
本文通过端到端示例帮助您快速完成第一个强化学习(RL) 训练任务的提交与监控。
RL 训练全流程概览
RL 训练从环境准备到模型部署,共 5 步:
-
环境准备 — 安装离线 SDK、获取 API Key、完成 RL 授权
-
准备数据与代码 — 下载 Demo 包,了解数据格式与项目结构
-
提交训练任务 — 运行 Demo 一步完成函数部署、数据上传、任务提交
-
训练状态观测 — 查看训练状态、日志和 Reward 趋势
-
发布与部署模型 — 发布 Checkpoint 至"我的模型",部署后通过 API 调用
RL 训练原理
RL 训练通过"生成-评分-优化"循环不断提升模型能力。每轮训练的数据流如下:
训练数据(用户问题 + 参考答案)
│
▼
策略采样(Rollout):模型按当前策略生成候选结果
│
▼
奖励评分(Reward):对比参考答案,给出 0~1 分(可以合并到 Rollout)
│
▼
策略更新:根据奖励信号,强化高分策略、抑制低分策略
│
▼
循环迭代:用更新后的模型重新采样,逐轮提升质量
支持的模型
|
模型名称 |
模型 code |
是否为 MoE(混合专家)模型 |
推荐的模型训练单元数量 |
|
千问3.5-9B |
qwen3.5-9b |
否 |
IV型模型单元 * 24 |
|
千问3.5-35B-A3B |
qwen3.5-35b-a3b |
是 |
- |
训练单元价格
|
计费方式 |
说明 |
计费公式 |
|
训练单元·预付费 |
按月购买模型训练单元,使用专属训练资源,训练速度更快,无需排队等待。 最小计费粒度:小时。提前退订按小时单价的 1.2 倍计费。 如需购买或管理预付费训练单元,可在模型调优控制台点击管理训练资源。 |
|
|
训练单元·后付费 |
使用专属训练资源,训练速度更快,无需排队等待。按实际使用时长计费,创建任务时直接开通,无需预先购买。 |
|
|
训练单元类型 |
计费方式 |
单价 |
最小计费粒度 |
|
IV 型(MTU4) |
预付费(包月) |
19,914.00 元/月/实例 |
1 小时 |
|
后付费(按分钟) |
41.00 元/小时/实例 |
1 分钟 |
预付费扩缩容、续费、退订等运营规则与具体 MTU 容量测算请联系商务经理。
环境准备
RL 训练仅支持通过模型训练单元(MTU)计费,不支持按 Token 计费方式。
按照以下步骤完成环境配置:
-
获取 API Key:在百炼控制台获取 DashScope API Key。
-
完成 RL 服务授权:在百炼控制台的模型调优页面完成一键授权。首次使用 RL 训练时,控制台会提示授权阿里云 OpenTelemetry、函数计算(FC)和日志服务(SLS)两项云服务。
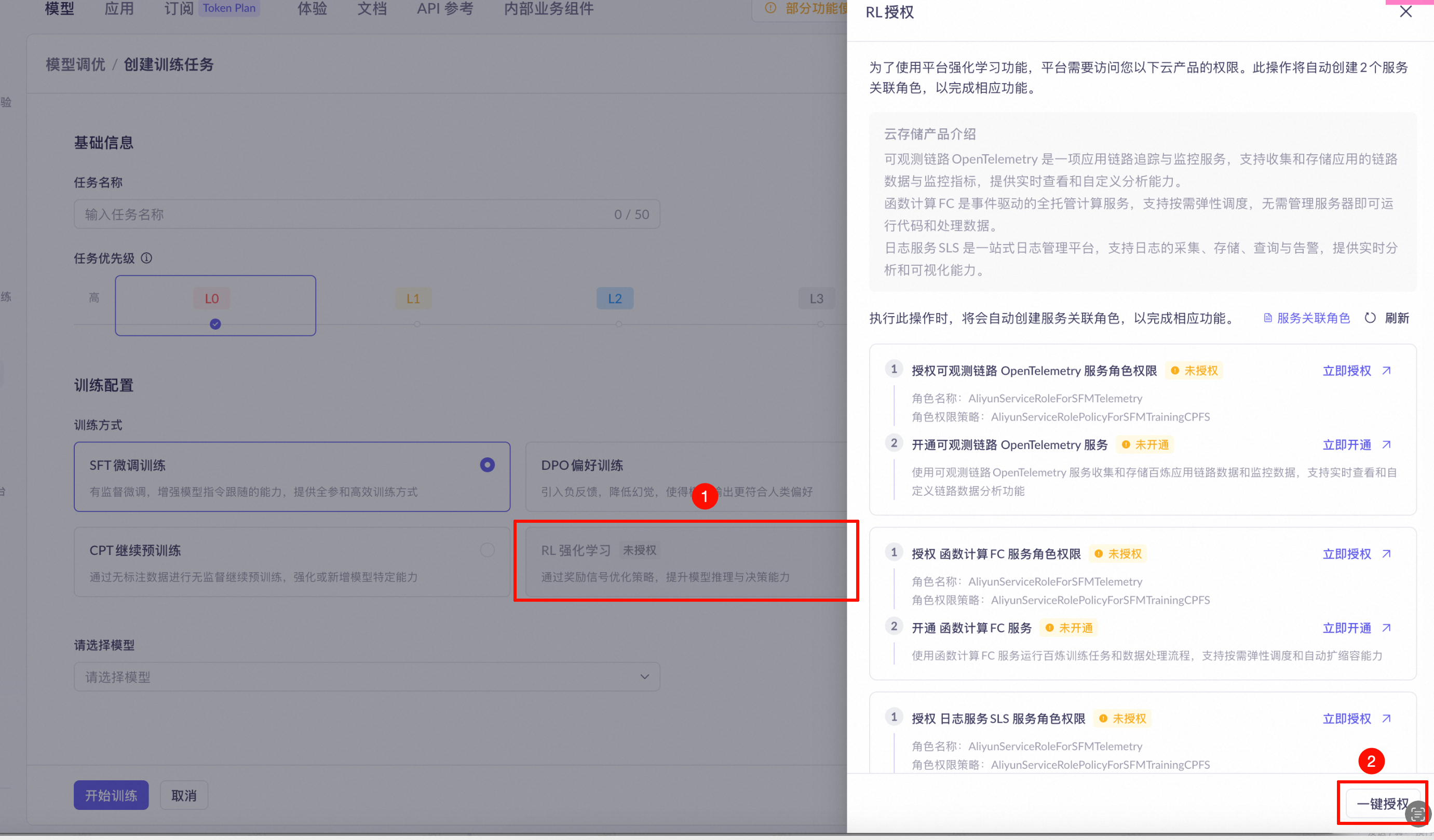
-
设置环境变量:以下变量由本地 SDK 读取,控制打包、上传和部署行为:
-
DASHSCOPE_API_KEY(必填):API 密钥。
-
FC_PYPI_LIB(必填):指定 FC 容器启动时安装的 dashscope 离线包。SDK 打包部署时会自动将该变量注入为
FC_SDK_PACKAGE,无需在 FC 侧手动安装。whl 文件名需与此变量完全一致,且放在项目根目录下。 -
LOG_LEVEL(可选,默认
info):设为debug可输出完整请求/响应信息,便于排查提交失败等问题。
export DASHSCOPE_API_KEY="sk-your-api-key" export FC_PYPI_LIB="dashscope-1.25.16-py3-none-any.whl" export LOG_LEVEL="info" -
准备数据与代码
-
下载 Demo 包agentic-rl-example.zip。(该 Demo 运行最低要求 24 个 IV 型模型训练单元)
-
下载完成后需要安装 DashScope SDK(要求 Python >= 3.10):请按照 Demo 包中附带的指引安装相关依赖:
pip install dashscope-1.25.16-py3-none-any.whl # 安装本地WHL包 # 或使用PyPI源:pip install dashscope==1.25.16
您将获得以下项目结构:
agentic-rl-example/
├── submit_job.py ← 主入口,提交训练任务
├── test_functions.py ← 函数注册与远程测试
├── config.yaml ← 可选的 YAML 配置文件
├── dashscope-1.25.16-py3-none-any.whl ← 离线 SDK 安装包
├── requirements.txt ← 依赖清单
├── data/
│ ├── calc_train.jsonl ← 训练数据(完整版)
│ ├── calc_train_min.jsonl ← 训练数据(Demo 默认使用精简版)
│ ├── calc_validation.jsonl ← 验证数据(完整版)
│ └── calc_validation_min.jsonl ← 验证数据(Demo 默认使用精简版)
├── functions/
│ ├── __init__.py
│ ├── rollout/
│ │ ├── rollout.py ← Rollout 函数(LangGraph + MCP 工具)
│ │ └── rollout_only.py ← Rollout 函数(简单版,含追踪示例)
│ └── reward/
│ ├── reward.py ← Reward 函数(基础评分)
│ ├── reward_decorator.py ← Reward 函数(装饰器风格)
│ └── group_reward.py ← Reward 函数(分组评分)
└── resources/
├── rollout_input.json ← Rollout 测试输入
├── reward_input.json ← Reward 测试输入
├── reward_decorator_input.json ← 装饰器 Reward 测试输入
└── group_reward_input.json ← 分组 Reward 测试输入
Demo 简介
本 Demo 实现了一个数学计算 Agent:
-
Rollout 函数:调用训练中的模型,配合计算器工具回答数学问题
-
Reward 函数:将模型输出与参考答案对比,判定回答是否正确并评分
Demo 中的 Rollout 函数使用 LangGraph 编排 Agent 流程,通过 MCP(Model Context Protocol,一种 LLM 工具调用协议)调用计算器工具。
如需编写自己的 Rollout 和 Reward 函数,请参见强化学习开发指南。
数据格式
训练数据采用 JSONL 格式,每行一个 JSON 对象,包含 messages 和 rollout_extra 两个字段:
{"messages": [{"content": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "role": "user"}], "rollout_extra": {"solution": "72"}}
-
messages:用户问题,格式与 ChatML 一致 -
rollout_extra:存放参考答案或其他业务数据,会传递给 Reward 函数用于评分(rollout_extra 支持自定义字段)
rollout_extra 中的数据会透传到 Rollout 函数的 RolloutInput.rollout_extra 和 Reward 函数的 RewardInput.agent_output.rollout_extra,方便在评分逻辑中使用。该字段支持自定义 key,不限于示例中的 solution。
数据量建议
-
起步:几十到几百条即可验证方案有效性(数据量至少大于
Batch_size)。 -
正式训练:数据量越大效果越优,大规模数据集还支持更大的 batch_size,有助于提升训练稳定性
提交训练任务
Demo 中已包含 Rollout 和 Reward 函数,运行以下命令即可一步完成函数部署、数据上传、训练任务提交:
python submit_job.py也可以通过配置文件或 CLI 提交训练任务(dashscope rl run),三种提交方式与字段逐项说明详见 《训练配置 — 提交与配置》。
起步技巧
第一次跑通后,建议参考以下 4 项实践:
-
先用精简数据:Demo 默认
calc_train_min.jsonl+n_epochs=1跑一次,确认链路通了再换完整数据集,避免拿 24 个 MTU 烧大数据集才发现配置错。 -
超参先不动:上面 13 项超参是 qwen3.5-9b 的推荐起点,第一次训练别调。要调时一次只动一个变量(lr 或 batch_size),跑满
eval_steps × 3步再判断趋势。 -
盯一个核心指标:在指标页签看
critic/rewards/mean——稳步上升说明在学;停滞或下降就停下来排查,别空跑。 -
FAILED 先看日志:任务失败 → 日志页签看末尾报错,或 SDK 拉
AgenticRL.logs(job_id="ft-xxx", lines=100)。配置/依赖类报错通常一眼能定位。
算法选型、超参起点表、调参决策详见《强化学习训练配置 — 提交与配置》;Reward 函数设计哲学与 Hacking 防御详见《强化学习开发指南》;看到指标异常如何归因详见《强化学习的可观测配置与指标参考》。
训练过程观测与分析
任务提交后,run() 返回的 job_id 是后续查询训练状态的唯一标识。训练通常需要数十分钟到数小时,取决于数据量和模型大小。
在百炼控制台的模型调优页面点击任务进入详情页,包含以下 5 个页签:
|
页签 |
定位 |
主要内容 |
|
详情 |
任务元数据 |
任务 ID、状态、基座模型、训练方法、起止时间、数据配置 |
|
轨迹 |
Agent 行为回放 |
完整对话过程、Reward 分析(Step / Sample / Trajectory 三维度)、工具调用详情 |
|
指标 |
训练健康度 |
13 组指标图表(actor / critic / trajectory / trace / timing / perf / fully_async 等),含用户自定义指标 |
|
日志 |
运行排查 |
训练过程 stdout / stderr,任务失败时用于定位报错原因 |
|
产出 |
模型资产 |
Checkpoint 列表、发布状态,可将 Checkpoint 发布至"我的模型"后部署调用 |
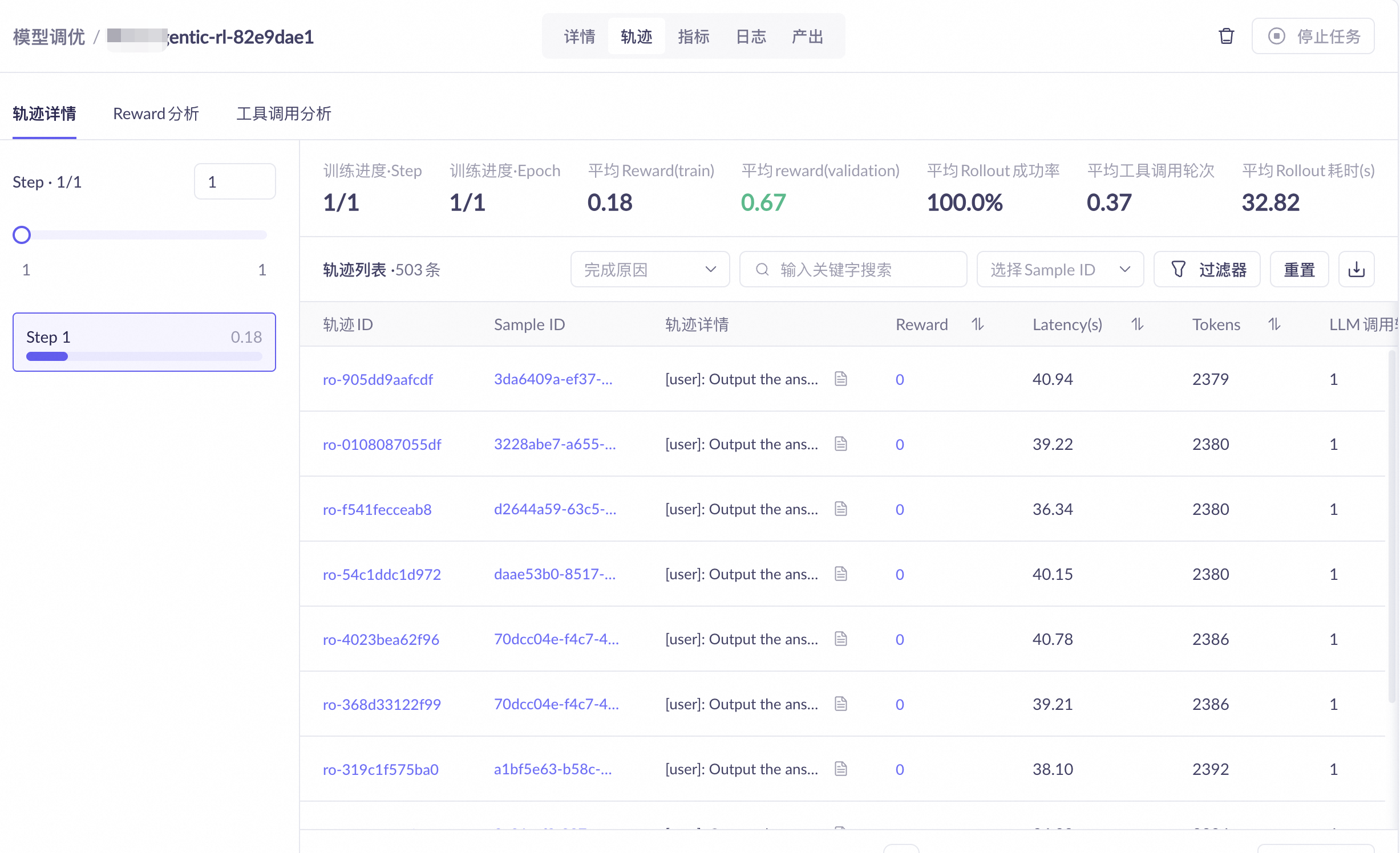
各页签的详细说明请参见强化学习的可观测配置。
发布与部署模型
训练完成后,最后一个 Checkpoint 会自动发布至我的模型。如需发布中间 Checkpoint,前往百炼控制台模型调优 > 产出页面手动操作,详见模型调优控制台(百炼文档,需在线查看)。
发布后的模型可在我的模型页面进行部署。部署完成后即可通过 API 调用模型。详见模型部署(百炼文档,需在线查看)。
后续步骤
-
了解函数开发的完整细节 → 强化学习开发指南
-
了解训练配置和监控 → 强化学习训练配置
-
训练指标参考字典 → 强化学习的可观测配置与指标参考
-
了解可观测性配置与轨迹查看 → 强化学习的可观测配置与指标参考