
模型观测功能可用于:
查看调用记录
指标监控与告警,如Token延时、调用时长、RPM(每分钟调用次数)、TPM(每分钟消耗Token数)和失败率
统计Token消耗
支持的模型
日志功能:目前仅支持部分模型。
qwen-max、qwen-max-latest、qwen-max-2025-01-25qwen-plus、qwen-plus-latestqwen-flashqwen-turbo、qwen-turbo-latestqwen3-max、qwen3-max-preview、qwen3-max-2025-09-23qwen3-235b-a22b、qwen3-235b-a22b-instruct-2507、qwen3-235b-a22b-thinking-2507qwen3-30b-a3b-thinking-2507、qwen3-30b-a3b-instruct-2507
监控模型运行
开通模型调用服务后,阿里云百炼会自动在模型观测看板中添加以下4类监控指标:
安全:识别对话中的违规内容,例如
内容安全错误次数。成本:评估模型的成本效益,例如
平均单次请求调用量。性能:观察模型的性能变化,例如
调用时长、首Token延时。错误:判断模型的稳定性,例如
失败次数、失败率。
您可基于上述指标创建告警,以便及时发现和处理异常。
步骤一:开通模型调用服务
如果阿里云百炼控制台页面顶部显示以下消息,主账号需要开通阿里云百炼的模型服务(可获得免费调用额度)。如果未显示该消息,则表示已开通。
 说明
说明如果开通服务时提示“您尚未进行实名认证”,请先进行实名认证。
开通后,系统会自动采集主账号下所有业务空间内的模型调用数据。当有直接或间接模型调用发生时,系统会自动收集并同步相关数据至模型观测(北京或新加坡)的列表中。
列表记录按“模型 + 业务空间”维度生成。新模型在首次数据同步完成后自动加入列表(普通监控的延迟通常为小时级,请耐心等待;如需分钟级的数据洞察,请使用高级监控)。
默认业务空间成员可查看所有业务空间的模型调用情况;子业务空间成员仅能查看当前空间的数据,无法切换查看其他业务空间数据。
步骤二:查看监控指标
查看 Token 消耗
在实际使用中,调整模型的参数、系统提示词等操作均会改变模型的Token消耗。为统计和精细化管理成本,模型观测提供成本监控相关功能:
汇总:按业务空间维度汇总模型的历史Token消耗,并可按时间范围和API Key进一步筛选。
追踪:记录每一次模型调用的Token消耗。
告警:设置Token消耗阈值,当指定模型出现异常消耗时,系统立即告警。
步骤一:开通模型调用服务
确保已开通模型调用服务。
步骤二:查看 Token 消耗或创建告警
查看模型历史 Token 消耗:
查看某次调用的 Token 消耗:
该功能目前仅适用于中国大陆版(北京地域)的部分模型。
使用主账号(或拥有足够权限的子账号)登录,在目标业务空间的模型观测页面,点击右上角的模型观测配置,按照指引依次开通审计日志和推理日志。
开通后,系统即开始记录该业务空间内每一次模型调用的输入与输出。从调用发生到日志被记录存在分钟级延迟,请耐心等待。
在模型观测列表中找到目标模型,点击其右侧操作列的日志。
日志页签展示该模型的实时推理调用记录,用量字段即为本次调用的Token消耗。
创建异常消耗告警:
请参见建立主动告警。
查看历史对话
该功能目前仅适用于中国大陆版(北京地域)的部分模型。
模型观测支持查看模型的每一次对话,包括输入、输出及耗时,是故障排查和内容审计的关键工具。
步骤一:开通日志
确保已开通模型调用服务。
使用主账号(或拥有足够权限的子账号)登录,在目标业务空间的模型观测页面,点击右上角的模型观测配置,按照指引依次开通审计日志和推理日志。
开通后,系统即开始记录该业务空间内每一次模型调用的输入与输出。从调用发生到日志被记录存在分钟级延迟,请耐心等待。
如需停止记录,只需在模型观测配置中关闭推理日志即可。
步骤二:查看历史对话
在模型观测列表中找到目标模型,点击其右侧操作列的日志。
日志页签展示该模型的实时推理调用记录,请求和响应字段分别对应本次调用的输入与输出。
建立主动告警
模型的静默失败(如超时、Token消耗突增),传统应用日志难以发现。模型观测支持对监控指标(如成本、失败率、响应延迟)设置告警。一旦指标出现异常,系统立即告警。
步骤一:开启高级监控
确保已开通模型调用服务。
使用主账号(或拥有足够权限的子账号)登录,在目标业务空间的模型观测(北京或新加坡)页面,点击右上角的模型观测配置。
在高级监控区域,手动开启性能和用量指标监控。
步骤二:创建告警规则
接入 Grafana 与自建应用
模型观测的监控指标数据存储在您的私有Prometheus实例中,并支持标准的Prometheus HTTP API,可用于接入 Grafana 或您的自建应用进行可视化分析。
步骤一:获取数据源HTTP API地址

步骤二:接入 Grafana 或自建应用
接入自建应用
通过Prometheus HTTP API获取监控数据的示例如下。完整 API 用法,请参考Prometheus HTTP API文档。
示例1:查询阿里云账号下全部业务空间在指定时间范围内(2025年11月20日全天,UTC时间)所有模型的Token消耗(query=
model_usage),步长step=60s。示例
参数说明
GET {HTTP API}/api/v1/query_range?query=model_usage&start=2025-11-20T00:00:00Z&end=2025-11-20T23:59:59Z&step=60s Accept: application/json Content-Type: application/json Authorization: Basic base64Encode(AccessKey:AccessKeySecret)query:
query对应的值可替换为下方监控指标列表中的任意指标名称。HTTP API:
{HTTP API}需替换为前面步骤一获取的HTTP API地址。Authorization:需将阿里云账号的
AccessKey:AccessKeySecret拼接后进行Base64编码,并以Basic 编码后字符串的形式提供。示例值:Basic TFRBSTV3OWlid0U4XXXXU0xb1dZMFVodmRsNw==
请注意:AccessKey及AccessKey Secret与前面步骤一的Prometheus实例必须归属同一阿里云账号。
示例2:在示例1基础上增加筛选,仅获取指定模型(model=
qwen-plus)在指定业务空间(workspace_id=llm-nymssti2mzww****)内的Token消耗。示例
说明
GET {HTTP API}/api/v1/query_range?query=model_usage{workspace_id="llm-nymssti2mzww****",model="qwen-plus"}&start=2025-11-20T00:00:00Z&end=2025-11-20T23:59:59Z&step=60s Accept: application/json Content-Type: application/json Authorization: Basic base64Encode(AccessKey:AccessKeySecret)query:通过
{}包裹多个过滤条件,条件之间以英文逗号分隔,例如:{workspace_id="值1",model="值2"}。支持的过滤条件(LabelKey)清单如下。LabelKey
描述
user_id
阿里云账号ID。
RAM用户为UID。如何获取
apikey_id
API Key ID(非API Key),可在密钥管理(中国大陆版 | 国际版)页面获取。
 说明
说明apikey_id 值为 -1 表示调用源自阿里云百炼控制台,而非通过API。
workspace_id
业务空间ID。如何获取
model
模型。
protocol
协议类型。可能取值:
HTTP:HTTP非流式
SSE:HTTP流式
WS:Websocket协议
sub_protocol
子协议。可能取值:
DEFAULT:同步调用
ASYNC:异步调用
常见于图像生成模型。文本生成图像
status_code
HTTP状态码。
仅
model_call_count监控指标支持该LabelKey。error_code
错误码。
仅
model_call_count监控指标支持该LabelKey。usage_type
用量类型。
仅
model_usage监控指标支持该LabelKey。可能取值:
total_tokens
input_tokens
output_tokens
cache_tokens
image_tokens
audio_tokens
video_tokens
image_count
audio_count
video_count
duration
characters
audio_tts
times
接入 Grafana
在 Grafana(自建或阿里云 Grafana 服务)中添加模型观测数据源。此处以Grafana 10.x(英文版)为例。其他版本的操作类似,详情请参考Grafana官方文档。
添加数据源:
使用管理员账号登录Grafana。点击页面左上角的
 图标,选择。点击+ Add new data source,数据源类型选择Prometheus。
图标,选择。点击+ Add new data source,数据源类型选择Prometheus。在Settings页签配置数据源信息:
Name:输入自定义的名称。
Prometheus server URL:输入前面步骤一获取的HTTP API地址。
Auth:开启Basic auth,并设置User(阿里云账号的AccessKey)及Password(阿里云账号的AccessKey Secret)。
AccessKey及AccessKeySecret与前面步骤一的Prometheus实例必须归属同一阿里云账号。
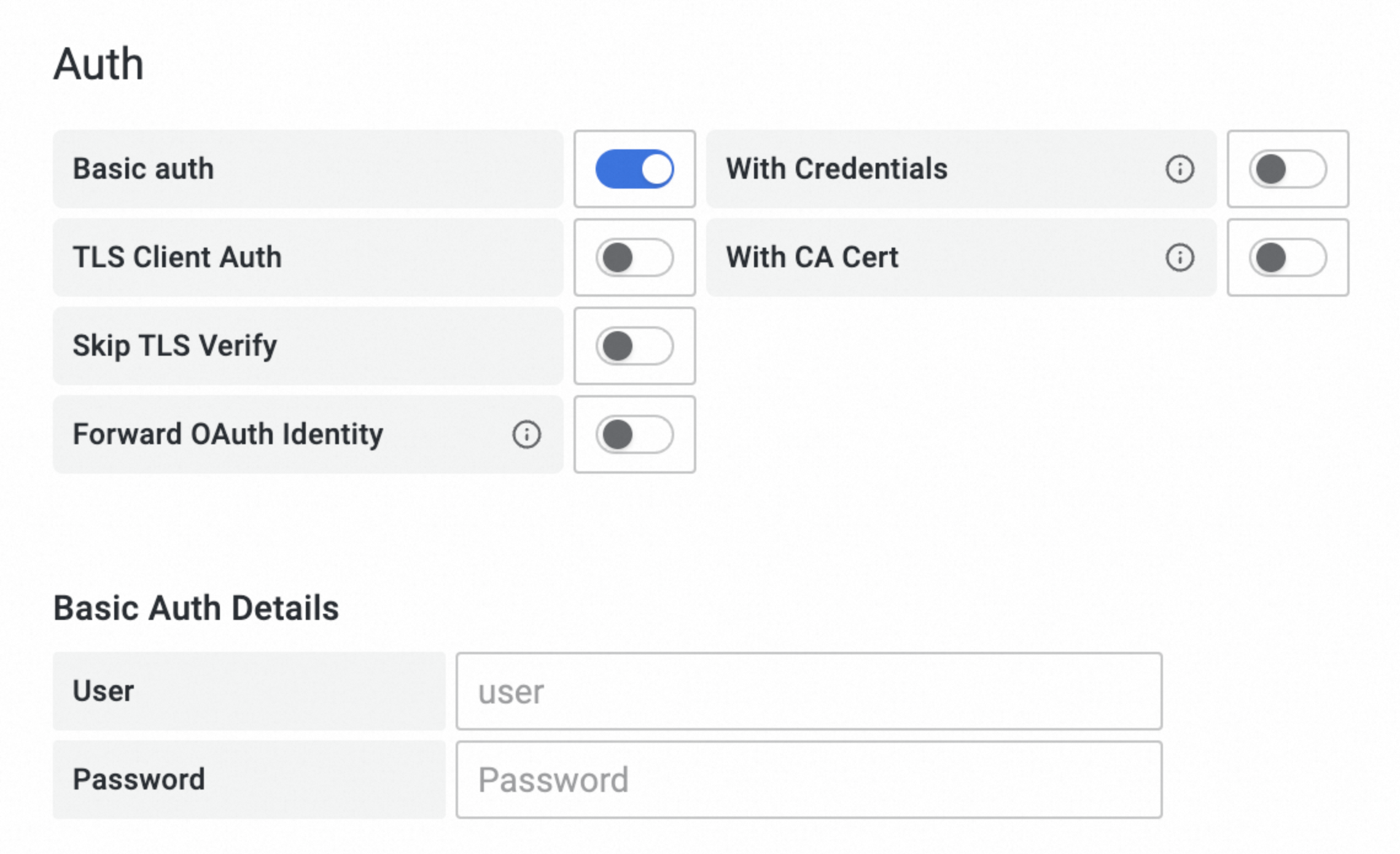
点击页签底部的Save & Test。
指标查询:
点击Grafana页面左上角的
 图标,在左侧导航栏中点击Dashboards。
图标,在左侧导航栏中点击Dashboards。点击Dashboards页面右侧的创建一个新的仪表盘。
点击+ Add visualization,并选择您刚创建的数据源。
在Edit Panel页面点击Query页签,在A区域的Label filters字段中选择_name_及指标名称。以查询模型Token消耗
model_usage为例:示例
说明

图中
_name_对应的值(model_usage)可替换为下方监控指标列表中的任意指标名称。增加以下Label filters进一步筛选:
LabelKey
描述
user_id
阿里云账号ID。
RAM用户为UID。如何获取
apikey_id
API Key ID(非API Key),可在密钥管理(中国大陆版 | 国际版)页面获取。
说明apikey_id 值为 -1 表示调用源自阿里云百炼控制台,而非通过API。
workspace_id
业务空间ID。如何获取
model
模型。
protocol
协议类型。可能取值:
HTTP:HTTP非流式
SSE:HTTP流式
WS:Websocket协议
sub_protocol
子协议。可能取值:
DEFAULT:同步调用
ASYNC:异步调用
常见于图像生成模型。文本生成图像
status_code
HTTP状态码。
仅
model_call_count监控指标支持该LabelKey。error_code
错误码。
仅
model_call_count监控指标支持该LabelKey。usage_type
用量类型。
仅
model_usage监控指标支持该LabelKey。可能取值:
total_tokens
input_tokens
output_tokens
cache_tokens
image_tokens
audio_tokens
video_tokens
image_count
audio_count
video_count
duration
characters
audio_tts
times
点击Run queries进行查询。
如果图表中成功渲染出数据,则说明配置成功。否则请检查:1)填写的HTTP API地址或AccessKey及AccessKeySecret是否正确;2)前面步骤一的Prometheus实例中是否有监控数据。
监控模式对比模型观测提供两种监控模式:普通监控和高级监控。 普通监控:作为基础服务提供,随模型调用服务开通自动开启,不支持关闭。 高级监控:需主账号(或拥有足够权限的子账号)在目标业务空间的模型观测(北京或新加坡)界面手动开启,支持关闭。仅记录开启高级监控后的调用数据。
| ||||||||||||||||||||||||||||
配额与限制
数据保留周期:普通和高级监控的数据默认均保留30天。如需查询更早的用量信息,请通过费用与成本页面查询。
告警模板限制:每个业务空间最多可创建100个告警模板。
API限制:模型观测的监控指标数据请通过Prometheus HTTP API查询。
替代方案:如需通过API获取单次调用Token消耗,可在每次调用模型时从响应中的
usage字段提取当前调用数据。该字段结构示例如下(更多说明请参见通义千问API参考):{ "prompt_tokens": 3019, "completion_tokens": 104, "total_tokens": 3123, "prompt_tokens_details": { "cached_tokens": 2048 } }
计费说明
普通监控:免费。
高级监控:开启后,分钟级的监控数据将写入云监控CMS服务并产生费用。具体计费方式参见云监控CMS计费概述。
推理日志:开启后,分钟级的日志数据将写入日志服务SLS服务并产生费用。具体计费方式参见日志服务SLS计费概述。
常见问题
为什么调用了模型,但在模型观测中查不到调用次数和消耗Token数?
按以下步骤排查:
数据延迟:确认是否已等待足够的数据同步时间。普通监控延迟为小时级,高级监控为分钟级。
业务空间:如果当前处于某个子业务空间,则只能看到该空间内的数据。切换到默认业务空间可查看所有数据。
调用大模型时出现超时,可能是什么原因?
常见原因:
输出内容过长:模型生成内容过多导致整体耗时超过客户端等待上限。建议改用流式输出方式,以更快获得首个Token。
网络问题:检查客户端与阿里云服务之间的网络连接是否稳定。
使用子账号开通高级监控,应如何配置权限?
操作步骤:
为子账号配置
AliyunBailianFullAccess全局管理(阿里云百炼)权限。为子账号配置
模型观测-操作(或管理员)页面权限,使其能在模型观测页面执行写入类操作。创建并授予子账号创建服务关联角色系统策略。
登录RAM控制台,在左侧导航栏,选择,然后点击页面上的创建权限策略。
点击脚本编辑,将以下内容粘贴至策略输入框后,点击确定。
{ "Version": "1", "Statement": [ { "Action": "ram:CreateServiceLinkedRole", "Resource": "*", "Effect": "Allow" } ] }输入权限策略名称
CreateServiceLinkedRole后,点击确定。在左侧导航栏,选择。从页面列表中找到待授权的子账号,然后点击子账号操作列的添加权限。
从权限策略列表中,选择刚创建的权限策略(CreateServiceLinkedRole),然后点击确认新增授权。至此,子账号拥有了创建服务关联角色的权限。
使用子账号开通推理日志,应如何配置权限?
操作步骤:
为子账号配置
AliyunBailianFullAccess全局管理(阿里云百炼)权限。为子账号配置
模型观测-操作(或管理员)页面权限,使其能在模型观测页面执行写入类操作。创建并授予子账号创建服务关联角色系统策略。
登录RAM控制台,在左侧导航栏,选择,然后点击页面上的创建权限策略。
点击脚本编辑,将以下内容粘贴至策略输入框后,点击确定。
{ "Version": "1", "Statement": [ { "Action": "ram:CreateServiceLinkedRole", "Resource": "*", "Effect": "Allow" } ] }输入权限策略名称
CreateServiceLinkedRole后,点击确定。在左侧导航栏,选择。从页面列表中找到待授权的子账号,然后点击子账号操作列的添加权限。
从权限策略列表中,选择刚创建的权限策略(CreateServiceLinkedRole),然后点击确认新增授权。至此,子账号拥有了创建服务关联角色的权限。
完成以上所有权限配置后,返回模型观测页面,使用子账号重试开启推理日志。
附录
名词解释
名词 | 解释 |
实时推理 | 指对模型的所有直接和间接调用,主要涵盖以下场景:
|
批量推理 | 对于无需实时响应的场景,通过OpenAI兼容-Batch接口以离线方式进行的大规模数据处理。 |