
人工评测智能体应用需要手动构建评测集,耗时费力,同时评测结果依赖领域专家的判断,虽保证了专业性,但过程难以量化且可能带入个人主观偏好。阿里云百炼提供了自动评测功能,利用大模型、基于应用的知识库自动生成评测集,评估智能体的回答并生成评测报告与调优建议。自动评测支持两种模式:
-
单应用评测:深度评估单个智能体应用的表现,生成包含评分、错误分析和优化建议的详细报告,用于快速发现问题并针对性优化。
-
多应用横向评测:在同一评测基准下,对比评估多个应用(或同一应用的不同版本)的各项指标,用于选型决策或版本迭代效果验证。
前提条件
操作流程
完成一次完整的自动评测需要经历四个阶段:创建评测任务、设置评测集、配置评测规则和执行评测。
创建评测任务
-
进入阿里云百炼控制台自动评测界面,单击创建评测任务。
若尚未开通应用观测,请在弹出窗口单击立即前往完成开通。
-
选择需要评测的智能体应用。可以选择 1 个应用进行评测,或选择最多 8 个应用进行横向评测。
说明-
仅支持选择已发布且配置知识库的应用。
-
同一智能体的不同版本将被视为不同的、独立的应用。
-
进行多应用横向评测时,所有被选应用必须都已关联了至少一个相同的知识库。
在选择智能体页面,左栏显示智能体列表,勾选目标智能体后,右栏自动展示该智能体的可用版本列表,勾选需要评测的版本,然后单击下一步进入设置评测集步骤。
-
-
选择用于评测的知识库。单应用评测时,可从该应用关联的所有知识库中选择一个或多个用于生成评测集;多应用横向评测时,系统会列出所有被选应用的公共知识库,选择一个或多个用于生成评测集。
在创建评测任务页面的第一步选择评测应用中,先在已选智能体区域选择需要评测的应用,再在下方选择知识库范围区域勾选目标知识库,完成后单击下一步。
-
确认选择无误后,单击下一步。若所选应用没有开通应用观测,请在弹出窗口单机一键开通并进入下一步。
设置评测集
评测集选择支持生成评测集和选择已有评测集两种方式:
-
生成评测集:基于上一步选中的知识库,由大模型自动生成评测集。所有生成的评测集均可在评测集页面查看。
-
选择已有评测集:复用已有评测集,需确保所选评测集内各问题的参考答案,均能在当前指定的知识库中找到。否则将导致评测结果不准确。评测集格式请参考评测集。
以下以生成评测集为例。
-
输入评测集名称。
-
选择任务类型。生成评测集时,需选择 2 至 8 种任务类型。系统默认提供“事实型”、“分析型”、“比较型”、“教程型”四种任务类型。此外也支持自定义新类型,单击增加任务类型,输入任务类型、描述和示例即可。
页面提供生成评测集和选择已有评测集两种方式。选择生成评测集后,需填写评测集名称并确认已选知识库,完成任务类型配置后单击生成评测集按钮提交。
-
选择用于生成评测任务的模型。为确保生成质量,目前仅支持使用
qwen-max和qwen-plus模型。各模型能力请参考选择模型,计费规则请参考模型调用计费。 -
模型选择完毕后,页面下方将显示模型 Token 的预估平均消耗和预估最大消耗。评测完成后,可以在自动评测页面查看实际 Token 消耗明细。
说明-
预估平均消耗是参考值,最终用量请以实际账单为准。
-
预估最大消耗是为防止意外的超长输出而设置的成本硬性上限,实际消耗通常远低于此值。
-
-
单击生成评测集,在弹出页面确认配置信息,然后单击继续生成。
弹出的确认对话框中显示 已选知识库、任务类型(事实型、教程型、比较型、分析型)和 评测模型选择 三项配置,并提示评测集生成发起后不支持修改且会消耗较多tokens。
-
等待评测集生成,生成状态可在评测集管理页面查看。评测集生成的时间开销,主要取决于所选知识库的数量与文档总量。生成完毕后,单击下一步。
进入查看评测集页面,页面显示评测集名称及版本信息,可单击编辑评测集进行修改。评测集以表格形式展示,包含任务类型、用户query、参考答案、粗粒度关键词和细粒度关键词列。确认评测集内容无误后,单击下一步进入评测规则设置。
配置评测规则
-
选择分类采样数。用于设置每个任务类型需要采样的问题数量。系统将从每个类型下随机抽取指定数量的问题用于最终评测。
分类采样数包含事实型(Factual)、教程型(Tutorial)、比较型(Comparative)和分析型(Analytical)四个类型,可通过滑块分别设置采样数量。本示例中将事实型和分析型各设为1,其余设为0,评测总数为2。
-
选择评测模型。为确保结果准确,目前仅支持使用
qwen-max和qwen-plus模型,模型能力和计费规则请参考选择模型和模型调用计费。 -
模型选择完毕后,下方将显示预估平均消耗和预估最大消耗。采样的评测数据越多,消耗的 Token 数量越大。评测完成后,可在自动评测页面查看实际 Token 消耗明细。
说明-
预估平均消耗是参考值,最终用量请以实际账单为准。
-
预估最大消耗是为防止意外的超长输出而设置的成本硬性上限,实际消耗通常远低于此值。
完成配置后,单击试运行可先验证评测流程,确认无误后单击发起评测任务开始正式评测。
-
-
在正式评测之前,可以选择试运行以预览评测效果,试运行仅支持单个应用的评测结果预览。试运行将随机抽取一道题执行完整评测,此过程会消耗少量 Token。单击试运行,在弹窗中选择需要试运行评测的应用,再次单击试运行。
查看试运行结果。
试运行结果弹窗中展示每条评测用例的用户query、参考答案、实际运行结果、任务类型(如教程型、分析型、事实型)以及大模型打分(星级评分)。
执行评测
-
确认评测集与评测规则配置无误后,单击发起评测任务。
在设置评测规则页面,通过滑块调整各评测维度的权重值(范围0~1),在评测模型下拉框中选择模型(如
qwen-max),页面将展示预估平均和最大token消耗。可单击试运行预览评测效果。 -
在弹出窗口确认评测配置和预计消耗后,单击开始评测。
等待评测完成。自动评测的时间开销,主要取决于评测样本的总规模。
评测任务开始后,任务列表中该任务的评测状态显示为评测中(X%),如需中途停止,可在操作列单击终止。
-
评测完成后,可在任务列表中单击追加评测,为本次任务加入新的应用进行对比。此操作适用于单应用评测和多应用评测。追加后的应用总数不能超过 8 个。
评测报告分析
评分机制
系统使用大模型对每个回答进行评分(1-5 分),评分时会对比智能体的输出和评测集中的参考答案,评估答案的准确性、完整性和相关性。评分规则如下:
-
5 分:答案正确,质量优秀。
-
4 分:答案正确,质量良好。
-
4 分以下:答案错误,系统将自动进行归因分析。
结果分析
-
总正确率:展示应用的整体表现评估,计算公式:总正确率 = 得分不低于4分的回答数量 / 总回答数量 × 100%。多应用评测会以图表形式展示各应用的对比。
单应用:

多应用:
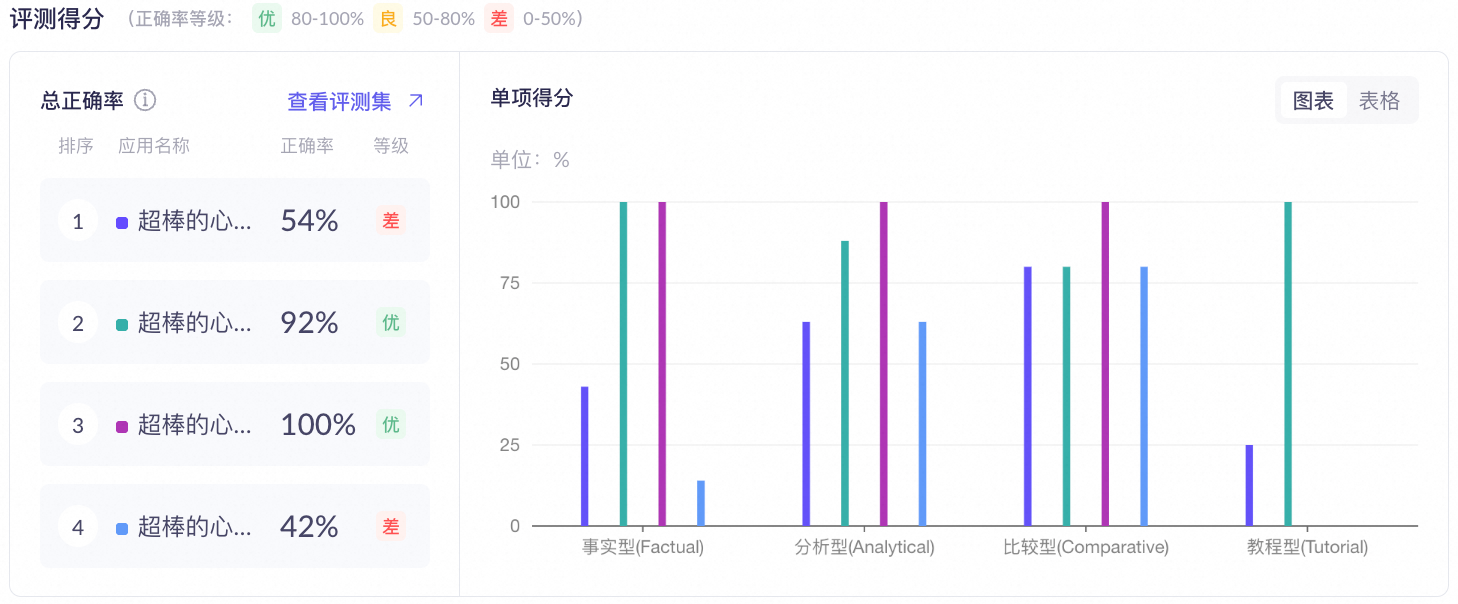
-
BadCase 分析:BadCase 列表默认按分数从低到高展示 Top-5 的错误评测条目,点击查看全部数据可以查看全部错误评测条目。
若无 BadCase,BadCase 分析列表将为空。如需查看全部结果,可单击页面右上角下载评测结果。
BadCase分析页面左侧为汇总区域,包含大模型打分和问题分类两个Tab页签,通过环形图展示不同分数段(2-4分、低于2分)的BadCase数量分布。右侧BadCase列表包含任务类型、用户输入、应用输出、打分/问题分类等列。
-
调优建议:系统会根据归因分析结果,提供针对Prompt、检索配置或知识库切片的具体优化建议。
例如,针对切片不完整问题(通常由于创建知识库时选择的切分策略不合适,导致关键信息被切分到多个切片),系统建议:1. 根据参考答案长度调整最大分段长度和分段重叠长度;2. 选择自定义切分方式,自由调整切分策略(如按页码切分、按标题切分、按正则切分等);3. 找到被错误切分的切片,手动调整切片信息,使得相关性强的内容在同一个切片内。
-
RAG 智能体评价:展示各问题类型(如事实型、分析型)的单项得分。
评分标准分为表现优秀(>=4)、表现良好(2-4)和待提升(<2)三档。事实型(Factual)和比较型(Comparative)表现优秀占比均为100.0%;分析型(Analytical)表现优秀占比80.0%,表现良好占比20.0%;教程型(Tutorial)各项占比均为0.0%。
归因分析
对于得分低于 4 分的 BadCase,系统会自动进行归因分析,定位问题出在 RAG 流程的哪个环节。各项归因类型的含义及优化建议如下:
-
模型理解有误:已获取正确知识,但应用配置的提示词不明确或模型推理能力不足,导致答案错误。需补充更清晰的回答要求或切换更强的模型。
-
重排不佳:正确切片已被召回,但排序靠后未被包含在最终传递给大模型的上下文中。需调整重排配置或增加传递给模型的切片数量。
-
检索无效:通常是由于设置的检索策略不合适,导致召回了过多或过少的切片。需根据数据特点调整检索方式。
-
切片不完整:通常是由于创建知识库时,切分粒度过细导致一个完整的语义单元被分割到多个不同的切片中。需增大切片长度或启用语义切分。
-
未获取知识:可能是由于知识库召回无结果或缺失与问题相关的内容。需向知识库中补充相应知识。
最佳实践
单次评测只能反映应用在特定时间点的表现。要持续保障智能体应用的质量,需要将自动评测融入日常的开发和运维流程。
建立持续评测机制
以下场景建议触发一次评测:
-
知识库更新后:新增、修改或删除知识内容可能影响检索和回答质量。
-
调整 Prompt 后:提示词的变化直接影响模型的输出行为。
-
更换或升级模型后:不同模型的理解和生成能力存在差异。
-
调整检索/重排策略后:这些配置直接影响 RAG 流程的召回质量。
-
定期回归(每周或每月):即使没有主动变更,也建议定期评测以监控潜在的质量波动。
建立优化闭环
建议按以下流程进行迭代:
-
识别 BadCase:在评测报告中,重点关注得分低于 4 分的回答。
-
分析归因,定位问题:根据系统给出的归因类型,参考归因分析中的说明,快速定位每个 BadCase 的产生原因。
-
实施针对性优化:根据归因结果,修改对应的配置。
-
发布新版本,再次评测:将优化后的应用发布为新版本,使用同一评测集进行评测。
-
对比结果,确认改进:对比新旧版本的评测报告,验证优化效果。若优化效果未达预期或发现新问题,则返回第一步,开始新一轮优化循环。
常见问题
模型 Token 的预估平均消耗和预估最大消耗有什么区别?为什么实际消耗与预估消耗不符?
-
预估平均消耗是参考值,最终用量请以实际账单为准。
-
预估最大消耗是理论上限,基于模型最大输入输出 Token 长度计算,实际消耗不会超过这个值。
为什么评测集生成和应用评测的进度长时间保持在0%?
评测集生成和应用评测均为离线任务,需在后台排队执行,排队期间进度将保持0%。任务开始执行后,进度会自动更新。
评测任务运行时,关闭应用观测会有什么影响?
为确保评测任务正常运行,请勿在评测期间关闭应用观测,否则可能导致评测任务失败、数据丢失或最终评测报告不准确。
为什么评测报告中显示的用例数量与设置的不符?
自动评测可能会失败。评测报告只显示成功完成评测的任务用例,失败的任务不计入最终正确率的计算。
为什么评测任务失败了,还会消耗 Token?
评测任务是分步执行的。每个成功完成的步骤都会消耗 Token 并计费。如果任务在后续步骤失败,此前已消耗的 Token 仍然会计入用量。