
数据跨境传输合规声明
如果在使用 XCOPY 时涉及跨境数据传输,需符合相关地域的法律法规要求。
请注意,该功能将使您在云上的业务数据传输至您所选择的区域或产品部署区域,可能会涉及数据跨境。您同意并确认,您完全拥有该份业务数据的所有处置权限,对数据传输的行为全权负责。
您应确保您的数据传输符合所有适用法律,包括提供充分的数据安全保护技术和策略,履行获得个人充分明示同意、完成数据出境安全评估和申报等法定义务,且您承诺您的业务数据不含任何所适用法律限制、禁止传输或披露的内容。
如您未遵守前述声明与保证,您将承担对应的法律后果,导致阿里云和或其他关联公司遭受任何损失的,您应承担赔偿责任。
功能介绍
跨地域数据复制(XCOPY)功能支持表快照(Snapshot)增量复制,适用于跨Region数据备份、迁移、共享等场景。
采用文件级增量复制,拷贝列压缩的二进制数据文件,兼顾传输效率、降低传输成本及数据一致性。
基于表快照(SnapShot)复制,复制后的数据与原表解耦,独立管理备份生命周期。
表快照(Snapshot)副本的数据可恢复时间点明确,即Point-in-Time Recovery(PITR)。可以从上游数据源补全最近丢失数据。
增量复制为分区(Partition)级,前后两次复制基于同一个表的两个Snapshot。如果有重复的分区,将不会触发重复复制,只复制差异的分区。
计费参考:跨地域数据复制费用。
适用范围
地域限制:中国香港、新加坡、日本(东京)。
跨Region带宽:初始值为10Gbps,按需调整。
XCOPY对象:表快照(SnapShot)。
表快照支持对普通表(包括分区/非分区/聚簇表)、PK/Append Delta Table 创建,不支持对 Transaction Table 创建。
XCOPY任务数上限:
每个项目最多并发执行128个XCOPY Snapshot,超过限制后任务提交会失败。
权限限制:
待复制数据源的项目和复制目标的项目必须归属于同一个主账号。
在待复制数据源的项目中,具备待复制表快照(SnapShot)的
SELECT权限。在复制目标的项目中,具备
CREATE TABLE权限。
备Region的备份Project建议只用于存储备份数据和临时查询,如需在备Region跑生产业务建议另外创建Project。
XCOPY功能开通
开通步骤
通过提交工单,提供待备份的项目名称。
在控制台打开XCOPY通道开关。
在数据源Region开启XCOPY通道开关,允许数据源Region中的数据被有权限的用户通过XCOPY方式复制到其他Region。
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择 。
在租户管理页面,单击租户属性页签。
在租户属性页签,打开XCOPY通道开关。
XCOPY命令说明
命令格式
XCOPY SNAPSHOT <src_remote_project_name>.<src_remote_snapshot_name>
TO SNAPSHOT [<dest_local_project_name>.]<dest_local_snapshot_name>
OPTIONS(src_region=<region_name>); 参数说明
src_remote_project_name:待复制数据源的项目名称。
src_remote_snapshot_name:待复制数据源项目中的表快照(SnapShot)名称。
dest_local_project_name:选填。复制目标的项目名称。
dest_local_snapshot_name:复制目标的项目中待创建或覆盖的表快照(SnapShot)名称。
region_name:待复制数据源的地域名称。例如中国香港:cn-hongkong,日本(东京):ap-northeast-1。更多region name参考Region name。
使用示例
该示例实现新加坡(SGP)主 Region 到中国香港(HK)备 Region 的数据容灾备份。如下图所示:
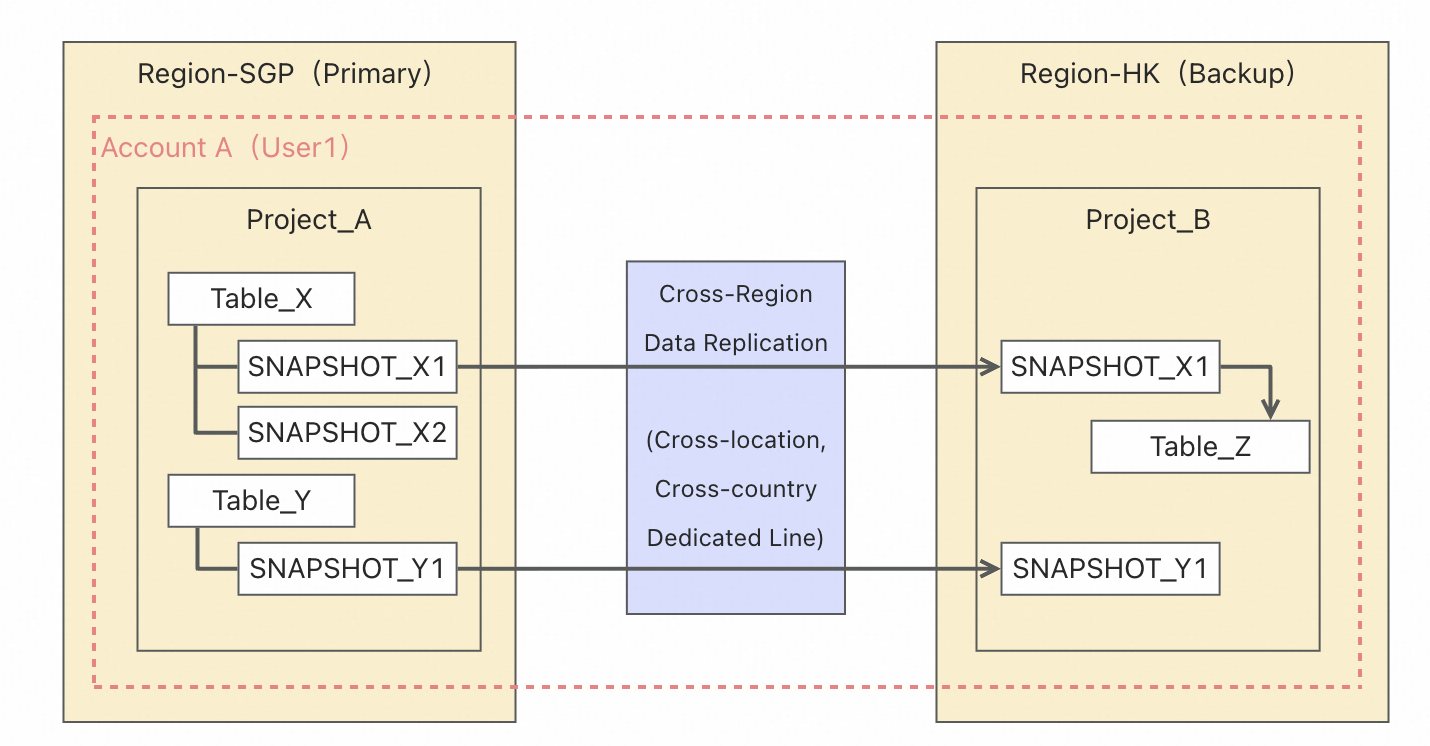
备份阶段
主区域(Region-SGP):Account A(User1)下的 Project_A 包含源表 Table_X 和 Table_Y,分别创建快照 SNAPSHOT_X1/X2 和 SNAPSHOT_Y1。
-- 备份阶段 -- User在 Region-SGP 创建快照 CREATE SNAPSHOT TABLE Project_A.table_x_snapshot_20260101 CLONE Project_A.table_x;跨域复制
通过跨地、跨国专线将快照数据从主 Region复制到备 Region。
-- User在 Region-HK Copy Region-SGP 创建的快照 XCOPY SNAPSHOT Project_A.table_x_snapshot_20260101 TO SNAPSHOT Project_B.table_x_snapshot_20260101 OPTIONS( src_region =” ap-southeast-1”);恢复阶段
备区域(Region-HK):Project_B 接收复制后的快照,可基于快照恢复为 Table_Z 等目标表。
-- 恢复阶段 -- User在 Region-HK 临时查询备份数据 SELECT * FROM Project_B.table_x_snapshot_20260101; -- User在 Region-HK 恢复数据 CREATE TABLE table_x CLONE table_x_snapshot_20260101;
每日跨Region备份固定的Table
步骤一:在主Region创建Snapshot
进入 DataWorks 开发环境
登录DataWorks控制台,在左上角选择地域。
在左侧导航栏选择工作空间。
选择工作空间,单击进入Data Studio。
新建MaxCompute SQL 节点
在Data Studio左侧,单击
 ,选择。
,选择。节点名称:create_daily_snapshots
节点描述:每日为表创建快照
编写 SQL 脚本
-- 表a快照命名方式为a_snapshot_20260101 -- var1、var2 在右侧导航栏运行配置中,配置为$[yyyymmdd],表示当前时间 CREATE SNAPSHOT TABLE a_snapshot_${var1} CLONE a; CREATE SNAPSHOT TABLE b_snapshot_${var2} CLONE b;配置调度属性
点击节点右上角调度配置,单击调度时间,配置属性如下:
配置项
填写示例
调度周期
日
调度时间
01:00
生效日期
永久生效
指定时间:2026-01-01 ~ 9999-12-31(长期有效)
步骤二:在备Region XCOPY Snapshot
进入 DataWorks 开发环境
登录DataWorks控制台,在左上角选择地域。
在左侧导航栏选择工作空间。
选择工作空间,单击进入Data Studio。
新建MaxCompute SQL 节点
在Data Studio左侧,单击
,选择。节点名称:create_daily_snapshots
节点描述:每日为表创建快照
编写 SQL 脚本
-- 表a快照命名方式为a_snapshot_20260101 -- var1、var2 在右侧导航栏运行配置中,配置为$[yyyymmdd],表示当前时间 CREATE SNAPSHOT TABLE a_snapshot_${var1} CLONE a; CREATE SNAPSHOT TABLE b_snapshot_${var2} CLONE b; -- 表a快照命名方式为a_snapshot_20260101 XCOPY SNAPSHOT src_project.a_snapshot_$[yyyymmdd] TO SNAPSHOT a_snapshot_$[yyyymmdd] options(src_region="cn-hongkong"); XCOPY SNAPSHOT src_project.b_snapshot_$[yyyymmdd] TO SNAPSHOT b_snapshot_$[yyyymmdd] options(src_region="cn-hongkong");配置调度属性
点击节点右上角调度配置,单击调度时间,配置属性如下:
配置项
填写示例
调度周期
日
调度时间
02:00
生效日期
永久生效
指定时间:2026-01-01 ~ 9999-12-31(长期有效)
步骤三:在备Region检查Snapshot完整性
在租户级别Information Schema中检查备 Region Snapshot 是否全部创建完成。
在备 Region 中执行如下代码,查看Snapshot创建数量是否与 XCOPY 复制的Snapshot 数量一致。
SET odps.namespace.schema=true; SELECT * FROM SYSTEM_CATALOG.INFORMATION_SCHEMA.tables WHERE table_catalog = <dest_project> AND table_type = 'SNAPSHOT_TABLE' AND table_name LIKE "%_snapshot_20260101";数据内容抽样验证(按需执行)
在主、备Region 计算Snapshot的统计信息和 MD5,验证数据一致性。
-- 通过count、sum、distinct、min、max统计对比。 -- 把Table分1000个桶进行细分对比,确保每个桶内数据每行的MD5求和结果一致。每行的MD5计算方式为该行每列数据拼装成字符串算MD5。 WITH table_hashs AS ( SELECT COUNT(1) row_count, MD5( SUM( MD5( CONCAT_WS('|', <column_name_1>, <column_name_n>) ) ) ) AS bucket_hash FROM <snapshot_name> GROUP BY HASH(<column_name_1>) % 1000 ) SELECT SUM(row_count) AS row_count, MD5(WM_CONCAT(',', bucket_hash ) WITHIN GROUP (ORDER BY bucket_hash)) AS table_hash FROM table_hashs;