
MaxCompute提供了多种数据湖分析方案,基于多种对接数据湖的功能和方案,打破数据湖与数据仓库割裂的体系,融合数据湖的灵活性、丰富的多引擎生态与数据仓库的企业级能力,助力构建数据湖和数据仓库相融合的数据管理平台。
数据湖分析和湖仓开放架构
数据仓库更强调对进入数仓的结构化、半结构化数据的管理和约束,并依赖强管理能力,获得更好的计算性能和更规范化的管理能力。
数据湖更强调数据存储的开放性和数据格式的通用性,支持多种引擎按需生产或消费数据,为保障灵活性只提供弱管理能力,可以兼容非结构化数据,并支持后建Schema的使用方式,是一种更灵活的数据管理方式。
因此MaxCompute提出湖仓一体解决方案,融合了数据仓库和数据湖能力。
数据湖分析
MaxCompute支持对接数据湖进行数据湖分析,提供以下能力:
作为高性能高性价比的批处理计算引擎在湖上和其他引擎基于一份数据协同计算;
将数仓的管理能力延伸到数据湖上,使数据湖更安全可控;
将高价值数据向数据仓库沉淀;
基于数据仓库与包括数据湖、数据库等在内的多种外部数据源进行仓内仓外数据联邦计算。
湖仓开放架构
MaxCompute也是大数据存算分离架构,其开放存储、开放元数据和多引擎架构构成了一套湖仓开放架构,提供以下能力:
湖上元数据发现和管理;
对外部提供数仓的元数据和MaxCompute管理的湖表元数据统一视图;
开放MaxCompute存储,支持MaxCompute引擎和外部三方引擎消费MaxCompute数据;
基于元数据管理服务和数据服务,控制多引擎读写MaxCompute湖仓架构下数据的行为,例如控制不同用户身份使用多个引擎操作同一份数据湖上的数据的权限,协同写入数据的任务,保证任何引擎操作数据后元信息都可以被其他引擎感知,支持读出的数据符合平台统一定义的规则(例如数据脱敏),以及支持对开放数据进行自动维护和优化(例如自动compact),便于引擎更高效率的使用数据湖数据。
详见湖仓开放架构。
MaxCompute的数据湖分析功能体系
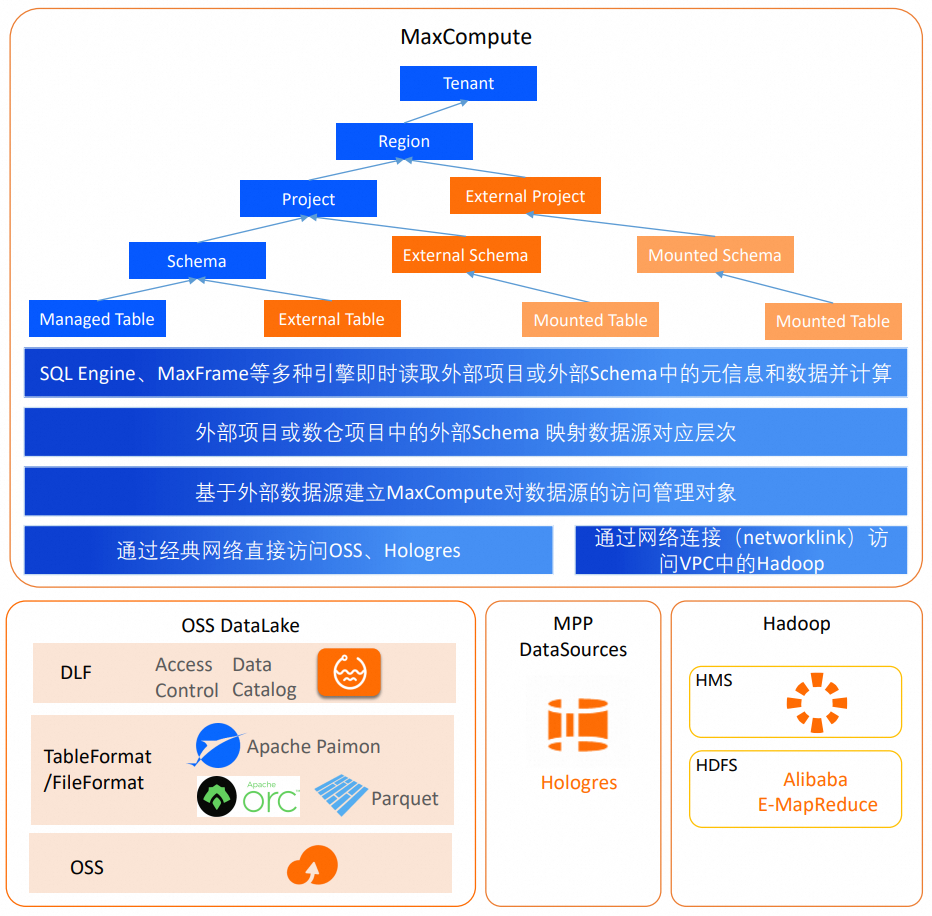
MaxCompute对数据湖分析和联邦计算的能力按照对外部数据的管理能力由弱到强排列,包括Schemaless Query、外部表、托管湖表,而湖上的元数据管理服务不只在MaxCompute,还有如DLF、文件系统catalog层析规范等。因此,又推出了基于外部元信息映射外部数据源进行数据分析和处理的External Schema和External Project方案。
Schemaless Query
Schemaless Query(免定义查询)支持MaxCompute SQL引擎无需预先定义OSS中Parquet、CSV、JSON等数据的Schema和分区信息,而是通过解析样例数据自动获取元信息(如Parquet文件的Schema、CSV表头、JSON自描述信息),直接访问OSS目录中的数据。查询结果可以导出至OSS、写入内部表,也可以作为子查询嵌入SQL运算,从而便捷地操作湖上数据。
外部表
外部表通过DDL语句定义访问MaxCompute外部数据所需的表名、Schema、表属性、权限、位置和协议等信息,这些信息记录在MaxCompute元数据中。SQL引擎基于这些元信息,根据不同的外部表格式采用对应的方式连接外部数据源,实现外部数据的元信息获取与更新,以及数据的读取、计算和写出。
湖表
为了进一步保证数据湖上的数据更符合管理要求,MaxCompute基于开放的存储服务OSS、开放的湖格式Iceberg和MaxCompute 开放元数据服务,数据读写服务Storage API和开源引擎Connector,提供了MaxCompute管理体系下的湖表功能。
湖表的Schema和分区等信息由湖格式文件Iceberg提供,可以提供更灵活的Schema evolution能力;
湖表元信息本身存储在MaxCompute元数据服务中,MaxCompute引擎和第三方引擎读取数据可以遵守元数据服务统一定义的规则,写入数据也可以保证元数据更新可以被其他基于元数据服务的引擎立即感知;
湖表管理能力还包括湖仓统一权限管理和湖表底层文件运维管理。如果需要原生的开放性,MaxCompute湖表后续还提供原生的iceberg rest catalog元数据服务和只读的直接堆积OSS的iceberg快照文件访问能力。
详情参见MaxCompute管理的Iceberg表(beta),此功能于北京时间2026年5月7日在上海和德国region邀测发布。
外部模式和外部项目
外部模式和外部项目与外部表最大的不同在于:外部数据的元信息不在MaxCompute内部存储和维护,而是从外部数据源实时获取。用户需要先创建管理对象,定义与外部元数据服务、数据服务或数据库实例的访问方式。MaxCompute通过该管理对象实时获取外部元数据,再通过外部模式或外部项目的映射机制,直接访问外部数据源Catalog、Database或Schema范围内的全部表。
功能和基本概念
网络连接
详情请参见网络开通流程中Networklink的相关说明。MaxCompute可以通过网络连接访问VPC网络中的数据源,例如EMR实例,RDS实例(准备中)。DLF(Data Lake Formation,数据湖构建)、OSS(对象存储)和Hologres位于云产品互联网络中,MaxCompute无需设置网络连接对象Networklink即可直接访问其中的数据。
网络连接同时支持外部表、需要访问VPC网络中数据源的外部模式和外部项目。
外部数据源(Foreign Server)
包含了元数据和数据访问的信息,同时包含访问数据源系统的身份认证信息,位置信息和连接协议说明等。通过外部数据源,MaxCompute才可以连接和使用数据源的元数据和数据。外部数据源是租户面的管理对象,由租户管理员定义。
外部数据源支持外部模式和外部项目。后续Foreign Server会逐步过渡为Connection对象,从租户面对象调整为数据面对象,支持湖表、外部模式,而之前依赖Foreign Server的外部项目则把Foreign Server的信息转存到外部项目上,而不再依赖新的Connection对象,这一过渡过程用户并不感知。
外部模式(External Schema)
外部模式是MaxCompute数仓项目中一种特殊Schema,如上图所示,可以映射数据源的Database(DLF_lagecy或Hive场景)或Schema(Hologres场景)层级,并可直接访问对端Database或Schema范围内的表和数据。这种并没有在MaxCompute元数据中创建,只是通过外部Schema映射至对端数据源的表被称为联邦外表(Mounted Table)。
联邦外表在MaxCompute内不存储元数据信息,而是由MaxCompute通过外部数据源对象中的元数据服务实时获取。用户查询时无需在数仓中通过DDL语句创建外部表,可直接以项目名称和外部模式名称作为命名空间,引用数据源原表名的方式进行操作。数据源表结构或数据发生变化时,联邦外表能够即时反映数据源表的最新状态。外部Schema映射的数据源层次由外部数据源定义的层次与数据源中表层次之间的系统层次决定。外部数据源定义的层次由认证身份能访问的数据源层次决定。
外部项目(External Project)
在湖仓一体1.0方案中,外部项目是两层模式,和外部模式一样映射一个数据源的Database(DLF_lagecy或Hive场景)或Schema(Hologres场景)层级,且需要依赖一个数仓项目作为任务运行环境才可以读取外部数据并计算。但是以项目层级映射数据源Database或Schema会导致外部项目数量过多,且MaxCompute后续建议构建的项目为三层模式,便于和外部数据源三层的Catalog层析对应,而两层的湖仓一体1.0的外部项目难以和新的三层数仓项目共同使用,所以MaxCompute会逐步收敛湖仓一体1.0的外部项目,存量用户可以将其迁移到外部Schema上。迁移方案详情参见:湖仓一体1.0外部项目迁移为湖仓一体2.0外部模式方案。
在数据湖分析中,新的外部项目直接映射对端三层模式数据源Catalog(DLF场景)或Database(Hologres场景),并直接可见DLF Catalog之下的Database,或Hologres Database之下的Schema ,这层在MaxCompute中也不通过创建而是直接映射而来,称为Mounted Schema,再以联邦外表的方式访问数据源表。
数据源类型 | 外部数据源层次 | 外部Schema映射层次 | 外部项目映射层次 | 湖仓一体1.0外部项目(下线中)映射层次 | 认证方式 |
DLF_legacy+OSS | Region级别DLF服务和OSS服务 | DLF的Catalog.Database | 不支持 | DLF的Catalog.Database | RAMRole |
Hive+HDFS | EMR实例 | Hive的Database | 不支持 | Hive的Database | 免认证方式 |
Hologres | Hologres实例的Database | Schema | - | 不支持 | RAMRole |
- | Database | 不支持 | SLR+当前用户身份认证 | ||
DLF | Region级别DLF服务 | 不支持 | DLF的Catalog | 不支持 | SLR+当前用户身份认证 |
Filesystem Catalog | OSS上Paimon Catalog级别目录 | 不支持 | Paimon Catalog级别目录解析的Catalog | 不支持 | RAMRole |
不同数据源的认证方式有多种类型,MaxCompute会在后续版本逐步提供多种认证方式,例如访问Hologres使用当前用户身份方式、访问Hive使用Kerberos认证方式等。