将CTE计算结果缓存,以供WITH语句外层的SQL引用,而无需全部展开。这一机制能够有效避免嵌套CTE展开而导致的内存超限问题,从而提升CTE的语句性能。
使用示例
定义CTE时,可在SELECT语句中使用MATERIALIZE HINT提示 /*+ MATERIALIZE */ 将CTE的计算结果缓存到一张临时表中,后续引用时候,可以直接从缓存中读取结果,不需要重新计算。示例如下:
WITH
v1 AS (SELECT /*+ MATERIALIZE */ SIN(1.0) AS a)
SELECT a FROM v1 UNION ALL SELECT a FROM v1;
-- 返回结果如下。
+------------+
| a |
+------------+
| 0.8414709848078965 |
| 0.8414709848078965 |
+------------+当MATERIALIZE HINT生效时,在LogView的Job Details页签中可以看到,中间的结果落盘,对应提交了多个Fuxi Job。
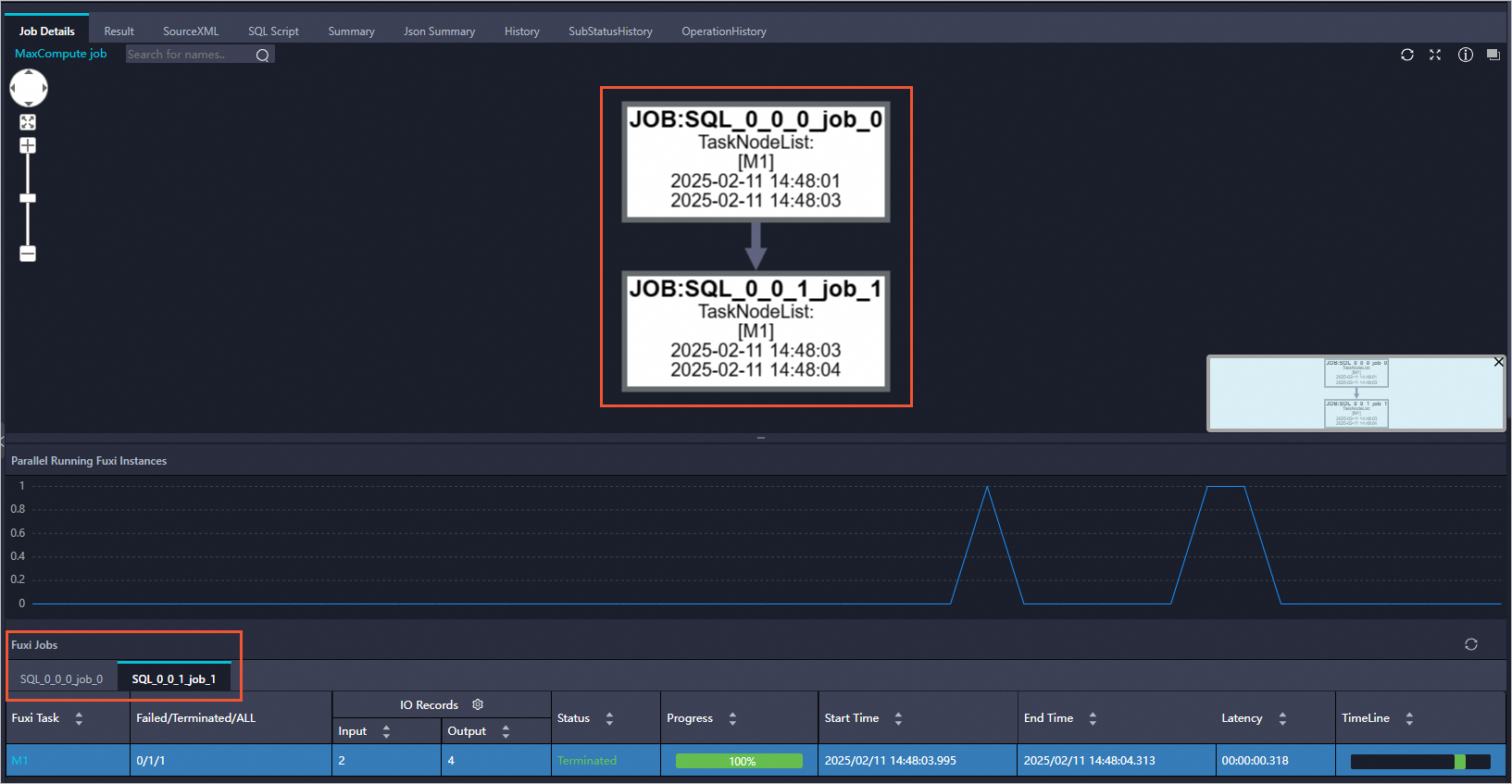
使用限制
MATERIALIZE HINT必须应用于NON RECURSIVE CTE顶级的SELECT语句中,递归CTE不需要使用MATERIALIZE HINT。
错误示例:如下CTE中的顶级语句是UNION而不是SELECT,所以MATERIALIZE HINT不会生效。
WITH v1 AS (SELECT /*+ MATERIALIZE */ SIN(1.0) AS a UNION ALL SELECT /*+ MATERIALIZE */ SIN(1.0) AS a) SELECT a FROM v1 UNION ALL SELECT a FROM v1;在LogView中可以看到,对应仅提交了一个Fuxi Job,如下图所示。
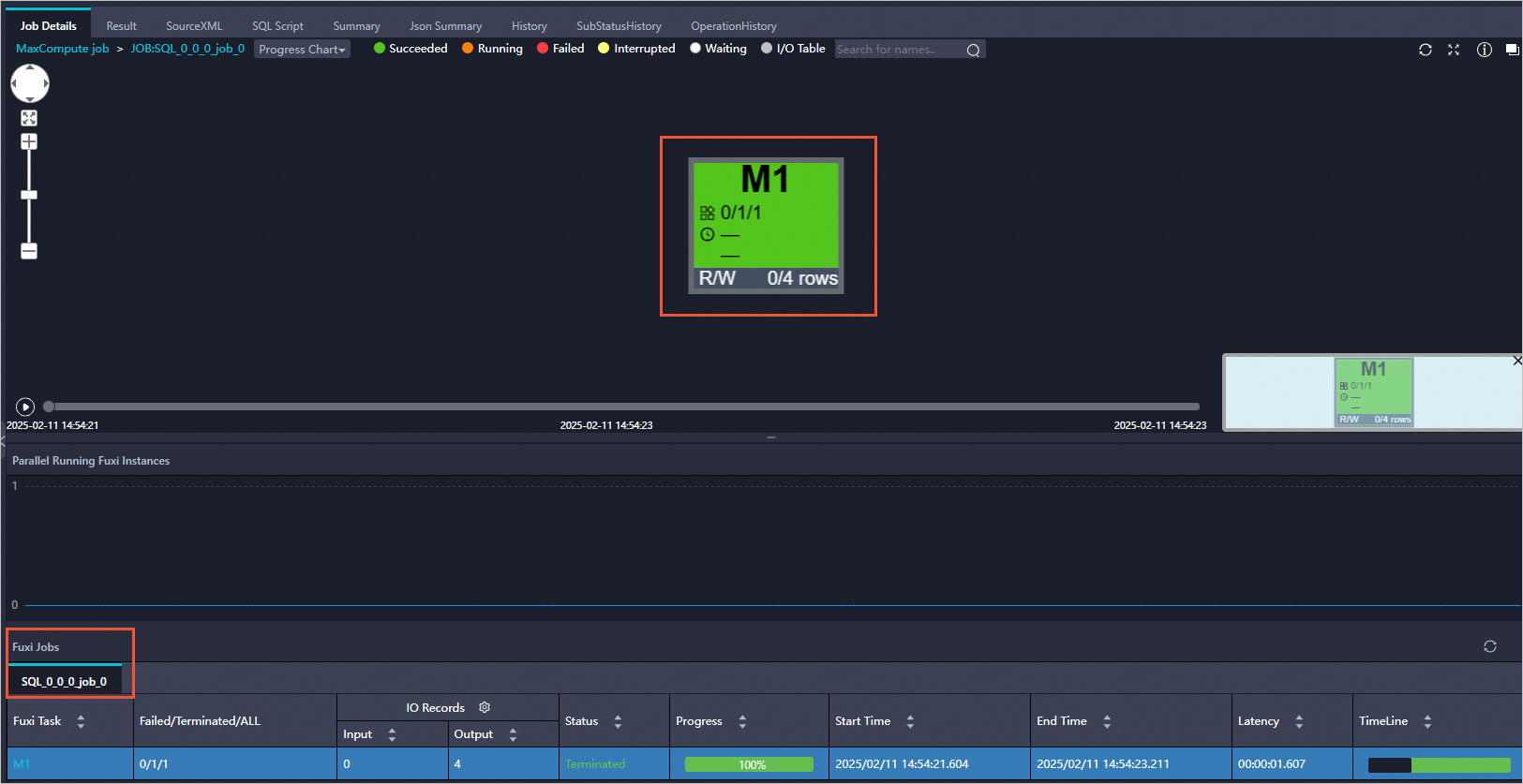
正确示例:将上述错误示例改写为子查询来解决。
WITH v1 AS (SELECT /*+ MATERIALIZE */ * FROM (SELECT SIN(1.0) AS a UNION ALL SELECT SIN(1.0) AS a) ) SELECT a FROM v1 UNION ALL SELECT a FROM v1;
如果CTE中使用了非确定性的函数,例如RAND函数或者是用户自定义的非确定性的Java/Python UDF,将CTE修改为MATERIALIZE CTE之后,缓存机制可能会导致最终计算结果发生变化。
MATERIALIZE CTE不支持在开启查询加速(MCQA)模式中执行。若用户在MCQA模式中使用MATERIALIZE CTE,当设置了
interactive_auto_rerun=true,任务可以回退到普通模式执行。否则任务会失败。