本文以开源数据集(Mushroom Data Set)为例,介绍如何快速使用MaxCompute SQLML及机器学习的逻辑回归二分类模型,预测蘑菇是否有毒。
前提条件
已注册阿里云账号,并完成实名认证。更多信息,请参见准备阿里云账号。
如果您需要使用RAM用户身份进行操作,请确认账号可用并已授权,详情请参见准备RAM用户。
操作步骤
可选:开通MaxCompute按量计费服务、DataWorks(基础版)服务及人工智能平台 PAI(PAI(Designer、DLC、EAS)按量付费开通)服务,三种服务的开通区域保持一致。
进入阿里云MaxCompute产品首页,单击立即购买。
更多MaxCompute服务开通信息,请参见开通MaxCompute和DataWorks。
说明如果您未开通过MaxCompute服务,通过该方式开通MaxCompute服务时,默认会为您开通DataWorks基础版服务(免费)和MaxCompute按量计费服务。
如果您已开通MaxCompute按量计费服务,请忽略本步骤。
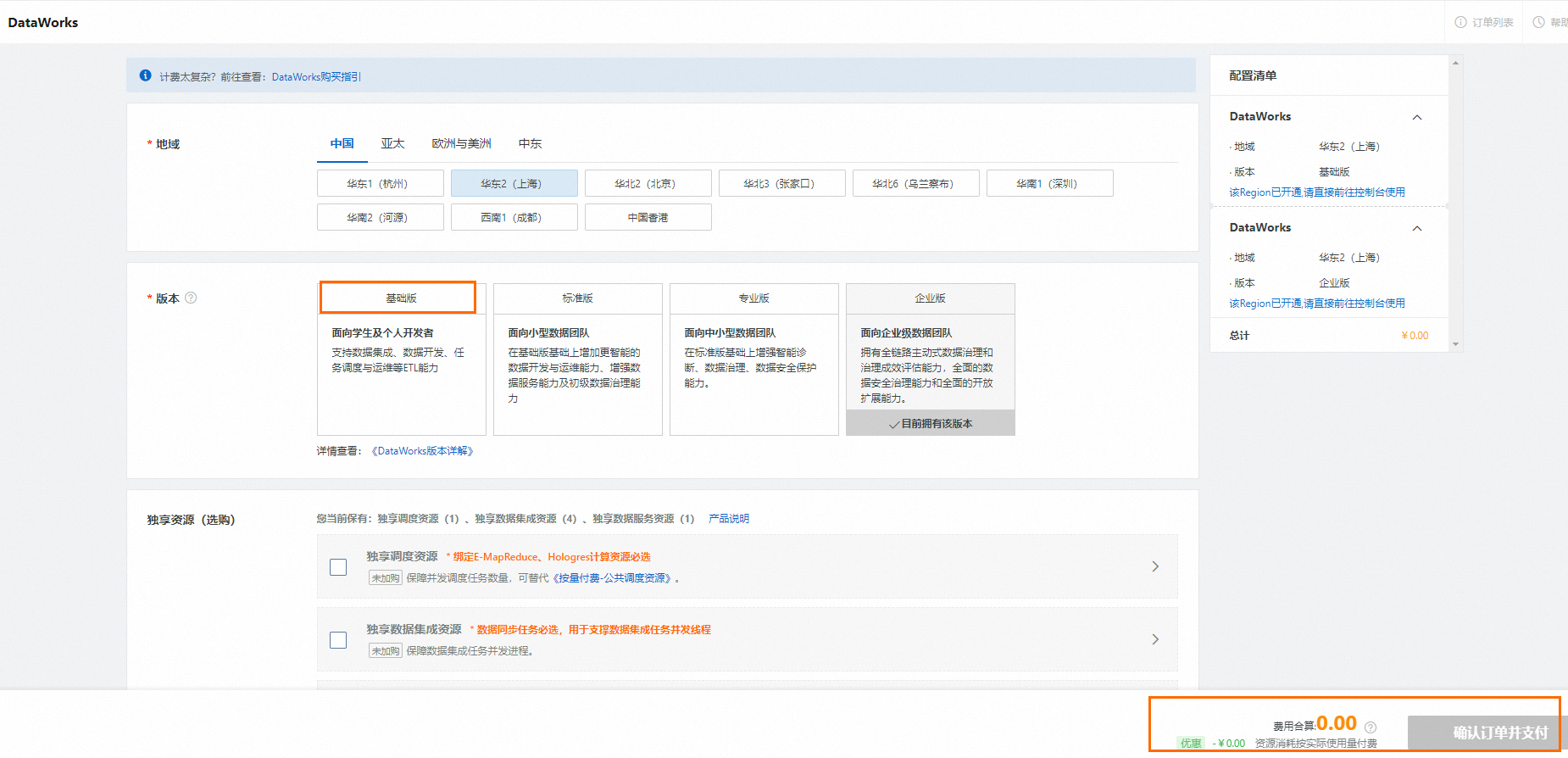
进入DataWorks购买页面,购买基础版服务。
更多DataWorks服务开通信息,请参见开通DataWorks。
 说明
说明如果已开通DataWorks基础版服务,请忽略本步骤。
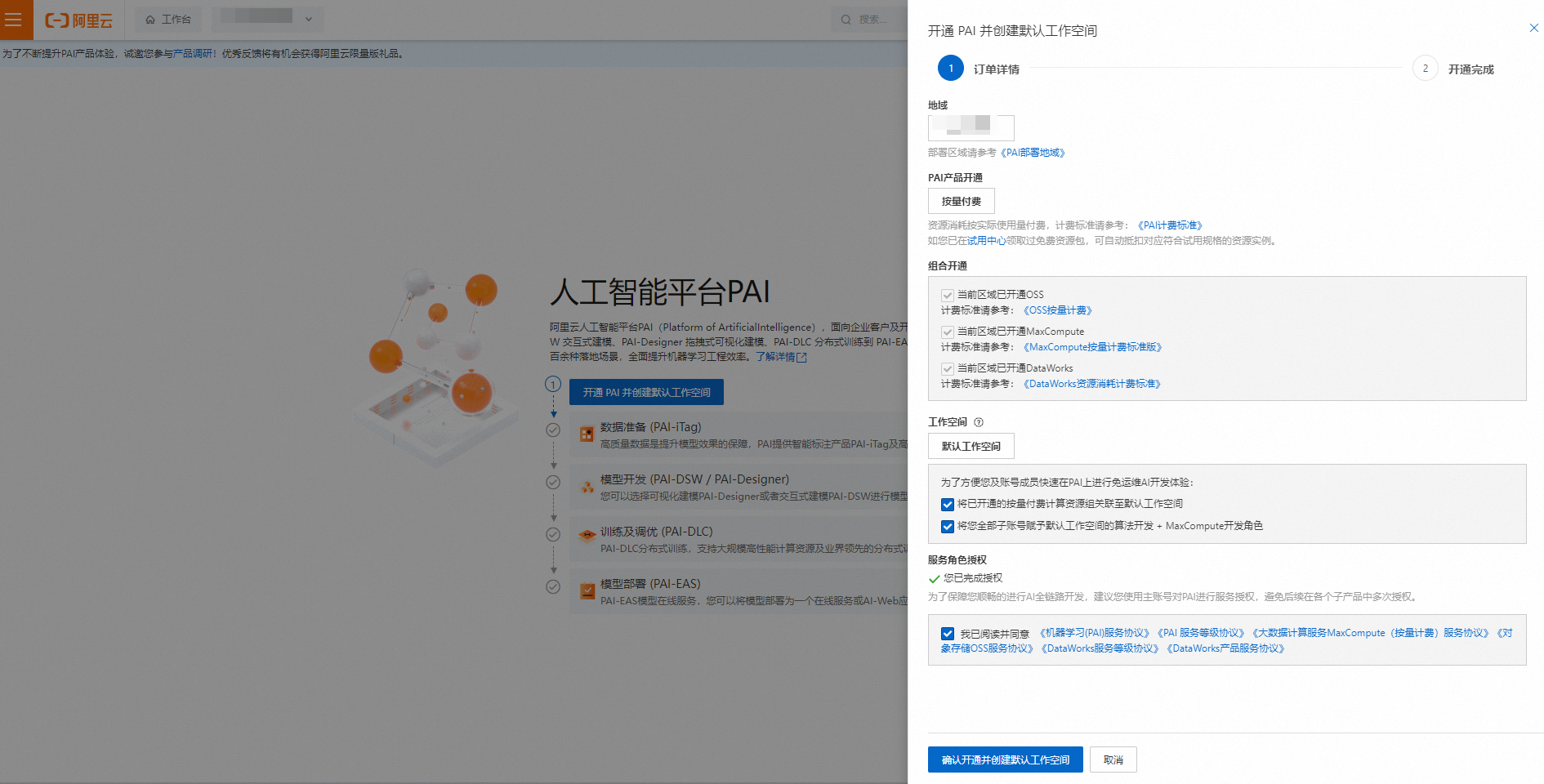
进入人工智能平台 PAI购买页面,开通PAI并创建默认工作空间。
更多人工智能平台 PAI服务开通信息,请参见开通PAI并创建默认工作空间。
 说明
说明如果您已开通PAI并创建了工作空间,请忽略本步骤。
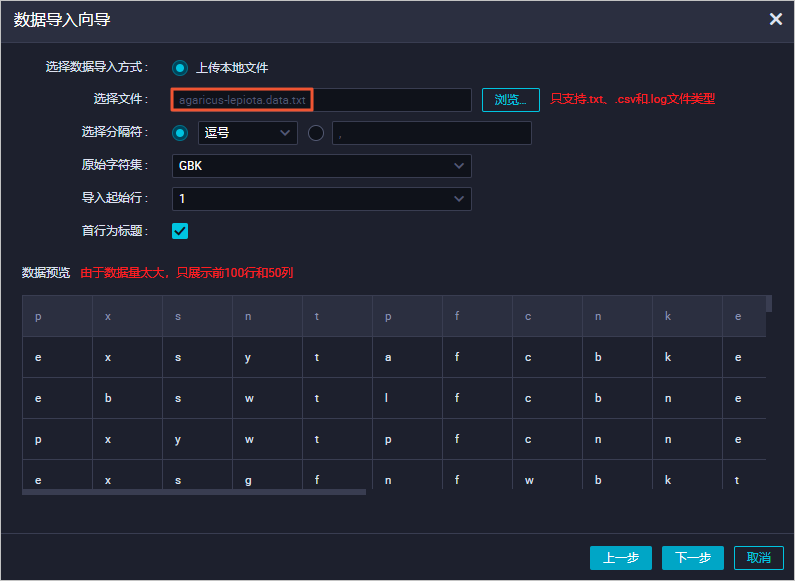
下载Mushroom Data Set数据集文件agaricus-lepiota.data,并保存为TXT、CSV或LOG文件类型。例如agaricus-lepiota.data.txt。
登录DataWorks控制台,创建或配置DataWorks工作空间。
如果已有DataWorks工作空间,请为目标工作空间配置MaxCompute计算引擎,并开启调度PAI算法任务开关。操作步骤如下:
单击左侧导航栏的工作空间,进入工作空间列表页面。
在工作空间列表页面,单击目标工作空间操作列的管理。
单击左侧导航栏通用配置,在基本属性区域开启调度PAI算法任务。
单击左侧导航栏数据源,进入数据源页面,创建MaxCompute数据源。数据源创建方法请参见绑定MaxCompute计算资源。
如果没有DataWorks工作空间,请创建DataWorks工作空间。配置计算引擎服务为MaxCompute,并开启调度PAI算法任务开关。更多创建DataWorks工作空间信息,请参见创建工作空间。
通过DataWorks创建表mushroom_classification并导入准备好的数据集信息。
单击目标DataWorks工作空间操作列的快速进入 > Data Studio,创建表mushroom_classification。
更多创建表操作信息,请参见创建并使用MaxCompute表。
创建表的DDL语句示例如下:
CREATE TABLE mushroom_classification ( label string comment 'poisonous=p,edible=e', cap_shape string comment 'bell=b,conical=c,convex=x,flat=f,knobbed=k,sunken=s', cap_surface string comment 'fibrous=f,grooves=g,scaly=y,smooth=s', cap_color string comment 'brown=n,buff=b,cinnamon=c,gray=g,green=r,pink=p,purple=u,red=e,white=w,yellow=y', bruises string comment 'bruises=t,no=f', odor string comment 'almond=a,anise=l,creosote=c,fishy=y,foul=f,musty=m,none=n,pungent=p,spicy=s', gill_attachment string comment 'attached=a,descending=d,free=f,notched=n', gill_spacing string comment 'close=c,crowded=w,distant=d', gill_size string comment 'broad=b,narrow=n', gill_color string comment 'black=k,brown=n,buff=b,chocolate=h,gray=g,green=r,orange=o,pink=p,purple=u,red=e,white=w,yellow=y', stalk_shape string comment 'enlarging=e,tapering=t', stalk_root string comment 'bulbous=b,club=c,cup=u,equal=e,rhizomorphs=z,rooted=r,missing=?', stalk_surface_above_ring string comment 'fibrous=f,scaly=y,silky=k,smooth=s', stalk_surface_below_ring string comment 'fibrous=f,scaly=y,silky=k,smooth=s', stalk_color_above_ring string comment 'brown=n,buff=b,cinnamon=c,gray=g,orange=o,pink=p,red=e,white=w,yellow=y', stalk_color_below_ring string comment 'brown=n,buff=b,cinnamon=c,gray=g,orange=o,pink=p,red=e,white=w,yellow=y', veil_type string comment 'partial=p,universal=u', veil_color string comment 'brown=n,orange=o,white=w,yellow=y', ring_number string comment 'none=n,one=o,two=t', ring_type string comment 'cobwebby=c,evanescent=e,flaring=f,large=l,none=n,pendant=p,sheathing=s,zone=z', spore_print_color string comment 'black=k,brown=n,buff=b,chocolate=h,green=r,orange=o,purple=u,white=w,yellow=y', population string comment 'abundant=a,clustered=c,numerous=n,scattered=s,several=v,solitary=y', habitat string comment 'grasses=g,leaves=l,meadows=m,paths=p,urban=u,waste=w,woods=d' );将数据集文件agaricus-lepiota.data.txt的信息导入表mushroom_classification中,字段匹配方式选择按位置匹配。
更多上传数据操作信息,请参见上传本地数据。
使用DataWorks的临时查询功能,新建MaxCompute ODPS SQL节点,执行SQL命令验证数据导入结果。
更多临时查询操作信息,请参见使用临时查询运行SQL语句(可选)。
命令示例如下:
SELECT * FROM mushroom_classification;返回结果如下:
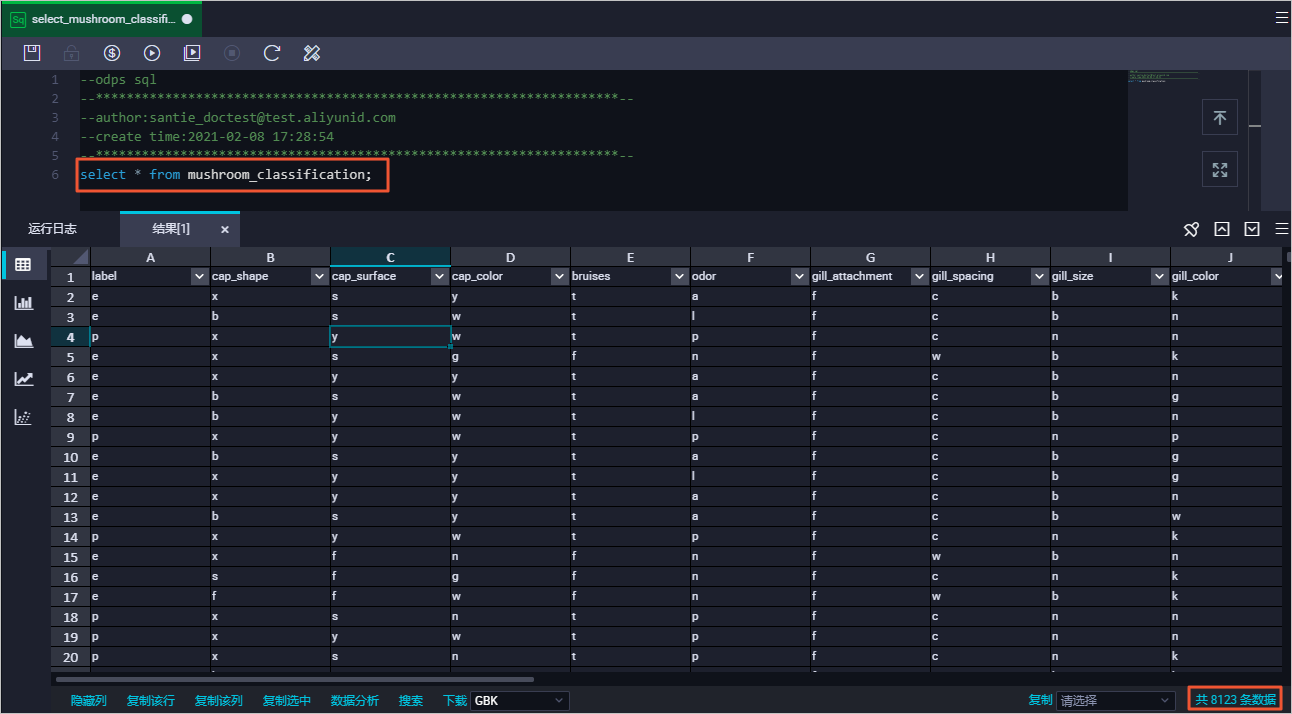
对导入表mushroom_classification中的数据通过one-hot编码方式进行处理。
由于逻辑回归二分类模型要求字段为数值类型,此处通过one-hot编码方式,将枚举类型的值转为数值类型。例如cap_shape对应的值为
b、c、x、f、k、s6个值,one-hot编码方式会将这6个枚举值转为6列,每一列对应一个枚举值,当cap_shape的值与对应列的枚举值相等时填1,否则填0。可选:创建业务流程。例如mc_test。
更多创建业务流程操作信息,请参见创建周期业务流程。
说明如果已有创建好的业务流程,可直接使用,请忽略本步骤。
新建MaxCompute ODPS Script节点,编写代码,对导入的数据按照one-hot编码方式进行处理并写入新表mushroom_classification_one_hot中。
更多创建ODPS Script节点信息,请参见开发ODPS Script任务。
命令示例如下:
CREATE temporary FUNCTION one_hot AS 'onehot.OneHotEncoding' USING -- CODE ('lang'='JAVA') package onehot; import com.aliyun.odps.udf.UDFException; import com.aliyun.odps.udf.UDTF; import com.aliyun.odps.udf.annotation.Resolve; import java.io.IOException; import java.util.ArrayList; import java.util.List; @Resolve({"string,string,string,string,string,string,string,string,string,string," + "string,string,string,string,string,string,string,string,string,string,string,string" + "->" + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,"+ "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint,bigint," + "bigint,bigint,bigint,bigint,bigint,bigint"}) public class OneHotEncoding extends UDTF { private static char[][] features = { { 'b','c','x','f','k','s'}, //cap-shape { 'f','g','y','s'}, //cap-surface { 'n','b','c','g','r','p','u','e','w','y'}, //cap-color { 't','f'}, //bruises { 'a','l','c','y','f','m','n','p','s'}, //odor { 'a','d','f','n'}, //gill-attachment { 'c','w','d'}, //gill-spacing { 'b','n'}, //gill-size { 'k','n','b','h','g','r','o','p','u','e','w','y'}, //gill-color { 'e','t'}, //stalk-shape { 'b','c','u','e','z','r','?'}, //stalk-root { 'f','y','k','s'}, //stalk-surface-above-ring { 'f','y','k','s'}, //stalk-surface-below-ring { 'n','b','c','g','o','p','e','w','y'}, //stalk-color-above-ring { 'n','b','c','g','o','p','e','w','y'}, //stalk-color-below-ring { 'p','u'}, //veil-type { 'n','o','w','y'}, //veil-color { 'n','o','t'}, //ring-number { 'c','e','f','l','n','p','s','z'}, //ring-type { 'k','n','b','h','r','o','u','w','y'}, //spore-print-color { 'a','c','n','s','v','y'}, //population { 'g','l','m','p','u','w','d'}, //habitat }; @Override public void process(Object[] objects) throws UDFException, IOException { List<Long> featuresEncoding = new ArrayList<>(126); for (int i = 0; i < objects.length; i++) { String value = (String)objects[i]; char[] feature = features[i]; for (char c : feature) { featuresEncoding.add(value.charAt(0) == c ? 1L : 0L); } } forward(featuresEncoding.toArray()); } } -- END CODE; CREATE TABLE mushroom_classification_one_hot AS SELECT t.*, label FROM mushroom_classification LATERAL VIEW one_hot(cap_shape,cap_surface,cap_color,bruises,odor,gill_attachment, gill_spacing, gill_size, gill_color, stalk_shape,stalk_root , stalk_surface_above_ring,stalk_surface_below_ring,stalk_color_above_ring, stalk_color_below_ring,veil_type,veil_color,ring_number,ring_type,spore_print_color, population,habitat) t AS f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13,f14,f15,f16,f17,f18,f19,f20, f21,f22,f23,f24,f25,f26,f27,f28,f29,f30,f31,f32,f33,f34,f35,f36,f37,f38,f39,f40, f41,f42,f43,f44,f45,f46,f47,f48,f49,f50,f51,f52,f53,f54,f55,f56,f57,f58,f59,f60, f61,f62,f63,f64,f65,f66,f67,f68,f69,f70,f71,f72,f73,f74,f75,f76,f77,f78,f79,f80, f81,f82,f83,f84,f85,f86,f87,f88,f89,f90,f91,f92,f93,f94,f95,f96,f97,f98,f99,f100, f101,f102,f103,f104,f105,f106,f107,f108,f109,f110,f111,f112,f113,f114,f115,f116, f117,f118,f119,f120,f121,f122,f123,f124,f125,f126;使用DataWorks的临时查询功能,新建MaxCompute ODPS SQL节点,执行SQL命令验证one-hot处理结果。
命令示例如下:
SELECT * FROM mushroom_classification_one_hot;返回结果如下:
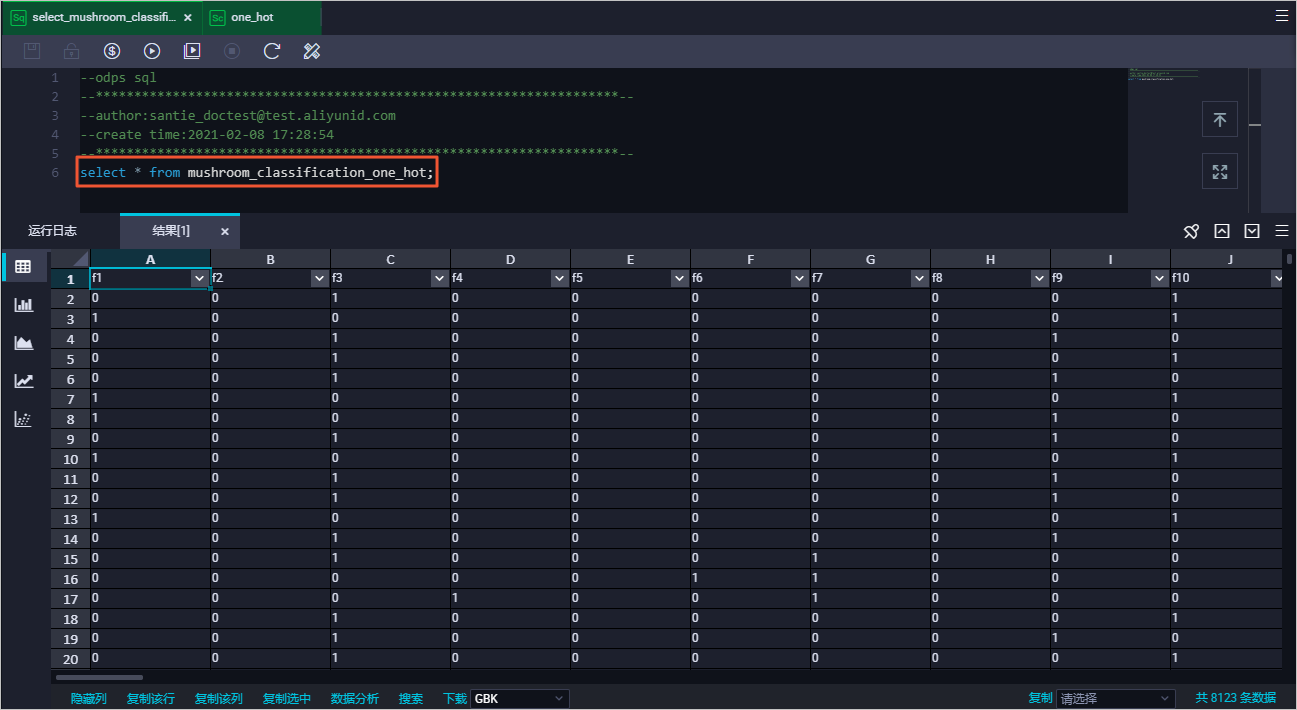
使用DataWorks的临时查询功能,新建MaxCompute ODPS SQL节点,基于表mushroom_classification_one_hot中的数据创建训练数据集和测试数据集。
命令示例如下:
-- 训练数据集。1/4的数据用于模型训练。 CREATE TABLE mushroom_training AS SELECT * FROM mushroom_classification_one_hot WHERE sample(4,1); -- 测试数据集。其余3/4的数据用于预测和评估。 CREATE TABLE mushroom_predict AS SELECT * FROM mushroom_classification_one_hot EXCEPT ALL SELECT * FROM mushroom_training;
创建机器学习模型并做预测。
使用DataWorks的临时查询功能,新建MaxCompute ODPS SQL节点,基于训练数据集创建逻辑回归二分类模型lr_test_model。
命令示例如下:
CREATE model lr_test_model WITH properties('model_type'='logisticregression_binary', 'goodValue'='p','maxIter'='1000') AS SELECT * FROM mushroom_training;说明properties中还可以指定更多参数,参数和人工智能平台 PAI平台保持一致,请参见线性支持向量机。SQL引擎会把
as后的查询语句提取出来单独运行,结果存放在一个临时表中,可以在作业的Logview的Summary信息中查看。临时表的生命周期为1天,超时会自动回收。如果后续需要删除模型,可以执行
drop offlinemodel lr_test_model命令。
使用DataWorks的临时查询功能,新建MaxCompute ODPS SQL节点,基于模型lr_test_model,通过内置函数
ml_predict对测试数据集中的数据进行预测。命令示例如下:
CREATE TABLE mushroom_predict_result AS SELECT * FROM ml_predict( lr_test_model, (SELECT * FROM mushroom_predict) );说明SQL引擎会把
ml_predict函数下的子查询结果保存到临时表。临时表的生命周期为1天,超时会自动回收。ml_predict的结果可以直接放在SQL查询from子句中,也可以通过insert或create table as语句存到另一个表中。更多ml_predict信息,请参见支持的预测模型函数。
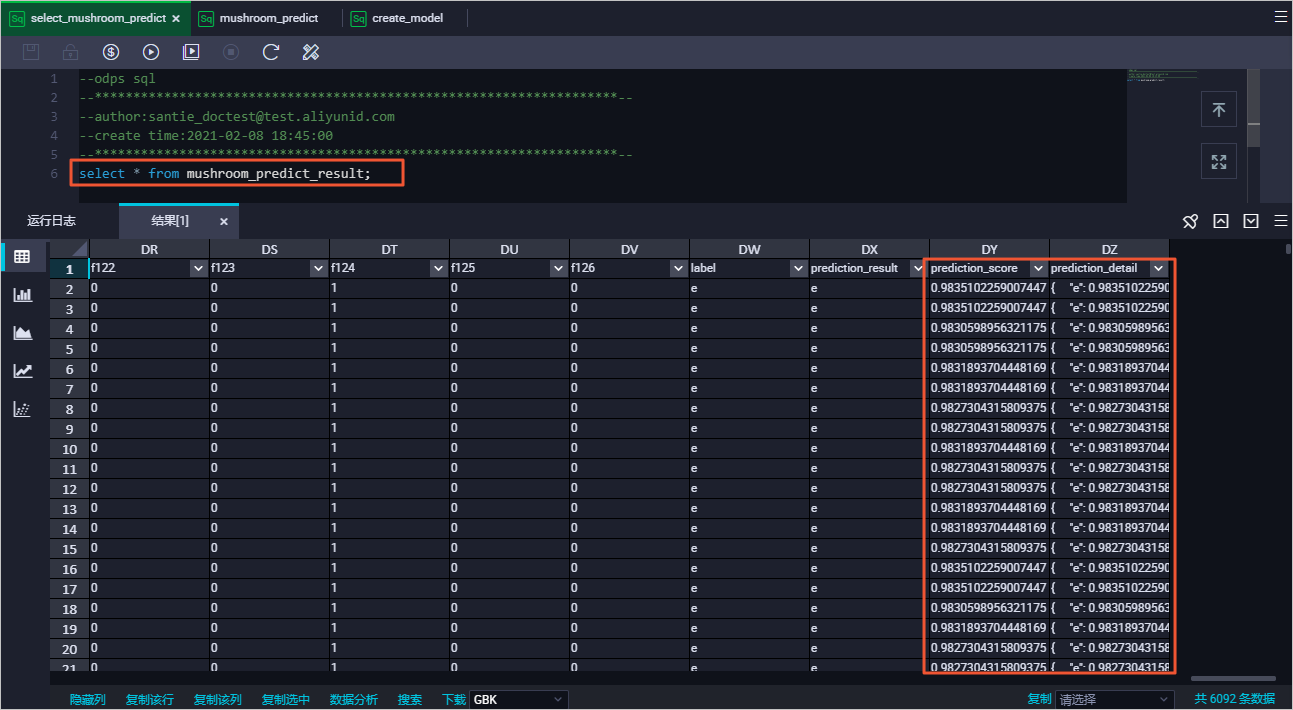
使用DataWorks的临时查询功能,新建MaxCompute ODPS SQL节点,执行SQL命令查看表mushroom_predict_result中的预测结果。
命令示例如下:
SELECT * FROM mushroom_predict_result;返回结果如下:

通过内建函数
ml_evaluate评估模型的预测准确度。更多
ml_evaluate信息,请参见支持的评估模型函数。