本文为您介绍基于MaxCompute Studio通过Java UDTF读取MaxCompute资源的使用示例。
前提条件
-
已安装MaxCompute Studio,并连接至MaxCompute项目,创建了MaxCompute Java Module。
-
已安装开发工具IDEA 2024,JDK1.8版本。
-
更多操作信息,请参见安装MaxCompute Studio、管理项目连接和创建MaxCompute Java Module。
-
更多MaxCompute资源信息,请参见资源。
UDTF代码示例
java UDTF代码。
|
参数区别 |
参数类型 |
参数说明 |
|
入参 |
字符串(string)。 |
第一个输入参数。 |
|
字符串(string)。 |
第二个输入参数。 |
|
|
出参 |
字符串(string)。 |
第一个输入参数值。 |
|
整型(bigint)。 |
第二个输入参数的字符串长度值。 |
|
|
字符串(string)。 |
file_resource.txt行数,table_resource1资源表行数和table_resource2资源表行数,三者拼接返回的值。 |
package com.aliyun.odps.examples.udf;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Iterator;
import com.aliyun.odps.udf.ExecutionContext;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.UDTF;
import com.aliyun.odps.udf.annotation.Resolve;
/**
* project: example_project
* table: wc_in2
* partitions: p1=2,p2=1
* columns: cola,colc
*/
@Resolve("string,string->string,bigint,string")
public class UDTFResource extends UDTF {
ExecutionContext ctx;
long fileResourceLineCount;
long tableResource1RecordCount;
long tableResource2RecordCount;
@Override
public void setup(ExecutionContext ctx) throws UDFException {
this.ctx = ctx;
try {
InputStream in = ctx.readResourceFileAsStream("file_resource.txt");
BufferedReader br = new BufferedReader(new InputStreamReader(in));
String line;
fileResourceLineCount = 0;
while ((line = br.readLine()) != null) {
fileResourceLineCount++;
}
br.close();
Iterator<Object[]> iterator = ctx.readResourceTable("table_resource1").iterator();
tableResource1RecordCount = 0;
while (iterator.hasNext()) {
tableResource1RecordCount++;
iterator.next();
}
iterator = ctx.readResourceTable("table_resource2").iterator();
tableResource2RecordCount = 0;
while (iterator.hasNext()) {
tableResource2RecordCount++;
iterator.next();
}
} catch (IOException e) {
throw new UDFException(e);
}
}
@Override
public void process(Object[] args) throws UDFException {
String a = (String) args[0];
long b = args[1] == null ? 0 : ((String) args[1]).length();
forward(a, b, "fileResourceLineCount=" + fileResourceLineCount + "|tableResource1RecordCount="
+ tableResource1RecordCount + "|tableResource2RecordCount=" + tableResource2RecordCount);
}
}pom.xml代码,本地测试需要引入。
<dependency>
<groupId>com.aliyun.odps</groupId>
<artifactId>odps-udf-local</artifactId>
<version>0.48.0-public</version>
</dependency>操作步骤
本地测试
-
在MaxCompute Studio中新建UDTF类型的Java程序。例如Java Class名称为
UDTFResource,程序代码为UDTF代码示例中的代码。 -
根据Java Module中warehouse资源内容,配置运行参数。
说明-
入参为本地资源中wc_in2表中分区p1=2,p2=1中每行第一列和第三列的值。
-
代码执行获取本地资源file_resource.txt中数据,table_resource1对应表wc_in1中的数据,table_resource2对应表wc_in2(p1=2,p2=1)的数据。

-
-
在类名UDTFResource上,右键单击运行。并返回结果。


客户端测试
-
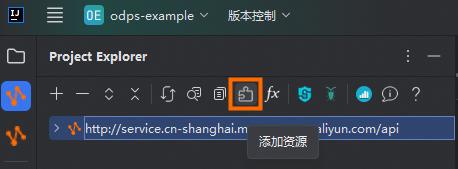
单击IDEA左上角
 Project Explorer,选择
Project Explorer,选择 添加资源。
添加资源。
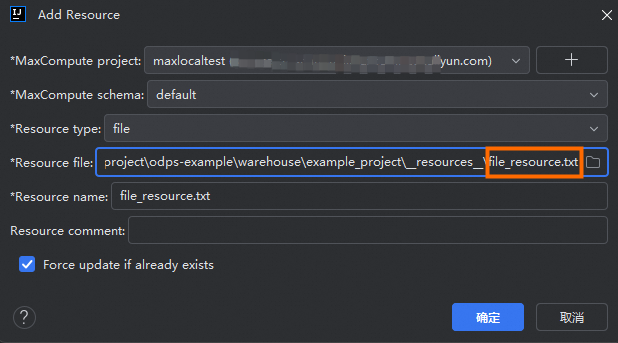
-
根据MaxCompute实例信息,添加file_resource.txt文件。
-
在MaxCompute项目中创建示例数据表wc_in1和wc_in2,并插入数据。
CREATE TABLE wc_in1 ( col1 STRING, col2 STRING, col3 STRING, col4 STRING ); INSERT INTO wc_in1 VALUES ('A1','A2','A3','A4'), ('A1','A2','A3','A4'), ('A1','A2','A3','A4'), ('A1','A2','A3','A4'); CREATE TABLE wc_in2 ( cola STRING, colb STRING, colc STRING ) PARTITIONED BY (p1 STRING, p2 STRING); ALTER TABLE wc_in2 ADD PARTITION (p1='2',p2='1'); INSERT INTO wc_in2 PARTITION (p1='2',p2='1') VALUES ('three1','three2','three3'), ('three1','three2','three3'), ('three1','three2','three3'); -
将MaxCompute创建的wc_in1和wc_in2两张表映射到Resource的table_resource1和table_resource2中。
wc_in1添加资源。
wc_in2添加资源。
-
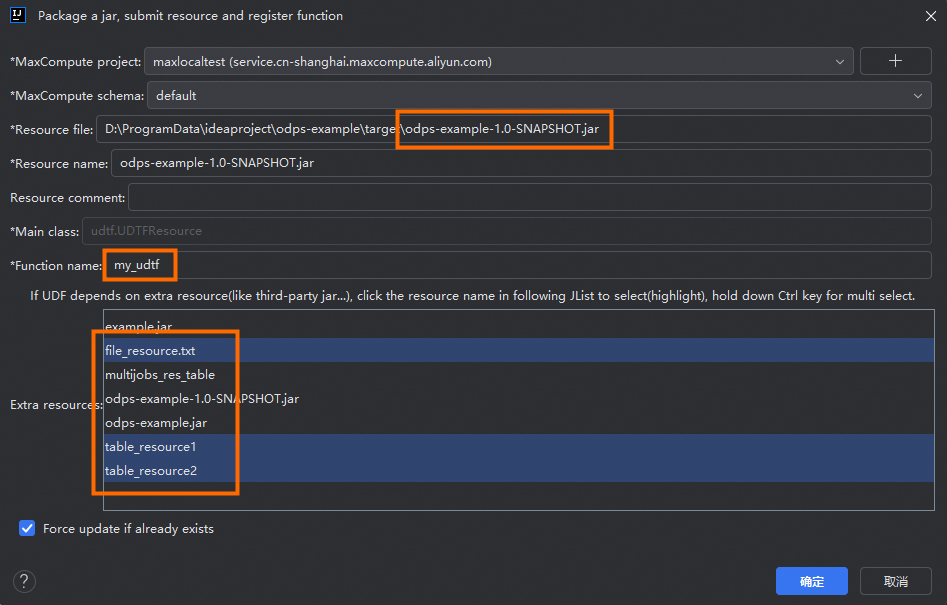
将创建的UDTF打包为JAR包,上传至MaxCompute项目并注册函数。例如函数名称为
my_udtf。在类名UDTFResource上,右键单击Deploy to Server...,进入打包上传界面,并在Extra resources中添加所需的file_resource.txt、table_resource1和table_resource2资源。 -
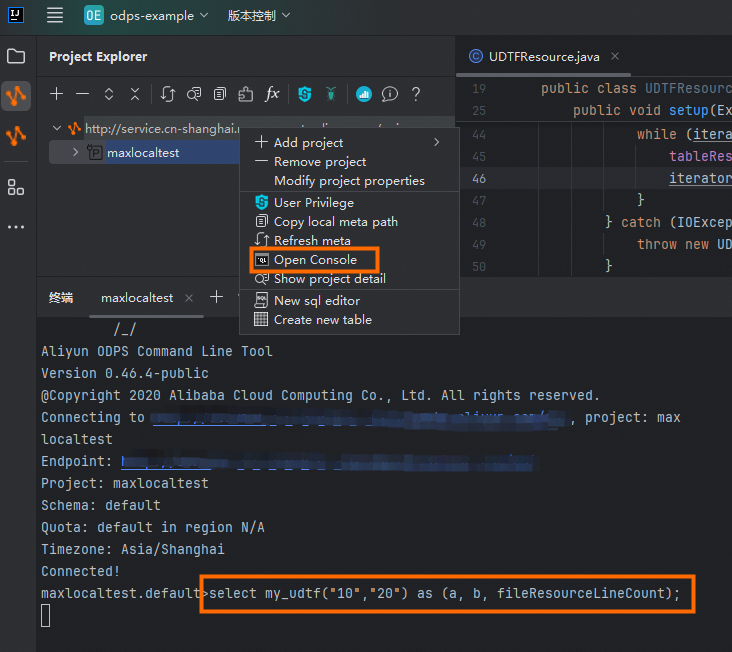
单击IDEA左上角
Project Explorer,在目标MaxCompute项目上单击右键Open Console,启动MaxCompute客户端,并执行SQL命令调用新创建的UDTF,并返回结果。示例代码如下。
SELECT my_udtf("10","20") AS (a, b, fileResourceLineCount);