
本文为您介绍错误码ODPS-0130071:Semantic analysis exception的报错场景,并提供对应的解决方案。
错误1:the number of input partition columns (n) doesn't equal to table's partition columns (m)
错误信息示例
FAILED: ODPS-0130071:[m,n] Semantic analysis exception - the number of input partition columns (n) doesn't equal to table's partition columns (m)
错误描述
数据插入表是一个分区表,其中有m个分区字段,但是插入数据SQL里只有n个分区列,导致数据写入找不到分区报错
解决方案
建议修改插入数据SQL,对齐分区字段。
示例
--创建表
CREATE TABLE if NOT EXISTS mf_sale_detail
(
shop_name STRING,
customer_id STRING,
total_price DOUBLE
)
partitioned BY
(
sale_date string,
region string
);
--错误:目标表有2级分区,partition子句只指定了部分或完全没指定
INSERT overwrite TABLE mf_sale_detail
VALUES ('s1','c1',100.1),('s2','c2',100.2),('s3','c3',100.3);
FAILED: ODPS-0130071:[1,24] Semantic analysis exception - the number of input partition columns (0) doesn't equal to table's partition columns (2)
--正确:partition子句指定完整分区
INSERT overwrite TABLE mf_sale_detail PARTITION(sale_date = '2013', region = 'china')
VALUES ('s1', 'c1', 100.1), ('s2', 'c2', 100.2), ('s3', 'c3', 100.3);
OK
--正确:使用动态分区
INSERT overwrite TABLE mf_sale_detail PARTITION(sale_date = '2013', region)
VALUES ('s1', 'c1', 100.1, 'china'), ('s2', 'c2', 100.2, 'china'), ('s3', 'c3', 100.3, 'china');
OK错误2:expect equality expression (i.e., only use '=' and 'AND') for join condition without mapjoin hint
错误信息示例
ODPS-0130071:[m,n] Semantic analysis exception - expect equality expression (i.e., only use '=' and 'AND') for join condition without mapjoin hint
错误描述
MaxCompute SQL模式使用Sort-Merge JOIN作为JOIN的物理算法,需要JOIN condition包括等值表达式;实际Query执行会按照等值表达式中左右表涉及的列做Shuffle。
解决方案
保证Join condition包含等值表达式。
增加mapjoin hint。
说明ON条件只包含非等值表达式,可能会导致JOIN膨胀出特别多的数据,执行缓慢。
示例
--错误:join condition只包含非等值表达式
SELECT t1. *
FROM src t1
JOIN src t2
ON t1.value > t2.value;
FAILED: ODPS-0130071:[4,4] Semantic analysis exception - expect equality expression (i.e., only use '=' and 'AND') for join condition without mapjoin hint
--正确:join condition包含有左右两表列的等值表达式(t1.key = t2.key)
SELECT t1. *
FROM src t1
JOIN src t2
ON t1.key = t2.key AND t1.value > t2.value;
--正确:增加mapjoin hint
SELECT /*+mapjoin(t1)*/ t1. *
FROM src t1
JOIN src t2
ON t1.value > t2.value;错误3:insert into HASH CLUSTERED table/partition xxx is not current supported
错误信息
ODPS-0130071:[m,n] Semantic analysis exception - insert into HASH CLUSTERED table/partition xxx is not current supported
错误码描述
目前不支持用INSERT INTO语句往聚簇表里写数据。
解决方案
建议修改成普通表
修改语句为INSERT OVERWRITE。
示例
--聚簇表建表
CREATE TABLE sale_detail_hashcluster
(
shop_name STRING,
total_price decimal,
customer_id BIGINT
)
clustered BY(customer_id)
sorted BY(customer_id)
INTO 1024 buckets;
--错误:insert into cluster表
INSERT INTO sale_detail_hashcluster
VALUES ('a', 123, 'id123');
FAILED: ODPS-0130071:[1,13] Semantic analysis exception - insert into HASH CLUSTERED table/partition meta.sale_detail_hashcluster is not current supported
--正确:insert into普通表
CREATE TABLE sale_detail
(
shop_name STRING,
total_price decimal,
customer_id BIGINT
);
INSERT INTO sale_detail
VALUES ('a', 123, 'id123');
--正确:修改为insert overwrite cluster表
INSERT overwrite TABLE sale_detail_hashcluster
VALUES ('a', 123, 'id123');错误4:should appear in GROUP BY key
错误信息示例
ODPS-0130071:[m,n] Semantic analysis exception - column reference xx.yy should appear in GROUP BY key
问题描述
GROUP BY语句按照指定的key对输入表进行聚合,经过聚合之后:
对于聚合key对应的列,可以直接输出它们的值,也可以调用普通函数(非聚合函数)对它们进行进一步加工和计算。
对于非聚合key对应的列,必须调用聚合函数(例如sum/count/avg等)来计算聚合结果,而不能直接输出它们的值。
解决方案
对于非聚合key对应的列,必须要调用聚合函数(例如sum/count/avg/any_value等)来计算聚合结果。
Query示例
--错误,列c不是group by的key,没有使用聚合函数
SELECT a, sum(b), c
FROM VALUES (1L, 2L, 3L) AS t(a, b, c)
GROUP BY a;
--报错
FAILED: ODPS-0130071:[1,19] Semantic analysis exception - column reference t.c should appear in GROUP BY key
--正确,使用聚合函数any_value来计算列c的聚合值
SELECT a, sum(b), any_value(c)
FROM VALUES (1L, 2L, 3L) AS t(a, b, c)
GROUP BY a;错误5:Invalid partition value
错误信息示例
ODPS-0130071:[m,n] Semantic analysis exception - Invalid partition value: 'xxx'
问题描述
分区字段的取值非法。MaxCompute的分区字段取值规则如下。
分区值不能包含双字节字符(如中文),必须以字母开头,包含字母、数字和允许的字符,长度不超过128字节。
允许的字符包括空格、冒号(:)、下划线(_)、美元符号($)、井号(#)、英文句点(.)、感叹号(!)和at(@),其他字符的行为未定义,例如转义字符
\t、\n和/。
解决方案
修改分区字段的取值,修改为合法值。
Query示例
--创建table
CREATE TABLE mc_test
(
a bigint
)
partitioned BY
(
ds string
);
--错误,分区值'${today}'非法
ALTER TABLE mc_test ADD PARTITION(ds = '${today}');
--报错
FAILED: ODPS-0130071:[1,40] Semantic analysis exception - Invalid partition value: '${today}'
--正确,修改分区值为合法值'20221206'
ALTER TABLE mc_test ADD PARTITION(ds='20221206');错误6:only oss external table support msck repair syntax
错误信息示例
ODPS-0130071:[m,n] Semantic analysis exception - only oss external table support msck repair syntax
问题描述
只有OSS外部表才支持msck repair操作,参考文档补全OSS外部表分区数据语法。
方式一(推荐):自动解析OSS目录结构,识别分区,为OSS外部表添加分区信息。
通过这种方式,MaxCompute会根据您创建OSS外部表时指定的分区目录,自动补全OSS外部表的分区,而不用逐个按照分区列名和名称增加,这适用于一次性补全全部缺失的历史分区的场景,
msck repair TABLE <mc_oss_extable_name> ADD partitions [ WITH properties (key:VALUE, key: VALUE ...)];说明该方式不适用于处理增量数据的补充,尤其是在OSS目录包含大量分区(如超过1000个)的情况下。由于当新增分区远少于已有分区时,频繁使用
msck命令会导致对OSS目录大量的重复扫描和元数据更新请求,这将显著降低命令执行的效率。因此,对于需要更新增量分区的场景,建议您采用方式二。方式二:手动执行如下命令为OSS外部表添加分区信息。
当历史分区已经创建完成,需要频繁地周期性追加分区,建议采用该方式,在执行数据写入任务之前提前创建好分区。分区创建完成后,即使OSS上有新数据写入,也无需刷新对应分区,外部表即可读取OSS目录上的最新数据。
ALTER TABLE < mc_oss_extable_name > ADD PARTITION (< col_name >= < col_value >)[ ADD PARTITION (< col_name >= < col_value >)...][location URL];col_name和col_value的值需要与分区数据文件所在目录名称对齐。假设,分区数据文件所在的OSS目录结构如下图,col_name对应
direction,col_value对应N、NE、S、SW、W。一个add partition对应一个子目录,多个OSS子目录需要使用多个add partition。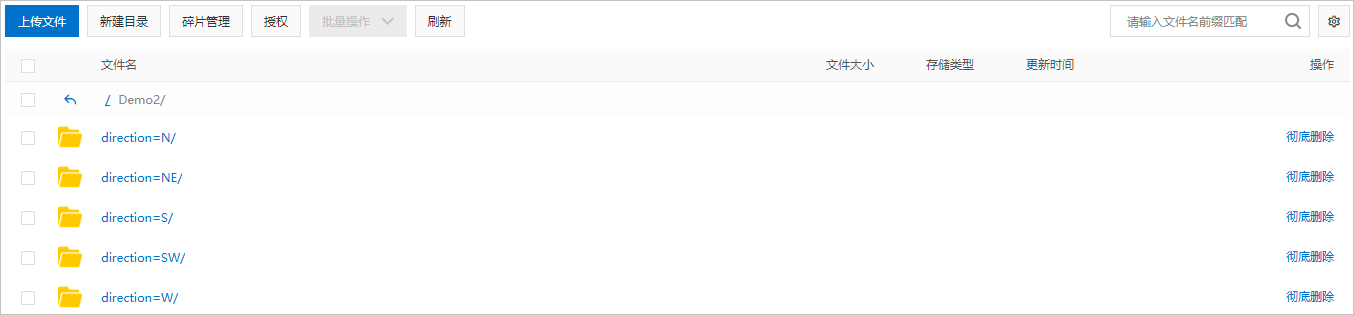
示例
在OSS上创建目录
demo8并分别在下面建立两个分区文件夹,分别放入对应的文件。分区文件夹:
$pt1=1/$pt2=2,文件名称:demo8-pt1.txt。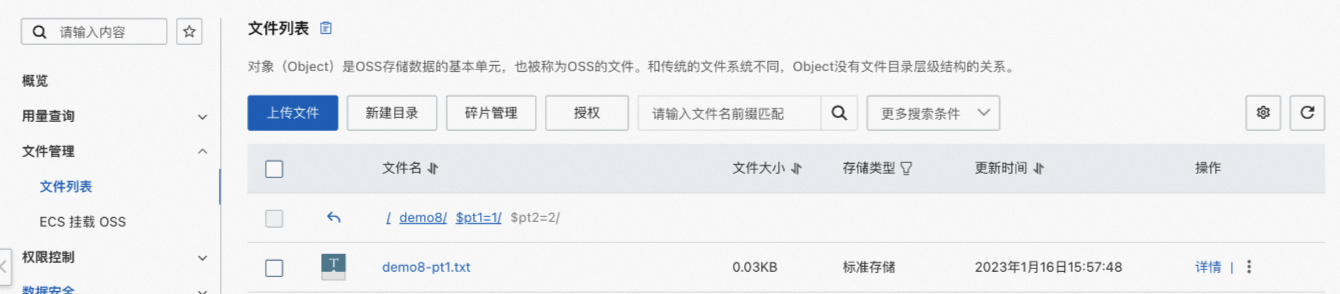
分区文件夹:
$pt1=3/$pt2=4,文件名称:demo8-pt2.txt。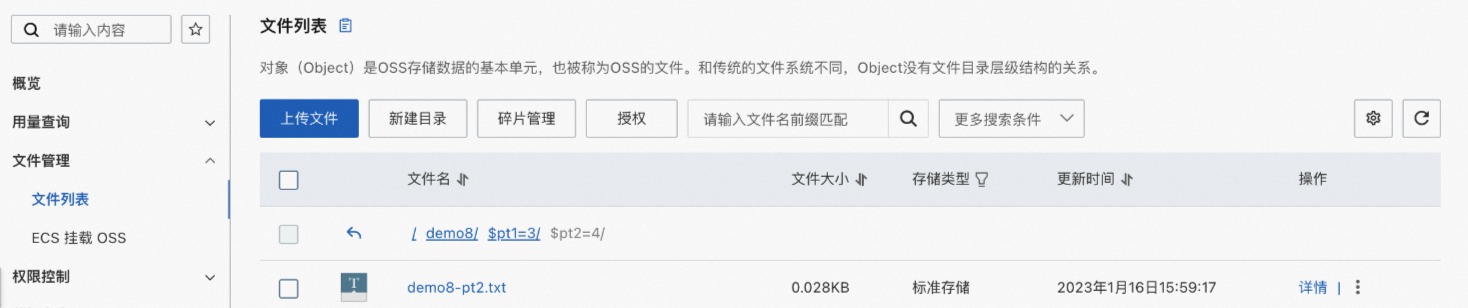
创建外部表并指定
pt字段。--创建外部表 create external table mf_oss_spe_pt (id int, name string) partitioned by (pt1 string, pt2 string) stored as TEXTFILE location "oss://oss-cn-beijing-internal.aliyuncs.com/mfoss*******/demo8/"; --指定分区字段 MSCK REPAIR TABLE mf_oss_spe_pt ADD PARTITIONS with PROPERTIES ('odps.msck.partition.column.mapping'='pt1:$pt1,pt2:$pt2'); --查询数据 select * from mf_oss_spe_pt where pt1=1 and pt2=2; --返回 +------------+------------+------------+------------+ | id | name | pt1 | pt2 | +------------+------------+------------+------------+ | 1 | kyle | 1 | 2 | | 2 | nicole | 1 | 2 | +------------+------------+------------+------------+ --查询数据 select * from mf_oss_spe_pt where pt1=3 and pt2=4; +------------+------------+------------+------------+ | id | name | pt1 | pt2 | +------------+------------+------------+------------+ | 3 | john | 3 | 4 | | 4 | lily | 3 | 4 | +------------+------------+------------+------------+当OSS外表中的分区列名与OSS的目录结构不一致时,需要指定目录。
--MaxCompute分区与OSS的目录对应如下: --pt1=8-->8 --pt2=8-->$pt2=8 --添加分区 alter table mf_oss_spe_pt add partition (pt1=8,pt2=8) location 'oss://oss-cn-beijing-internal.aliyuncs.com/mfosscostfee/demo8/8/$pt2=8/'; --需要关闭commit mode --插入数据 set odps.sql.unstructured.oss.commit.mode=false; insert into mf_oss_spe_pt partition (pt1=8,pt2=8) values (1,'tere'); --查询数据 set odps.sql.unstructured.oss.commit.mode=false; select * from mf_oss_spe_pt where pt1=8 and pt2=8; +------+------+-----+-----+ | id | name | pt1 | pt2 | +------+------+-----+-----+ | 1 | tere | 8 | 8 | +------+------+-----+-----+
解决方案
按照文档的描述,创建OSS外部表,才能执行MSCK REPAIR命令。
Query示例
--创建普通表
CREATE TABLE mc_test
(
a BIGINT
)
partitioned BY
(
ds string
);
--错误,普通表不能执行msck repair操作。
msck TABLE mc_test ADD partitions;
FAILED: ODPS-0130071:[1,12] Semantic analysis exception - only oss external table support msck repair syntax
错误7:column xx in source has incompatible type yy with destination column zz, which has type ttt
错误信息示例
ODPS-0130071:[m,n] Semantic analysis exception - column xx in source has incompatible type yy with destination column zz, which has type ttt
问题描述
向表中插入数据的时候,要求目标表的数据类型和插入数据的数据类型相匹配,或者是插入的数据可以隐式转换为目标表的数据类型,否则就会报错。
解决方案
修改Query,使得插入数据的类型和目标表的数据类型相匹配。
Query示例
--创建表
odps> CREATE TABLE mc_test
(
a datetime
);
--错误,数据类型不匹配
odps> INSERT overwrite TABLE mc_test
VALUES (1L);
FAILED: ODPS-0130071:[2,9] Semantic analysis exception - column __value_col0 in source has incompatible type BIGINT with destination column a, which has type DATETIME
--正确,插入正确类型的数据
odps> INSERT overwrite TABLE mc_test
VALUES (datetime '2022-12-06 14:23:45');错误8:function datediff cannot match any overloaded functions with (STRING, STRING, STRING), candidates are BIGINT DATEDIFF(DATE arg0, DATE arg1, STRING arg2); BIGINT DATEDIFF(DATETIME arg0, DATETIME arg1, STRING arg2); BIGINT DATEDIFF(TIMESTAMP arg0, TIMESTAMP arg1, STRING arg2); INT DATEDIFF(DATE arg0, DATE arg1); INT DATEDIFF(STRING arg0, STRING arg1); INT DATEDIFF(TIMESTAMP arg0, TIMESTAMP arg1)
错误信息示例
ODPS-0130071:[m,n] Semantic analysis exception - function datediff cannot match any overloaded functions with (STRING, STRING, STRING), candidates are BIGINT DATEDIFF(DATE arg0, DATE arg1, STRING arg2); BIGINT DATEDIFF(DATETIME arg0, DATETIME arg1, STRING arg2); BIGINT DATEDIFF(TIMESTAMP arg0, TIMESTAMP arg1, STRING arg2); INT DATEDIFF(DATE arg0, DATE arg1); INT DATEDIFF(STRING arg0, STRING arg1); INT DATEDIFF(TIMESTAMP arg0, TIMESTAMP arg1)
错误描述
使用的函数DATEDIFF入参类型不匹配,常见的类型不匹配问题,是由于开启数据类型2.0隐式转换关闭引起。
解决方案
您可以通过以下方式解决:
在SQL前添加
set odps.sql.type.system.odps2=false;并与SQL一同运行,关闭数据类型2.0打开隐式转换处理。修改输入参数数据类型。
错误9:The role not exists: acs:ram::xxxxxx:role/aliyunodpsdefaultrole
错误信息示例
ODPS-0130071:[1,1] Semantic analysis exception - external table checking failure, error message: java.lang.RuntimeException: {"RequestId":"A7BFAD2F-8982-547A-AB5E-93DAF5061FBD","HostId":"sts.aliyuncs.com","Code":"EntityNotExist.Role","Message":"The role not exists: acs:ram::xxxxxx:role/aliyunodpsdefaultrole. ","Recommend":"https://next.api.aliyun.com/troubleshoot?q=EntityNotExist.Role&product=Sts"}
错误描述
在创建OSS外部表时,需要指定访问OSS的RAM Role,在此示例中指定了一个不存在的Role。导致系统在角色验证时失败,提示指定的角色不存在。
解决方案
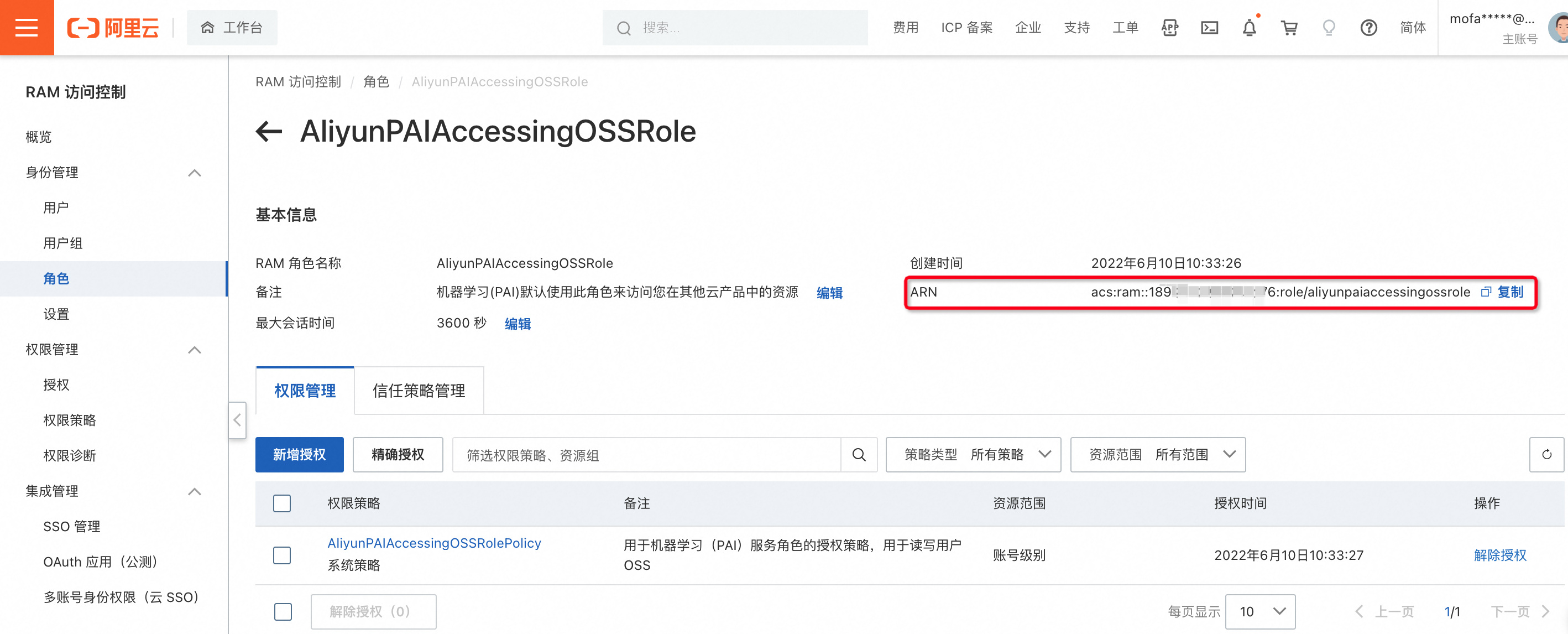
修改创建外表ARN(odps.properties.rolearn)参数的值,ARN值的具体组成格式为acs:ram::<UID>:role/<Role>。
其中:
UID:正常为16位数字。
Role:为RAM上用户自己定义的角色名称。
示例
'odps.properties.rolearn'='acs:ram::189xxxxxxx76:role/aliyunpaiaccessingossrole'
ARN具体获得方法请点击查看,进入页面点击角色名称进行查看,示例如下:
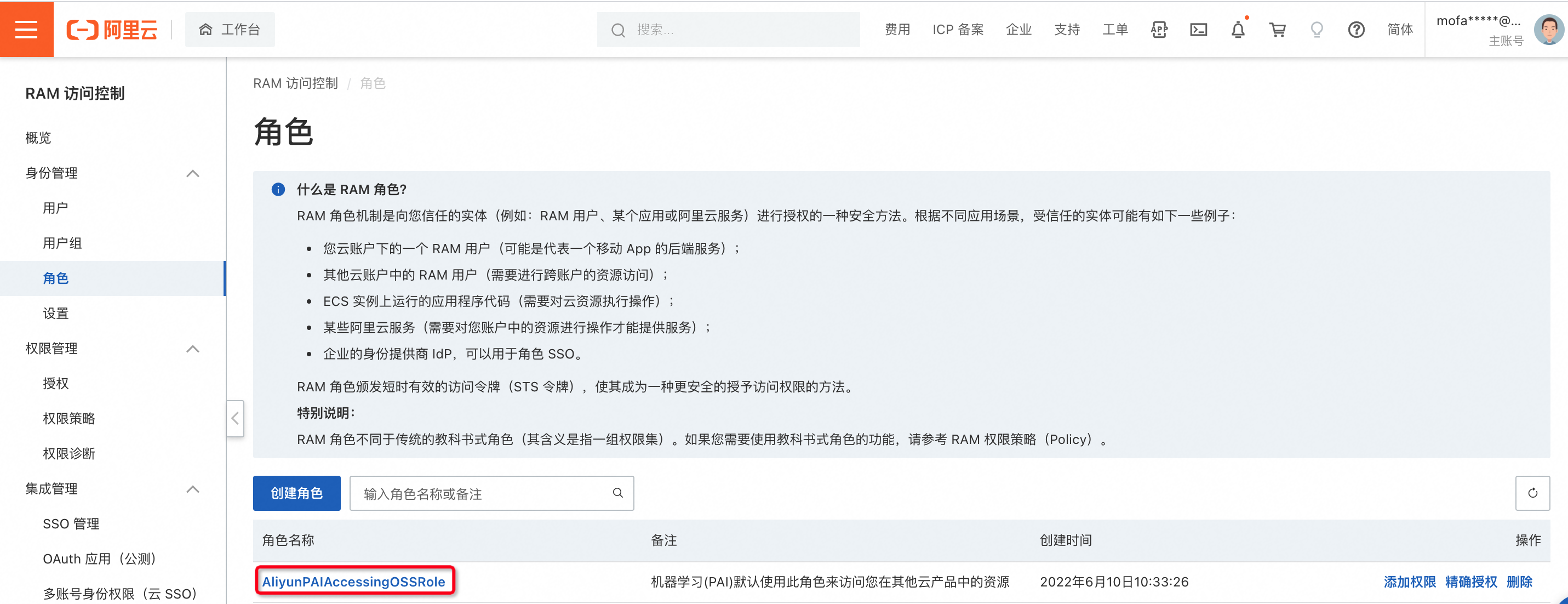
错误10:encounter runtime exception while evaluating function MAX_PT
错误信息示例
FAILED: ODPS-0130071:[33,26] Semantic analysis exception - encounter runtime exception while evaluating function MAX_PT, detailed message: null
错误描述
在SQL执行的过程中,max_pt对应的最大分区发生变化,已经不是最大的分区,触发引起数据不一致的检测报错。
解决方案
避免在新生成分区时执行带有max_pt的SQL语句。
配置任务出错自动重跑。
错误11:column xxx cannot be resolved
错误信息示例
ODPS-0130071:[73,12] Semantic analysis exception - column xxx cannot be resolved
错误描述
对应表中xxx列不存在。
解决方案
检查SQL脚本,更新xxx至正确的列名。
错误12:evaluate function in class XX for user defined function YY does not match annotation ZZ
错误信息示例
FAILED: ODPS-0130071:[1,8] Semantic analysis exception - evaluate function in class test.MyPlus for user defined function my_plus does not match annotation bigint->bigint
错误描述
用户写UDF(Java或者Python UDF)的时候,代码不符合UDF的规范,函数签名annotation和实际的代码不匹配。
解决方案
修改用户的UDF代码,使得函数签名annotation和实际的代码相匹配。
Query示例
--下面是一个不规范的Python UDF示例,实际代码有两个输入参数,但是annotation中只有一个输入参数
from odps.udf import annotate
@annotate("bigint->bigint")
class MyPlus(object):
def evaluate(self, arg0, arg1):
if None in (arg0, arg1):
return None
return arg0 + arg1
--下面是另外一个不规范的Python UDF示例,evaluate函数没有self参数
from odps.udf import annotate
@annotate("bigint,bigint->bigint")
class MyPlus(object):
def evaluate(arg0, arg1):
if None in (arg0, arg1):
return None
return arg0 + arg1
--下面是正确的Python UDF
from odps.udf import annotate
@annotate("bigint,bigint->bigint")
class MyPlus(object):
def evaluate(self, arg0, arg1):
if None in (arg0, arg1):
return None
return arg0 + arg1错误13:Vpc white list: , Vpc id: vpc-xxxx is not allowed to access
错误信息示例
FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: com.aliyun.odps.lot.cbo.plan.splitting.impl.vpc.AliHyperVpcRuntimeException: Vpc white list: , Vpc id: vpc-xxxx is not allowed to access.Contact project owner to set allowed accessed vpc id list.=
错误描述
用户访问外部表时,VPC配置不正确,VPC没有打通MaxCompute的数据访问。
解决方案
在VPC中配置MaxCompute可以访问的白名单。具体请参见访问VPC方案(专线直连)。
错误14:Semantic analysis exception - physical plan generation failed
错误信息示例
FAILED: ODPS-0130071:[0,0] Semantic analysis exception - physical plan generation failed: com.aliyun.odps.common.table.na.NativeException: kNotFound:The role_arn you provide not exists in HOLO auth service. Please check carefully.
错误描述
用户访问阿里云产品时,没有开通服务角色(SLR),不能通过云产品服务角色授权访问对方数据。
解决方案
单击访问控制开通SLR服务角色。