
借助OSS Connector for AI/ML的高性能IO特性,充分发挥OSS高吞吐大带宽的性能优势,实现DeepSeek推理模型的快速加载。
OSS在AI场景的优势
优势 | 实现效果 |
高吞吐高并发 |
|
低成本分层存储 |
|
高可靠性 |
|
高效分发共享 |
|
使用OSS Connector for AI/ML实现大模型秒级加载
OSS Connector for AI/ML专为提升AI推理中的模型加载与数据访问效率而设计,无需修改推理框架即可无缝集成。其核心优势包括:
开箱即用:无缝集成主流框架,无需修改代码
百GB模型秒级加载:用户态I/O加速,性能较FUSE提升数倍
带宽100%利用:自研高并发网络模块打满OSS吞吐
智能预取缓存:内存热点数据预加载,显著降低推理延迟
实现单节点最优性能
步骤1:构建高性能计算与弹性网络环境
本教程以创建
ecs.g8i.48xlarge实例为例(该实例提供192核CPU + 1TiB内存+自带100Gbit/s基础网络带宽),保障足够的计算资源和基础网络带宽,支撑AI/ML任务及OSS数据传输需求。在弹性网卡页面,创建弹性网卡。弹性网卡必须与ECS实例位于同一专有网络。
通过多网卡聚合带宽,实现VPC内OSS的高吞吐访问,突破单网卡带宽限制。
查看弹性网卡接口信息。
其中
local 172.16.6.121 dev eth0和local 172.16.6.122 dev eth1两条本地路由条目表示两块弹性网卡已分别获取到IP地址。(xxx ]# ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether xxx brd ff:ff:ff:ff:ff:ff altname enp2s1 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether xxx brd ff:ff:ff:ff:ff:ff altname enp7s2 (xxx ]# ip route show table local broadcast 127.0.0.0 dev lo proto kernel scope link src 127.0.0.1 local 127.0.0.0/8 dev lo proto kernel scope host src 127.0.0.1 local 127.0.0.1 dev lo proto kernel scope host src 127.0.0.1 broadcast 127.255.255.255 dev lo proto kernel scope link src 127.0.0.1 broadcast 172.16.6.0 dev eth0 proto kernel scope link src 172.16.6.121 broadcast 172.16.6.0 dev eth1 proto kernel scope link src 172.16.6.122 local 172.16.6.121 dev eth0 proto kernel scope host src 172.16.6.121 local 172.16.6.122 dev eth1 proto kernel scope host src 172.16.6.122 broadcast 172.16.6.255 dev eth0 proto kernel scope link src 172.16.6.121 broadcast 172.16.6.255 dev eth1 proto kernel scope link src 172.16.6.122 (xxx ]# ip route show table main default via 172.16.6.253 dev eth0 proto dhcp src 172.16.6.121 metric 100 default via 172.16.6.253 dev eth1 proto dhcp src 172.16.6.122 metric 101 172.16.6.0/24 dev eth0 proto kernel scope link src 172.16.6.121 metric 100 172.16.6.0/24 dev eth1 proto kernel scope link src 172.16.6.122 metric 101
步骤2:准备模型数据并安装推理框架
获取DeepSeek-R1-GGUF格式Q8量化版本的模型数据。该模型具备较高的推理性能与较低的内存占用,适用于评估大规模模型加载与部署效率。
使用推理框架为 llama.cpp,支持 GGUF 格式模型的高效加载与运行。
从 GitHub 克隆
llama.cpp仓库到本地。git clone https://github.com/ggerganov/llama.cpp进入项目目录。
cd llama.cpp创建构建目录。
mkdir build生成构建配置。
cmake -B build -DCMAKE_BUILD_TYPE=Release执行编译。
cmake --build build --config Release
步骤3:安装OSS Connector并启动推理服务
安装并配置OSS Connector。
下载安装包。
wget https://gosspublic.alicdn.com/oss-connector/oss-connector-lib-1.1.0rc7.x86_64.rpm安装OSS Connector。
yum install -y oss-connector-lib-1.1.0rc7.x86_64.rpm配置OSS Connector。
修改
/etc/oss-connector/config.json路径下的配置文件。{ "logLevel": 1, "logPath": "/var/log/oss-connector/connector.log", "auditPath": "/var/log/oss-connector/audit.log", "expireTimeSec": 120, "prefetch": { "vcpus": 32, "workers": 32 } }修改环境变量。
export OSS_ACCESS_KEY_ID=LTA******** export OSS_ACCESS_KEY_SECRET=tg******** export OSS_REGION=cn-beijing export OSS_ENDPOINT=oss-cn-beijing-internal.aliyuncs.com export OSS_PATH=oss://<BUCKET-NAME>/deepseek/DeepSeek-R1-Q8_0/ export MODEL_DIR=/tmp/model/DeepSeek-R1-Q8_0/ export HTTP_SOURCE_IP=172.xx.x.xxx,172.xx.x.xxx环境变量 KEY
说明
OSS_ACCESS_KEY_ID
阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret。
使用临时访问令牌进行权限配置时,请设置为临时访问凭证的AccessKey ID和AccessKey Secret。
使用OSS Connector需要具有目标Bucket对应目录的oss:ListObjects 权限。如果访问的Bucket及文件支持匿名访问,可以不设置 OSS_ACCESS_KEY_ID 和 OSS_ACCESS_KEY_SECRET环境变量,或设置为空字符串。
OSS_ACCESS_KEY_SECRET
OSS_SESSION_TOKEN
临时访问令牌。当使用从STS获取的临时访问凭证访问OSS时,需要设置此参数。
使用阿里云账号或者RAM用户的AccessKey ID和AccessKey Secret进行权限配置时,将该字段设置为空字符串。
OSS_ENDPOINT
指定OSS服务Endpoint,示例值为
http://oss-cn-beijing-internal.aliyuncs.com。当不指定协议类型时,默认使用HTTPS协议。建议在内网等安全环境中使用HTTP协议,以达到更好的性能。OSS_REGION
指定OSS Region ID,示例值为 cn-beijing。如不指定则可能出现鉴权失败。
OSS_PATH
OSS模型路径,格式为 oss://bucketname/path/,示例值为
oss://examplebucket/deepseek/DeepSeek-R1-Q8_0/。MODEL_DIR
本地模型路径。示例值为:
/tmp/model/DeepSeek-R1-Q8_0/。HTTP_SOURCE_IP
启动推理服务。
LD_PRELOAD=/usr/local/lib/libossc_preload.so ENABLE_CONNECTOR=1 llama-server -m /tmp/model/DeepSeek-R1-Q8_0/DeepSeek-R1.Q8_0-00001-of-00015.gguf -t 48 -c 1024 --host 0.0.0.0 --port 9090 --numa isolate
步骤4:性能观测
启动推理服务后,一分钟内云服务器内网带宽变化如下:
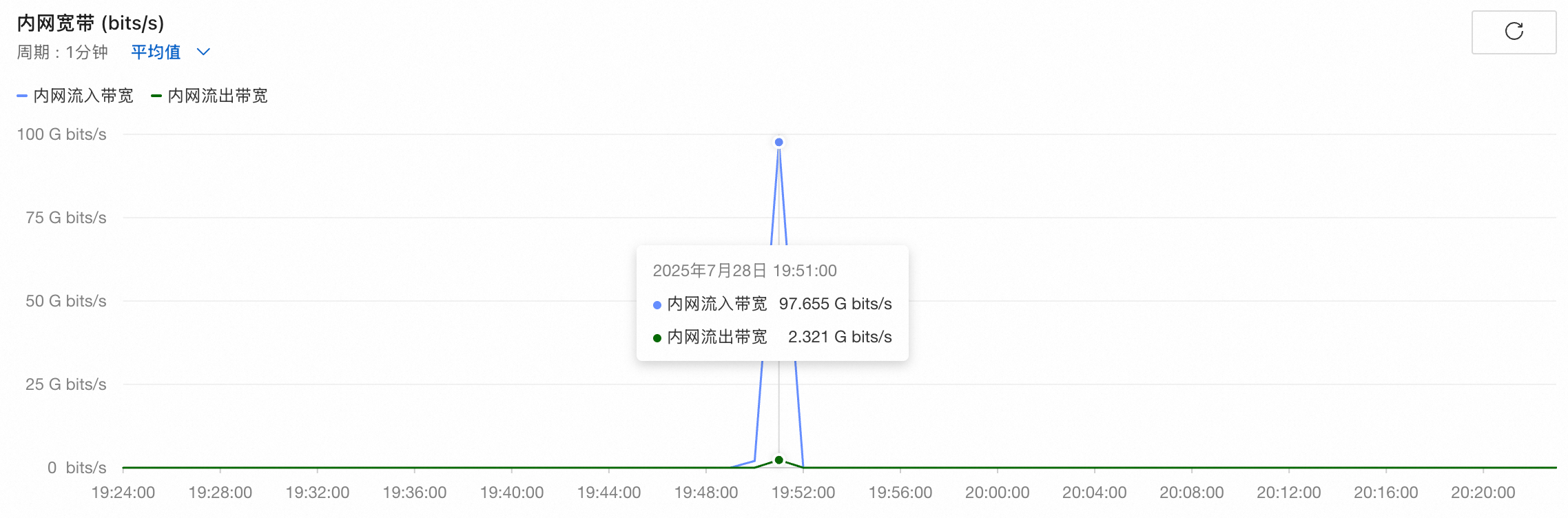
通过云服务器观测网卡流量,发现云服务器双网卡网络基础带宽持续跑满100Gbit/s:
31秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
32秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
32秒 eth0 4685527.00 2914154.00 6576352.14 233729.15 0.00 0.00 0.00 0.00
32秒 eth1 4431023.00 0.00 6219142.01 0.00 0.00 0.00 0.00 0.00
32秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
33秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
33秒 eth0 4643666.00 2968261.00 6517694.15 238021.36 0.00 0.00 0.00 0.00
33秒 eth1 4472967.00 0.00 6278001.55 0.00 0.00 0.00 0.00 0.00
33秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
34秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
34秒 eth0 4698994.00 3100866.00 6595290.37 250645.66 0.00 0.00 0.00 0.00
34秒 eth1 4417638.00 0.00 6200418.34 0.00 0.00 0.00 0.00 0.00
34秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
35秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
35秒 eth0 4673228.00 2882323.00 6559128.50 229996.60 0.00 0.00 0.00 0.00
35秒 eth1 4443430.00 1.00 6236539.08 0.04 0.00 0.00 0.00 0.00
35秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
36秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
36秒 eth0 4706184.00 2963548.00 6605398.16 237661.12 0.00 0.00 0.00 0.00
36秒 eth1 4410386.00 0.00 6190296.66 0.00 0.00 0.00 0.00 0.00
36秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
37秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
37秒 eth0 4723438.00 2932274.00 6629798.87 235513.98 0.00 0.00 0.00 0.00
37秒 eth1 4392835.00 0.00 6165661.72 0.00 0.00 0.00 0.00 0.00下表为本次实践实际统计数据,并对比其他加载方案如ossfs。
加载工具 | 推理服务启动端到端耗时(包含访问OSS和模型加载) | OSS单账号带宽限制 | 实际使用带宽 | 从OSS读取数据总量 |
OSS connector For AI/ML | 81s | 100Gbit/s | 100Gbit/s | 664GB |
ossfs 2.0 | 257s | 100Gbit/s | 20Gbit/s | 666GB |
ossfs 1.0 | 1020s | 100Gbit/s | 6.4Gbit/s | 782GB |
大规模推理节点部署方案
基于P2P方案加速大规模推理节点启动
OSS connector For AI/ML 可与自研的 P2P 分发系统协同工作,实现同一批次模型数据在多节点间的高效共享与传输。该 P2P 系统针对多节点同时加载相同数据的典型推理部署场景,显著降低了对中心数据源(OSS)的访问压力,提升整体带宽利用效率。系统支持按需分发机制,具备对大文件的随机读取与流式读取能力,在保障准确性的同时优先降低单次数据片段的访问延迟。同时,底层设计支持高并发访问,能够满足大规模推理任务对分发效率与稳定性的双重要求。
有效削峰限流:通过节点间数据共享,显著缓解海量推理节点同时启动时对 OSS 带宽的冲击,极大降低中心数据源的瞬时压力。
性能无损传递:仍依托 Connector 从 OSS 拉取原始数据,充分发挥 Connector 的性能,确保首次访问的低延迟和高吞吐。
天然支持横向扩展:支持推理节点的大规模水平扩展,具备良好的并发启动能力,即使在百节点级别的集群中,启动耗时仍与单节点相近。
显著降低回源量:通过本地缓存与 P2P 分发机制,最大限度避免重复拉取,有效控制 OSS 的回源流量,提升整体资源利用效率。
实验环境和测试方法
使用DeepSeek-R1 模型的 GGUF 格式 Q8 量化版本,总容量664GB。推理框架 llama.cpp。
使用50台机型 ecs.g8i.48xlarge 云服务器共同组建推理集群。实践中借助阿里云容器服务 ACK 平台对推理集群进行统一管理与部署。推理服务作为容器中的主进程运行,确保服务启动的高效性与稳定性,实现了容器化环境下的灵活调度与资源管理。
llama.cpp 推理框架的启动日志时间戳作为模型加载完成的时间参考点,用于衡量从启动到模型可用之间的耗时。
在每个推理节点上均独立进行计时,并统计以下关键性能指标:各节点的平均加载耗时、最长加载耗时,以及在整个部署过程中从 OSS 请求的数据总量,以全面评估模型加载过程中的带宽利用效率与系统整体性能表现。
测试结果
推理服务启动端到端平均耗时(包含访问OSS和模型加载) | OSS单账号带宽限制 | 从OSS读取数据总量 |
127s | 100Gbit/s | 1262GB |
总结
在本次测试中,推理节点端到端平均启动耗时约为单节点的 1.5 倍,实测结果说明在节点数量大幅增加的情况下,整体部署耗时并未显著增长。即使在高并发环境下,系统也能保持稳定的加载性能和资源调度效率,该方案展现出良好的横向扩展能力。另外,集群整体回源数据量仅为模型总容量的约两倍,有效控制了对中心存储服务的访问开销,显著削弱了大规模集群并发加载模型对后端存储服务造成的瞬时带宽冲击。