
我的模型页面用于管理您创建和导入的模型。通过该页面,您可以将本地训练的 LoRA 模型从阿里云对象存储 OSS 导入到百炼平台。
使用前提
导入前,请确保满足以下条件:
-
OSS Bucket 准备:已创建 OSS Bucket,并为目标 Bucket 添加标签。
说明-
支持的 OSS Bucket 存储类型不包括归档、冷归档或深度冷归档。支持内容加密的 Bucket。支持私有的Bucket。
-
不支持访问OSS Bucket根目录下的文件,请您在OSS Bucket下选择已有的子目录或新建一个子目录供阿里云百炼访问。
-
支持导入任意大小的模型文件,导入后将使用阿里云百炼提供的免费存储空间。
-
-
模型文件准备:模型文件需符合导入要求与限制。模型文件夹需直接放在 OSS Bucket 中,系统会自动识别。
支持导入的基础模型
当前支持导入以下基础模型的 LoRA 微调版本:
|
模型系列 |
模型名称 |
|
千问3 |
千问3-32B |
|
千问3-14B |
|
|
千问3-8B |
|
|
千问3-4B-Instruct-2507 |
|
|
千问3-VL |
千问3-VL-8B-Instruct |
|
千问2.5 |
千问2.5-72B-Instruct |
|
千问2.5-32B-Instruct |
|
|
千问2.5-14B-Instruct |
|
|
千问2.5-7B-Instruct |
|
|
千问2.5-VL |
千问2.5-VL-72B-Instruct |
|
千问2.5-VL-7B-Instruct |
操作步骤
按照以下步骤将 LoRA 模型从 OSS 导入到百炼平台:
-
在我的模型页面,点击导入模型按钮。
-
在导入模型页面中,填写以下信息:
-
模型名称:输入模型的显示名称,最多50个字符。
-
基础模型:选择该 LoRA 模型对应的基础模型。
-
训练方式:选择模型的训练方式。可选项取决于所选基础模型,选择基础模型后自动显示。
-
导入来源:当前仅支持"从OSS导入",系统已默认选中。
-
Bucket:选择存储模型文件的 OSS Bucket。
-
模型目录:在选定的 Bucket 中浏览并选择模型 Checkpoint 所在的目录。
-
模型加密:为保障您的数据安全,平台会为导出的模型文件开启 OSS 服务端加密,使用 OSS 完全托管密钥进行加解密(SSE-OSS),加密算法为 AES256。
-
-
确认信息无误后,点击确定提交导入请求。如需放弃导入,点击取消返回列表页。系统将自动验证模型文件格式和完整性,验证通过后开始导入。导入完成后,您可以在我的模型页面查看导入的模型,并进行部署、增量训练或删除等操作。
导入后的模型状态包括:创建中(正在导入)、创建成功(导入成功,可部署)、创建失败(导入失败)、已失效(模型文件已变更)。列表页还展示模型名称/ID、基础模型、来源、支持部署方式和创建时间等信息。您可以通过页面顶部的搜索框按名称筛选模型。
导入要求与限制
重要:当前版本仅支持导入 LoRA(Low-Rank Adaptation)模型,不支持导入全参微调模型。
导入 LoRA 模型前,请确保满足以下要求:
-
必需文件:OSS Bucket 中需包含以下文件:
-
adapter_model.safetensors:LoRA 适配器的权重文件,采用 SafeTensors 格式存储。
-
adapter_config.json:LoRA 适配器的配置文件,包含 rank、alpha 等关键参数信息。
-
-
rank 参数限制:rank 值必须为 8、16、32 或 64 中的一个,且同一模型的所有 LoRA 层必须使用相同的 rank 值。
-
修改词汇表的模型:如果训练过程中添加了新 token 或修改了原始词汇表(vocab),该模型无法导入。系统要求使用与基础模型完全一致的词汇表。
-
修改对话模板的模型:如果训练过程中修改了 chat_template 配置,该模型无法导入。系统仅支持使用与对应开源基础模型默认配置一致的 chat_template。
chat_template 配置通常位于以下位置:
-
模型的 config.json 文件中的
chat_template字段。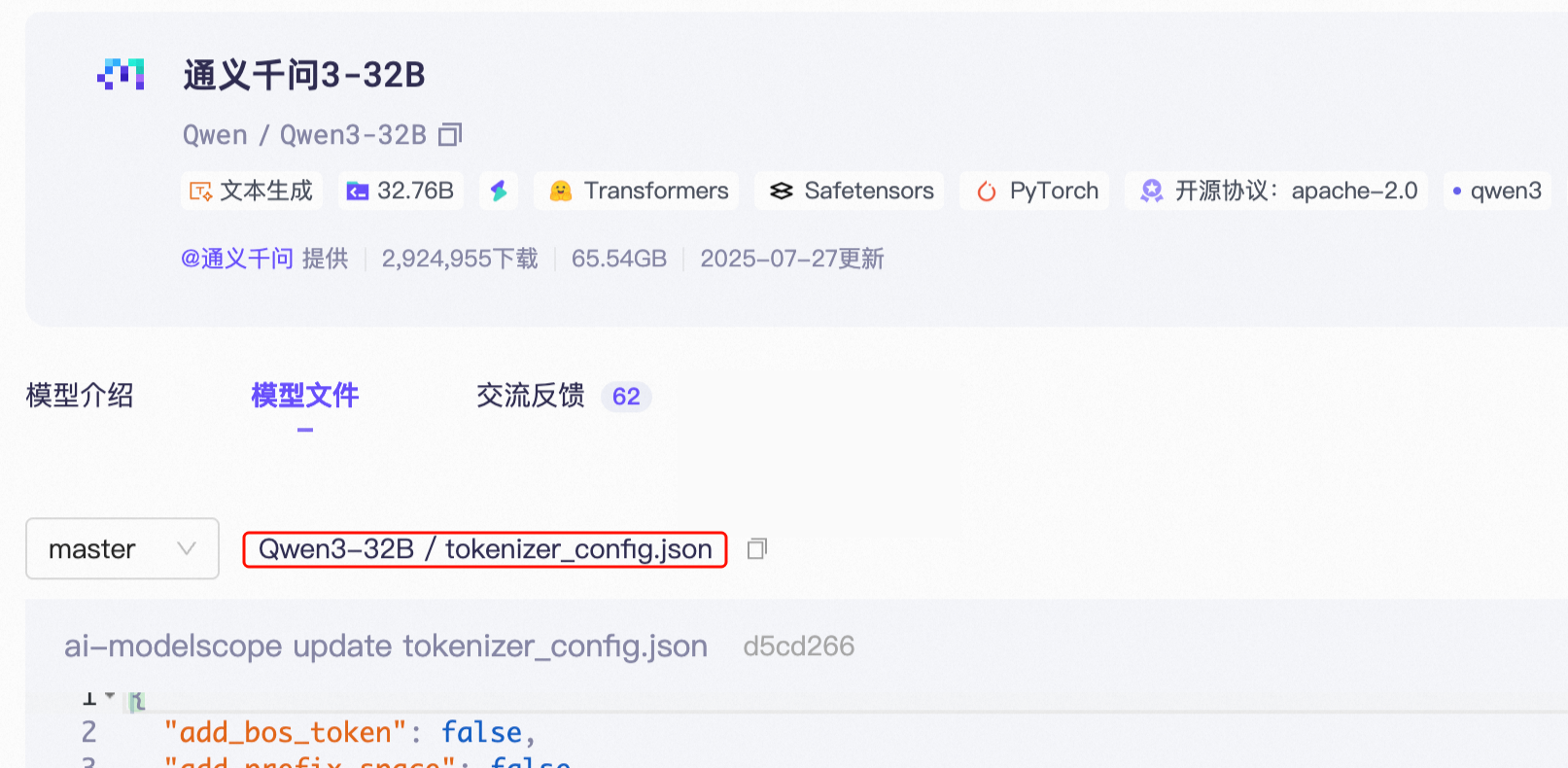
-
tokenizer_config.json 文件中的
chat_template字段。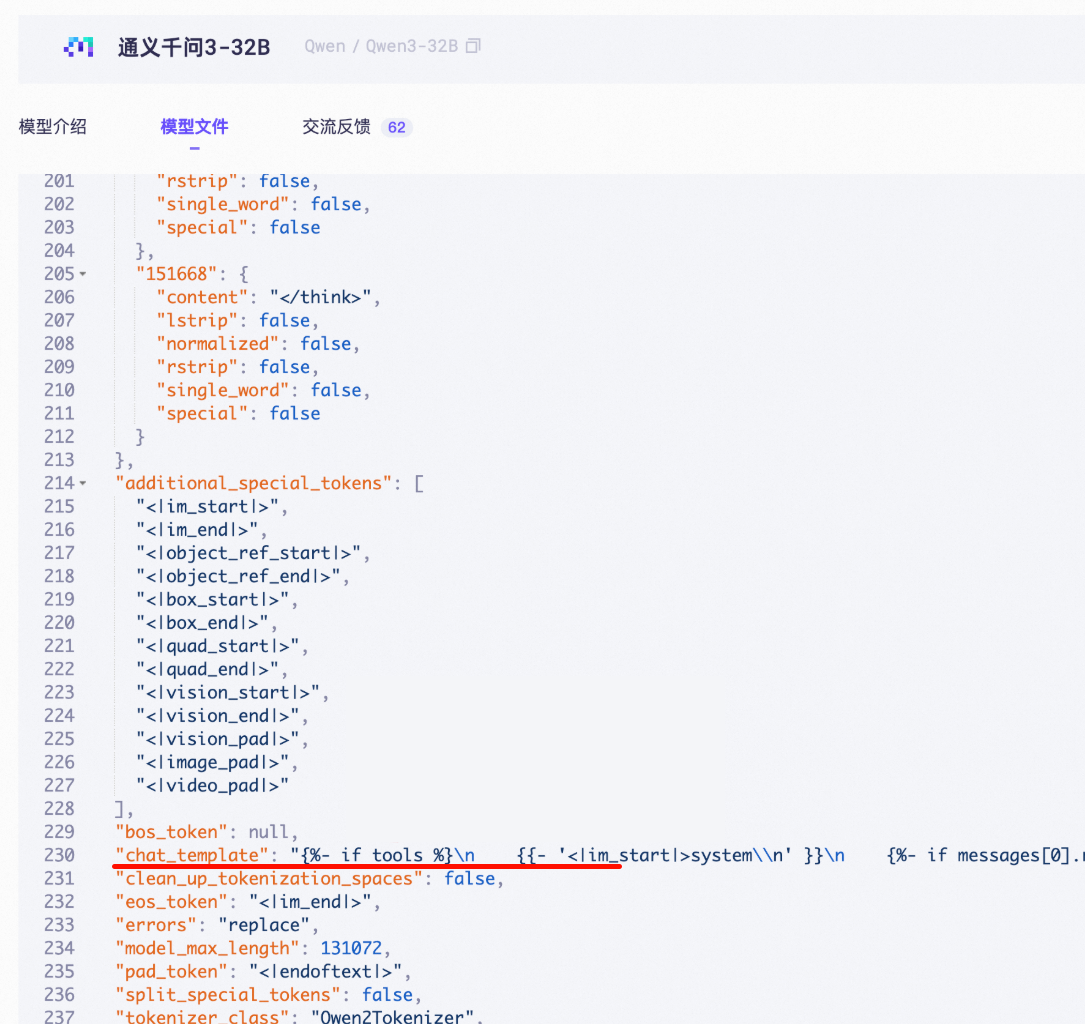
-
-
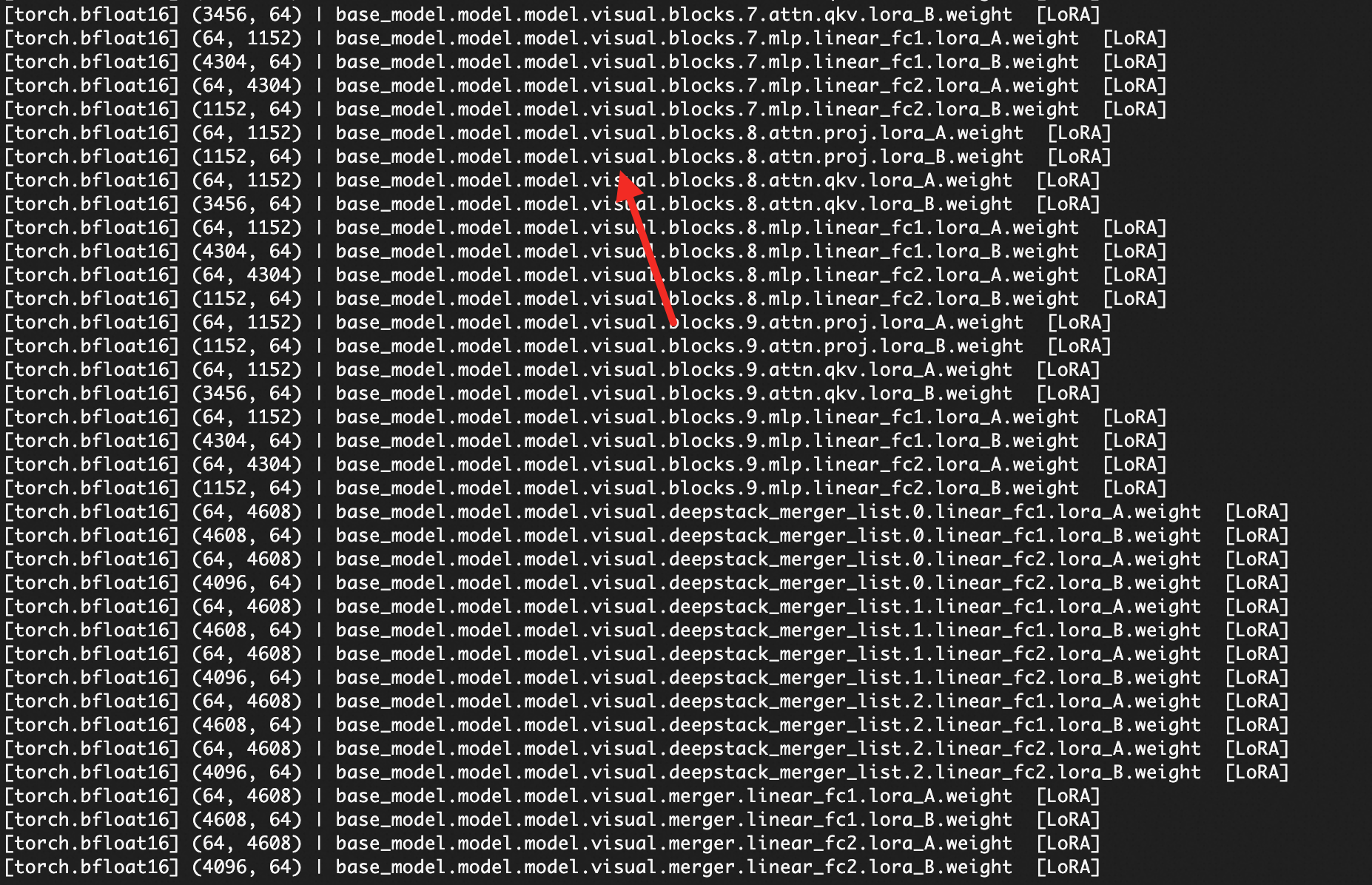
未冻结 VIT 的视觉语言模型:对于 VL(Vision-Language)模型,必须冻结 Vision Transformer(VIT)部分。如果 LoRA adapter 中包含 visual 相关的权重参数(即未冻结 VIT),该模型无法导入。
可以运行以下代码判断。
from safetensors import safe_open import argparse def print_safetensor_structure(file_path): print(f"Loading safetensor file: {file_path}") print("="*80) with safe_open(file_path, framework="pt") as f: keys = f.keys() print(f"Found {len(keys)} tensors in the file:\n") for key in sorted(keys): tensor = f.get_tensor(key) shape = tuple(tensor.shape) dtype = str(tensor.dtype) device = tensor.device if hasattr(tensor, 'device') else 'cpu' lora_tag = " [LoRA]" if "lora_A" in key or "lora_B" in key else "" print(f"[{dtype:>14}] {shape} | {key} {lora_tag}") if __name__ == "__main__": parser = argparse.ArgumentParser(description="Print structure of a .safetensors LoRA adapter.") parser.add_argument("filepath", type=str, help="Path to the .safetensors file") args = parser.parse_args() print_safetensor_structure(args.filepath)判断方法:检查 adapt_model.safetensors 文件中是否包含
visual相关的权重参数。如果文件中存在以visual开头的参数键(例如visual.encoder.layer.0...),说明 VIT 部分未被冻结,该模型无法导入。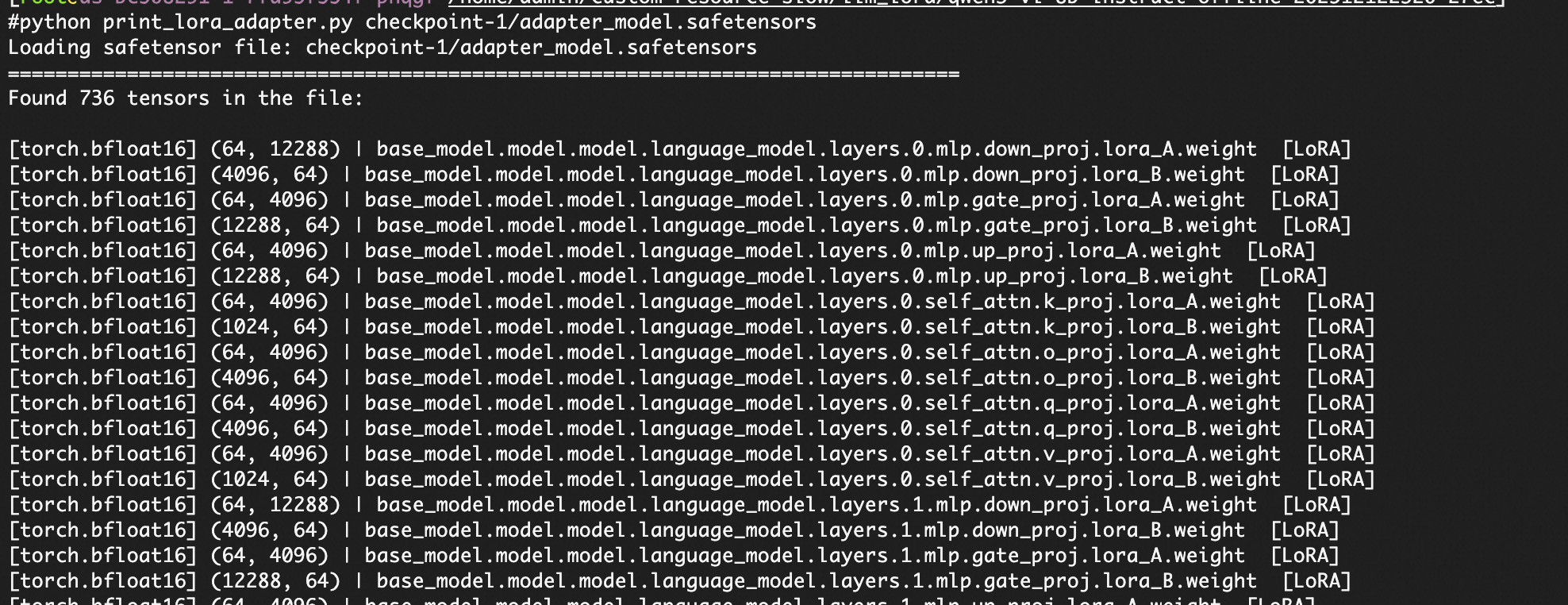
常见问题
为什么导入的模型与本地使用 vLLM、SGLang 推理的效果不一致?
百炼平台的推理引擎参数设置可能与您本地使用的推理框架默认值不同。为确保效果一致,建议在调用 API 时调整以下参数:
|
参数名称 |
推荐值(对应 vLLM 默认值) |
|
temperature |
取值范围:[0, 2)。设置为 1.0 等同于 vLLM 引擎默认值。 |
|
top_p |
取值范围:(0, 1.0]。设置为 1.0 等同于 vLLM 引擎默认值。 |
|
top_k |
取值为 None 或大于 100 时,表示不启用 top_k 策略,此时仅有 top_p 策略生效。设置为 99 不支持全采样,该值接近 vLLM 默认值 0(全采样)。 |
|
presence_penalty |
取值范围:[-2.0, 2.0]。设置为 0 等同于 vLLM 引擎默认值。 |
|
repetition_penalty(DashScope 协议) |
提高 repetition_penalty 可以降低模型生成的重复度,1.0 表示不做惩罚。取值范围:大于 0。设置为 1.0 等同于 vLLM 引擎默认值。 |
说明:以上参数值基于 vLLM 引擎的默认配置。如果您的本地环境使用 SGLang 或其他推理框架,请参考对应框架的文档调整参数。
如果您是首次从 OSS 向阿里云百炼导入文件,请先按照界面提示完成授权,并为目标 OSS Bucket 添加bailian-datahub-access标签,然后再进行导入。
如果您尚不清楚主账号和子账号的概念和区别,请先阅读权限管理。
使用主账号
-
单击前往授权。
在导入来源中选择从OSS导入后,页面会显示"您还未授权OSS"的提示信息,在提示栏右侧找到 前往授权 链接。
-
在弹出的对话框中,单击确认授权,系统将为您自动开通OSS服务关联角色(必要条件)。
通常秒级生效,服务高峰期可能会稍有延迟。
-
为目标 OSS Bucket 添加
bailian-datahub-access标签。该标签用于标记阿里云百炼可访问的 Bucket,未标记的 Bucket 阿里云百炼无法访问。
-
访问OSS管理控制台,单击左侧导航栏中的Bucket 列表,即可查看您已创建的Bucket。
-
在待添加标签的Bucket标签列,悬停鼠标于
 图标上,然后单击前往编辑。
图标上,然后单击前往编辑。 -
单击创建标签。
-
单击标签,添加标签名为
bailian-datahub-access,标签值为read的标签,然后单击保存。
-
-
返回导入模型界面,重新选择目标 Bucket 再尝试导入。
请注意,阿里云百炼不支持访问保存在 Bucket 根目录下的文件。请您选择 Bucket 下的现有文件夹或新建一个文件夹供阿里云百炼访问。
使用子账号
-
单击前往授权。
-
在弹出的对话框中,单击确认授权。界面会提示授权失败、当前用户没有创建服务关联角色的权限(因为当前子账号没有创建服务关联角色的权限。接下来需要先授予子账号创建服务关联角色的权限,再授予子账号通过阿里云百炼访问OSS的权限)。
对话框中显示 Service Name 为
datahub.sfm.aliyuncs.com,服务关联角色名称为AliyunServiceRoleForSFMDataHubOSSImport,执行该操作所需的用户权限为ram:CreateServiceLinkedRole。 -
授予子账号创建服务关联角色的权限。
-
需主账号登录RAM控制台,在左侧导航栏,选择,然后单击界面上的创建权限策略。
-
在脚本编辑的
Effect、Action、Resource、Condition中分别输入以下脚本中的对应内容后,单击确定。{ "Action": [ "ram:CreateServiceLinkedRole" ], "Resource": "*", "Effect": "Allow", "Condition": { "StringEquals": { "ram:ServiceName": "datahub.sfm.aliyuncs.com" } } } -
输入权限策略名称后,单击确定。
本示例中,权限策略名称为
服务关联角色。 -
在左侧导航栏,选择。在页面列表中找到待授权的子账号,然后单击子账号操作列的添加权限。
-
在权限策略中选择刚才创建的权限策略(自定义策略),单击确认新增授权。至此,子账号拥有了创建服务关联角色的权限。
-
-
授权子账号通过阿里云百炼访问OSS。
-
返回导入模型界面,单击前往授权。
在导入来源中选择从OSS导入后,界面提示您还未授权OSS。
-
在弹出的对话框中,单击确认授权,系统将为您自动开通OSS服务关联角色(必要条件)。
通常秒级生效,服务高峰期可能会稍有延迟。
-
-
为目标 OSS Bucket 添加
bailian-datahub-access标签。该标签用于标记阿里云百炼可访问的 Bucket,未标记的 Bucket 阿里云百炼无法访问。
-
访问OSS管理控制台,单击左侧导航栏中的Bucket 列表,即可查看您已创建的Bucket。
-
在待添加标签的Bucket标签列,悬停鼠标于
 图标上,然后单击前往编辑。
图标上,然后单击前往编辑。 -
单击创建标签。
-
单击标签,添加标签名为
bailian-datahub-access,标签值为read的标签,然后单击保存。
-
-
返回导入模型界面,重新选择目标 Bucket 再尝试导入。
请注意,阿里云百炼不支持访问保存在 Bucket 根目录下的文件。请您选择 Bucket 下的现有文件夹或新建一个文件夹供阿里云百炼访问。