MaxCompute支持Schema,允许在Project之下对Table、Resource、Function进行更细粒度的管理。本文为您介绍Schema的概念、权限内容以及如何使用Schema。
背景信息
MaxCompute项目(Project)作为基本组织单元,是进行多用户隔离和访问控制的主要边界。Project中包含表(Table)、资源(Resource)、函数(Function)对象,这些对象原来直接放在Project下,需要Project充当类似于传统数据库的Database或Schema的概念,因此导致了概念不清晰(既是Database又是Schema),使用不方便,尤其是在有很多表或者对象的情况下。现在MaxCompute支持Schema,可以在Project之下对Table、Resource、Function进行归类,层级如下图所示。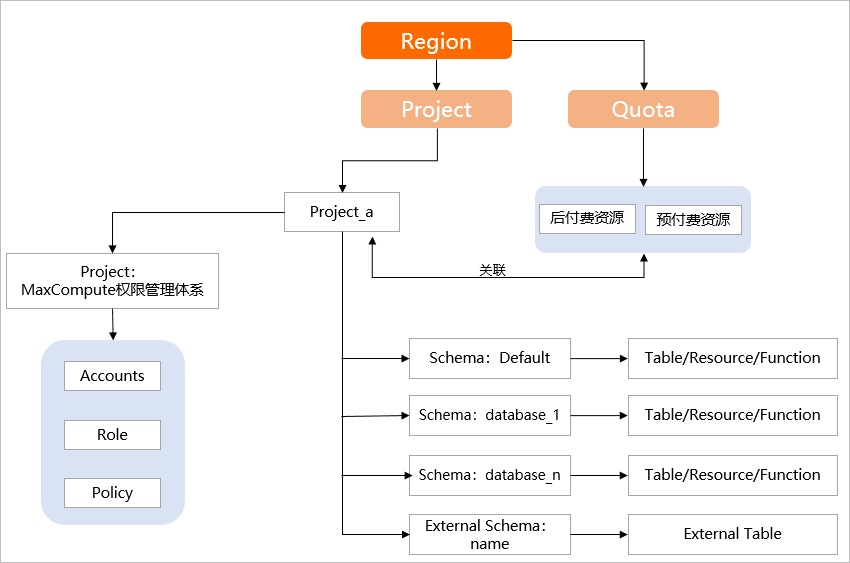
重点术语
Schema。
Schema是用于对Project下的Table、Resource、UDF进行归类的机制。一个Project下可以包含多个Schema。
Schema语法开关。
使用Schema功能,语法上需要识别
project.schema.table的语义,通过Schema语法开关来决定。当Schema语法打开,则可将a.b.c格式的语句识别为project.schema.table;将a.b格式的语句识别为schema.table。当Schema语法关闭,则不识别a.b.c格式的语句,并将a.b格式的语句识别为projet.table。此开关支持租户级别和作业级别设置。租户级别设置,决定整个租户提交数据访问的默认语义。可以在MaxCompute控制台的租户管理>租户属性页面查看,同时如果当前租户下没有任何项目,或者项目数量不超过10个,且都已经升级支持Schema以及评估过影响,则可以在租户属性页面打开租户级Schema语法开关,如果当前租户下的项目数量超过10个,不允许也不建议您修改。关于开启租户级Schema详情,请参见租户属性。
作业级别设置,仅影响当前作业的语义,优先级高于租户级别设置,可通过
set odps.namespace.schema=true | false;命令打开或关闭Schema语法。
Default Schema。
使用Schema功能的Project,每个Project下会内建一个名称为DEFAULT的Schema,且不可自定义删除。
使用限制
当前MaxCompute Schema功能在陆续完善中,有些模块没有适配,即这些模块对MaxCompute发起的操作仅能在set odps.namespace.schema=false的模式下正常使用,具体限制如下。
MaxCompute的Spark作业从spark.hadoop.odps.spark.version=spark-3.1.1-odps0.35.0版本开始支持,同时需要Spark作业设置以下参数:
spark.hadoop.odps.spark.version=spark-3.1.1-odps0.35.0 spark.hadoop.odps.spark.default.enable=false spark.sql.catalog.odps.enableNamespaceSchema=trueMaxCompute的Mars、MapReduce作业暂不支持有Schema的项目,即您的项目一旦升级为支持Schema,将无法使用这两类作业。
PAI、Quick BI等其他云产品暂不支持自定义Schema相关功能。
MaxCompute Studio插件4.0.0及以上版本支持Schema相关功能。
在
odps.namespace.schema=false模式下创建的View和UDF只能在同样的模式下访问,odps.namespace.schema=true模式同理。Hologres V1.3及以上版本支持MaxCompute Schema相关功能。若您需要升级Hologres的实例,请参见实例升级。
Java SDK 0.40.8及以上版本、JDBC 3.3.2及以上版本、MaxCompute客户端v0.40.8及以上版本、PyODPS 0.11.3.1及以上版本支持Schema相关功能。
MaxCompute租户级别或项目级别开启Schema功能后,DataWorks才支持展示Schema相关交互。详情请参见DataWorks支持MaxCompute Schema。
功能开启
当您有需求使用MaxCompute的Schema功能,可以参考如下方式开启功能。
若您刚开始使用MaxCompute,无存量项目,则可以在MaxCompute控制台的租户管理>租户属性页面打开租户级Schema语法开关,这样您新建的项目都是支持Schema功能的项目,同时所有请求默认按
odps.namespace.schema为true的语法识别。若您有存量项目,且不超过10个,但无存量作业或少量作业并愿意修改适配,则可以先将存量的项目全部升级为Schema模式,然后再在MaxCompute控制台的租户管理>租户属性页面打开租户级Schema语法开关,成功后,您新建的项目都支持Schema功能,同时所有请求默认按
odps.namespace.schema为true的语法识别。若您有存量的项目和作业,但是目前有新的业务需要使用Schema功能,即某个或几个项目要升级支持Schema,项目支持Schema功能升级方式如下,升级后默认在Project内新建名为DEFAULT的Schema。
您可直接在MaxCompute控制台的工作区>项目管理页面进行操作升级。如果项目管理页面的项目未支持Schema,则操作列会有如下入口,您可自行操作。

需要注意的是,此时没有开启租户级别Schema语法(实际也不建议开启,因为会影响存量作业),所有请求默认是按
odps.namespace.schema为false的语法识别,因此已经升级的项目创建了自定义Schema后,要访问自定义Schema下的数据,需使用作业级别开启Schema语法即set odps.namespace.schema=true;。若出现关联访问多个项目,而其他项目没有升级支持Schema:在Schema语法打开的情况下,对未升级的项目,数据路径写法为
projectname.default.tablename。在Schema语法关闭情况下,对于已升级的项目,无法访问自定义Schema,写法为
projectname.tablename仅会识别DEFAULT这个Schema下的数据。
使用说明
关于使用Schema的说明如下。
创建Project
使用Schema前需创建Project,详情请参见创建MaxCompute项目。通过MaxCompute控制台创建项目时,如果租户级别语法开关打开(odps.namespace.schema值为true),则项目默认支持Schema。否则,需要提交新功能测试申请将项目升级为支持Schema,详情请参见新功能试用申请。
提交新功能测试申请后,MaxCompute将在每周一和每周四对Project进行升级,请耐心等待。
管理Schema
通过命令管理Schema
管理Schema的命令如下所示。
查看Schema列表。
show schemas;创建Schema。
create schema <schema_name>;schema_name为自定义的Schema名称。
查看Schema信息。
desc schema <schema_name>;schema_name为Schema名称。
删除Schema。
drop schema <schema_name>;schema_name为Schema名称。
通过管理控制台管理Schema
登录MaxCompute控制台,在左上角选择地域。
在左侧导航栏,选择工作区 > 项目管理。
在项目管理页面,单击目标项目操作列的管理。
在项目配置页面,单击Schema。
说明支持Schema的项目才可见Schema页签。
在Schema页签,您可以查看Schema列表、创建和删除Schema。
操作Schema内对象
需要操作Schema内的对象(Table、View、Resource、Function),写命令时按照project.schema.table的格式进行编辑。
注意事项
本文中对Table对象的所有描述,同时适用于View、Resource、Function。
跨Project操作Table时,命令格式需要写完整(project.schema.table)。
同一个Project下跨Schema的命令格式可以写成
schema.table,即命令中如果写成a.b格式,则a解析为Schema,b解析为Table,Project为当前Project。同一个Project下可以使用
use schema <schema_name>命令指定当前Schema,命令中可直接使用类似select * from a的命令,此时a是Table,自动解析到当前的Project和指定的Schema。如果无上下文指定Schema,命令中使用类型
select * from a的命令,此时a是Table,自动解析到当前Project和名称为default 的Schema。
使用示例
示例1:在同一个Project(projectA)下操作Schema内对象。
操作default这个Schema内的对象。
use projectA; set odps.namespace.schema=true;--租户级别如果已经设置,此处就不用再指定 --操作table t_a create table t_a(c1 string,c2 bigint); insert into/overwrite table t_a values ('a',1),('b',2),('c',3); select * from t_a; show tables; desc t_a; tunnel upload <path> t_a[/<pt_spc>]; tunnel download t_a[/pt_spc] <path>; --操作resource res_a.jar add jar <path>/res_a.jar ; desc resource res_a.jar; list resources; get resource res_a.jar D:\; drop resource res_a.jar; --操作function fun_a create function fun_a as 'xx' using 'res_a.jar'; desc function fun_a; list functions; drop function fun_a;参数说明如下:
path:文件的存放路径以及文件名称。
pt_spc:需要指定至最末级分区,格式为:
pt_spcpartition_col1=col1_value1, partition_col2=col2_value1...pt_spc。
操作自定义Schema(s_1和s_2)下的对象,包括跨Schema操作。
use projectA; set odps.namespace.schema=true;--租户级别已经设置,此处就不用再指定 --操作s_1下的table t_c use schema s_1; create table t_c(c1 string,c2 bigint); insert into/overwrite table t_c values ('a',1),('b',2),('c',3); select * from t_c; show tables; drop table t_c; tunnel upload <path> t_c[/<pt_spc>]; tunnel download t_c[/pt_spc] <path>; --操作s_2下的table t_d create table s_2.t_d(c1 string,c2 bigint); insert into/overwrite table s_2.t_d values ('a',1),('b',2),('c',3); select * from s_2.t_d; show tables in s_2; drop table s_2.t_d; tunnel upload <path> s_2.t_d[/<pt_spc>]; tunnel download s_2.t_d[/pt_spc] <path>; --操作s_1下的resource res_b.jar use schema s_1; add jar <path>/res_b.jar ; desc resource res_b.jar; list resources; get resource res_b.jar D:\; drop resource res_b.jar; --操作s_2下的resource res_c.jar add jar xxx ;--add resource只能在当前schema/project下操作不能跨schema/project,所以正常操作还是需要切换到schema s_2 --跨项目或跨Schema时,resource的层级使用英文冒号(:)分隔 desc resource s_2:res_c.jar; list resources in s_2; get resource s_2:res_c.jar D:\; drop resource s_2:res_c.jar; --操作s_1下的function fun_b use schema s_1; create function fun_b as 'xx' using 'res_b.jar' desc function fun_b; list functions; drop function fun_b; --操作s_2下的function fun_c create function s_2.fun_c as 'xx' using 's_2/resources/res_c.jar' drop function s_2.fun_c; desc function s_2.fun_c; list functions in s_2; drop function s_2.fun_c;
示例2:跨Project操作(在ProjectA下操作ProjectB的对象)。
use projectA; set odps.namespace.schema=true; --租户级别如果已经设置,此处不用再指定 --操作projectB下的s_3的table t_f create table projectB.s_3.t_f(c1 string,c2 bigint); insert into/overwrite table projectB.s_3.t_f values ('a',1),('b',2),('c',3); select * from projectB.s_3.t_f; show tables in projectB.s_3; desc projectB.s_3.t_f; drop table projectB.s_3.t_f; tunnel upload <path> projectB.s_3.t_f[/<pt_spc>]; tunnel download projectB.s_3.t_f[/pt_spc] <path>; --操作projectB下的s_3的resource res_f.jar add jar xxx ;--add resource只能在当前schema/project下操作不能跨schema/project,所以正常操作还是需要切换到projectB并使用schema s_3 --跨项目跨Schema时,resource的层级使用英文冒号(:)分隔 desc resource projectB:s_3:res_f.jar; list resources in projectB.s_3; get resource projectB:s_3:res_f.jar D:\; drop resource projectB:s_3:res_f.jar; --操作projectB下s_3的function fun_f create function projectB.s_3.fun_f as 'xx' using 'projectB/schemas/s_3/resources/res_f.jar' desc function projectB.s_3.fun_f; list functions in projectB.s_3; drop function projectB.s_3.fun_f;
权限说明
Schema对象权限授权。
Schema对象相关的操作权限(如CreateTable、CreateResource、CreateFunction)需通过对Project对象授权来实现。拥有Project的这些操作权限,则所有Schema都具有这些操作权限。后续会实现对Schema对象的权限控制。
说明Schema Owner默认拥有Schema以及Schema内资源的所有访问权限和权限管控权限。
如果已经拥有Project的CreateTable、CreateResource、CreateFunction几项操作权限,自动继承Project下Schema对应的几个操作权限。
Schema内资源对象权限。
对Schema内资源对象进行授权时,对象必须写完整(
project.schema.table),授权语法格式如下。具体对象(Table、Resource、Function)的权限列表请参见MaxCompute权限。您也可以通过管理控制台进行授权操作,详情请参见通过控制台管理用户权限。--授予某角色Schema内所有表操作权限 GRANT schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.* TO role {rolename}; --移除某角色Schema内所有表操作权限 REVOKE schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.* FROM role {rolename}; --授予某角色或某用户Schema内某表操作权限 GRANT schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.<tablename> TO {role|user} {rolename | USER name};--授予某角色或者某用户Schema内某表操作权限 --移除某角色或某用户Schema内某表操作权限 REVOKE schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.<tablename> FROM {role|user} {rolename | USER name}; --查看某表的权限 SHOW GRANTS ON TABLE <project_name>.<schema_name>.<tablename>;说明为保障数据安全,不支持使用
GRANT schemaObjectPrivileges ON TABLE <project_name>.<schema_name>.xxx* TO role {rolename};语法进行授权。