2019 年双十一是蚂蚁集团架构云化的关键时间节点,Service Mesh 是应用云化非常重要的一环。业务与基础设施层的解耦势在必行,Mesh 化为这层解耦带来了实际可落地的解决方案。本文主要介绍蚂蚁集团 Service Mesh 落地实践的核心部分。
本文主要内容分为下述几个方面:
基础能力建设
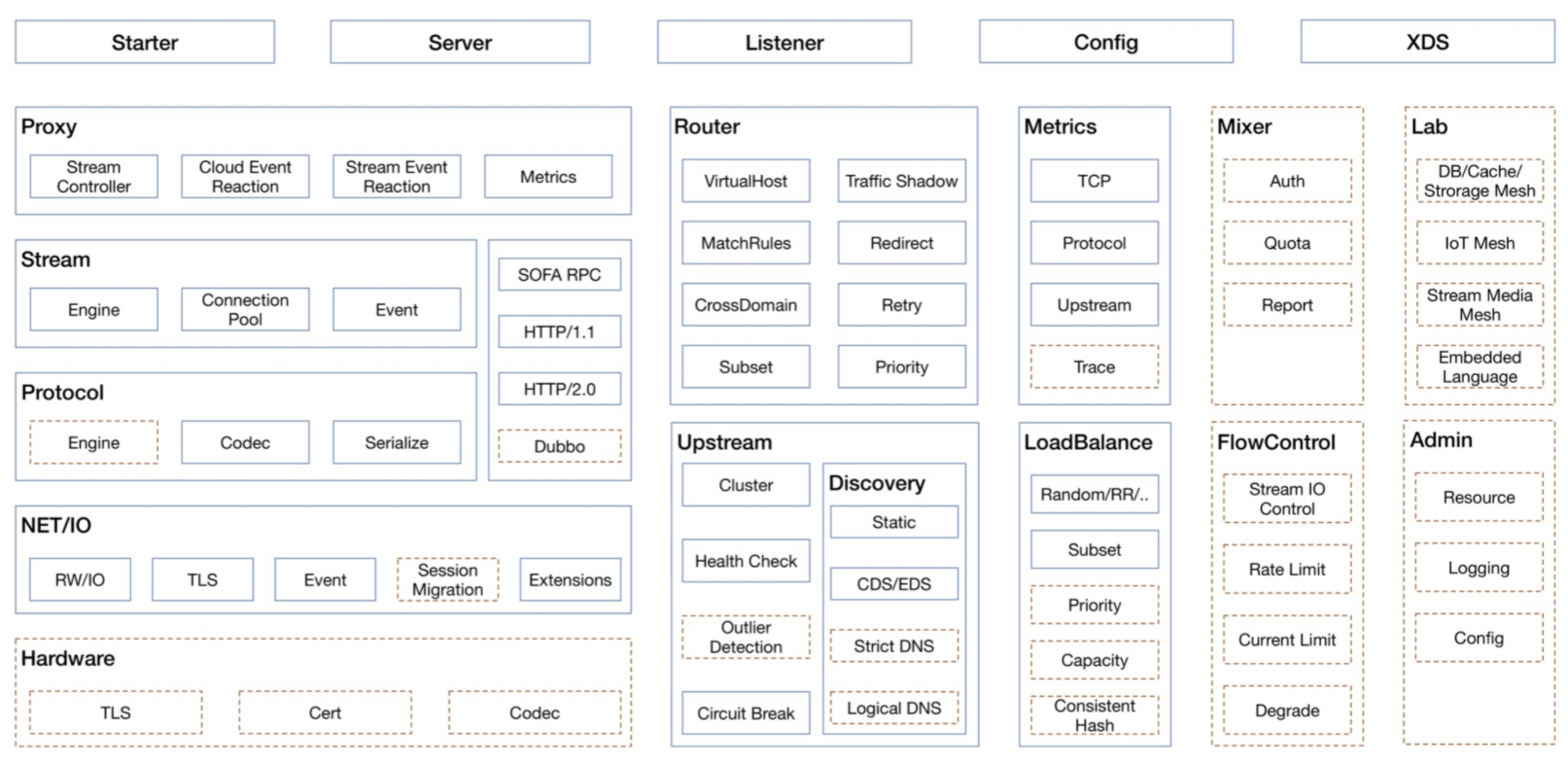
SOFAMosn 能力大图
SOFAMosn 主要包括了下述能力:
网络代理具备的基础能力。
XDS(Extended Discovery Service) 等云原生能力。
SOFAMosn 主要模块图
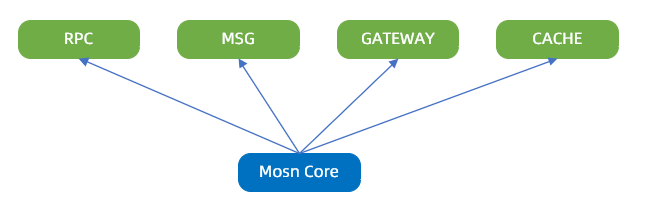
业务支持
SOFAMosn 作为底层的高性能安全网络代理,支撑的业务场景包括:RPC、MSG、GATEWAY 等。
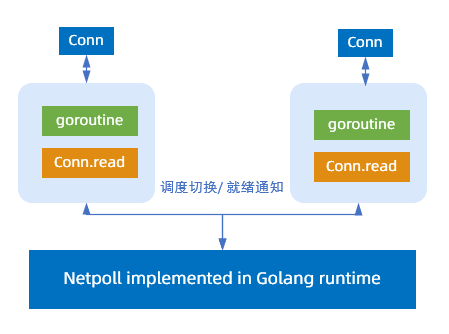
IO 模型
SOFAMosn 支持两种 IO 模型:
Golang 经典模型:在蚂蚁集团内部的落地场景,连接数不是瓶颈,都在几千或者上万的量级,蚂蚁集团选择了 Golang 经典模型 goroutine-per-connection。
模型缺陷:协程数量与连接数量成正比,大链接场景下,协程数量过多,存在以下开销:
Stack 内存开销
Read buffer 开销
Runtime 调度开销
RawEpoll 模型:也就是 Reactor 模式,即 I/O 多路复用(I/O multiplexing) + 非阻塞 I/O (non-blocking I/O)模式。对于接入层和网关有大量长连接的场景,更加适合于 RawEpoll 模型。
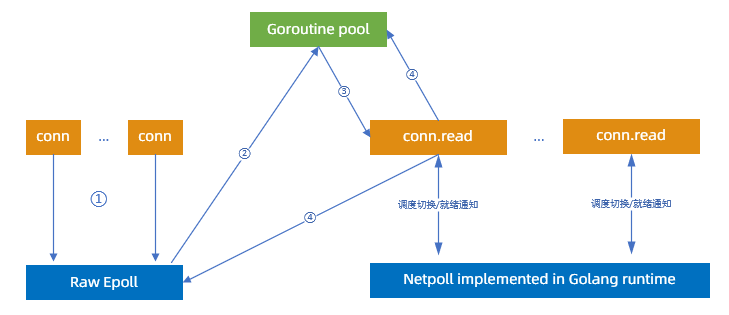
步骤说明:
建立连接:
向 Epoll 注册 oneshot 可读事件监听。此时不允许有协程调用
conn.read,以免与runtime Netpoll冲突。可读事件到达,从 goroutine pool 挑选一个协程进行读事件处理。由于使用的是 oneshot 模式,该 fd 后续可读事件不会再触发。
请求处理过程中,协程调度与经典 Netpoll 模式一致。
请求处理完成,将协程归还给协程池,同时将 fd 重新添加到 RawEpoll 中。
协程模型
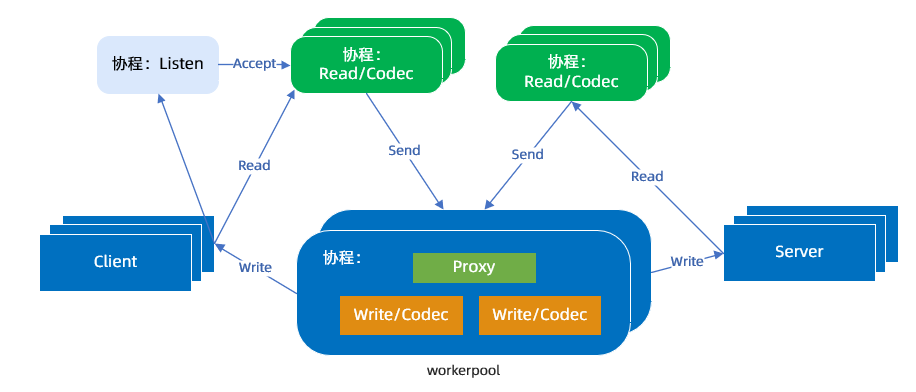
一个 TCP 连接对应一个 Read 协程,执行收包和协议解析。
一个请求对应一个 Worker 协程,执行业务处理、Proxy 和 Write 逻辑。
在常规模型中,一个 TCP 连接有 Read/Write 两个协程,蚂蚁团队取消了单独的 Write 协程,让 workerpool 工作协程代替它,减少了调度延迟和内存占用。
能力扩展
能力扩展主要包括下述几个方面:
协议扩展:SOFAMosn 通过使用统一的编、解码引擎,以及编、解码器核心接口,提供协议的 plugin 机制。支持下述协议:
SOFARPC
HTTP1.x/HTTP2.0
Dubbo
NetworkFilter 扩展:SOFAMson 通过提供 Network Filter 注册机制,以及统一的 packet read/write filter 接口,实现了 Network filter 扩展机制,当前支持下述功能。
TCP proxy
Fault injection
StreamFilter 扩展:SOFAMosn 通过提供 stream filter 注册机制,以及统一的 stream send/receive filter 接口,实现了 Stream filter 扩展机制,支持下述功能。
流量镜像
RBAC 鉴权
TLS 安全链路
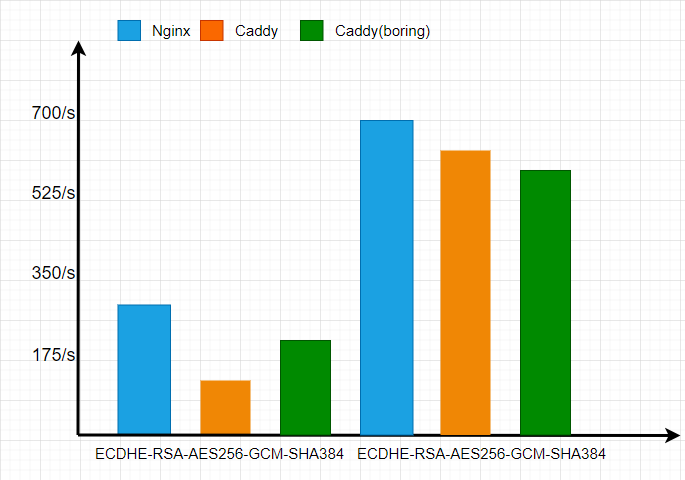
作为金融科技公司,资金安全是最重要的一环,链路加密又是其中最基础的能力。在 TLS 安全链路上,蚂蚁团队进行了大量的调研测试。测试结果显示:
原生 Go 的 TLS 经过了大量的汇编优化,在性能上是 Nginx(OpenSSL)的 80%。
Boring 版本的 Go,使用 CGO 调用 BoringSSL,因为 CGO 的性能问题, 该版本并不占优势。
所以,蚂蚁团队最后选择了原生 Go 的 TLS,相信 Go Runtime 团队后续会有更多的优化,蚂蚁团队也会有一些优化计划。
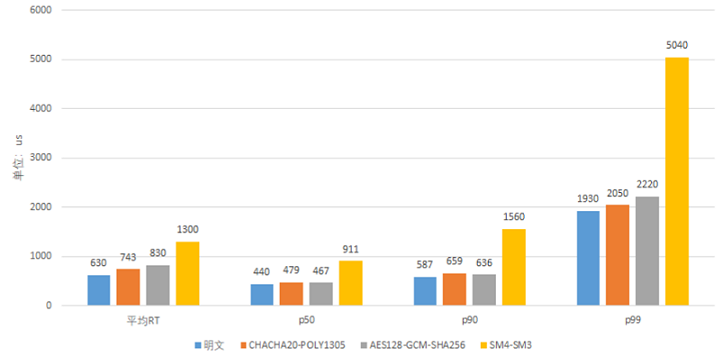
Go 在 RSA 上没有太多优化,Go-boring(CGO)的能力是 Go 的 1 倍。
p256 在 Go 上有汇编优化,ECDSA 优于 Go-boring。
在 AES-GCM 对称加密上,Go 的能力是 Go-boring 的 20 倍。
在 SHA、MD 等 HASH 算法上,也有对应的汇编优化。
为了满足金融场景的安全合规,蚂蚁团队同时也对国产密码进行了开发支持,这个是 Go Runtime 所没有的。相比国际标准 AES-GCM,目前的性能有大概 50% 的差距,蚂蚁团队已经有了后续的一些优化计划,敬请期待。
平滑升级能力
为了让 SOFAMosn 的发布对应用无感知,蚂蚁团队开发了平滑升级方案,该方案类似 Nginx 的二进制热升级能力,最大的区别是 SOFAMosn 老进程的连接不会断,会迁移给新的进程,包括底层的 socket FD 和上层的应用数据。这样可以保证整个二进制发布过程中,业务不受损,对业务无感知。除了支持 SOFARPC、Dubbo、消息等协议,还支持 TLS 加密链路的迁移。
平滑升级能力主要包括下述几个方面的内容:
容器升级:主要流程包括下述几个方面。
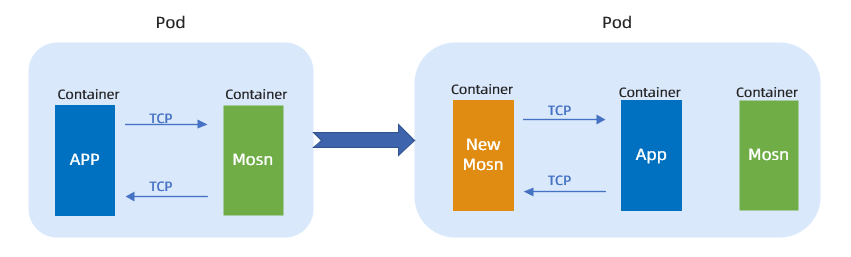
先注入一个新的 SOFAMosn。
通过共享卷的 UnixSocket 去检查是否存在老的 SOFAMosn。
如果存在老的 SOFAMosn,就和老的 SOFAMosn 进行连接迁移,然后老的 SOFAMosn 退出。
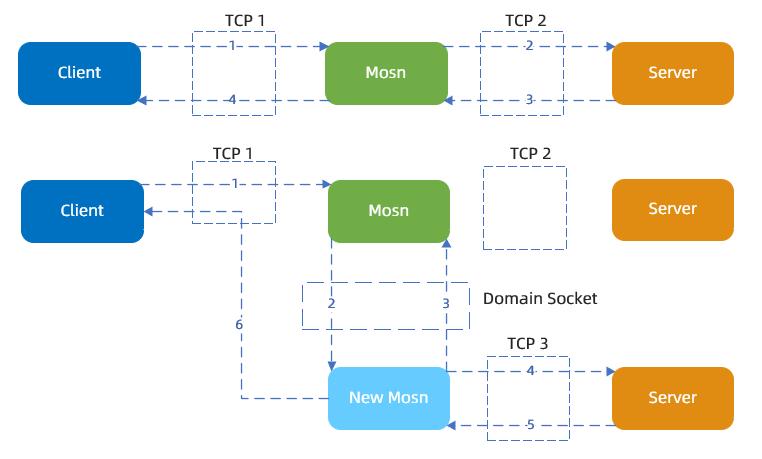
SOFAMosn 的连接迁移:连接迁移的核心是内核 Socket 的迁移和应用数据的迁移。连接不断,且对用户无感知。
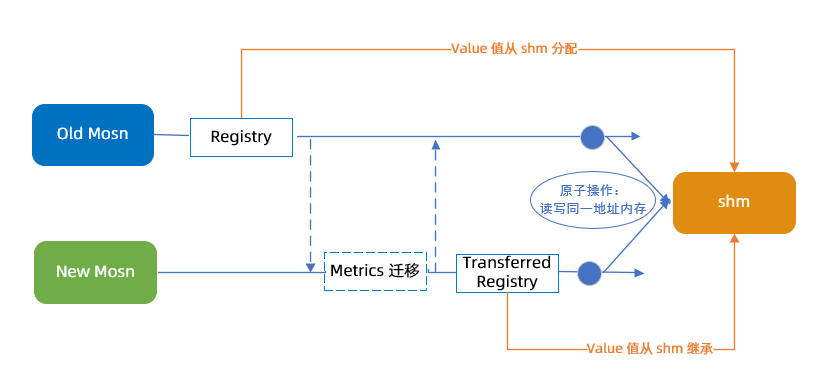
SOFAMosn 的 Metric 迁移:蚂蚁团队使用了共享内存来共享新老进程的 Metric 数据,保证在迁移的过程中 Metric 数据也是正确的。
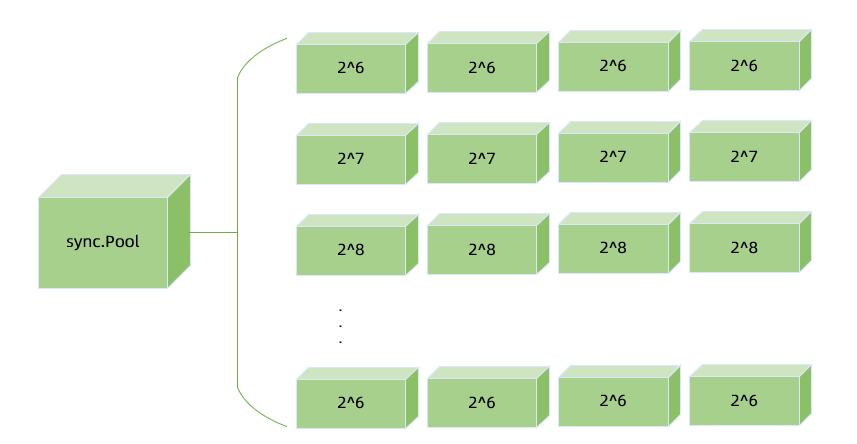
内存复用机制
内存复用机制主要特征如下:
基于 sync.Pool。
Slice 复用使用 Slab 细粒度,提高复用率。
常用结构体复用。
当前现状:
线上复用率可以达到 90% 以上。
sync.Pool 还存在一些问题,随着 Runtime 对 sync.Pool 的持续优化,比如 Go 1.13 使用 lock-free 结构减少锁竞争和增加了 victim cache 机制,它在未来会越来越完善。
XDS(UDPA)
支持云原生统一数据面 API,全动态配置更新。其中,XDS 指 Extended Discovery Service。UDPA 指 Universal Data Plane API。

前期准备
性能压测和优化
在上线前的准备过程中,蚂蚁团队在灰度环境中针对核心应用 cashiercloudtb 进行了大量的压测和优化,为后面的落地打下了坚实的基础。
从线下环境到灰度环境,蚂蚁团队遇到了很多线下没有的大规模场景,比如:
单实例数万后端节点,数千路由规则:不仅占用内存,对路由匹配效率也有很大影响。
海量高频的服务发布注册:对性能和稳定性有很大挑战。
整个压测优化过程历时五个月,从最初的 CPU 整体增加 20%,RT 每跳增加 0.8 ms, 到最后 CPU 整体增加 6%,RT 每跳增加 0.25 ms,内存占用峰值优化为之前的 1/10。
整体增加CPU | 每跳RT | 内存占用峰值 | |
优化前 | 20% | 0.8 ms | 2365 M |
优化后 | 6% | 0.25 ms | 253 M |
部分优化措施:
在 6.18 大促时,蚂蚁团队上线了部分核心链路应用,CPU 损耗最多增加 1.7%,有些应用从 Java 迁移到 Go,CPU 损耗还降低了 8% 左右。延迟方面平均每跳增加 0.17 ms,两个合并部署系统全链路增加 5~6 ms,有 7% 左右的损耗。
在单机房上线 SOFAMosn 时,SOFAMosn 在全链路压测下的整体性能表现更好。比如:交易付款时,带 SOFAMosn 比不带 SOFAMosn 的响应时间(RT)降低了 7.5%。
SOFAMosn 所做的大量核心优化和下沉的 Route Cache 等业务逻辑优化,更带来了架构的红利。
Go 版本选择
版本的升级都需要做一系列测试,新版本并不都最适合目标场景。该项目最开始使用的版本为 Go 1.9.2,在经过一年迭代之后,蚂蚁团队开始调研当时的最新版 Go 1.12.6,测试验证了新版很多好的优化,也修改了内存回收的默认策略,以便更好地满足项目需求。
GC 优化,减少长尾请求:新版的自我抢占(self-preempt)机制,将耗时较长的 GC 标记过程打散,来换取更为平滑的GC 表现,减少对业务的延迟影响。
Go 1.9.2

Go 1.12.6

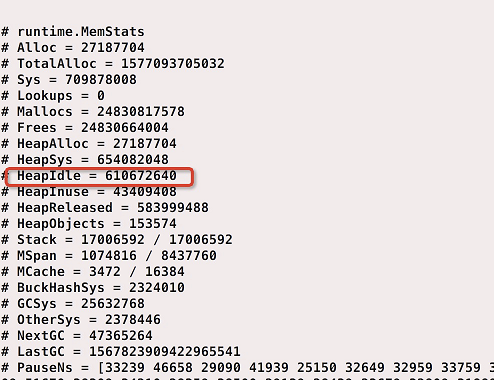
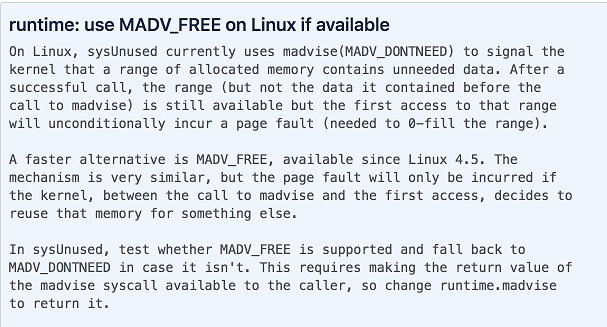
内存回收策略:Go 1.12 修改了内存回收策略,从默认的 MADV_DONTNEED 修改为了 MADV_FREE。虽然这是一个性能优化,但是在实际使用中,测试显示性能并没有大的提升,却占用了更多的内存,对监控和问题判断有很大的干扰。蚂蚁团队通过 GODEBUG=madvdontneed=1 恢复为之前的策略。在 issue 里也有相关讨论,后续版本可能也会改动这个值。
使用 Go 1.12 默认的 MADV_FREE 策略时,HeapInuse = 43 M, 但是 HeapIdle = 600 M,一直不能释放。
Go Runtime Bug 修复
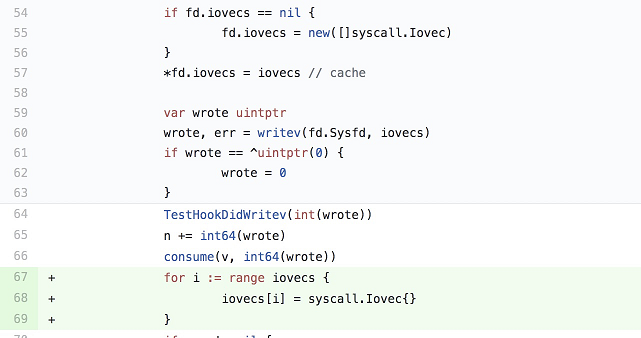
在前期灰度验证时,SOFAMosn 线上出现了较严重的内存泄露,一天泄露了 1 G 内存,最终排查显示,是 Go Runtime 的 Writev 实现存在缺陷,导致 Slice 的内存地址被底层引用,GC 不能释放。
蚂蚁团队给 Go 官方提交了 Bugfix,已合入 Go 1.13 最新版,参见 internal/poll: avoid memory leak in Writev。