
本文介绍如何在阿里云MaxCompute中使用MaxFrame AI Function,结合典型案例快速上手大模型离线推理应用。
功能概述
MaxFrame AI Function是阿里云MaxCompute平台针对大模型离线推理场景推出的端到端解决方案,旨在无缝集成数据处理与AI能力,降低企业级大模型应用门槛。
设计理念:“数据即模型输入,结果即数据输出”。允许用户基于MaxFrame Python开发框架与Pandas风格API,直接在MaxCompute生态中完成从数据准备、数据处理、模型推理到结果存储的完整流程。
适用场景:适用于处理海量结构化数据(如日志分析、用户行为日志)、非结构化数据(如文本翻译、文档摘要)以及数据 Embedding 等场景,支持单次任务处理 PB 级数据规模,且通过分布式计算架构实现低延迟与线性扩展能力。可应用于从文本数据中提取结构化信息、整理总结内容、生成摘要、翻译语言,以及文本质量评估、情感分类等多项任务,极大简化大模型数据处理流程并提升处理结果的质量。
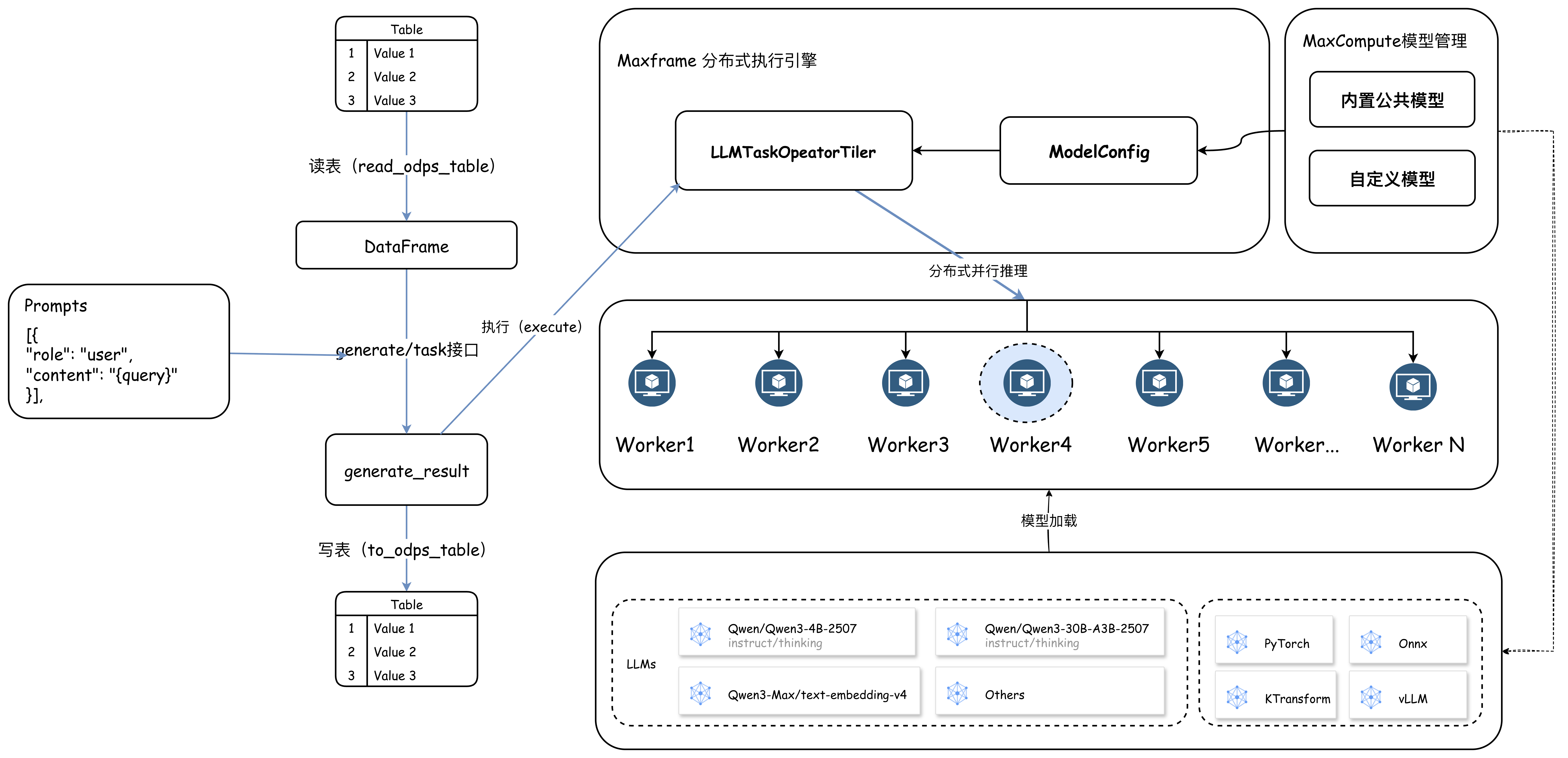
整体架构
MaxFrame AI Function提供了灵活、通用的
generate及简洁的、场景化的task(如文本翻译、结构化提取、Embedding 等)接口,允许用户选择模型种类,输入参数为MaxCompute表和Prompts。在接口执行中,MaxFrame会先切分表数据,用户可根据数据规模设置合适的并发度并启动Worker组执行计算任务。每个Worker以用户传入的Prompts参数为模板,基于输入的数据行渲染并构建模型,并将推理结果和成功状态写入MaxCompute。
整体架构和流程如图所示:
核心优势:
易用性:熟悉的 Python API,开箱即用的模型库,零部署成本。
扩展性:依托 MaxCompute CU、GU、Token Quota 计算资源,支持大规模并行处理,提升整体 token 吞吐率。
Data + AI 一体化:在统一平台内完成数据读取、数据处理、AI 推理与结果存储,减少数据迁移成本,提升开发效率。
场景覆盖:覆盖翻译、结构化抽取及向量化等10+个高频场景。
适用范围
支持地域:
华东1(杭州)、华东2(上海)、华北2(北京)、华北6(乌兰察布)、华南1(深圳)、西南1(成都)、中国香港、华东 1 金融云、华东 2 金融云。
支持Python3.11版本。
支持SDK版本:需确保MaxFrame SDK版本为2.7.1 或以上版本。可以通过以下方式查看版本:
// Windows系统 pip list | findstr maxframe // Linux系统 pip list | grep maxframe若版本过低,直接执行安装指令
pip install --upgrade maxframe;安装最新版本。安装MaxFrame最新客户端。
模型支持体系
目前,MaxFrame以开箱即用的方式支持Qwen 3、Deepseek-R1-Distill-Qwen、Qwen3-embedding等系列内置大模型,同时支持调用百炼商业化大模型,如qwen3.7-max、qwen3.6-plus、qwen3.6-flash、deepseek-v4-pro、deepseek-v4-flash、qwen3-vl-embedding、text-embedding-v4等多模态及文本类商业化旗舰大模型。模型均离线托管在MaxCompute平台内部。无需考虑模型下载、分发以及API调用的并发上限问题,仅需通过 API 调用即可使用,充分利用MaxCompute海量的计算资源,以较高的总体Token吞吐率和并发完成大模型离线推理任务。
支持模型(持续更新)
模型类型 | 模型名称 | 适用Quota |
百炼商业化旗舰大模型 |
|
|
Qwen 3系列开源模型 |
|
|
Qwen Embedding开源模型 |
|
|
Deepseek-R1-Distill-Qwen系列开源模型 |
|
|
Deepseek-R1-0528-Qwen3开源模型 |
|
|
Quota 资源类型说明
MaxFrame 支持三种资源类型,可根据模型规模和业务需求灵活选择。
CU Quota 资源
CU(1CU = 1CPU + 4GB内存)为通用CPU计算资源,适用于小尺寸模型和小规模数据量的推理任务。
配置方式:
# 使用CU Quota计算资源
options.session.quota_name = "mf_cpu_quota"GU Quota 资源
GU为GPU计算资源,针对大模型推理优化,支持更多尺寸模型规模,适用于 8B 及以上模型的推理任务。
配置方式:
# 使用GU Quota计算资源
options.session.gu_quota_name = "mf_gpu_quota"模型计算 Quota 资源(Token 计费)
支持直接调用百炼商业化大模型,按照 Token Quota 资源使用计费,支持如qwen3-max、text-embedding-v4等大尺寸模型推理任务。该方式按实际 Token 消耗计费,无需预先配置 CU/GU 资源、无需管理底层计算资源,使用更加灵活便捷且成本可控。
接口说明
MaxFrame AI Function 通过generate及Task双接口平衡灵活性与易用性:
通用接口:generate
通用接口:generate
关键参数说明
参数名称 | 是否必填 | 说明 |
model_name | 必填 | 模型名称。 |
df | 必填 | 封装在DataFrame中需要分析的文本或数据。 |
prompt_template | 必填 | 消息列表,格式与OpenAI文本Chat Format Messages兼容,在Content中可以使用 |
特定场景接口:Task
特定场景接口:Task
预设标准化任务接口,简化常见场景的开发流程。当前支持的task接口有:translate、extract、embedding。
关键参数说明
参数名称
是否必填
说明
model_name
必填
模型名称。
df
必填
封装在DataFrame中需要分析的文本或数据。
task接口
必填
translate:文本翻译extract:结构化提取embed:向量化
使用示例
from maxframe.learn.contrib.llm.models.managed import ManagedTextLLM llm = ManagedTextLLM(name="<model_name>") # 文本翻译 translated_df = llm.translate( df["english_column"], source_language="english", target_language="Chinese", examples=[("Hello", "你好"), ("Goodbye", "再见")], ) translated_df.execute()
典型应用场景
GU Quota 资源场景
GU Quota 资源场景
语言翻译
场景描述:某跨国企业需将 10 万份英文合同翻译成中文,并标注关键条款。
import os
import maxframe.dataframe as md
from maxframe import new_session
from maxframe.config import options
from maxframe.udf import with_running_options
from odps import ODPS
options.dag.settings = {
"engine_order": ["DPE", "MCSQL"]
}
o = ODPS(
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'),
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
project='your-default-project',
endpoint='your-end-point',
)
# 初始化MaxFrame会话
session = new_session(o)
# 打印作业Logview地址
print(session.get_logview_address())
# 1. 使用GU Quota计算资源
options.session.gu_quota_name = "mf_gu_quota"
# 2. 使用Qwen3 4B模型
from maxframe.learn.contrib.llm.models.managed import ManagedTextLLM
llm = ManagedTextLLM(name="Qwen3-1.7B")
# 3. 数据准备,如果已有数据可忽略构建测试数据步骤
# o.execute_sql("""
# CREATE TABLE IF NOT EXISTS raw_contracts (
# en STRING
# );
# """)
#
# o.execute_sql("""
# INSERT INTO raw_contracts VALUES
# ('This agreement is governed by the laws of the State of California.'),
# ('The tenant shall pay rent on the first day of each month.'),
# ('Either party may terminate this contract with 30 days written notice.'),
# ('All intellectual property rights shall remain with the original owner.'),
# ('The warranty period for this product is twelve months from the date of purchase.');
# """)
df = md.read_odps_table("raw_contracts")
# 4.定义Prompts模板
messages = [
{
"role": "system",
"content": "你是一个文档翻译专家,能够将用户给定的英文流畅的翻译成中文",
},
{
"role": "user",
"content": "请将以下英文翻译成中文,直接输出翻译后的文本,不要输出任何其他内容。\n\n 例如:\n输入:Hi\n输出:你好。\n\n 以下是你要处理的文本:\n\n{en}",
},
]
# 5.直接使用 `generate` 接口,定义提示词,引用对应的数据列。
result_df = llm.generate(
df,
prompt_template=messages,
params={
"temperature": 0.7,
"top_p": 0.8,
},
).execute()
# 6.结果数据写入MaxCompute表
result_df.to_odps_table("raw_contracts_result")关键词提取
场景描述:该场景展示MaxFrame AI Function在非结构化数据处理上的能力。非结构化数据中占据较高比例的文本和图像,在大数据分析中带来了巨大的处理挑战。以下是利用AI Function简化这一过程的示例。
如下代码演示如何使用AI Function从简历中提取候选人的工作经验,示例使用数据为随机生成的简历文本。详细使用实践及 Demo 可参考:AI Function On GU 开发实践。
import maxframe.dataframe as md
from maxframe import new_session
from maxframe.config import options
from maxframe.udf import with_running_options
from odps import ODPS
options.dag.settings = {
"engine_order": ["DPE", "MCSQL"]
}
o = ODPS(
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_ID'),
os.getenv('ALIBABA_CLOUD_ACCESS_KEY_SECRET'),
project='your-default-project',
endpoint='your-end-point',
)
# 初始化MaxFrame会话
session = new_session(o)
# 打印作业Logview地址
print(session.get_logview_address())
# 1. 使用GU Quota计算资源
options.session.gu_quota_name = "mf_gu_quota"
# 2. 使用Qwen3 4B模型
from maxframe.learn.contrib.llm.models.managed import ManagedTextLLM
llm = ManagedTextLLM(name="Qwen3-4B-Instruct-2507-FP8")
df = md.read_odps_table("traditional_chinese_medicine", index_col="index")
# 指定四个并发
parallel_partitions = 4
df = df.mf.rebalance(num_partitions=parallel_partitions)
# 3. 使用 extract 预设任务接口
result_df = llm.extract(
df["text"],
description="请从以下就诊记录中按顺序抽取结构化数据,最终按照 schema 以严格的 JSON 格式返回",
schema=MedicalRecord,
examples=[(example_input, example_output)],
)
result_df.execute()
Inference Quota 资源场景(Token计费)
Inference Quota 资源场景
文本向量化:text-embedding-v4
场景描述:使用百炼商业化模型text-embedding-v4进行向量化任务,按 Token 消耗计费,无需管理底层计算资源。适用于复杂文本分析任务、需要大尺寸模型或百炼商业化大模型的高质量推理任务。
Qwen3.6-Plus 百炼多模态模型图片理解
场景描述:适用于需要大尺寸模型或百炼商业化大模型的高质量推理以及复杂文本分析、多模态数据处理任务。按需使用,成本可控。
性能优化
并行推理
MaxFrame采用并行计算机制实现大规模数据离线推理:
数据切分:通过
rebalance接口将输入数据表按指定分区数(num_partitions)均匀分配至多个Worker节点。模型并行加载:每个Worker独立加载模型并进行预热,避免因模型加载导致的冷启动延迟。
结果聚合:输出结果按分区写入MaxCompute表,支持后续的数据分析。
常用性能调优建议
异构计算资源切换
针对大尺寸模型(如 8B 及以上模型),CPU 推理效率较低,可切换至 GU Quota 计算资源或 Token Quota 计算资源推理。
数据分区并行处理
针对大规模数据推理作业,可根据数据情况通过
rebalance接口提前切分并发,从而并行处理数据。