
本文为您介绍任务运行失败的报错信息及解决方法。
Seek阶段pk重复导致运行失败
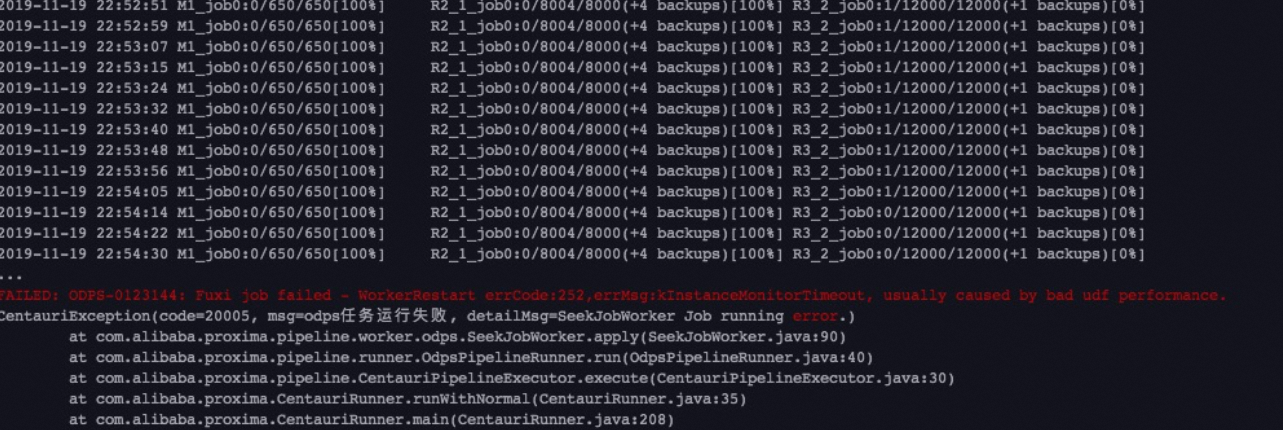
报错信息
解决方法
打开运行MaxCompute任务的Logview,并查看StdOut中的值。Loview使用方法请参考使用Logview查看作业运行信息。
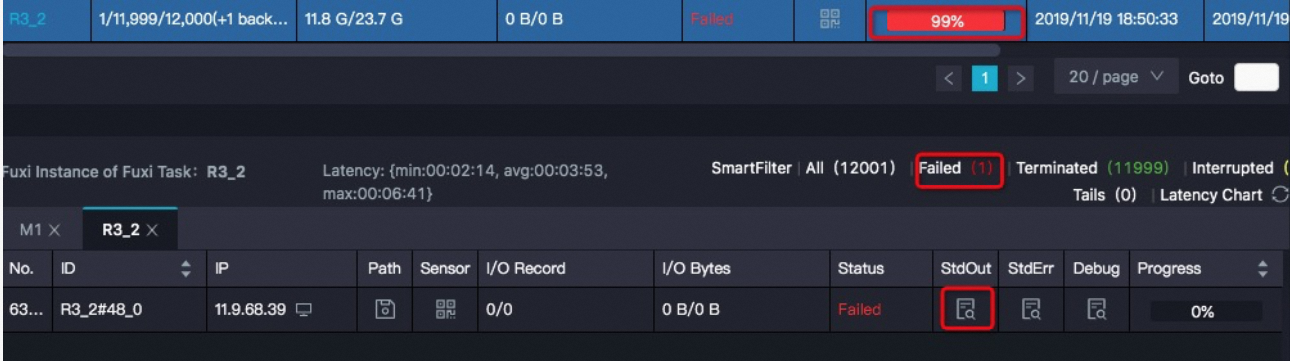
 如果该实例的record number比其它实例大很多,请检查数据是否存在pk相同、但value不同的vector。此种情况是数据没有去重,在数据库当中有pk相同,但是向量不同的数据。在seek阶段M-R1-R2的R1到R2的过程,会将这些数据交给同样的Reducer去执行,导致数据倾斜,造成某个Reduce Job挂掉。
如果该实例的record number比其它实例大很多,请检查数据是否存在pk相同、但value不同的vector。此种情况是数据没有去重,在数据库当中有pk相同,但是向量不同的数据。在seek阶段M-R1-R2的R1到R2的过程,会将这些数据交给同样的Reducer去执行,导致数据倾斜,造成某个Reduce Job挂掉。
小类目检索准备阶段GetSmallCategoryDocNum为空
报错信息

解决方法
该问题的主要原因是表当中某些字段的值为空,比如category列的值为空或者pk列的值为空,建议通过SQL将这些空值对应的record删除。
小类目检索阶段schema validation不匹配
报错信息
2020-07-28 16:58:15.221 [main] INFO p.a.p.p.ProximaCEPipelineExecutor - [] - execute SmallCategorySeek worker start .......... [400] com.aliyun.odps.OdpsException: ODPS-0420031: Invalid xml in HTTP request body - The request body is malformed or the server version doesn't match this sdk/client. XML Schema validation failed: Element 'Value': [facet 'maxLength'] The value has a length of '4952955'; this exceeds the allowed maximum length of '2097152'. Element 'Value': '{"MaxCompute.pipeline.0.output.key.schema":"instId:BIGINT,type:BIGINT,pk:STRING,category:BIGINT","MaxCompute.pipeline.0.output.value.schema":"v解决方法
表明doc表中的类目数量太多,需要按类目拆分成多个表。
解析表数据时出现“-nan”错误
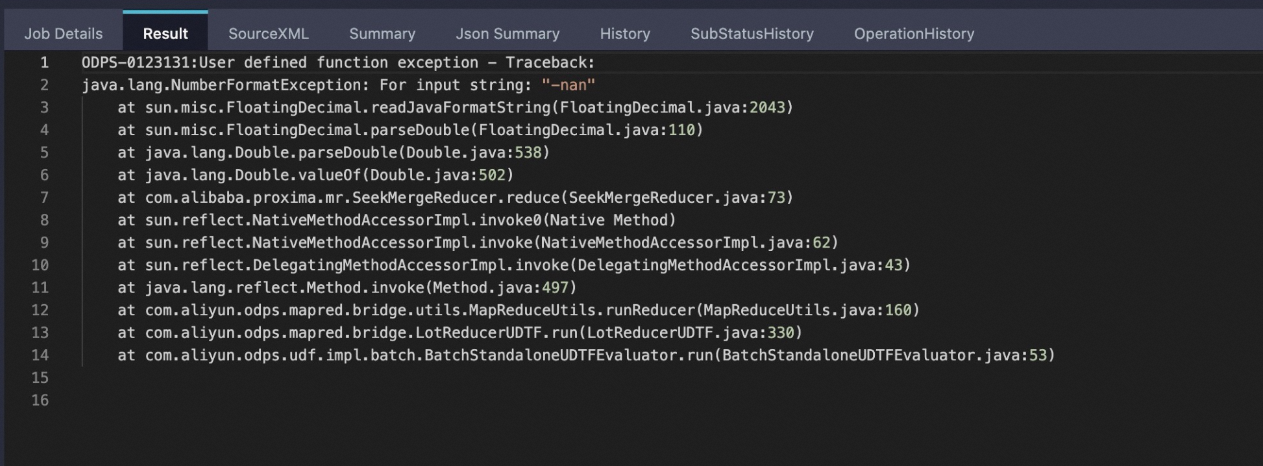
报错信息
解决方法
该问题一般是原始doc或query表输入的格式有问题,可能存在很大的值或者接近0的值。例如某一行vector下的值为
1.23~4.56~7.89~nan~4.21或1.1~2.2~127197893781729178311928739179222121.23128767846816278193456789087654~ 0.000000000000000000000000000000000000000001~5.5,会导致在数值计算时溢出或者出现除零错误。可以尝试使用MaxCompute的SQL UDF过滤出doc表和query表中的问题数据。
多类目情况下,某个类目doc数目为0,query数目不为0导致的jni调用异常
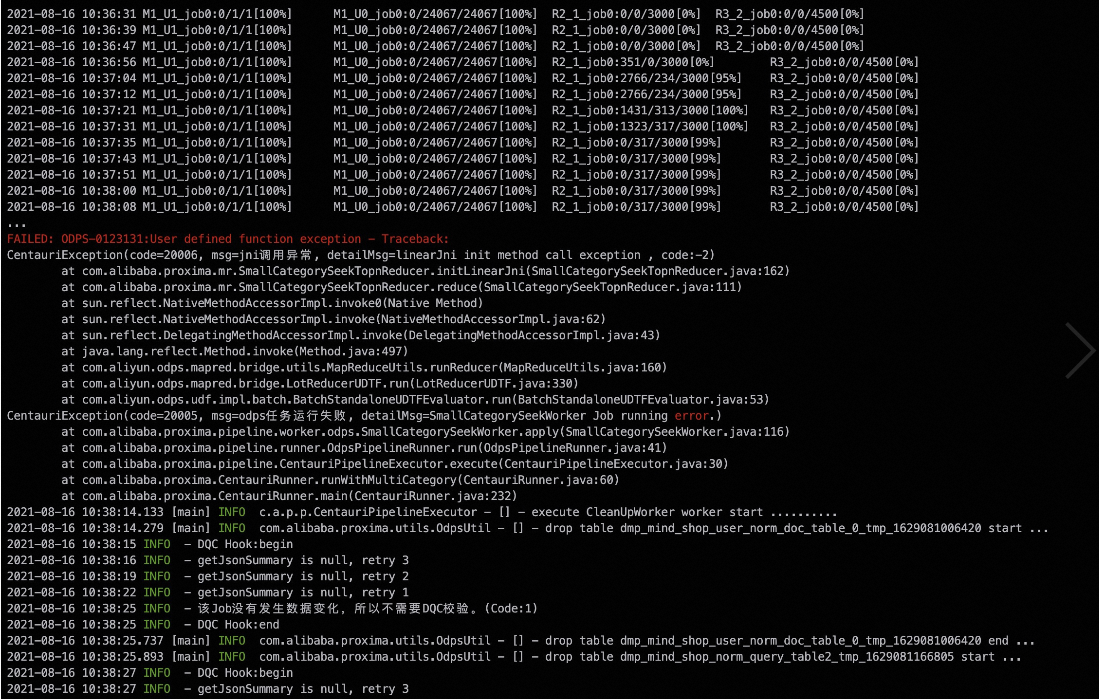
报错信息

解决方法
这种情况被认为是用户输入问题,在设计时发现这样的情况时通过报错终止来提示用户,而不是忽略。这样做防止用户需要某个类目的召回结果,但是最终没有召回,如果忽略将会导致隐蔽的Bug。解决方案是剔除query或doc表中记录为0的对应类目,因为空记录的召回无论是doc还是query都是无实际意义的。
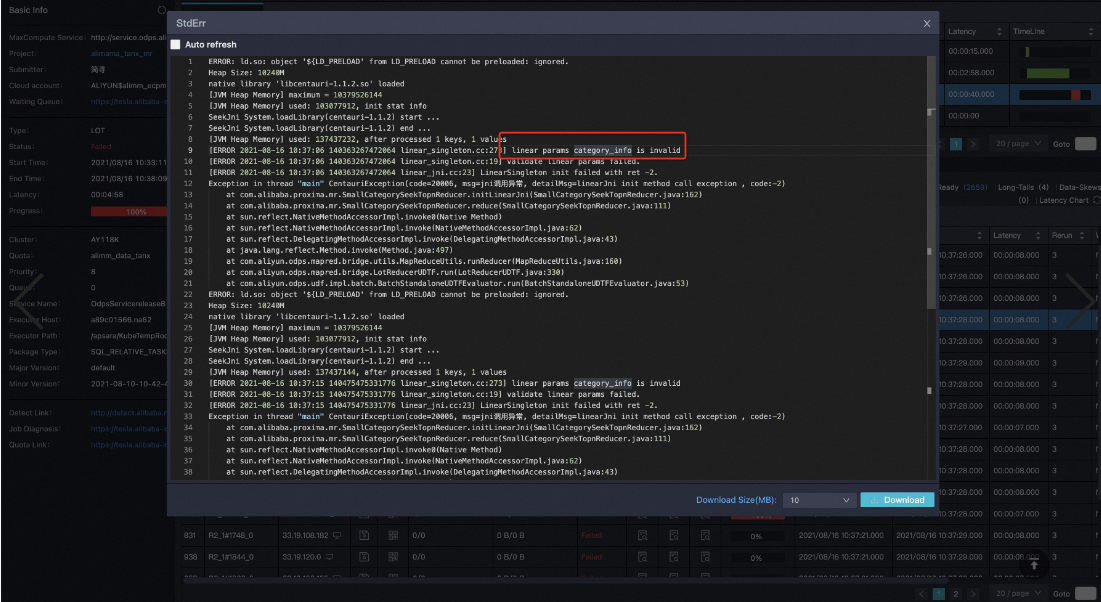
MaxCompute Tunnel Endpoint问题
报错信息
建立DownloadSession失败 ErrorCode=Local Error, ErrorMessage=Failed to create download session with tunnel endpoint解决方法
该问题的主要是Proxima CE内部调用MaxCompute关于Tunnel的某些接口失败导致的,存在的原因有:
网络问题,重试即可。
跨网络访问。Tunnel Endpoint设置错误导致的读取MaxCompute table count失败。详情参考Tunnel命令常见问题 。用户可以通过添加启动参数-tunnel_endpoint指定有效的Tunnel Endpoint重新运行。
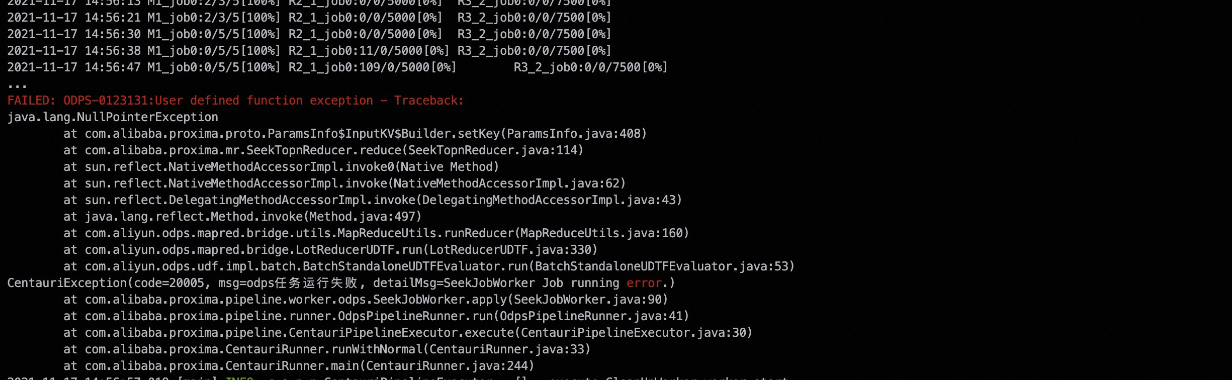
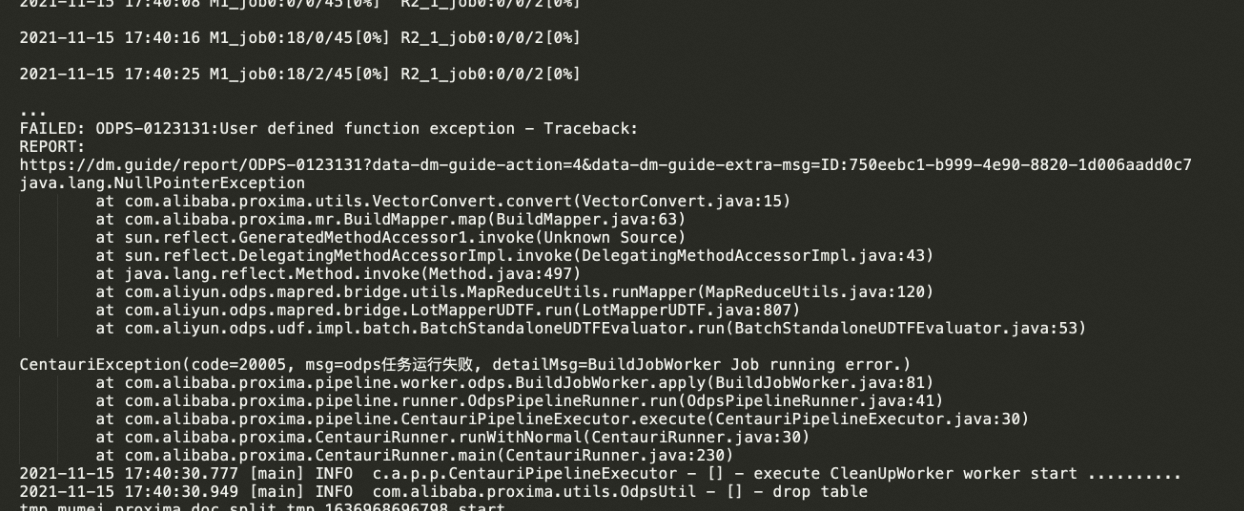
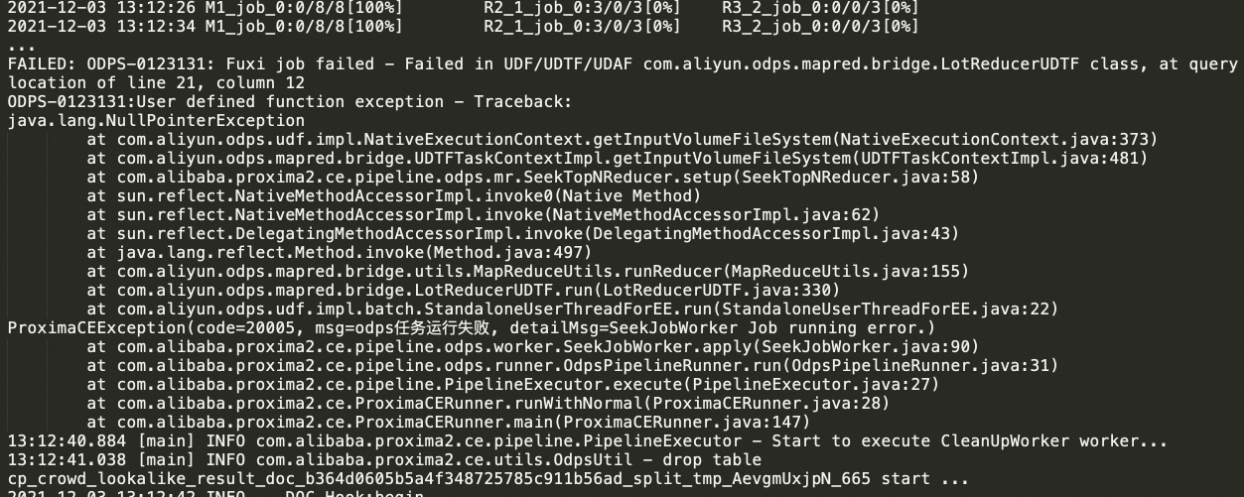
运行过程中MapReduce里的java NPE (java.lang.NullPointerException) 问题
报错信息
error example1:
setKey()导致。error example2:
VectorConvert.convert()导致。error example3:
getInputVolumeFileSystem()导致。
解决方法
对于error example1和error example2:一般是由于在build或seek阶段,MR任务读取输入表中的某一列时失败导致,可能的原因有:
该列不存在。
该列下存在某行值为null。
该列下存在某行值不合法,导致解析错误。
一般在build阶段失败需要检查doc表是否存在上述问题,在seek阶段失败需要检查query表是否存在上述问题,build/seek阶段区分如下:
build阶段是由Mapper-Reducer构成的MR任务,通常在日志里如上述error example2的输出。
seek阶段是由Mapper-Reducer1-Reducer2构成的MRR任务,通常在日志里如上述error example1的输出。
对于error example3:一般是由于在seek阶段Mapper任务获取MaxCompute Volume时出现错误,找不到对应的Volume及对应的 Volume Partition,主要原因可能有:
同一时间运行多个具有相同输入doc表的任务,最后运行日志会报如图所示错误。对于当前版本Proxima CE,对索引的分区是依赖输入的doc表名和分区名的,因此同时跑多个任务时,如果doc表相同,会出现多个任务对同一个Volume下的索引文件有覆盖甚至删除的错误,导致读取MaxCompute Volume失败,类似的也会导致索引加载失败。可以通过调整任务的输入doc表名不同,保证每个任务的正常运行。
行列设置有问题。MaxCompute目前支持reducer实例最多为99999个,如果用户设置的-column_num和-row_num过大,会导致seek阶段MRR任务的实例个数(
实例个数 = column_num * row_num)超过限制,这样会导致不可控的错误,使得seek阶段的reducer无法找到正确的索引Volume。可以通过使用合理的行列值来保证,详情请参考聚类分片。
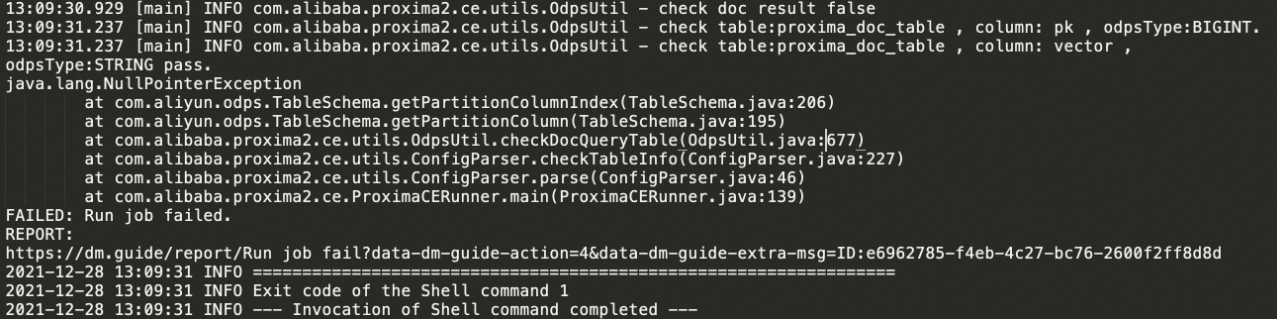
getPartitionColumn获取分区列pt出错
报错信息
解决方法
一般这种情况是没有检查到
pt列,目前doc_table和query_table强制规定了表的schema,其中规定partition列为STRING类型的pt列,详情请参考导入数据至 输入表。另外pt列必须指定为分区列,如果是普通列也会出现同样的错误。
报错ShuffleServiceMode: Dump checkpoint failed
报错信息
0010000:System internal error - fuxi job failed, caused by: ShuffleServiceMode: Dump checkpoint failed解决方法
该问题一般是单个实例output size超限导致的,即MR处理过程中,单个Mapper或Reducer实例的输出超过限制(400 GB)。原因为单个实例处理的数据过大,或者Mapper或Reducer内部逻辑导致数据膨胀过大。可以通过指定-mapper_split_size参数调低单个Mapper切分的数据大小来解决,单位为MB。
FAILED: MaxCompute-0430071: Rejected by policy - rejected by system throttling rule
报错信息
FAILED: MaxCompute-0430071: Rejected by policy - rejected by system throttling rule解决方法
这种情况是MaxCompute系统限流,任务的执行请求被拒绝,有可能是集群在执行其他任务(例如:压测任务),也有可能是为了安全保障某段时间内禁止用户执行任务。一般过段时间重跑任务即可,具体时间可以询问Project Owner或Project集群所在负责人。
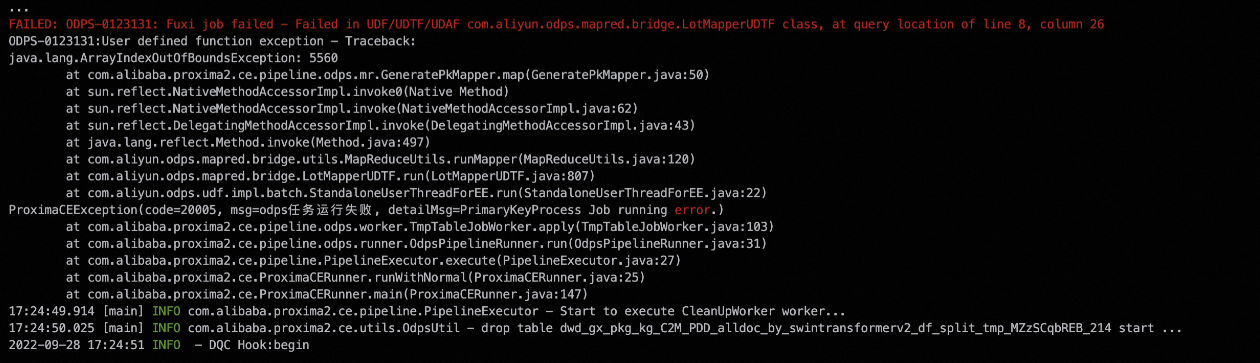
因读表失败导致的 java.lang.ArrayIndexOutOfBoundException
报错信息
解决方法
这种情况的原因通常是内部Mapper任务
GeneratePkMapper依赖读取的一个数组长度未获取到正确数据,通常情况该数组长度是前序的SQL任务通过读表获取的,一般是因为读表失败导致的。超时:由于Project所在集群网络波动导致,一般重试几次或者过段时间重跑即可。
Tunnel Exception:Proxima CE内部读表时会通过Tunnel获取表记录,因此Tunnel失败也会导致读表失败,Tunnel错误可以参考MaxCompute Tunnel Endpoint问题。
运行聚类分片时,遇到Timeout问题
报错信息
FAILED: ODPS-0010000:System internal error - Timeout when graph master wait all workers start java.io.IOException: Job failed! at com.aliyun.odps.graph.GraphJob.run(GraphJob.java:429) at com.alibaba.proxima2.ce.pipeline.odps.worker.KmeansGraphJobWorker.apply(KmeansGraphJobWorker.java:131) at com.alibaba.proxima2.ce.pipeline.odps.runner.OdpsPipelineRunner.run(OdpsPipelineRunner.java:31) at com.alibaba.proxima2.ce.pipeline.PipelineExecutor.execute(PipelineExecutor.java:27) at com.alibaba.proxima2.ce.ProximaCERunner.runWithNormal(ProximaCERunner.java:28) at com.alibaba.proxima2.ce.ProximaCERunner.main(ProximaCERunner.java:149)解决方法
聚类分片在构建索引时,首先会基于Graph引擎做数据聚类,具体是执行对应的GraphJob来完成,GraphJob会默认申请一个Worker数量,当集群资源不足时会出现上述问题。可以在执行命令里限定执行GraphJob的Worker数量来限制资源申请。在Proxima CE的启动命令前设置参数:
set odps.graph.worker.num=400; -- 400 是实例说明,具体数量根据集群资源设置完整命令如下:
set odps.graph.worker.num=400; jar -resources kmeans_center_resource_cl,proxima-ce-aliyun-1.0.0.jar -classpath http://schedule@{env}inside.cheetah.alibaba-inc.com/scheduler/res?id=251678818 com.alibaba.proxima2.ce com.alibaba.proxima2.ce.ProximaCERunner -doc_table doc_table_pailitao -doc_table_partition 20210707 -query_table query_table_pailitao -query_table_partition 20210707 -output_table output_table_pailitao_cluster_2000w -output_table_partition 20210707 -data_type float -dimension 512 -oss_access_id xxx -oss_access_key xxx -oss_endpoint xxx -oss_bucket xxx -owner_id 123456 -vector_separator blank -pk_type int64 -row_num 10 -column_num 10 -job_mode build:seek:recall -topk 1,50,100,200 -sharding_mode cluster -kmeans_resource_name kmeans_center_resource_cl -kmeans_cluster_num 1000;