
数据处理支持用户使用多种模型算子,对模型调优所使用的训练集进行数据清洗和数据增强,从而获得更高质量的训练集。
本文档仅适用于中国大陆版(北京地域)。
如果您训练集中的数据不适合数据清洗与增强(如法律文件、医学记录、文学作品、方言汇总、用户评论、技术手册等),建议您直接跳过本文的阅读。
为什么做数据处理
在模型调优过程中,高质量的训练集将显著提升大模型的训练效果和预测能力。不过,目前绝大多数训练集的数据质量较低且数据量不足。因此,有必要先借助阿里云百炼的数据处理功能,对您的训练集进行数据清洗和数据增强。待获得足够的高质量训练数据后,再进行模型调优。
构建一个有效的SFT训练集通常需要1000+样本。
处理方式 | 适用场景 |
数据清洗 | 需要修正训练数据中存在的规范性、合规性、一致性以及重复等问题(阿里云百炼目前已支持特殊内容移除、敏感信息打码等十种清洗操作)。 特殊内容移除:识别并剔除训练数据中的URL、特殊字符等。
敏感信息打码:识别并脱敏训练数据中的敏感信息。
|
数据增强 | 需要增加训练数据的多样性和均衡性,或扩展数据的规模(增广数据)。 |


支持的训练集
数据处理支持SFT-文本生成训练集,暂不支持SFT-图片理解训练集和DPO-文本生成训练集。
SFT-文本生成训练集包含一轮或多轮对话数据,采用ChatML格式。SFT-ChatML格式示例.jsonl
创建数据流任务
阿里云百炼目前暂未提供可用的API进行数据处理。
本段落将指导您在控制台搭建一个自定义数据流,以说明数据处理过程。该数据流的功能是先对训练数据中的敏感信息进行敏感信息打码(数据清洗),随后增广数据(数据增强)。只需简单两步:
此处先清洗数据再进行增强的原因是:可以确保增强操作是在一个干净、高质量的数据集上进行的,从而保证模型调优的数据源是准确的。
如果您仅需对训练数据进行清洗或增强,可以直接使用阿里云百炼预置的数据流模板:访问数据管理页面,在数据流页签下单击。
步骤一:创建数据流
访问数据管理页面,在数据流页签下单击
在创建数据流对话框中,输入数据流名称和数据流描述,单击确定进入数据流画布(在单击右上角发布之前,数据流处于草稿状态)。
开始节点会预设一个
对话文本参数表示待处理的训练集(此参数无法自行更改)。单击左上角的
 图标可退出画布,系统会自动保存您的数据流草稿,单击管理再次进入后可继续编辑。
图标可退出画布,系统会自动保存您的数据流草稿,单击管理再次进入后可继续编辑。
将左侧数据清洗节点拖入画布,并为数据清洗节点开启敏感信息打码算子,其余算子关闭。
数据清洗节点会预设一个
dataSetCount参数表示该节点处理完成后生成的训练集大小(此参数无法自行更改)。
将开始节点连接到数据清洗节点。
将左侧数据增强节点拖入画布,并为数据增强节点配置对应参数。了解参数详情。
参数
对应配置
场景选择
数据增强-通用。
指令生成依赖样本数
须小于当前节点输入的数据量,否则保持默认即可。
过滤相似度阈值
保持默认即可。
生成样本数
保持默认即可。
Prompt配置
使用阿里云百炼提供的默认模板。
System Prompt: 请你仔细观察多个示例数据的输入和输出,按照你的理解,总结出相应规律,然后写出一个新的【问题】和【回答】。注意,新生成的【问题】和【回答】需要满足如下要求: 1. 生成的【问题】和【回答】不能与输入的【问题】和【回答】一致,但是需要保持格式相同。 2. 生成的【问题】不一定要局限于输入【问题】的话题或领域,生成的【回答】需要正确回答生成的【问题】。 3. 提供的【问题】和【回答】可能是多轮对话,生成的【问题】和【回答】也可以是多轮,但是需要保持格式相同。 4. 生成的【问题】和【回答】必须成对出现,而且【问题】需要在【回答】之前。 ${few_shot_examples}将数据清洗节点连接到数据增强节点,并将数据增强节点连接到结束节点。
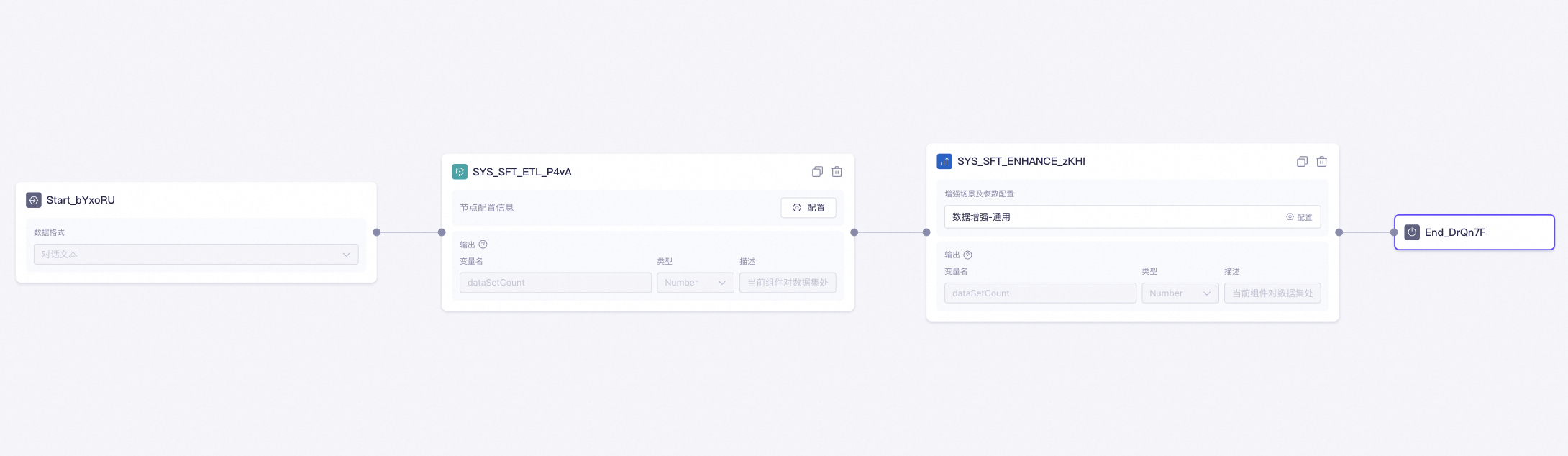
单击右上角发布(数据流变为发布状态,如果再次编辑,数据流会回到草稿状态),至此本数据流搭建完成,单击页面左上角的
图标退出画布。关于搜索数据流:数据流列表页签的搜索框中输入数据流名称后,单击
 图标查找数据流,支持模糊搜索。
图标查找数据流,支持模糊搜索。接下来,请参考下方步骤二:创建数据流任务启动一个数据流任务,使用此数据流来处理您的训练集。
步骤二:创建数据流任务
访问数据管理页面,在数据流页签下单击。在对话框中选择目标数据流后,单击确定。如果列表中没有您已创建的数据流,可能是因为:
该数据流尚未发布。
您可以单击,在列表中找到您想要发布的数据流后,单击。
该数据流不属于当前业务空间。
输入任务名称,选择模型数据作为数据来源,并从列表中选择要处理的训练集。
若无可用训练集,请单击去管理前往模型数据上传一个训练集。具体操作,请参见训练集与评测集。
模型数据提供了训练集的版本管理能力,您的训练集将在清洗或增强后自动生成一个新版本。新版本独立保存,不会覆盖原训练集。
数据处理目前仅支持处理SFT-文本生成训练集,不支持ChatML以外格式。SFT-ChatML格式示例.jsonl
单击创建完成,数据流任务将自动开始执行。
执行需要一定时间,请您耐心等待,执行期间暂不支持手动终止。
单击
 图标,刷新处理状态查看任务是否处理完成。任务所有可能的处理状态如下表所示。
图标,刷新处理状态查看任务是否处理完成。任务所有可能的处理状态如下表所示。处理状态
说明
处理中
表示数据流任务在执行中。在请求高峰时段,数据流任务需要排队等待执行,期间无需您介入操作。
已完成
表示数据流任务已成功完成。单击目标数据流任务右侧的执行过程,查看处理结果。
处理失败
表示数据流任务执行失败。建议您提交工单咨询具体原因。
任务完成后,系统将为处理后的训练集生成一个新版本,请您在使用时注意区分版本。
管理数据流任务
本段落为您说明如何查看业务空间下的数据流任务列表,查找某个数据流任务,以及查看指定数据流任务的基本信息、配置、处理状态和处理结果。
访问数据管理页面,单击任务列表页签,在此页面您可以:
查看数据流任务列表:查看当前业务空间下的完整数据流任务列表及概况,包括每个数据流任务的处理状态和数据流向等信息。
查找数据流任务:搜索框中输入数据流任务名称后,单击
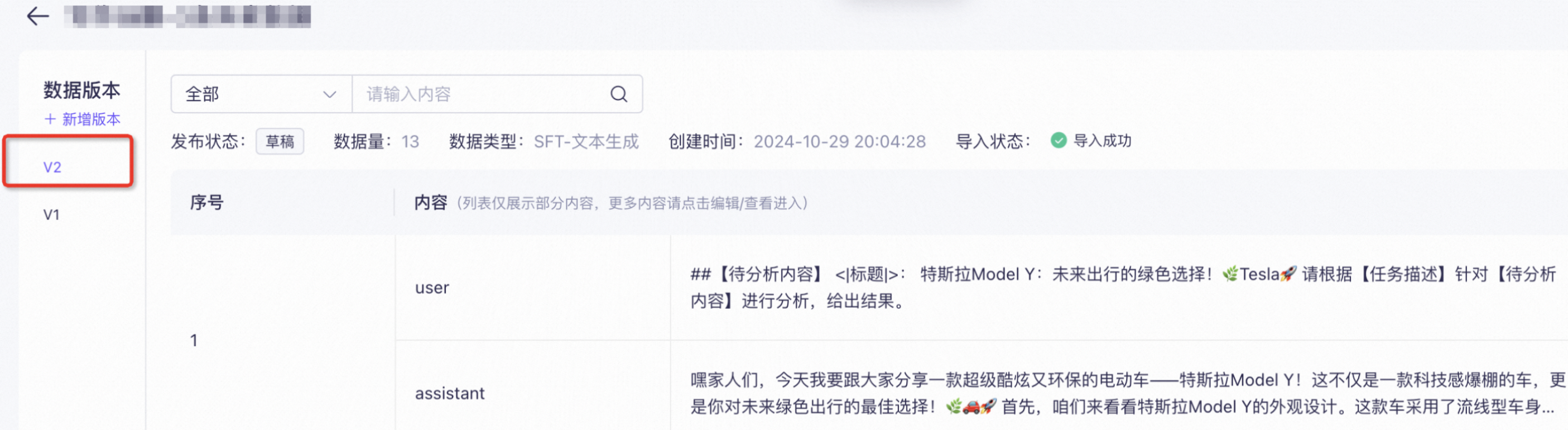
图标查找数据流,支持模糊搜索。查看数据来源和数据流向:您的训练集将在清洗或增强后自动生成一个新版本。新版本独立保存,不会覆盖原训练集。如下图示例中,处理前训练集为V1版本,处理后的数据则存储为训练集的V2版本。
建议检查清洗后的训练集,以确保数据的完整性和真实性没有被破坏。
查看执行过程:单击操作列的执行过程,查看数据流任务的处理结果和耗时情况,包括每个处理节点的中间结果和耗时情况。
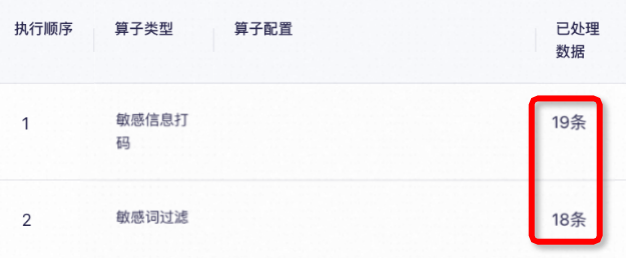
数据清洗节点支持显示每次经过算子后的输出训练集大小。以上图为例,敏感词过滤算子在敏感信息打码算子后执行,敏感词过滤算子过滤掉了1条数据。
删除数据流任务:单击操作列的删除。
任务删除后其对应执行过程将无法找回,请慎重操作。
节点说明
开始/结束节点
定义:开始节点用于开启一个数据流,结束节点用于输出数据流的结果。请注意,每个数据流都必须包含一个开始节点和一个结束节点。结束节点为最后节点,用于输出处理后的训练集,后面不能再添加其它节点,工作流应用中运行到结束节点后才输出执行结果。
开始节点参数配置:
简介
参数配置
输入
输出
其他参数
用于接收用户待清洗或增强的训练集,暂不支持自定义变量。
对话文本表示用户待处理的训练集(此参数无法自行更改)。与输入变量相同,将输入变量向后传递。
无。
结束节点参数配置:
简介
参数配置
输入
输出
其他参数
用于输出已清洗或增强的训练集。暂不支持自定义变量。
前置节点已处理完成的训练集。
与输入变量相同。
无。
节点示例:
下方示例中,结束节点的输入为前置节点数据清洗节点的输出,即该数据流会在数据清洗节点执行完成后结束,并输出数据清洗节点的处理结果。

结束节点输出:
结束节点输出会自动生成一个新版本(可在数据流向列查看)。新版本独立保存,不会覆盖原训练集。

条件判断节点
用法:设置条件,满足条件后字段选择后续链路,支持且/或条件配置,多个条件是从上而下按顺序执行。
参数配置:
参数
说明
条件分支
填写条件判断语句。
其他
不需要条件判断的可从此输出。
节点示例:
以下是一个简单的先数据清洗后增强的示例。其工作流程逻辑如下:待处理的训练集先经过数据清洗节点清洗,随后清洗后的数据被传递给条件判断节点。在节点内部对
dataSetCount(即清洗后结果中messages的数量)进行条件判断,如果数量小于等于10就经过数据增强节点进行数据增广,最后由结束节点输出。
数据清洗节点
用法:需要修正训练数据中存在的规范性、合规性、一致性以及重复等问题。
参数配置:
参数
说明
输入
本节点需要清洗的训练集(对话文本,ChatML格式)。
清洗算子
选择需要执行的清洗算子和操作,如文章相似度去重、敏感词过滤、毒性消除等,支持单选,算子执行顺序按照编排顺序来执行,用于后续节点处理。
调整算子执行顺序:可通过拖拽
 图标调整算子的执行顺序。数据清洗节点将根据您此处设置的顺序对训练数据依次执行不同的算子。
图标调整算子的执行顺序。数据清洗节点将根据您此处设置的顺序对训练数据依次执行不同的算子。是否开启:
 开启代表执行此算子(建议每个数据清洗节点只开启一个算子,这样您可以更容易地检测和纠正错误)。
开启代表执行此算子(建议每个数据清洗节点只开启一个算子,这样您可以更容易地检测和纠正错误)。算子配置:
 勾选代表算子需要执行此操作,若未勾选,算子将不会执行该操作。
勾选代表算子需要执行此操作,若未勾选,算子将不会执行该操作。输出
输出本节点的清洗处理结果(即清洗后的训练集),和变量
dataSetCount(表示结果中messages的数量,此参数无法自行更改)。节点示例:
下方示例中,用户待清洗的训练集会被开始节点传递给数据清洗节点。在节点内部,清洗算子将按编排好的顺序,对训练数据进行对应处理,最终从结束节点输出清洗后训练集。

数据增强节点
用法:用于增加训练数据的多样性和均衡性,或扩展数据的规模(增广数据)。
场景选择:
数据增强-通用:从需要增强的训练集(种子池)中随机选出样本(种子)拼接到Prompt后,请求
通义千问-Max大模型(暂不支持选择模型),通过Few-Shot策略生成新数据,适用于增强微调文本问答大模型所需的SFT训练集。数据增强-文本分类、数据增强-文本抽取以及数据增强-文本创作则是在数据增强-通用的基础上经过场景优化,专门设计用于增强微调文本分类、文本抽取或文本创作相关大模型所需的SFT训练集。
它们在各自特定场景中的增强效果优于数据增强-通用。
参数配置:
数据增强-通用
参数
说明
输入
本节点需要增强的训练集(对话文本,ChatML格式)。
格式示例:
{ "messages": [ { "role": "user", "content": "你经常锻炼身体吗?" }, { "role": "assistant", "content": "经常锻炼身体。" } ] }生成样本数
本节点需要生成的数据量。如果原训练集包含10条训练数据,而生成样本数设置为10,则增强后的训练集将总计达到20条数据。
数据增强-通用任务每次最多生成2000条样本。
基于提供的种子,数据增强-通用生成的数据示例:
{ "messages": [ { "role": "user", "content": "你喜欢阅读哪种类型的书籍?" }, { "role": "assistant", "content": "我喜欢阅读科幻类和历史类的书籍。" } ], "foreignKey": "8ba0304e2452476d89ed6a60c4xxxxxx" }输出数据中
foreignKey为系统后添加,用于标识文本信息。增强后的训练集可直接用于模型调优,您无需删除foreignKey,不会影响模型调优效果。指令生成依赖样本数
系统从增强前训练集中选出的种子数量。种子将被拼接到Prompt中(见下方Prompt配置),提供给大模型进行增强。
如果种子加上Prompt的总长度超过通义千问-Max最大输入Token数,系统将自动调整指令生成依赖样本数以符合限制。
Prompt配置
您可以在这里定义对本次数据增强任务的输入和输出的具体要求,系统也提供默认模板供您参考和使用。
System Prompt: 请你仔细观察多个示例数据的输入和输出,按照你的理解,总结出相应规律,然后写出一个新的【问题】和【回答】。注意,新生成的【问题】和【回答】需要满足如下要求: 1. 生成的【问题】和【回答】不能与输入的【问题】和【回答】一致,但是需要保持格式相同。 2. 生成的【问题】不一定要局限于输入【问题】的话题或领域,生成的【回答】需要正确回答生成的【问题】。 3. 提供的【问题】和【回答】可能是多轮对话,生成的【问题】和【回答】也可以是多轮,但是需要保持格式相同。 4. 生成的【问题】和【回答】必须成对出现,而且【问题】需要在【回答】之前。 ${few_shot_examples}说明数据增强-通用节点本质上是一个
通义千问-Max大模型。节点将基于Prompt配置,通过Few-Shot策略对输入的训练数据进行增强。建议您根据每次数据增强的目标(比如提升数据多样性、均衡性等)适当调整Prompt配置内容。目前只支持
few_shot_examples参数。Few-Shot策略:比如在创建数据流任务时选择一个包含1000条数据的训练集,指令生成依赖样本数是5,期望生成样本数是200。此时算法每次从1000条数据中抽样5条拼入Prompt中的
few_shot_examples,然后请求通义千问-Max生成1条数据,重复200次,最终获得200条数据。说明小贴士:精准与多样化
任务相关性:在数据增强时,确保生成的增强数据与目标任务高度相关,避免引入不相关的变体,保持数据上下文和语义的一致性。
多样化策略:使用多种数据增强策略(如同义词替换、随机抽样、翻译变换等),以最大限度地增加数据的多样性。这有助于提升大模型的泛化能力。
平衡增强:生成的增强数据应在类别、难度和结构上相对平衡,避免让大模型接触过多的特定类型数据,导致过拟合。确保在数据增强过程中,不偏离数据的真实分布。
减少过拟合风险:当训练集的数据量或多样性不足时,大模型在进行全参数训练时可能会过度拟合占主导的训练数据,从而无法有效学习特定对象更泛化的特征。
过滤相似度阈值
取值范围0.1到1。此阈值越低,系统接受新生成数据的标准越严格(避免加入高相似度,即高Rouge-L得分的数据,系统根据整条ChatML数据进行相似度判断), 从而减少数据重复。
系统会对大模型生成的待选增强数据进行评估。若相似度低于设定阈值,则采纳为增强数据;若高于阈值则丢弃。
Rouge-L通过计算生成文本与参考文本之间的最长公共子序列(LCS)长度来衡量相似度,越接近1表示生成的文本与参考文本越相似。
输出
输出本节点增强后的训练集,和变量
dataSetCount(表示增强后的训练集中messages的数量)。说明目前阿里云百炼无法标识增强后的训练集中哪些数据是本次新生成的,哪些是原有的,需要您使用其它第三方diff工具手动比较。
输出格式示例:
{ "messages": [ { "role": "user", "content": "你喜欢阅读哪种类型的书籍?" }, { "role": "assistant", "content": "我喜欢阅读科幻类和历史类的书籍。" } ], "foreignKey": "8ba0304e2452476d89ed6a60c4xxxxxx" }输出数据中
foreignKey为系统后添加,用于标识文本信息。增强后的训练集可直接用于模型调优,您无需删除foreignKey,不会影响模型调优效果。数据增强-文本分类
参数
说明
数据示例
待增强的训练数据必须与给出的数据示例结构一致,否则会导致增强失败。
您可以单击页面上的下载JSON数据模板,然后仿照示例数据替换为您的训练数据,随后直接将其用于数据增强。
输入
本节点需要增强的训练集(对话文本,ChatML格式)。
格式示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " 【任务描述】\n请判断下面电影影评属于以下哪一种类别:\n1. 科幻冒险\n2. 浪漫爱情\n3. 喜剧幽默\n4. 动作惊悚\n5. 剧情文艺\n6. 动画家庭\n7. 恐怖悬疑\n8. 纪录历史\n9. 其他\n\n最终的结果请按照{\"category\": \"<类别结果>\"}的JSON格式进行输出。\n 【待分析内容】《泰坦尼克号》是一部永恒的经典,杰克和露丝的爱情故事令人动容,他们的爱情超越了阶级,超越了生死,让人相信真爱无敌。\n请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{\"category\": 浪漫爱情}" } ] }生成样本数
本节点需要生成的数据量。如果原训练集包含10条训练数据,而生成样本数设置为10,则增强后的训练集将总计达到20条数据。
数据增强-文本分类任务每次最多生成500条样本。
基于提供的种子,数据增强-文本分类生成的数据示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ##【任务描述】\n 请判断下面电影影评属于以下哪一种类别:\n1. 科幻冒险\n2. 浪漫爱情\n3. 喜剧幽默\n4. 动作惊悚\n5. 剧情文艺\n6. 动画家庭\n7. 恐怖悬疑\n8. 纪录历史\n9. 其他\n\n最终的结果请按照{\"category\": \"<类别结果>\"}的JSON格式进行输出。\n ##【待分析内容】《泰坦尼克号》展现了杰克与露丝之间不朽的爱情,这段跨越社会阶层的深情故事感人肺腑,强调了爱情的力量能够克服一切障碍。\n 请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{\"category\": 浪漫爱情}" } ], "foreignKey": "file-86970235b7ac4af8a0faf0338c5b1df0_2_e260ae4c8fec4732b40221a9a1xxxxxx" }输出数据中##和
foreignKey为系统后添加,用于标识文本和层级结构信息。增强后的训练集可直接用于模型调优,您无需删除##和foreignKey,不会影响模型调优效果。任务描述增强占比
以下通过一个种子的ChatML示例来说明该参数的作用:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " 【任务描述】\n请判断下面电影影评属于以下哪一种类别:\n1. 科幻冒险\n2. 浪漫爱情\n3. 喜剧幽默\n4. 动作惊悚\n5. 剧情文艺\n6. 动画家庭\n7. 恐怖悬疑\n8. 纪录历史\n9. 其他\n\n最终的结果请按照{\"category\": \"<类别结果>\"}的JSON格式进行输出。\n 【待分析内容】《泰坦尼克号》是一部永恒的经典,杰克和露丝的爱情故事令人动容,他们的爱情超越了阶级,超越了生死,让人相信真爱无敌。\n请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{\"category\": 浪漫爱情}" } ] }数据增强-文本分类节点本质上是一个
通义千问-Max大模型。节点将基于内置的Prompt配置(暂不支持自定义),仿照种子的格式,通过替换【任务描述】部分或【待分析内容】部分生成增强数据。假如生成样本数为10,任务描述增强占比为0.3,表示新生成的10条增强数据中,30%(3条)的【任务描述】部分会被大模型替换为等价表述,同时【待分析内容】部分不变;70%(7条)的【待分析内容】被大模型替换为等价表述,同时【任务描述】部分不变。该参数取值范围0到1。类别信息(可选)
以下通过一个种子的ChatML示例来说明该参数的作用:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " 【任务描述】\n请判断下面电影影评属于以下哪一种类别:\n1. 科幻冒险\n2. 浪漫爱情\n3. 喜剧幽默\n4. 动作惊悚\n5. 剧情文艺\n6. 动画家庭\n7. 恐怖悬疑\n8. 纪录历史\n9. 其他\n\n最终的结果请按照{\"category\": \"<类别结果>\"}的JSON格式进行输出。\n 【待分析内容】《冰雪奇缘》以精美的画面和动人的音乐,讲述了一个关于勇气、爱与自我发现的故事,是迪士尼动画电影的又一力作。\n请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{\"category\": 动画家庭}" } ], "foreignKey": "file-86970235b7ac4af8a0faf0338c5b1df0_1_71ee53ef0d364b539ffa7577bexxxxxx" }该种子的【任务描述】中一共出现了9种类别,分别是:
1. 科幻冒险 2. 浪漫爱情 3. 喜剧幽默 4. 动作惊悚 5. 剧情文艺 6. 动画家庭 7. 恐怖悬疑 8. 纪录历史 9. 其他基于种子,数据增强-文本分类生成的数据示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " 你是一个专家,擅长下面的技能:\n理解文本内容:能够准确把握影评中对电影类型的描述。\n分类判断能力:基于影评的内容,从给定的9个类别中挑选最符合的一个。\n信息匹配:将影评中的关键词或短语与预设的类型特征相匹配。\n格式化输出:按照要求以JSON格式{\"category\": \"<类别结果>\"}准确地给出答案。\n\n【任务描述】\n请判断下面电影影评属于以下哪一种类别:\n1. 科幻冒险\n2. 浪漫爱情\n3. 喜剧幽默\n4. 动作惊悚\n5. 剧情文艺\n6. 动画家庭\n7. 恐怖悬疑\n8. 纪录历史\n9. 其他\n\n最终的结果请按照{\"category\": \"<类别结果>\"}的JSON格式进行输出。\n\n【任务步骤】\n1. 仔细阅读给定的电影影评,理解其主要内容和情感倾向。\n2. 根据影评中的关键词、描述的情节以及所传达的情绪来识别它最符合哪个类别。比如提到未来科技、太空探索等词汇可能指向“科幻冒险”;而涉及恋爱故事、浪漫场景则可能是“浪漫爱情”。\n3. 确认分类后,使用提供的JSON格式{\"category\": \"<类别结果>\"}填写对应的结果,并确保<类别结果>准确反映了所选分类。\n4. 检查填写无误后提交最终答案。\n\n 【待分析内容】\n《冰雪奇缘》以精美的画面和动人的音乐,讲述了一个关于勇气、爱与自我发现的故事,是迪士尼动画电影的又一力作。\n\n请根据【任务描述】针对【待分析内容】进行分析,并且参考给定的【任务步骤】,给出结果。请注意:\n1. 仔细阅读给定的影评内容,理解其核心表达。\n2. 根据影评中提及的情节、风格或评价等信息,匹配最接近的电影类别。\n3. 注意区分相似类型的细微差别,如“动作惊悚”与“科幻冒险”之间的区别。\n4. 确认选择后,使用指定格式{\"category\": \"<所选类别>\"}准确回复。\n5. 如果影评内容涉及多个类别特征但侧重明显,则根据主要特色决定最终分类;若无法明确归属某一特定类别,则考虑归类为“其他”。\n" }, { "role": "assistant", "content": "{\"category\": 动画家庭}" } ], "foreignKey": "file-86970235b7ac4af8a0faf0338c5b1df0_5_9cba8195a8xxxxxx" }生成数据的【任务描述】中一共出现了9种类别,分别是:
1. 科幻冒险 2. 浪漫爱情 3. 喜剧幽默 4. 动作惊悚 5. 剧情文艺 6. 动画家庭 7. 恐怖悬疑 8. 纪录历史 9. 其他由于【任务描述】部分由大模型生成,可能不稳定。此处填写指定类别,例如“浪漫爱情”,可避免该类别在生成中被泛化为“浪漫恋爱”等类似表述。不填写则默认为训练数据【任务描述】中出现的所有类别添加检查以防止泛化。
该项可不填写。
过滤相似度阈值
取值范围0.1到1。此阈值越低,系统接受新生成数据的标准越严格(避免加入高相似度,即高Rouge-L得分的数据,系统根据整条ChatML数据进行相似度判断), 从而减少数据重复。
系统会对大模型生成的待选增强数据进行评估。若相似度低于设定阈值,则采纳为增强数据;若高于阈值则丢弃。
Rouge-L通过计算生成文本与参考文本之间的最长公共子序列(LCS)长度来衡量相似度,越接近1表示生成的文本与参考文本越相似。
输出
输出本节点增强后的训练集,和变量
dataSetCount(表示增强后的训练集中messages的数量)。说明目前阿里云百炼无法标识增强后的训练集中哪些数据是本次新生成的,哪些是原有的,需要您使用其它第三方diff工具手动比较。
输出格式示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ## 【任务描述】\n 请判断下面电影影评属于以下哪一种类别:\n1. 科幻冒险\n2. 浪漫爱情\n3. 喜剧幽默\n4. 动作惊悚\n5. 剧情文艺\n6. 动画家庭\n7. 恐怖悬疑\n8. 纪录历史\n9. 其他\n\n最终的结果请按照{\"category\": \"<类别结果>\"}的JSON格式进行输出。\n ##【待分析内容】《泰坦尼克号》展现了杰克与露丝之间不朽的爱情,这段跨越社会阶层的深情故事感人肺腑,强调了爱情的力量能够克服一切障碍。\n 请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{\"category\": 浪漫爱情}" } ], "foreignKey": "file-86970235b7ac4af8a0faf0338c5b1df0_2_e260ae4c8fec4732b40221a9a1xxxxxx" }输出数据中##和
foreignKey为系统后添加,用于标识文本和层级结构信息。增强后的训练集可直接用于模型调优,您无需删除##和foreignKey,不会影响模型调优效果。数据增强-文本抽取
参数
说明
数据示例
待增强的训练数据必须与给出的数据示例结构一致,否则会导致增强失败。
您可以单击页面上的下载JSON数据模板,然后仿照示例数据替换为您的训练数据,随后直接将其用于数据增强。
输入
本节点需要增强的训练集(对话文本,ChatML格式)。
格式示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " 【任务描述】请从一段电话对话中提取和时间、地点、电话号码有关的信息。并以JSON格式返回{\"time\": <时间>, \"location\": <地点>, \"telephone\": <电话>}。\n请注意如果对话中没有明确时间、地点或者没有提及电话号码,请在结果的相应字段返回空字符串。例如:{\"time\": <时间>, \"location\": <地点>, \"telephone\": \"\"}\n 【待分析内容】A: 小王,记得明天上午9点的会议吗?我们在公司会议室见。\\nB: 明白了,我一定会准时到达。我会提前准备好汇报的材料。\n请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{\"time\": \"明天上午9点\", \"location\": \"公司会议室\", \"telephone\": \"\"}" } ] }生成样本数
本节点需要生成的数据量。如果原训练集包含10条训练数据,而生成样本数设置为10,则增强后的训练集将总计达到20条数据。
数据增强-文本抽取任务每次最多生成500条样本。
基于提供的种子,数据增强-文本抽取生成的数据示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ## 【任务描述】\n 请从一段电话对话中提取和时间、地点、电话号码有关的信息。并以JSON格式返回{\"time\": <时间>, \"location\": <地点>, \"telephone\": <电话>}。\n请注意如果对话中没有明确时间、地点或者没有提及电话号码,请在结果的相应字段返回空字符串。例如:{\"time\": <时间>, \"location\": <地点>, \"telephone\": \"\"}\n ##【待分析内容】A: 小王,这周咱们读书俱乐部的聚会改到周五晚上7点了,地点是市中心图书馆,请务必到场哦。\nB: 收到!那晚我正好有空,对了,这是我的新手机:1865432****,方便的话加个好友吧。\n 请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{'time': '周五晚上7点', 'location': '市中心图书馆', 'telephone': '1865432****'}" } ], "foreignKey": "file-168ee54fa66a47e2970ed76352d90941_2_91c81c0efcaf437284ec5d1c65xxxxxx" }输出数据中##和
foreignKey为系统后添加,用于标识文本和层级结构信息。增强后的训练集可直接用于模型调优,您无需删除##和foreignKey,不会影响模型调优效果。Prompt配置
您可以在这里定义对本次数据增强任务的输入和输出的具体要求,系统也提供默认模板供您参考和使用。
一个完整的大语言模型的训练示例可以定义为以下的结构: Question: 描述期待大语言模型要做的任务。 Context: 描述期待大语言模型要分析的内容。 Answer: 期待大语言模型输出的正确结果。 给定的Question: ${Question} 给定的<Context, Answer>数据对: Context: ${Context} Answer: ${Answer} 【注意事项】 1. 为了保证你编写的答案的准确性,你需要先根据你对给定Question和Answer的理解来构造一个新的Answer。 2. 你编写的新Answer要和给定的Question匹配。 3. 你编写的新Answer格式要和给定的Answer匹配。 4. 根据你编写的Answer来构造蕴含这个Answer的Context。 5. 你编写的Context长度要和示例Context长度相当。 6. 把你编写的Answer和Context组合在一个JSON中,具体格式为${Format_Constraint} 请首先分析给定的<Question>和<Context, Answer>数据的特点,然后构造新的<Answer, Context>,满足【注意事项】中的所有要求,你可以参考这个执行步骤: 1. 首先分析给定的<Question>和<Context, Answer>数据的特点。 2. 理解【注意事项】中的每一条内容。 3. 构造新的Answer和Context,按照指定格式输出。 按照参考步骤,一步一步地执行给定的任务。说明数据增强-文本抽取节点本质上是一个
通义千问-Max大模型。节点将基于Prompt配置对输入训练集进行数据增强。建议您根据每次数据增强的目标适当调整Prompt配置内容(比如提升数据多样性、均衡性等)。说明小贴士:精准与多样化
任务相关性:在数据增强时,确保生成的增强数据与目标任务高度相关,避免引入不相关的变体,保持数据上下文和语义的一致性。
多样化策略:使用多种数据增强策略(如同义词替换、随机抽样、翻译变换等),以最大限度地增加数据的多样性。这有助于提升大模型的泛化能力。
平衡增强:生成的增强数据应在类别、难度和结构上相对平衡,避免让大模型接触过多的特定类型数据,导致过拟合。确保在数据增强过程中,不偏离数据的真实分布。
减少过拟合风险:当训练集的数据量或多样性不足时,大模型在进行全参数训练时可能会过度拟合占主导的训练数据,从而无法有效学习特定对象更泛化的特征。
过滤相似度阈值
取值范围0.1到1。此阈值越低,系统接受新生成数据的标准越严格(避免加入高相似度,即高Rouge-L得分的数据,系统根据整条ChatML数据进行相似度判断), 从而减少数据重复。
系统会对大模型生成的待选增强数据进行评估。若相似度低于设定阈值,则采纳为增强数据;若高于阈值则丢弃。
Rouge-L通过计算生成文本与参考文本之间的最长公共子序列(LCS)长度来衡量相似度,越接近1表示生成的文本与参考文本越相似。
输出
输出本节点增强后的训练集,和变量
dataSetCount(表示增强后的训练集中messages的数量)。说明目前阿里云百炼无法标识增强后的训练集中哪些数据是本次新生成的,哪些是原有的,需要您使用其它第三方diff工具手动比较。
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ## 【任务描述】\n 请从一段电话对话中提取和时间、地点、电话号码有关的信息。并以JSON格式返回{\"time\": <时间>, \"location\": <地点>, \"telephone\": <电话>}。\n请注意如果对话中没有明确时间、地点或者没有提及电话号码,请在结果的相应字段返回空字符串。例如:{\"time\": <时间>, \"location\": <地点>, \"telephone\": \"\"}\n ##【待分析内容】A: 小王,这周咱们读书俱乐部的聚会改到周五晚上7点了,地点是市中心图书馆,请务必到场哦。\nB: 收到!那晚我正好有空,对了,这是我的新手机:1865432****,方便的话加个好友吧。\n 请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "{'time': '周五晚上7点', 'location': '市中心图书馆', 'telephone': '1865432****'}" } ], "foreignKey": "file-168ee54fa66a47e2970ed76352d90941_2_91c81c0efcaf437284ec5d1c65xxxxxx" }输出数据中##和
foreignKey为系统后添加,用于标识文本和层级结构信息。增强后的训练集可直接用于模型调优,您无需删除##和foreignKey,不会影响模型调优效果。数据增强-文本创作
参数
说明
数据示例
待增强的训练数据必须与给出的数据示例结构一致,否则会导致增强失败。
您可以单击页面上的下载JSON数据模板,然后仿照示例数据替换为您的训练数据,随后直接将其用于数据增强。
输入
本节点需要增强的训练集(对话文本,ChatML格式)。
格式示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ##【任务描述】\n\n亲爱的家人们,你们的任务是以小红书汽车销售博主的风格,根据我给出的<|标题|>,发挥想象,创作一篇生动有趣的推荐帖子哦。每段都要加上精选的表情符号,让内容更加有趣和互动,这样大家看得开心,更愿意点赞分享呢。\n\n开头要非常吸引人,让读者一眼就明白你要分享的是干货内容,激发他们继续阅读的兴趣。接下来,至少写三个与主题相关的段落,每个段落都要突出独特之处和吸引力,让大家阅读时感到超开心,趣味横生,好玩到无以复加。\n\n写作时记得运用表情符号,增加生动感。每个表情都有自己的个性,像锅一样,各自的脾气不同,你需要根据经验来巧妙选择。此外,可以参考一些小红书常见的词汇,比如“超棒”、“心动不已”、“不要错过”、“无忧无虑”、“引爆”、“十分优惠”等等。这样你的帖子就能更贴近小红书的风格,更受欢迎哦。\n\n最后,别忘了在“正文”结尾部分换行后加上我提供的“标签”!\n\n\n ##【待分析内容】\n<|标题|>:\n女生10万预算新能源车怎么选\n请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "女生10万预算新能源车怎么选\n\nHey,美腻的小姐姐们,你们是不是也曾面对琳琅满目的新能源汽车市场,却不知如何下手?今天,你们的专属汽车顾问来啦!让我带你们穿越这片“绿动森林”,找到那辆专属于你的梦幻座驾,让出行生活从此与众不同!这篇帖子绝对满满的干货,记得收藏起来随时查阅哦!\n\n首先登场的是我们的“城市精灵”-A款电动车!它的外观设计宛如一颗精致糖果,俘获无数少女心。小巧玲珑的车身,轻松应对城市狭窄街道与停车位挑战。内饰更是温馨舒适,仿佛把自家客厅搬进了车里。最重要的是,续航里程完全满足日常通勤需求,让你无忧无虑地穿梭于都市丛林之间。而且,价格美丽到让你忍不住尖叫,性价比之王非它莫属!\n\n接下来是B款新能源车,它可是名副其实的“科技潮女”赋能神器。全液晶仪表盘、智能语音助手、手机无线充电。这些酷炫科技配置一应俱全,让你的驾驶体验瞬间升级到未来级别。更赞的是,它拥有同价位罕见的L2级自动驾驶辅助系统,让长途驾驶也能变得轻松惬意。如此前沿且实用的座驾,绝对能让你成为朋友圈的焦点,赚足回头率!\n\n最后压轴的是C款混动小车,环保理念与时尚元素完美融合的艺术品。其流线型车身线条优雅灵动,低风阻设计不仅美观,还能有效提升能耗效率。内饰采用环保材料,触感细腻,散发出淡淡的自然清香。最关键的是,它以低于10万的预算,为你提供超越期待的驾驶乐趣与节能环保双重享受。这款车型,无疑是你追求绿色生活方式的最佳拍档。\n\n以上就是我为各位女神精心挑选的三款新能源车型,无论你是钟情于可爱风、科技控,还是热衷环保生活,总有一款能触动你的小心脏。心动不如行动,赶快去试驾体验吧!记住,适合自己的才是最好的,祝每位仙女都能早日邂逅心仪的新能源座驾,开启属于你的无忧绿色旅程!\n\n#女生选车指南 #新能源汽车推荐 #10万预算购车攻略 #城市出行新风尚 #绿色出行我做主" } ] }生成样本数
本节点需要生成的数据量。如果原训练集包含10条训练数据,而生成样本数设置为10,则增强后的训练集将总计达到20条数据。
数据增强-文本创作任务每次最多生成200条样本。
基于提供的种子,数据增强-文本创作生成的数据示例:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ##【任务描述】\n 亲爱的家人们,你们的任务是以小红书汽车销售博主的风格,根据我给出的<|标题|>,发挥想象,创作一篇生动有趣的推荐帖子哦。每段都要加上精选的表情符号,让内容更加有趣和互动,这样大家看得开心,更愿意点赞分享呢。\n\n开头要非常吸引人,让读者一眼就明白你要分享的是干货内容,激发他们继续阅读的兴趣。接下来,至少写三个与主题相关的段落,每个段落都要突出独特之处和吸引力,让大家阅读时感到超开心,趣味横生,好玩到无以复加。\n\n写作时记得运用表情符号,增加生动感。每个表情都有自己的个性,像锅一样,各自的脾气不同,你需要根据经验来巧妙选择。此外,可以参考一些小红书常见的词汇,比如“超棒”、“心动不已”、“不要错过”、“无忧无虑”、“引爆”、“十分优惠”等等。这样你的帖子就能更贴近小红书的风格,更受欢迎哦。\n\n最后,别忘了在“正文”结尾部分换行后加上我提供的“标签”!\n\n\n##\n ##【待分析内容】<|标题|>:\n国庆出游选电车20万内哪款最值?\n 请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "国庆出游选电车20万内哪款最值?\n\n【国庆出游必备!20万内超值电车推荐】\n\n国庆长假即将来临,你是不是已经计划好了一场说走就走的旅行?但面对琳琅满目的新能源汽车市场,该如何选择一款既实用又高性价比的座驾呢?今天,本博主就为大家精心挑选了几款20万内的超值电车,让你的国庆出游更加无忧无虑、充满乐趣!\n\n**续航王者:比亚迪秦Pro EV**\n第一款推荐车型是比亚迪秦Pro EV。这款车拥有超长的续航里程,最高可达500公里以上!这意味着你可以毫无顾虑地踏上长途旅程,无需频繁寻找充电站。此外,秦Pro EV还配备了丰富的智能科技配置,如12.8英寸旋转大屏、DiLink智能网联系统等,让旅途中的娱乐和导航更加便捷。最重要的是,它的价格十分亲民,绝对物超所值!\n\n**颜值担当:小鹏G3i**\n如果你追求时尚与个性,那么小鹏G3i绝对是你的不二之选!这款车采用了流线型设计,外观极具未来感,无论是城市穿梭还是乡村探险,都能赚足回头率。内饰方面,小鹏G3i同样表现出色,全景天窗、Nappa真皮座椅、15.6英寸中控大屏。每一处细节都彰显出高级感。而且,它还配备了L2+级自动驾驶辅助系统,为你的出行安全保驾护航。\n\n**全能选手:广汽埃安AION Y**\n最后一款推荐车型是广汽埃安AION Y。这是一款综合性能出色的电动SUV,不仅拥有宽敞舒适的乘坐空间,还能提供高达500公里的续航里程。无论你是带着家人朋友出游,还是独自一人探索未知,AION Y都能满足你的需求。另外,它的智能化配置也非常丰富,包括ADiGO 3.0智驾互联生态系统、远程控制等功能,让驾驶变得更加轻松愉悦。\n\n总之,以上三款车型各有千秋,无论你是追求续航能力、时尚设计还是全能表现,总有一款适合你!亲爱的家人们,赶快行动起来吧,抓住这次国庆购车的好时机,开启一段精彩纷呈的旅程!\n\n#国庆出游 #新能源汽车 #20万预算 #比亚迪秦Pro EV #小鹏G3i #广汽埃安AION Y #超值电车推荐 #续航王者 #颜值担当 #全能选手 #智能科技 #自驾游攻略" } ], "foreignKey": "file-fe9bbd31fc6c4e659a53787331254617_3_d3d92a4208cb4376994feef8a3xxxxxx" }输出数据中##和
foreignKey为系统后添加,用于标识文本和层级结构信息。增强后的训练集可直接用于模型调优,您无需删除##和foreignKey,不会影响模型调优效果。任务描述增强占比
以下通过一个种子的ChatML示例来说明该参数的作用:
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ##【任务描述】\n\n亲爱的家人们,你们的任务是以小红书汽车销售博主的风格,根据我给出的<|标题|>,发挥想象,创作一篇生动有趣的推荐帖子哦。每段都要加上精选的表情符号,让内容更加有趣和互动,这样大家看得开心,更愿意点赞分享呢。\n\n开头要非常吸引人,让读者一眼就明白你要分享的是干货内容,激发他们继续阅读的兴趣。接下来,至少写三个与主题相关的段落,每个段落都要突出独特之处和吸引力,让大家阅读时感到超开心,趣味横生,好玩到无以复加。\n\n写作时记得运用表情符号,增加生动感。每个表情都有自己的个性,像锅一样,各自的脾气不同,你需要根据经验来巧妙选择。此外,可以参考一些小红书常见的词汇,比如“超棒”、“心动不已”、“不要错过”、“无忧无虑”、“引爆”、“十分优惠”等等。这样你的帖子就能更贴近小红书的风格,更受欢迎哦。\n\n最后,别忘了在“正文”结尾部分换行后加上我提供的“标签”!\n\n\n ##【待分析内容】\n<|标题|>:\n女生10万预算新能源车怎么选\n请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "女生10万预算新能源车怎么选\n\nHey,美腻的小姐姐们,你们是不是也曾面对琳琅满目的新能源汽车市场,却不知如何下手?今天,你们的专属汽车顾问来啦!让我带你们穿越这片“绿动森林”,找到那辆专属于你的梦幻座驾,让出行生活从此与众不同!这篇帖子绝对满满的干货,记得收藏起来随时查阅哦!\n\n首先登场的是我们的“城市精灵”-A款电动车!它的外观设计宛如一颗精致糖果,俘获无数少女心。小巧玲珑的车身,轻松应对城市狭窄街道与停车位挑战。内饰更是温馨舒适,仿佛把自家客厅搬进了车里。最重要的是,续航里程完全满足日常通勤需求,让你无忧无虑地穿梭于都市丛林之间。而且,价格美丽到让你忍不住尖叫,性价比之王非它莫属!\n\n接下来是B款新能源车,它可是名副其实的“科技潮女”赋能神器。全液晶仪表盘、智能语音助手、手机无线充电。这些酷炫科技配置一应俱全,让你的驾驶体验瞬间升级到未来级别。更赞的是,它拥有同价位罕见的L2级自动驾驶辅助系统,让长途驾驶也能变得轻松惬意。如此前沿且实用的座驾,绝对能让你成为朋友圈的焦点,赚足回头率!\n\n最后压轴的是C款混动小车,环保理念与时尚元素完美融合的艺术品。其流线型车身线条优雅灵动,低风阻设计不仅美观,还能有效提升能耗效率。内饰采用环保材料,触感细腻,散发出淡淡的自然清香。最关键的是,它以低于10万的预算,为你提供超越期待的驾驶乐趣与节能环保双重享受。这款车型,无疑是你追求绿色生活方式的最佳拍档。\n\n以上就是我为各位女神精心挑选的三款新能源车型,无论你是钟情于可爱风、科技控,还是热衷环保生活,总有一款能触动你的小心脏。心动不如行动,赶快去试驾体验吧!记住,适合自己的才是最好的,祝每位仙女都能早日邂逅心仪的新能源座驾,开启属于你的无忧绿色旅程!\n\n#女生选车指南 #新能源汽车推荐 #10万预算购车攻略 #城市出行新风尚 #绿色出行我做主" } ] }数据增强-文本创作节点本质上是一个
通义千问-Max大模型。节点将基于内置的Prompt配置(暂不支持自定义),仿照种子的格式,通过替换【任务描述】部分或【待分析内容】部分生成增强数据。假如生成样本数为10,任务描述增强占比为0.3,表示新生成的10条增强数据中,30%(3条)的【任务描述】部分会被大模型替换为等价表述,同时【待分析内容】部分不变;70%(7条)的【待分析内容】被大模型替换为等价表述,同时【任务描述】部分不变。该参数取值范围0到1。过滤相似度阈值
取值范围0.1到1。此阈值越低,系统接受新生成数据的标准越严格(避免加入高相似度,即高Rouge-L得分的数据,系统根据整条ChatML数据进行相似度判断), 从而减少数据重复。
系统会对大模型生成的待选增强数据进行评估。若相似度低于设定阈值,则采纳为增强数据;若高于阈值则丢弃。
Rouge-L通过计算生成文本与参考文本之间的最长公共子序列(LCS)长度来衡量相似度,越接近1表示生成的文本与参考文本越相似。
输出
输出本节点增强后的训练集,和变量
dataSetCount(表示增强后的训练集中messages的数量)。说明目前阿里云百炼无法标识增强后的训练集中哪些数据是本次新生成的,哪些是原有的,需要您使用其它第三方diff工具手动比较。
{ "messages": [ { "role": "system", "content": "你是一个AI助理。" }, { "role": "user", "content": " ##【任务描述】\n 亲爱的家人们,你们的任务是以小红书汽车销售博主的风格,根据我给出的<|标题|>,发挥想象,创作一篇生动有趣的推荐帖子哦。每段都要加上精选的表情符号,让内容更加有趣和互动,这样大家看得开心,更愿意点赞分享呢。\n\n开头要非常吸引人,让读者一眼就明白你要分享的是干货内容,激发他们继续阅读的兴趣。接下来,至少写三个与主题相关的段落,每个段落都要突出独特之处和吸引力,让大家阅读时感到超开心,趣味横生,好玩到无以复加。\n\n写作时记得运用表情符号,增加生动感。每个表情都有自己的个性,像锅一样,各自的脾气不同,你需要根据经验来巧妙选择。此外,可以参考一些小红书常见的词汇,比如“超棒”、“心动不已”、“不要错过”、“无忧无虑”、“引爆”、“十分优惠”等等。这样你的帖子就能更贴近小红书的风格,更受欢迎哦。\n\n最后,别忘了在“正文”结尾部分换行后加上我提供的“标签”!\n\n\n##\n ##【待分析内容】<|标题|>:\n国庆出游选电车20万内哪款最值?\n 请根据【任务描述】针对【待分析内容】进行分析,给出结果。" }, { "role": "assistant", "content": "国庆出游选电车20万内哪款最值?\n\n【国庆出游必备!20万内超值电车推荐】\n\n国庆长假即将来临,你是不是已经计划好了一场说走就走的旅行?但面对琳琅满目的新能源汽车市场,该如何选择一款既实用又高性价比的座驾呢?今天,本博主就为大家精心挑选了几款20万内的超值电车,让你的国庆出游更加无忧无虑、充满乐趣!\n\n**续航王者:比亚迪秦Pro EV**\n第一款推荐车型是比亚迪秦Pro EV。这款车拥有超长的续航里程,最高可达500公里以上!这意味着你可以毫无顾虑地踏上长途旅程,无需频繁寻找充电站。此外,秦Pro EV还配备了丰富的智能科技配置,如12.8英寸旋转大屏、DiLink智能网联系统等,让旅途中的娱乐和导航更加便捷。最重要的是,它的价格十分亲民,绝对物超所值!\n\n**颜值担当:小鹏G3i**\n如果你追求时尚与个性,那么小鹏G3i绝对是你的不二之选!这款车采用了流线型设计,外观极具未来感,无论是城市穿梭还是乡村探险,都能赚足回头率。内饰方面,小鹏G3i同样表现出色,全景天窗、Nappa真皮座椅、15.6英寸中控大屏。每一处细节都彰显出高级感。而且,它还配备了L2+级自动驾驶辅助系统,为你的出行安全保驾护航。\n\n**全能选手:广汽埃安AION Y**\n最后一款推荐车型是广汽埃安AION Y。这是一款综合性能出色的电动SUV,不仅拥有宽敞舒适的乘坐空间,还能提供高达500公里的续航里程。无论你是带着家人朋友出游,还是独自一人探索未知,AION Y都能满足你的需求。另外,它的智能化配置也非常丰富,包括ADiGO 3.0智驾互联生态系统、远程控制等功能,让驾驶变得更加轻松愉悦。\n\n总之,以上三款车型各有千秋,无论你是追求续航能力、时尚设计还是全能表现,总有一款适合你!亲爱的家人们,赶快行动起来吧,抓住这次国庆购车的好时机,开启一段精彩纷呈的旅程!\n\n#国庆出游 #新能源汽车 #20万预算 #比亚迪秦Pro EV #小鹏G3i #广汽埃安AION Y #超值电车推荐 #续航王者 #颜值担当 #全能选手 #智能科技 #自驾游攻略" } ], "foreignKey": "file-fe9bbd31fc6c4e659a53787331254617_3_d3d92a4208cb4376994feef8a3xxxxxx" }输出数据中##和
foreignKey为系统后添加,用于标识文本和层级结构信息。增强后的训练集可直接用于模型调优,您无需删除##和foreignKey,不会影响模型调优效果。节点示例:
下方示例中,用户待增强的训练集会被开始节点传递给数据增强节点。后者根据配置的场景和参数,对训练数据进行对应处理,最终从结束节点输出增强后训练集。

计费说明
当前为限时免费阶段,具体收费时间另行通知。
下一步
如果您对处理后的训练集感到满意,即可开始模型调优。