
本文介绍 PTU(预置吞吐)部署的长输入和前缀缓存能力,包括额度消耗规则、容量计算器使用方法和 API 响应字段说明。
功能概述
PTU 部署支持长输入请求(部分模型最高 200K token)和前缀缓存,通过阶梯容量系数和缓存折扣灵活管理额度消耗。
核心能力:
-
长输入支持:部分模型支持超过 32K token 的输入,超出部分按更高的阶梯系数折算 TPM(每分钟 Token 数)消耗,详见额度消耗规则。
-
前缀缓存优惠:部分模型支持前缀缓存,命中缓存的输入 token 按折扣系数消耗额度(具体折扣率因模型而异),可降低多轮对话和重复前缀场景的额度消耗。
-
自动转按量计费:超出 PTU 额度或输入超过模型上限(千问 128K / DeepSeek 64K)时,请求自动转为按量计费,无需修改调用代码。
自动转按量计费后,费用按对应模型的按量付费单价计算。建议通过容量计算器合理规划 PTU 额度,避免意外费用。
常见于长文档分析(合同、研报摘要)和多轮对话(客服、编程助手)等输入超 32K token 的场景。
额度消耗规则
长输入阶梯系数和缓存折扣按模型不同,以下为当前支持的模型参数:
|
模型 |
输入长度上限 |
缓存折扣 |
长输入阶梯系数 |
|
glm-5.1 |
200K |
0.2(缓存命中部分按 20% 折算容量) |
[0, 32K):输入 1.0 / 输出 1.0 |
|
deepseek-v4-pro |
256K |
0.08(缓存命中部分按 8% 折算容量) |
无阶梯(1.0) |
|
qwen3.7-plus-2026-05-26 |
256K |
0.2(缓存命中部分按 20% 折算容量) |
无阶梯(1.0) |
|
其他模型 |
以控制台为准 |
暂不支持 |
无阶梯(1.0) |
计算示例(以 glm-5.1 为例)
场景 1:短输入(10K token,无缓存)
输入消耗:10K × 1.0 = 10KTPM
场景 2:长输入(50K token,无缓存)
输入消耗:32K × 1.0 + 18K × 1.33 = 55.94 KTPM
输出消耗(假设 1K token):1K × 1.17 = 1.17 KTPM
场景 3:长输入 + 缓存命中(50K token,前 30K 命中缓存)
缓存部分输入(前 30K,均在 [0,32K) 阶梯内):
30K × 1.0 × 0.2 = 6 KTPM
非缓存部分输入(后 20K):
2K × 1.0 + 18K × 1.33 = 25.94 KTPM
输入合计 = 31.940 KTPM(比无缓存节省 43%)使用容量计算器估算额度
建议在创建或扩容前使用计算器评估长输入场景的额度需求,避免额度不足导致请求转为按量计费。购买上限以控制台实际展示为准。
前提条件:已开通百炼服务并具备 PTU 部署权限。登录百炼控制台,在模型部署 > 创建部署页面(或在已有部署详情页单击扩容),选择可部署的PTU(预置吞吐)模型后,展开容量计算器。
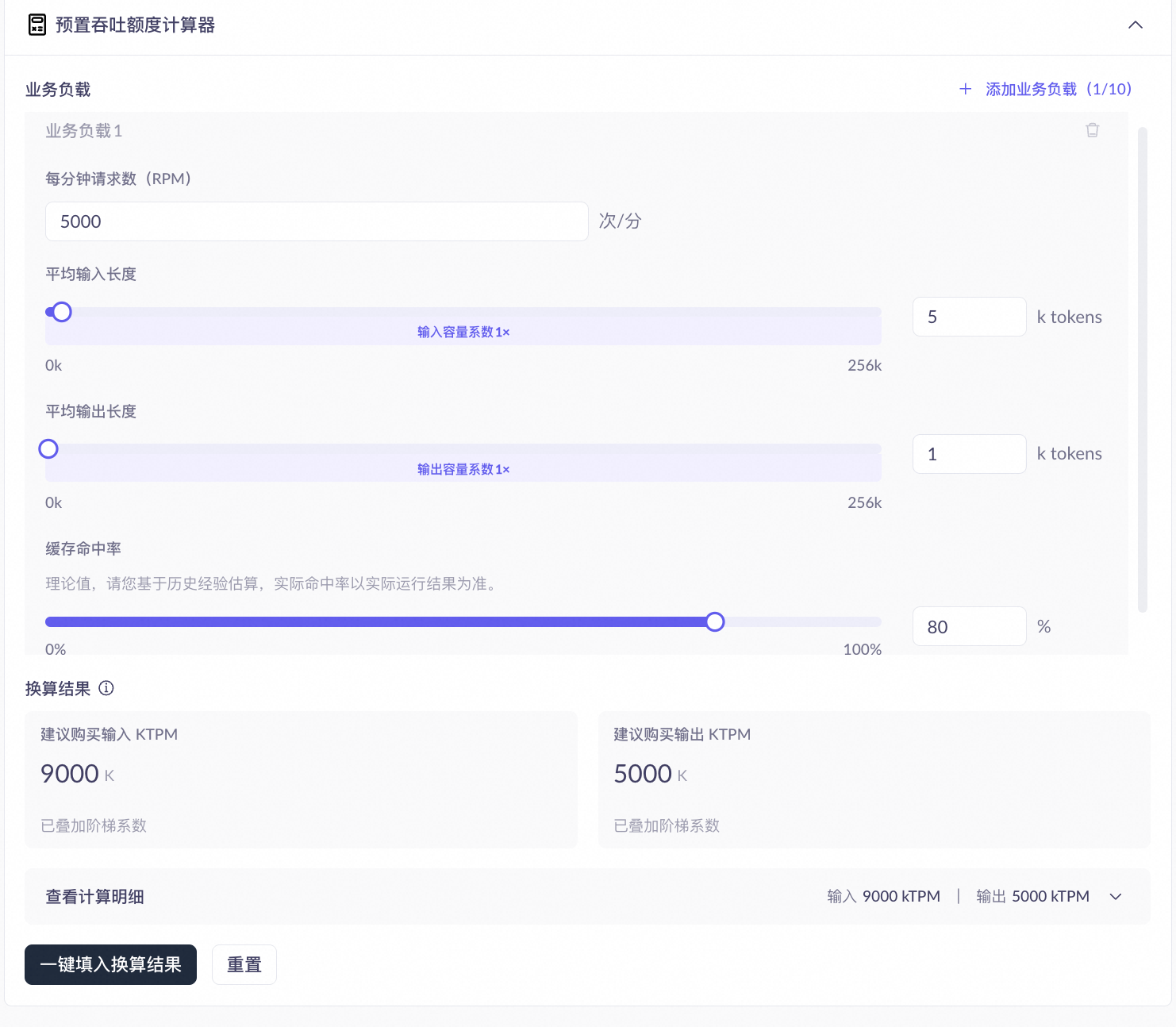
容量计算器根据业务负载自动推荐 TPM 额度。填写以下参数后,计算器输出推荐的输入 TPM 和输出 TPM。
|
参数 |
说明 |
对结果的影响 |
|
每分钟请求数(RPM) |
业务高峰期每分钟的请求数。 |
RPM 越大,建议购买的输入和输出 TPM 同比增大。 |
|
平均输入长度(token) |
每条请求的平均输入 token 数。 |
输入越长,所处阶梯越高,系数越大,建议购买的输入 TPM 越高。不同模型的阶梯边界不同,以控制台实际展示为准。 |
|
平均输出长度(token) |
每条请求的平均输出 token 数。 |
输出越长,系数可能越大,建议购买的输出 TPM 越高。 |
|
预估缓存命中率(%) |
请求中重复前缀被缓存命中的比例。实际命中率取决于请求内容的重复程度,以运行结果为准。 |
命中率越高,输入容量消耗越慢,建议购买的输入 TPM 越低。仅影响输入 TPM,不影响输出 TPM。 |
API 响应字段说明
PTU 部署的 API 响应包含以下额度相关字段,用于标识计费方式和额度消耗:
|
字段 |
类型 |
说明 |
|
|
String |
响应体顶层字段(所有 API 格式一致)。值为 |
|
|
Integer |
折算后实际消耗的 PTU 额度 token 数(已含阶梯系数和缓存折扣) |
|
|
Integer |
前缀缓存命中的 token 数,详见上下文缓存 |
不同 API 格式下上述字段的 JSON 路径存在差异:
OpenAI Chat 兼容
|
字段 |
JSON 路径 |
说明 |
|
|
|
输入侧缓存命中数 |
|
|
|
输入侧 PTU 额度消耗 |
|
|
|
输出侧 PTU 额度消耗 |
OpenAI Responses
|
字段 |
JSON 路径 |
说明 |
|
|
|
输入侧缓存命中数 |
|
|
|
输入侧 PTU 额度消耗 |
|
|
|
输出侧 PTU 额度消耗 |
Anthropic 兼容
|
字段 |
JSON 路径 |
说明 |
|
|
|
输入侧 PTU 额度消耗 |
|
|
|
输出侧 PTU 额度消耗 |
Anthropic 兼容格式暂不返回 cached_tokens 字段,可通过 provisioned_tokens 间接判断缓存效果。
DashScope
|
字段 |
JSON 路径 |
说明 |
|
|
|
输入侧缓存命中数 |
|
|
|
输入侧 PTU 额度消耗 |
|
|
|
输出侧 PTU 额度消耗 |
各字段的完整定义和取值范围,请参见API 参考文档。
监控与验证
-
PTU 利用率:输入/输出/思考模式输出三条独立曲线。长输入场景下阶梯系数会使利用率超过 100%,属于正常现象。
-
Token 用量与缓存命中:包含
cached_tokens数据系列,可查看缓存命中量占总输入的比例。 -
配额内/外调用次数:了解超出 PTU 额度后转为按量计费的请求占比。
更多监控指标和操作方式,请参见模型监控。