
本文介绍如何基于本地知识库和云端大模型构建RAG(检索增强生成)应用,用于私域知识问答、客户支持等场景。
如果您希望将知识库部署在本地,实现灵活的文档切分与嵌入模型选择,请参考本文档进行操作。
如果您希望将知识库部署在云端,直观、快速地创建RAG应用,请使用阿里云百炼提供的0代码构建RAG应用功能。
方案概览
您可以通过本文档实现以下效果:
RAG应用能够根据用户提供的文档生成回复,有效缓解大模型面对私有领域问题时的局限性,整体上可分为检索与生成两个环节。
在本应用中,检索环节在本地执行,您能够便捷地管理和维护知识文档、灵活定义文档切分方法,同时避免因文件体积庞大而导致的上传失败问题;生成环节则调用由阿里云百炼提供的通义千问API,您无需考虑本地计算资源及环境配置问题,即可获得相较于开源模型更优质的回复效果。
本应用的整体框架如下图所示:

搭建示例应用
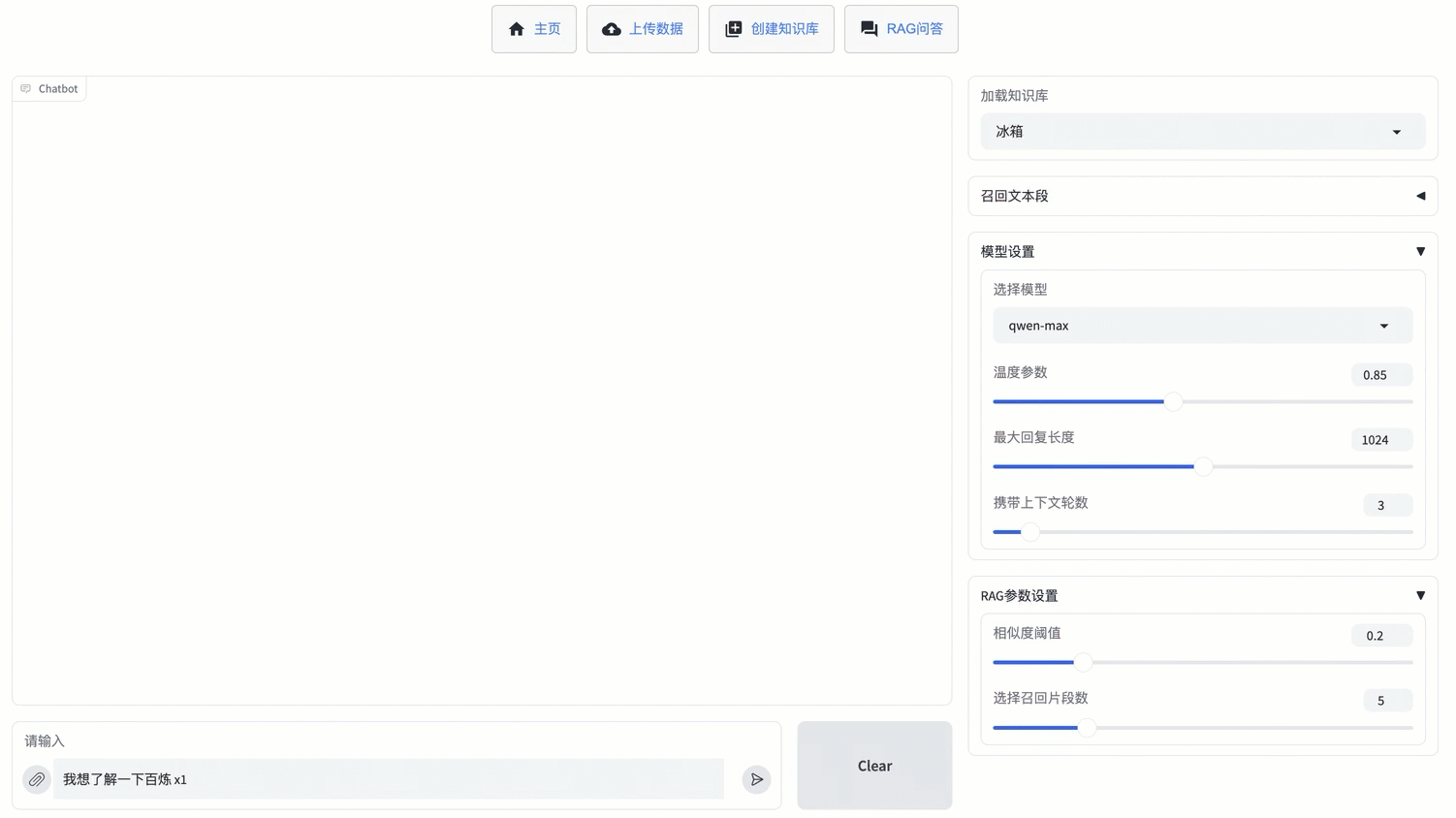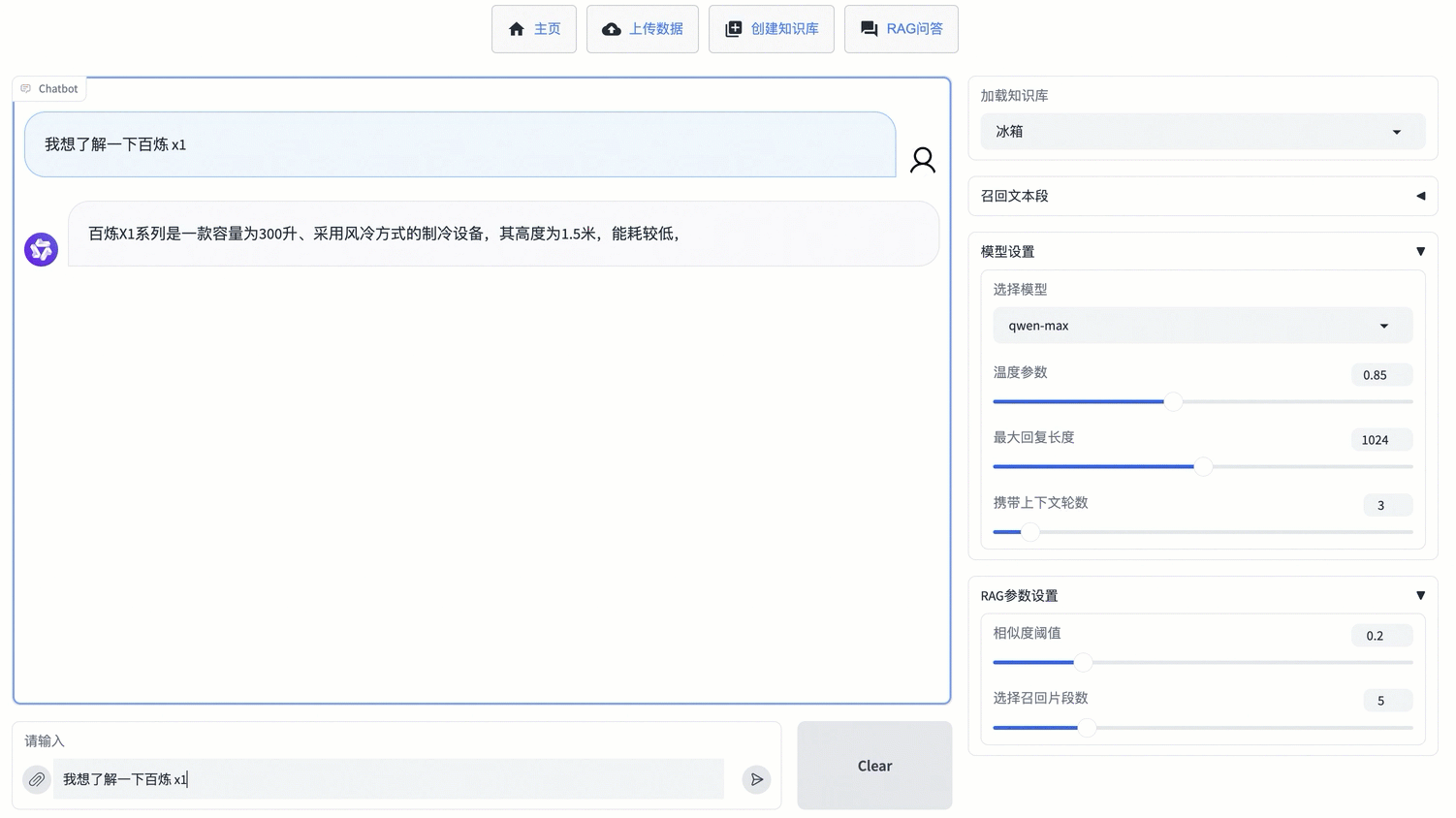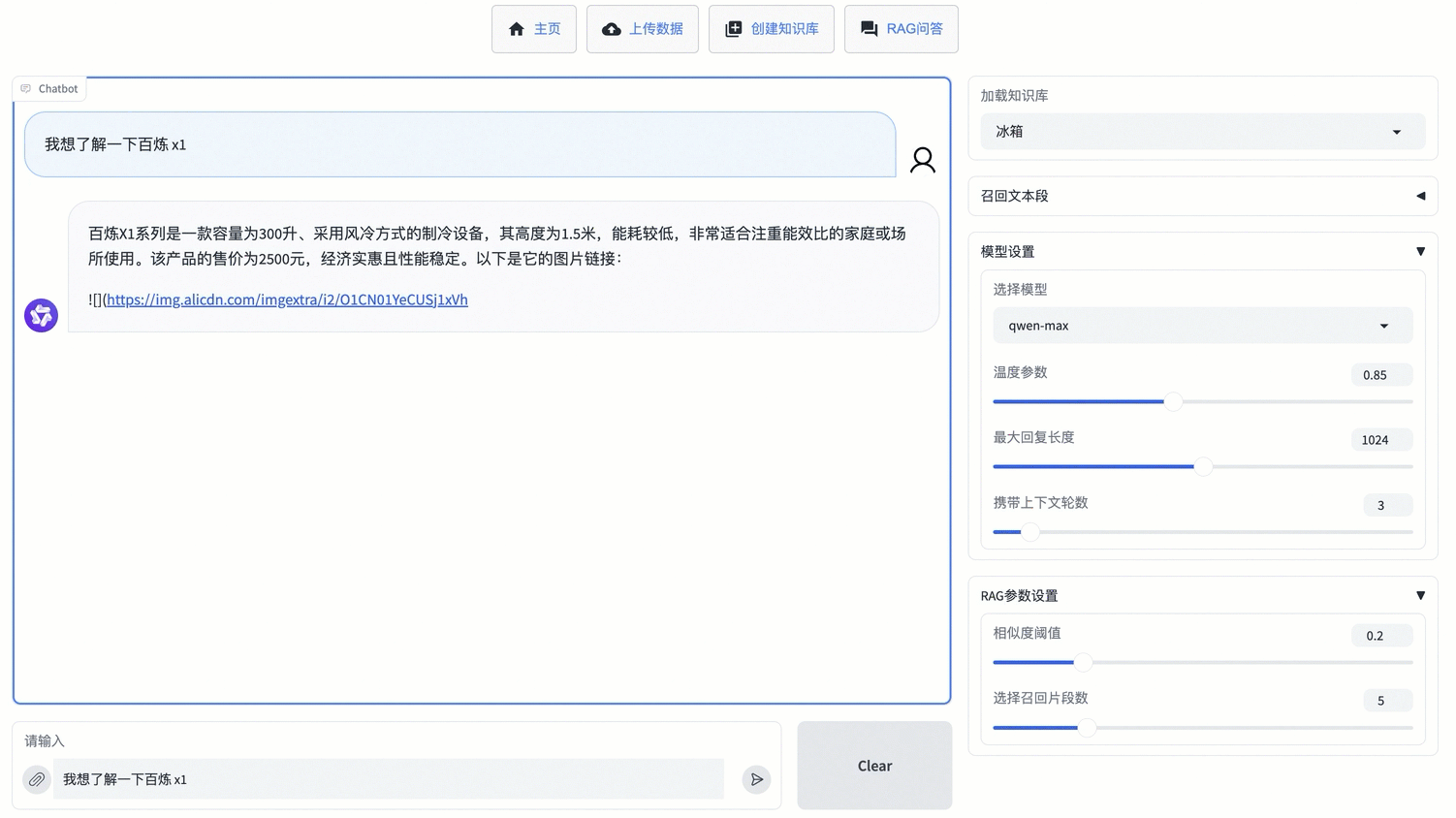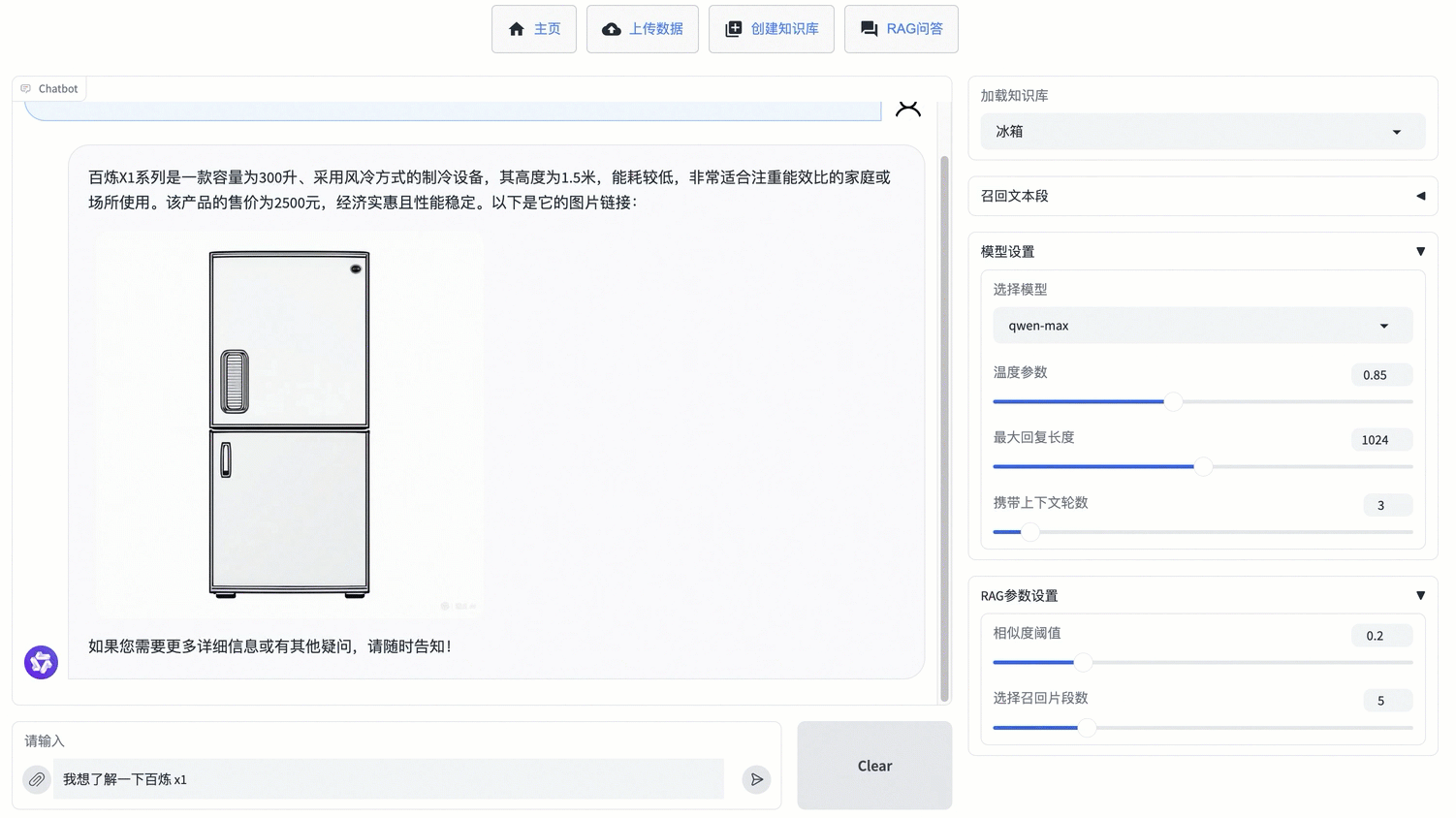
您仅需3步就可以搭建示例应用:
1. 解压文件
下载local_rag.zip并解压,您可以看到如下图所示的目录结构: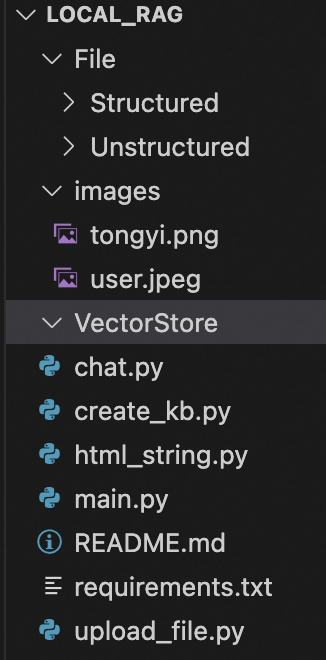
其中File/Structured用于存放用户上传的结构化数据,File/Unstructured用于存放用户上传的非结构化数据;images中的两张图片用于设置对话角色的头像;VectorStore用于存放用户创建的知识库。
2.配置计算环境
您的Python版本需要不低于3.8,且不高于3.12。在解压后的local_rag目录中运行:pip install -r requirements.txt,安装本应用所需要的依赖。
本应用默认使用阿里云百炼提供的embedding模型API来创建知识库。如果您计划使用本地embedding模型,请取消requirements.txt中的注释部分再运行pip install -r requirements.txt命令。
请获取阿里云百炼API Key,并参考配置API Key到环境变量将API Key配置到环境变量中。
修改嵌入模型配置(可选)
本应用默认使用阿里云百炼提供的嵌入模型API。如果您计划使用本地部署的嵌入模型,可以参考以下内容:
3.运行应用
新建一个终端会话窗口,在local_rag目录下运行:uvicorn main:app --port 7866,在终端中出现:INFO: Uvicorn running on http://127.0.0.1:7866 (Press CTRL+C to quit)后,访问http://127.0.0.1:7866即可进入RAG应用的网页。单击RAG问答,即可开始对话。
如果您使用Windows系统,打开页面报错DLL load failed while importing _cext:,请额外运行命令:pip install msvc-runtime后再运行应用。
传入知识文件
您可以通过以下两种方法之一向RAG应用传入知识文件:
若同时使用两种方法,RAG应用会优先参考临时性文件。
传入临时性文件
如果您想要直接在对话框中上传文件,并基于该文件进行问答,可以在RAG问答页面单击输入框旁的![]() 进行临时知识库文件的上传,便能直接输入问题并获得回复。该方法在页面刷新后无法找回上传的文件。
进行临时知识库文件的上传,便能直接输入问题并获得回复。该方法在页面刷新后无法找回上传的文件。
支持传入的文件类型有:pdf、docx、txt、xlsx、csv。
上传数据并创建知识库
如果您需要长期使用特定的知识库文件,建议您通过创建知识库的方法来传入知识文件。需要以下2步:
上传数据
在上传数据页面,您可以上传非结构化数据(暂时支持pdf与docx)或结构化数据(xlsx或csv)。非结构化数据会上传到您命名的类目中,
File/Unstructured中会新建一个您命名类目名称的文件夹,存放您上传的文件;结构化数据会上传到您命名的数据表中,File/Structured中会新建一个您命名数据表名称的文件夹,存放您上传的数据。如果您需要删除类目或数据表,请在管理类目或管理数据表中操作。
创建知识库
在创建知识库界面,您可以使用上一步创建的类目或数据表进行知识库的创建。您可以选择多个类目或多个数据表,并设置知识库名称,单击确认创建知识库,在界面上显示:
知识库创建成功,可前往RAG问答进行提问后,即代表知识库创建完成。知识库文件会存放在VectorStore中您命名知识库名称的文件夹下。您可以前往RAG问答,在加载知识库位置选中创建的知识库,便可以输入问题进行问答。如果您需要删除知识库,请在管理知识库中操作。
受限于 Embedding 模型 API 的限流条件,传入较大文件可能导致创建时间过长,不建议传入超过 100 MB 的文件。

优化回复效果
您可以参考以下方法,来优化RAG应用的回复效果。
修改模型参数与RAG参数
对于模型参数,您可以调整:
模型选择
您可以选择qwen-max、qwen-plus或qwen-turbo三个通义千问商业模型。一般来说,qwen-max性能优秀,qwen-turbo生成速度较快,价格较低,qwen-plus效果、速度、成本均衡,介于qwen-max和qwen-turbo之间。
温度参数
该参数用于控制模型生成的随机性,温度值越高生成的随机性越高。
最大回复长度
该参数用于控制模型生成的最多token个数。如果您希望生成详细的描述可以将该值调高;如果希望生成简短的回答可以将该值调低。
携带上下文轮数
该参数用于控制模型参考历史对话的轮数,设为1时表示模型在回复时不会参考历史对话信息。
对于RAG参数,您可以调整:
召回片段数
该参数用于控制选择与用户输入最相关文本段的个数。该值越大,模型可获得的参考信息越多,但无用信息也可能增加;该值越小,模型可获得的参考信息越少,但无用信息可能减少。
相似度阈值
该参数会剔除已被选择的相关文本段中,相似度低于该值的文本段。该值越大,模型可获得的参考信息越少,但无用信息可能减少。该值为0时,表示不对召回片段进行剔除。
优化切分方法
RAG应用会对文档进行切分,不同文档有不同的最佳切分策略。在创建知识库的过程中,本应用针对结构化数据的切分进行了优化;对于非结构化数据,本应用采用了LlamaIndex默认的切分策略。您可以根据您的文档内容,进行定制化的切分。
更换嵌入模型
嵌入模型对于检索过程十分重要,对于同一个知识文件,不同的嵌入模型可能有不同的表现。您可以尝试更换嵌入模型,查看召回的效果,以选出最符合您业务场景的嵌入模型。
优化提示词
您可以在chat.py中找到prompt_template参数,并根据您的使用场景进行改写,使得大模型的回复更符合业务预期。
通过 API 调用
如果您需要通过 API 调用,请单击 Gradio 界面下方的通过 API 使用,通过 Gradio 自动生成的 API 文档将本地 RAG 应用集成到您的业务场景中。
总结
通过前面的内容,您可以了解到:
如何搭建一个基于本地知识库与通义千问API的RAG应用,并通过 Gradio 界面进行交互;
如何从召回与生成方面优化回复效果;
如何通过 API 调用本地的 RAG 应用。