
本文档介绍阿里云百炼强化学习训练服务的功能特性、使用方法及配置说明。
1. RL训练数据格式
本节说明强化学习训练所需的数据格式规范。
1.1 数据格式说明
样例数据:
{
"messages": [{
"content": "Betty is saving money for a new wallet which costs $100. Betty has only half of the money she needs. Her parents decided to give her $15 for that purpose, and her grandparents twice as much as her parents. How much more money does Betty need to buy the wallet? Let's think step by step and output the final answer after \"####\".",
"role": "user"
}],
"extra_params": {
"solution": "5"
}
}字段说明:
训练集与验证集使用相同的数据格式。
字段名称 | 类型 | 描述 | 是否必传 | 示例 |
messages | JSON Array | 输入的对话数据,采用标准 Chat 格式,支持多轮对话。 | 是 | [{ "content": "Betty is ...", "role": "user" }] |
extra_params | JSON Object | 这条数据用于计算奖励相关的额外信息 | 是 | { "solution": "5" } |
2. HTTP 形式自定义奖励函数
系统通过 HTTP POST 请求调用您部署在函数计算(FC)中的奖励函数服务。请求体和响应体均为 JSON 格式。
2.1 奖励函数接口规范
入参样例数据:
{
'data': {
"prompts": "xxx",
"response": "aaa",
"extra_params": {"gt": "aaa"},
"request_id": "xxx"
}
}入参字段说明:
字段名称 | 类型 | 描述 | 是否必传 | 示例 |
prompts | JSON Array | 训练输入的对话数据,格式与训练数据中的 messages 字段一致,支持多轮对话。 | 是 | [{ "content": "Betty is ...", "role": "user" }] |
response | String | 模型在 rollout 阶段进行前向推理生成的响应内容。 | 是 | #####5 |
extra_params | JSON Object | 用于奖励计算的额外参数信息,由训练数据中的 extra_params 字段传递。 | 是 | { "solution": "5" } |
request_id | String | 请求id | 是 | ab45648c4d-d3ed4s-d13erw4 |
返回值样例数据:
{
'data': {
'status': 'success' # scucess表示成功,fail表示失败
'score': '1.0'
}
}返回值字段说明:
字段名称 | 类型 | 描述 | 是否必须 | 示例 |
status | string | 奖励计算处理状态,success 表示成功,fail 表示失败。 | 是 | success/failed |
score | String | 奖励分数值,字符串类型的浮点数。即使处理失败,也建议返回一个默认奖励值。 | 是 | 1.0 |
2.2 异常处理机制
当奖励函数调用失败时,系统会自动进行重试。
超过最大重试次数后,该请求的奖励值将被设置为默认值。
当请求总数超过阈值且失败率超过阈值时,训练任务将立即终止。
3. 函数计算 HTTP 格式奖励函数配置
3.1 创建和配置函数
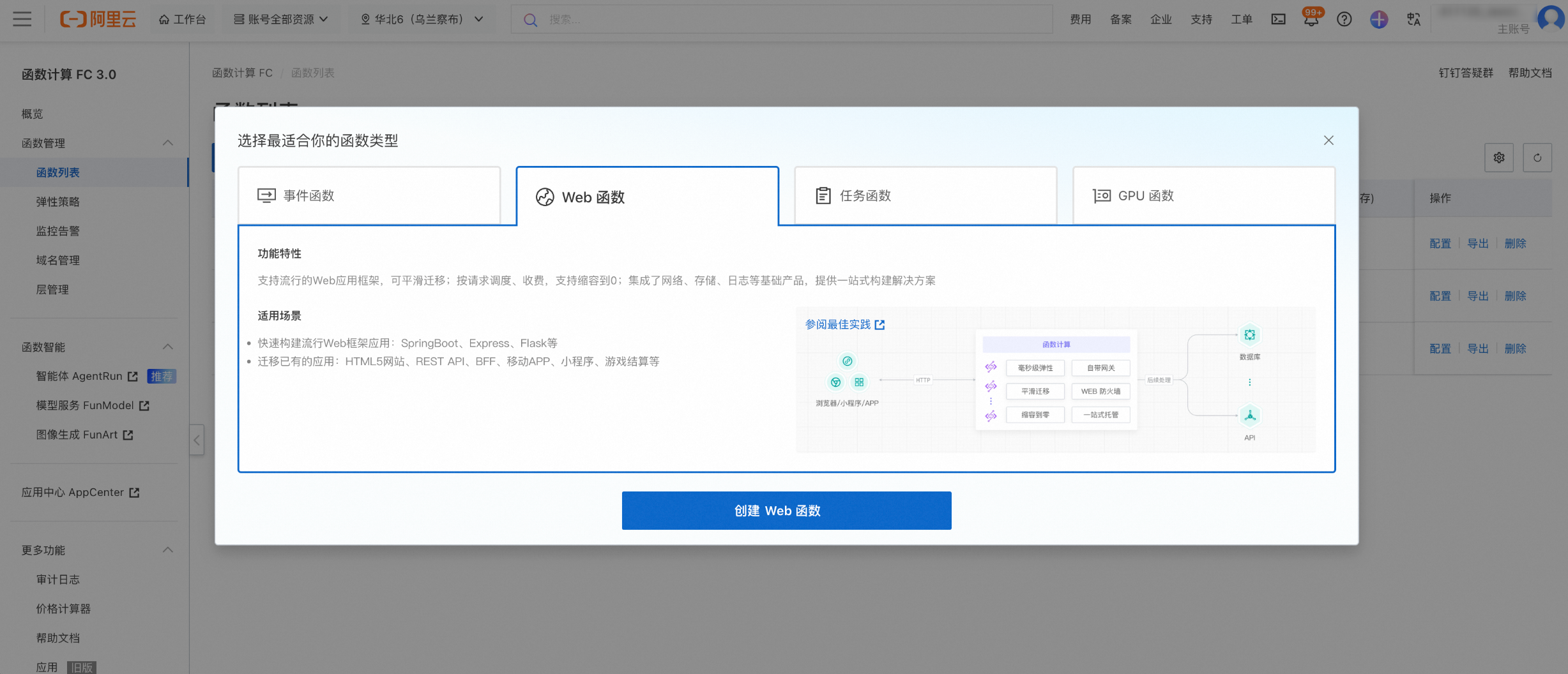
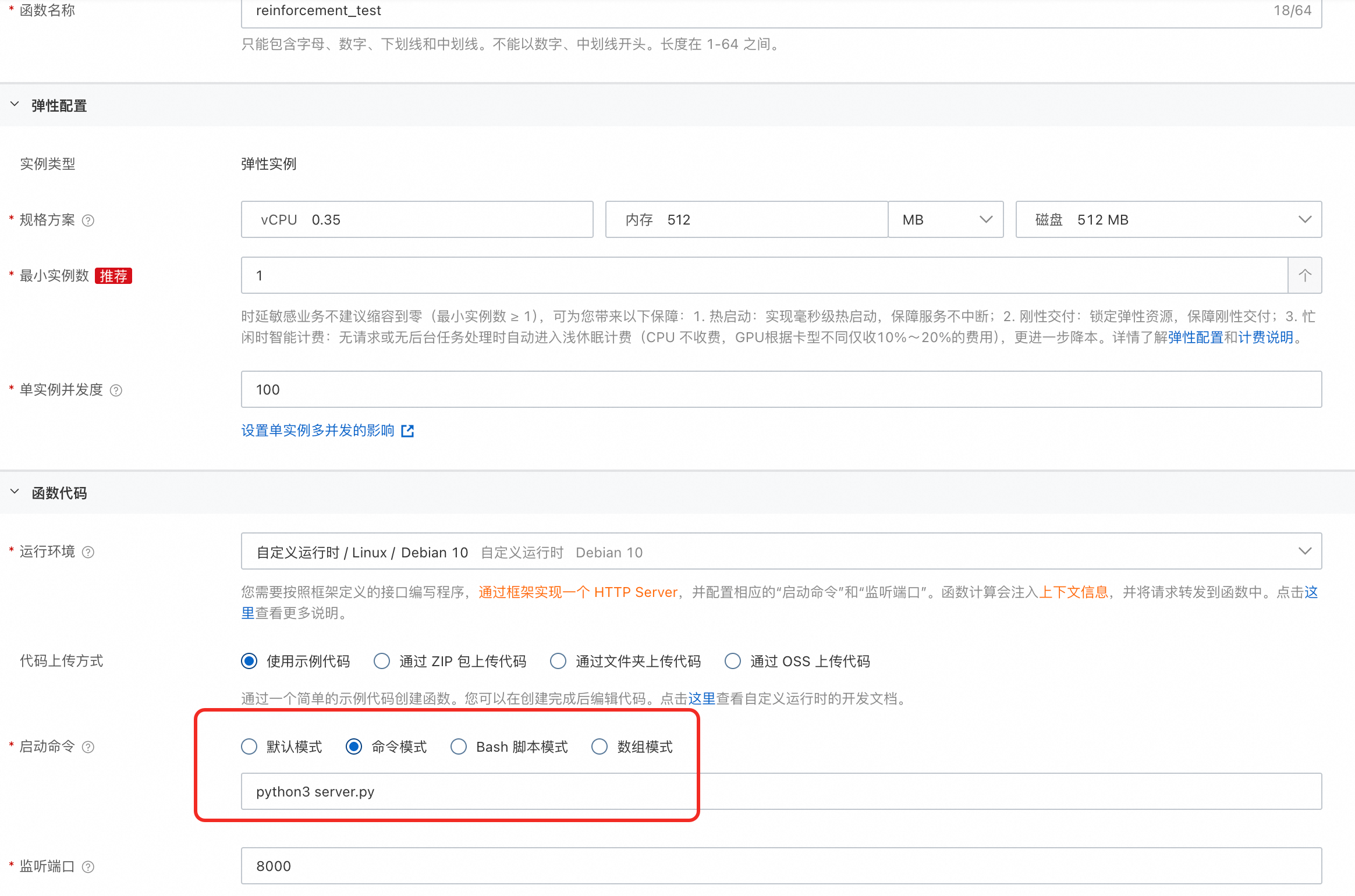
登录函数计算控制台,选择地域为乌兰察布(必选),创建 Web 函数。将启动文件设置为 server.py(百炼提供的组件默认启动文件),监听端口设置为 8000。您可以在创建后配置弹性伸缩策略,当并发水位或系统水位达到阈值时自动扩容。
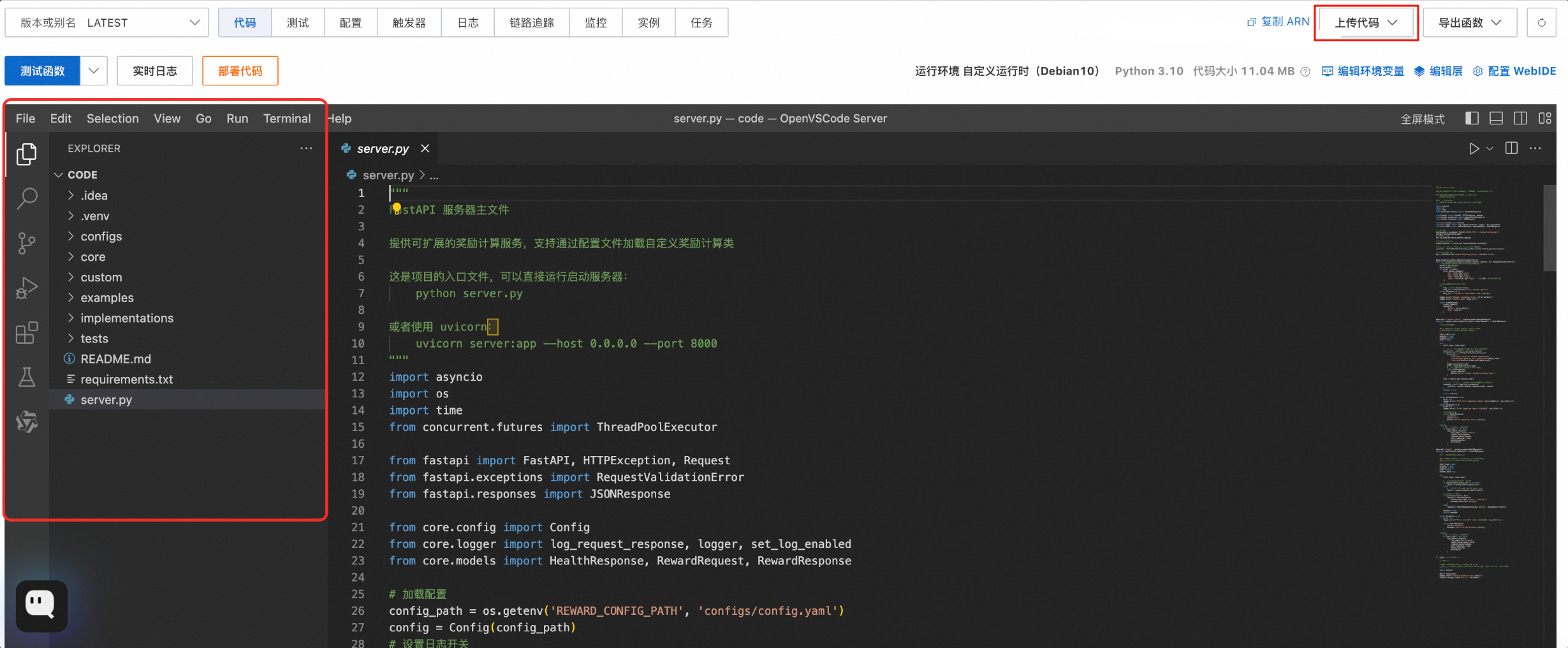
3.2 上传代码和安装依赖
上传奖励函数组件代码(详见第6章),然后在 package 目录中安装依赖包,并配置 Python 环境变量。
mkdir package
pip install fastapi -t .
pip install pyyaml -t .
pip install uvicorn -t .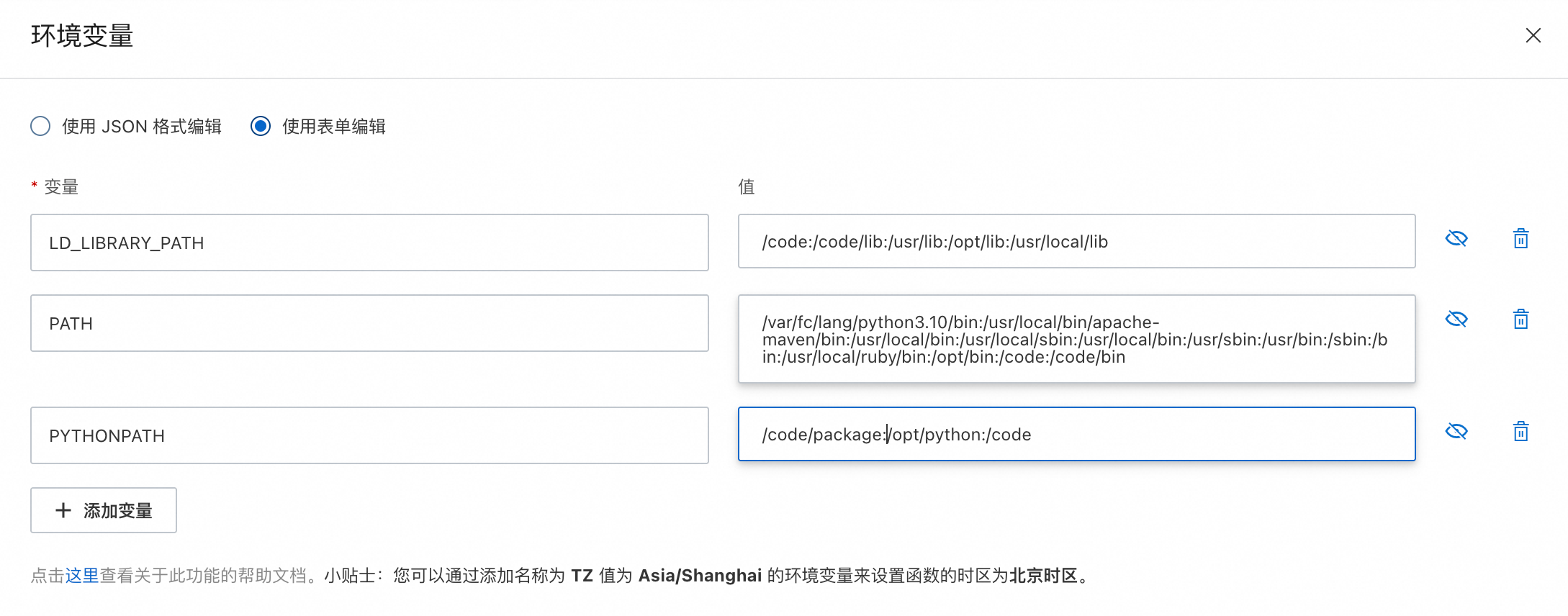
3.3 配置触发器和部署
配置触发器:关闭公网访问,选择 Bearer 认证方式。请记录访问地址和 Token,在发起强化学习训练时需要传入。配置完成后,部署代码。
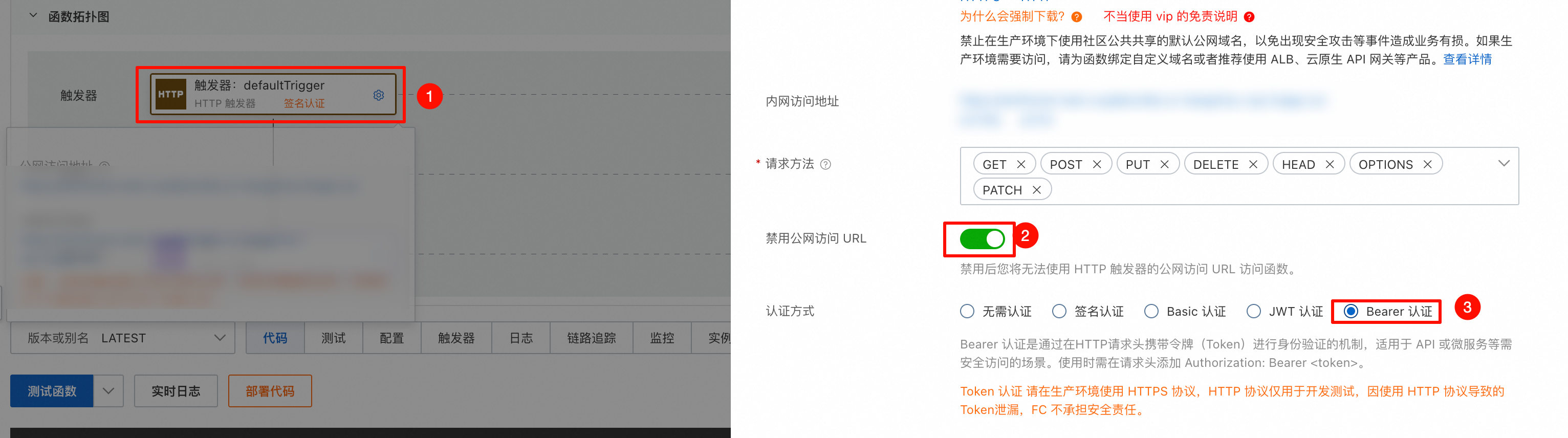
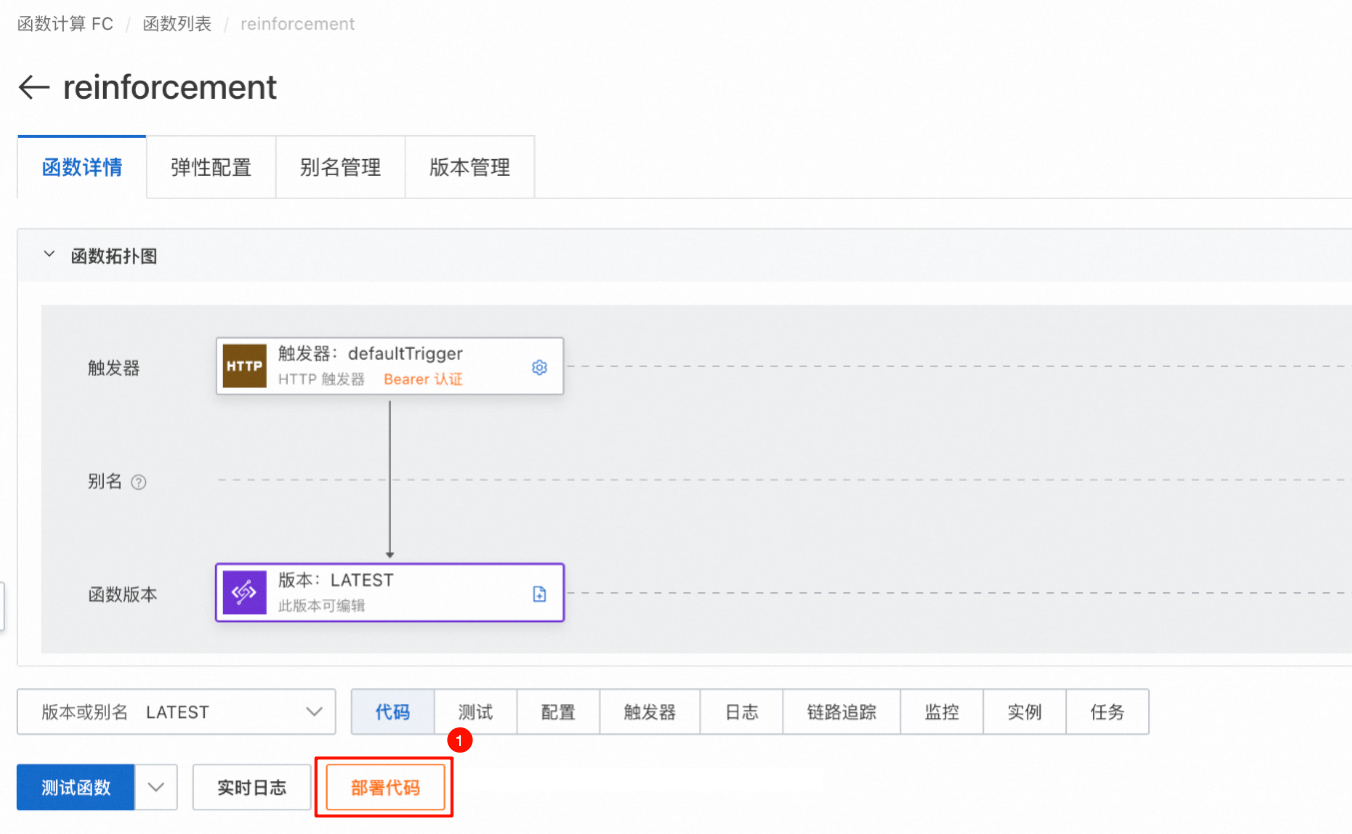
3.4 测试和弹性配置
curl -X POST https://reinforcement-lgyqqulpla.cn-wulanchabu.fcapp.run/compute_reward \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer tokenData-280j0hede8e0i2467c1697dgd1c8' \
-d '{
"request_id": "test-001",
"messages": [
{"role": "user", "content": "What is 6 multiplied by 7?"},
{"role": "assistant", "content": "Let me think..."}
],
"response": "The answer is 42",
"extra_params": {
"reward_func_type": "regex_match",
"solution": "42",
"regex_match_str": "-?\\d+\\.?\\d*"
}
}'测试说明:您可以在乌兰察布地域通过内网域名或公网域名进行测试。为提升访问速度,建议使用内网域名,并使用 HTTP 协议(非 HTTPS)。
返回值:
{"score":1.0,"status":"success","extra_info":{"reward_func_type":"regex_match","method":"regex_match","regex_pattern":"-?\\d+\\.?\\d*"},"detail":null}
您可以根据业务需求创建自定义弹性伸缩策略,建议配置基于并发水位或系统水位的自动伸缩策略。
4. 训练 API
本节说明强化学习训练 API 的接口规范、请求参数及响应格式。
4.1 发起训练和超参配置
接口名称:api/v1/fine-tunes
文档参考:查询调优任务详情
训练类型:reinforcement
超参及其介绍:
超参名称 | 中文名称 | 是否必填 | 描述 | 示例 |
algorithm | 算法类型 | 是 | 强化学习算法类型,指定训练使用的策略优化方法(当前支持gspo/grpo) | gspo |
batch_size | 批次大小 | 否 | 批次大小,表示模型训练过程中每次更新参数前处理的数据样本数量。批次大小越大,模型更新频率越低,但每次更新的稳定性越高。 | 512 |
eval_steps | 验证步数 | 否 | 验证步数,训练过程中进行模型验证的间隔步长,用于阶段性评估模型的准确率和训练损失。 | 50 |
kl_loss_coef | KL损失系数 | 否 | KL 散度损失系数,用于平衡策略更新的稳定性与探索性。该系数控制新旧策略之间的差异程度。 | 0.001 |
learning_rate | 学习率 | 否 | 学习率,控制模型参数更新的步长。学习率越大,参数更新幅度越大,对模型的影响越显著。 | 7e-6 |
lr_scheduler_type | 学习率调整策略 | 否 | 学习率调整策略,用于在训练过程中动态调整学习率大小,以优化训练效果。 | linear |
max_length | 序列长度 | 否 | 序列长度,单个训练数据样本的最大长度限制。超出该长度的样本将被丢弃。 | 131072 |
max_prompt_length | 最大提示长度 | 否 | 最大提示长度,输入提示(prompt)的最大长度限制。超出该长度的部分将被截断。 | 2048 |
max_response_length | 最大响应长度 | 否 | 最大响应长度,模型输出响应的最大长度限制。超出该长度的部分将被截断。 | 2048 |
n_epochs | 循环次数 | 否 | 训练轮数,表示模型完整遍历训练数据集的次数。 | 3 |
reward_func_address | 奖励函数地址 | 是 | 奖励函数的 HTTP 服务端点地址,用于调用奖励计算服务。 | http://rl-ohxiruizxe.cn-wulanchabu-vpc.fcapp.run/compute_reward |
reward_func_fail_count_threshold | 奖励函数失败次数阈值 | 是 | 奖励函数失败次数阈值,当累计失败次数超过该阈值时,系统将触发告警。 | 1000 |
reward_func_fail_threshold | 奖励函数失败率阈值 | 是 | 奖励函数失败率阈值,当失败率超过该阈值时,系统将触发告警。 | 0.9 |
reward_func_max_retries | 奖励函数最大重试次数 | 是 | 奖励函数最大重试次数,当调用失败时,系统将自动重试,最多重试指定次数。 | 2 |
reward_func_timeout | 奖励函数超时时间 | 是 | 奖励函数请求超时时间(单位:毫秒),超过该时间未响应则视为超时,请求将被丢弃。 | 2000 |
reward_func_token | 奖励函数令牌 | 是 | 奖励函数认证令牌(Token),用于访问 HTTP 奖励函数服务的身份认证。 | *** |
reward_func_type | 奖励函数类型 | 是 | 奖励函数类型,指定奖励计算方式。当前仅支持 http_reward(通过 HTTP 接口调用奖励函数)。 | http_reward |
split | 数据划分比例 | 否 | 数据集划分比例(取值范围 0-1),用于指定训练集与验证集的分割比例。设置为 0 表示训练集与验证集使用相同数据。 | 0 |
rollout_number | rollout数量 | 否 | rollout 数量,表示每次策略更新前,模型与环境交互生成的轨迹(episode)数量。 | 5 |
5. 自定义奖励函数组件
5.1 组件库和代码库结构
组件库源码:reward.zip

5.2 自定义奖励函数基类和示例
"""
奖励计算基类
所有自定义奖励计算类都应该继承此基类
"""
from abc import ABC, abstractmethod
from core.models import RewardRequest, RewardResponse
class BaseRewardComputer(ABC):
"""
奖励计算基类
所有自定义奖励计算类必须继承此类并实现 compute_reward 方法
"""
@abstractmethod
def compute_reward(self, request: RewardRequest) -> RewardResponse:
"""
计算奖励分数(必须实现)
Args:
request: 奖励计算请求
Returns:
奖励计算响应
"""
pass
def health_check(self) -> dict:
"""
健康检查(可选实现)
如果子类需要自定义健康检查逻辑,可以重写此方法。
默认返回健康状态。
Returns:
包含 status 和可选 message 的字典
"""
return {'status': 'healthy'}
实现示例:以下示例展示如何实现一个基于响应长度的奖励函数,使模型倾向于生成更长的响应内容。
"""
自定义奖励计算实现示例
展示如何创建自定义奖励计算类
"""
from core.base_reward import BaseRewardComputer
from core.models import RewardRequest, RewardResponse
class CustomRewardComputer(BaseRewardComputer):
"""
自定义奖励计算类示例
继承 BaseRewardComputer 并实现 compute_reward 方法
"""
def compute_reward(self, request: RewardRequest) -> RewardResponse:
"""
自定义奖励计算逻辑
Args:
request: 奖励计算请求
Returns:
奖励计算响应
"""
try:
# 示例:基于响应长度的简单奖励计算
response_length = len(request.response)
extra_params = request.extra_params
# 你的自定义逻辑
if response_length > 100:
score = 0.9
elif response_length > 50:
score = 0.7
else:
score = 0.5
# 可以访问 extra_params 来获取额外参数
custom_param = extra_params.get('custom_param', 'default')
return RewardResponse(
score=score,
status='success',
extra_info={
'custom_logic': True,
'response_length': response_length,
'custom_param': custom_param
}
)
except Exception as e:
# 异常处理:返回错误响应
return RewardResponse(
score=0.0,
status='fail',
detail=f'Error in custom compute_reward: {str(e)}'
)
def health_check(self) -> dict:
"""
自定义健康检查(可选)
Returns:
包含 status 和可选 message 的字典
"""
return {
'status': 'healthy',
'message': 'Custom reward computer is healthy'
}
5.3 系统及奖励函数配置
系统默认从 configs/config.yaml 文件中加载配置。
# 奖励计算服务配置文件
# 服务器配置
server:
# 监听端口,默认 8000
port: 8000
# 奖励计算配置
reward:
# 自定义奖励计算类的完整路径
# 格式: "module.path:ClassName"
# 该类必须继承自 BaseRewardComputer
# 如果不配置,则使用默认实现 (DefaultRewardComputer)
class: "implementations.default_reward:DefaultRewardComputer"
# 健康检查配置(可选)
health_check:
# 自定义健康检查函数的完整路径
# 格式: "module.path:function_name"
# 函数应该返回包含 'status' 键的字典
# 如果不配置,则使用奖励计算类的 health_check 方法
# function: "custom_module:custom_health_check"
# 日志配置
logging:
# 是否启用日志输出,默认 true
enable: true
# 线程池配置(可选)
# 用于 compute_reward 的并行计算
thread_pool:
# 线程池最大线程数(>0 的整数)
# 建议根据机器 CPU 核数和负载调整
max_workers: 600
# 允许排队等待的最大请求数(>0 的整数)
# 达到该上限后新请求将直接返回 HTTP 失败响应
queue_size: 600
6. gsm8k 训练数据集
6.1 训练集和测试集
训练集:rl-train.jsonl
测试集:rl-test.jsonl
6.2 训练结果

7. 模型支持列表
类型 | 系列 | 模型 |
文本模型 | Qwen 2.5系列 | qwen2.5-7b-instruct |
qwen2.5-14b-instruct | ||
qwen2.5-32b-instruct | ||
Qwen 3系列 | qwen3-8b | |
qwen3-14b | ||
qwen3-32b | ||
qwen3-8b-base | ||
qwen3-14b-base | ||
qwen3-32b-base |
说明:基于已训练的模型继续进行 GRPO、SFT、DPO 或 CPT 训练时,只需指定训练后的模型标识即可。