
开放数据处理服务 MaxCompute(原 ODPS)是一个大规模计算平台。若您的 OpenSearch-行业算法版数据源自 MaxCompute,可在应用中配置 MaxCompute 源信息。该方案支持 MaxCompute 三级表结构。触发索引重建任务后,系统将自动拉取表中的全量数据;后续增量数据则需通过调用 SDK API 进行推送。
设置账号AccessKey
目前在OpenSearch-行业算法版中配置MaxCompute数据源后,OpenSearch-行业算法版是通过用户填写的accessKey和accessKeySecret去下载MaxCompute数据表的数据,因此在配置MaxCompute数据源之前,需要确定账号的accessKey和accessKeySecret。
MaxCompute和OpenSearch需要同属于一个账号。
-
如果用户确定可以使用主账号的accessKey和accessKeySecret,那么即可用主账号的accessKey和accessKeySecret去访问该账号下的MaxCompute中project的表。
-
如果使用主账号的accessKey和accessKeySecret风险较大,也可以通过子账号去配置,配置步骤如下。
-
在该主账号下创建一个子账号,详情可参考RAM(子账号)的创建及授权;
-
在MaxCompute中为该子账号添加成员。
在 MaxCompute 项目管理的成员管理弹窗中,在左侧搜索成员名列表中搜索并选择目标 RAM 子账号,单击向右箭头按钮将其移至右侧已/待添加成员名列表,也可通过底部手动添加成员输入框直接输入成员名(多个成员名用逗号分隔),然后单击确定。
-
添加成员之后,在MaxCompute数据开发界面查看其账号,命令为
list users;,更多参考使用控制台(查询编辑器)连接:OK OK OK OK OK OK OK OK A xxx RAM$o; xxx h_test@test.xxx xxx st_1 2022-02-10 18:34:33 INFO ===xxx===================================================== 2022-02-10 18:34:33 INFO Exit code of the Shell command 0 2022-02-10 18:34:33 INFO -- Invocation of Shell command completed --- -
整体复制该账号名,然后给该账号赋权(xxx 表示3中复制的账号):
-- 1.project list权限 grant CreateInstance,List on project zy_ts_test to user xxx; -- 2.表的select,describe,download权限 GRANT select,describe,download ON TABLE people_info TO USER xxx; -- 3.odps表的label权限(可选) set label 2 to USER xxx; -- 查询指定用户的权限信息和绑定的角色信息 show grants for xxx;
授权完成后即可在opensearch中配置MaxCompute数据源。
配置MaxCompute 数据源
-
在应用配置页面,选择通过数据源配置应用,然后选择MaxCompute数据源。
-
在数据源类型列表中,单击MaxCompute,选择MaxCompute数据源。
-
点击新建数据库,配置MaxCompute(原ODPS)信息,填写project,以及已经在 MaxCompute授权的账号的accessKey和accessKeySecret:
填写完成后,单击连接按钮。
-
连接后选择需要配置的数据表,如以下示例添加三级表:
在选择数据源对话框中,单击MaxCompute页签,在选择数据库区域选择已连接的数据库,然后在选择数据表区域勾选目标三级表(例如
default.item_table、opensearch.bank_data),通过穿梭框将其移至已选择列表后,单击确定。
完成后,系统会自动映射出对应的字段,用户可根据业务需求,进行微调,符合需求后点击下一步:
自动映射后的字段配置表包含字段名称、主键、类型、外表连接和操作列,用户可为每个字段设置类型(如 TEXT、INT)、指定主键、配置外表连接,并支持删除或新增字段。
配置应用结构时,OpenSearch-行业算法版规定必须要有一张主表,并且各个表需要配置唯一的主键字段。
-
配置索引结构,可根据用户的检索需求,选择合适的分析器,详情可参考索引结构,符合需求后点击下一步:
示例中配置了两个索引:default 索引包含 country、source_buy_cnt、city、item_type、last_modify_time、channel、title、subscribe_cnt 字段,分析方式选择 中文-通用分析;id 索引包含 custom_pk_id 字段,分析方式选择 关键字。
-
配置数据源(包括:配置字段映射关系,选择分区信息,选择数据同步并发控制机制);
在数据源配置页面,单击+ 添加数据源添加 MaxCompute 数据源。
5.1. 配置字段映射关系:点击操作栏中的编辑按钮,OpenSearch-行业算法版为MaxCompute(原ODPS)的数据提供了若干数据源插件说明,如要使用,则在配置字段对应关系的同时,点击“内容转换”列中的“+”符号,则会在源字段被同步到OpenSearch-行业算法版之前,先进行内容转换,再进行同步。如果内容转换插件由于配置错误、无法连接等错误失效,则源字段仍然会被同步到目标字段,只是内容不会被转换。
5.2. 选择分区信息:根据MaxCompute(原ODPS)数据特性,OpenSearch-行业算法版允许用户根据具体需要来指定导入的分区,支持正则表达式,表示导入前一天的数据,结合应用基本信息-索引重建-定时索引重建功能,可以实现每天导入新分区数据的效果。
正则表达式 (等号/逗号/分号/双竖线为系统保留,每天自动导入前1天分区全量数据条件例子ds=%Y%m%d || -1 days)
ds为分区字段名,“=”两边不允许有空格等其他不可见字符
不同场景下MaxCompute(原ODPS)分区条件用法,参考如下所示:
-
1: 支持多个分区过滤规则,不同的分区过滤规则用分号分隔,如pt=1;pt=2将匹配满足分区字段pt=1或者pt=2的所有分区。
-
2: 分区过滤规则,支持指定多个分区字段的值,不同分区字段用逗号分隔,如:pt1=1,pt2=2,pt3=3 将匹配同时满足pt1=1,pt2=2,pt3=3的所有分区【多分区目前不支持function功能,即不支持 %Y%m%d || -1 days这样的,单分区是可以支持的】。
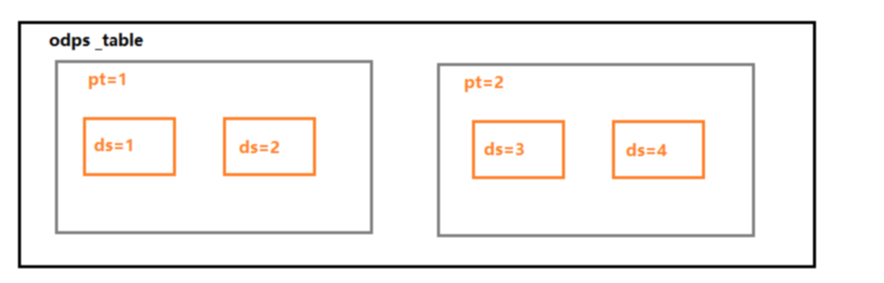
例:(如上图所示一张odps表中有pt分区下有ds分)
-
多个分区:pt=1;pt=2 将同步pt=1 和 pt=2分区下的所有数据
-
指定多个分区字段的值:pt=1,ds=1 将同步pt=1同时ds=1的分区数据
-
不支持情况:pt=1,ds=%Y%m%d || -1 days 或者pt=1;pt=%Y%m%d || -1 days 该类情况暂不支持
-
3: 分区字段的值支持通配符 *,表示该分区字段可以为任意的值,这种情况下,过滤规则中也可不写该字段
-
4: 分区字段的值支持正则表达式,如pt=[0-9]* 将匹配pt值为数字的所有分区。
-
5: 分区字段的值支持时间匹配,匹配规则: pt=包含格式化时间的分区列值||时间间隔表达式。如ds=%Y%m%d || -1 days,表示分区字段为ds,格式为20150510,需要访问1天前的数据。
-
5.1 格式化时间参数支持标准的时间格式参数,如下表
-
5.2 时间间隔表达式支持 +/- n week|weeks|day|days|hour|hours|minute|minutes|second|seconds|microsecond|microseconds, +号表示任务创建时间的表示n周/天/小时/分钟/秒/毫秒后,-号表示任务创建时间的表示n周/天/小时/分钟/秒/毫秒前。
-
5.3 系统默认会对所有过滤规则,按照+0 days进行时间参数替换,因此,需要注意的是,用于过滤的字段值不能包含下面这些字符串作为普通的字符串参数,如星期三创建的任务,pt=%abc 将匹配pt的值为Wedbc的分区,而不是pt=%abc的分区。
正则表达式全部可用参数及含义,参考如下:
%d: 日在这个月中的天数(是这个月的第几天)
%H: 小时(24小时制,[0, 23])
%m: 月份([01,12])
%M: 分钟([00,59])
%S: 秒(范围为[00,61])
%y: 2个数字表示的年份
%Y: 4个数字表示的年份5.3. 选择数据同步并发控制机制:
当用户勾选【使用done文件】后,OpenSearch支持用户通过上传done文件的方式控制系统拉取全量数据的时机,保证全量数据的完整性。系统在开始从MaxCompute(原ODPS)拉全量数据之前会先判断一下当天的done文件是否存在,如果不存在则等待,默认等待1小时后超时。
-
用户需从odps官网下载odpscm,文件名为:odps_clt_release_64.tar.gz;
-
用户需要具有所在project空间的CreateResource权限;
-
安装后在用户程序中运行如下命令:其中done文件的命名规则为$prefix_%Y-%m-%d。$prefix: 文件名前缀,默认为表名,%Y-%m-%d:索引重建任务日期,系统定时任务目前支持的最小粒度为1天。
odpscmd -u accessid -p accesskey --project=<prj_name>-e "add file <done file>;" -
MaxCompute客户端odpscmd使用说明,请参考使用本地客户端(odpscmd)连接。
-
done文件内容为JSON格式,目前仅需包含如下内容,用于指定该批全量数据的时间戳(毫秒)【最多只保留3天增量,因此该时间点不可以超过3天】。
-
该时间戳表示需要回溯的增量数据时间点,如果不配置则默认从索引重建任务开始时间追加数据【最多只保留3天增量,因此该时间点不可以超过3天】。
-
【例如】全量数据是今天9点的,odps处理完毕后为10点,OpenSearch定时任务为10:30,则done文件需要指定为当天9点的毫秒值,在处理完全量后系统会追加当天9点后的增量,保证数据完整性;否则会从默认任务启动时间10:30开始追加,这样9:00~10:30期间的增量会丢失,该行为非常重要,需要特别注意。(当然,若没有增量,则无需配置该时间戳)。
-
高级版done文件内容相关说明。(提示:标准版中需设置的数据时间值也是类似原理,都是用来追索引重建期间API的增量数据的)。
{
"timestamp":"1234567890000"
}done file与数据时间的优先级:
-
ODPS数据源的“数据时间”目前是必选的,且优先于donefile;
-
用户如果只创建一个版本,就只需要指定“数据时间”,没有办法单独使用donefile;
-
用户如果需要使用定时索引重建,就必须“数据时间”和donefile都配置:第一个版本优先使用“数据时间”,之后的每一个版本都优先使用donefile;
OpenSearch-行业算法版支持三种阿里云数据源:RDS、MaxCompute(原ODPS)和PolarDB。RDS和PolarDB支持多表关联配置,一个应用可配置主表和外表,通过外表连接实现多表数据关联。MaxCompute(原ODPS)数据源每个实例只能配置一个数据库。OpenSearch不支持自建数据库或外部数据源。
如需区分测试和生产环境,创建独立的OpenSearch实例,分别配置不同数据源,实现环境隔离。
注意事项
目前 MaxCompute 数据源只支持全量同步,不支持增量同步。