
OSS-HDFS服务是一款云原生数据湖存储产品。基于统一的元数据管理能力,在完全兼容HDFS文件系统接口的同时,提供充分的POSIX能力支持,能更好地满足大数据和AI等领域的数据湖计算场景。本文介绍Hadoop如何通过JindoSDK访问OSS-HDFS服务。
前提条件
已开通并授权访问OSS-HDFS服务。具体操作,请参见开通OSS-HDFS服务。
什么是OSS-HDFS服务
通过OSS-HDFS服务,无需对现有的Hadoop、Spark大数据分析应用做任何修改。通过简单的配置即可像在原生HDFS中那样管理和访问数据,同时获得OSS无限容量、弹性扩展、更高的安全性、可靠性和可用性支撑。
作为云原生数据湖基础,OSS-HDFS在满足EB 、亿级文件管理服务、TB级吞吐量的同时,全面融合大数据存储生态,除提供对象存储扁平命名空间之外,还提供了分层命名空间服务。分层命名空间支持将对象组织到一个目录层次结构中进行管理,并能通过统一元数据管理能力进行内部自动转换。同时相较于传统HDFS的元数据管理节点NameNode的主备冗余方式,OSS-HDFS的元数据管理采用多节点多活冗余机制,具备更好的数据冗余能力。对Hadoop用户而言,无需做数据复制或转换就可以实现像访问本地HDFS一样高效的数据访问,极大提升整体作业性能,降低了维护成本。
关于OSS-HDFS服务的应用场景、服务特性、功能特性等更多信息,请参见什么是OSS-HDFS服务。
步骤一:创建专有网络VPC并添加云服务器ECS实例
创建允许内网访问OSS-HDFS服务的专有网络VPC。
登录专有网络管理控制台。
在专有网络页面,单击创建专有网络。
创建专有网络VPC时,需确保创建的VPC与待开启OSS-HDFS服务的Bucket位于相同的地域(Region)。创建VPC的具体操作,请参见创建专有网络和交换机。
添加云服务器ECS实例。
单击已创建的VPC ID,然后单击资源管理页签。
在包含基础云资源区域,单击云服务器(ECS)右侧的
 。
。在实例页面,进行ECS实例的创建。
创建ECS实例时,需确保该ECS实例与已创建的专有网络VPC位于相同地域。创建ECS实例的具体操作,请参见选购ECS实例。
步骤二:创建Hadoop运行环境
安装Java环境。
在已创建的ECS示例右侧,单击远程连接。
关于远程连接ECS实例的具体操作,请参见ECS远程连接方式概述。
检查JDK版本。
java -version可选:如果JDK为1.8.0以下版本,请卸载已有的JDK。如果JDK为1.8.0或以上版本,请跳过此步骤。
rpm -qa | grep java | xargs rpm -e --nodeps安装Java。
sudo yum install java-1.8.0-openjdk* -y执行以下命令,打开配置文件。
vim /etc/profile添加环境变量。
如果提示当前JDK Path不存在,请前往/usr/lib/jvm/查找java-1.8.0-openjdk。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/jre/lib/rt.jar export PATH=$PATH:$JAVA_HOME/bin使环境变量生效。
source /etc/profile
启用SSH服务。
安装SSH服务。
sudo yum install -y openssh-clients openssh-server启用SSH服务。
systemctl enable sshd && systemctl start sshd生成SSH密钥,并将生成的密钥添加到信任列表。
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
安装Hadoop。
下载Hadoop安装包。
以下载3.4.0版本的Hadoop安装包为例。如使用其他版本的Hadoop,请替换为对应的Hadoop安装包名称。如何获取Hadoop安装包,请参见Hadoop。
wget https://downloads.apache.org/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz解压安装包。
tar xzf hadoop-3.4.0.tar.gz将安装包移动到常用位置。
mv hadoop-3.4.0 /usr/local/hadoop配置环境变量。
配置Hadoop环境变量。
vim /etc/profile export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$PATH source /etc/profile更新Hadoop配置文件中的HADOOP_HOME。
cd $HADOOP_HOME vim etc/hadoop/hadoop-env.sh将${JAVA_HOME}替换为实际路径。
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk
可选:如果提示目录不存在,请执行以下命令,使环境变量生效。
cd $HADOOP_HOME/etc/hadoop更新配置文件core-site.xml以及hdfs-site.xml。
更新配置文件core-site.xml并添加属性。
<configuration> <!-- 指定HDFS中NameNode的地址。--> <property> <name>fs.defaultFS</name> <!--替换为主机名或localhost。--> <value>hdfs://localhost:9000</value> </property> <!--将Hadoop临时目录修改为自定义目录。--> <property> <name>hadoop.tmp.dir</name> <!--admin操作时完成目录授权sudo chown -R admin:admin /opt/module/hadoop-3.4.0--> <value>/opt/module/hadoop-3.4.0/data/tmp</value> </property> </configuration>更新配置文件hdfs-site.xml并添加属性。
<configuration> <!-- 指定HDFS副本的数量。--> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
格式化文件结构。
hdfs namenode -format启动HDFS。
启动HDFS分为启动NameNode、DataNode和Secondary NameNode三个步骤。
启动HDFS。
cd /usr/local/hadoop/ sbin/start-dfs.sh查看进程。
jps返回结果如下:
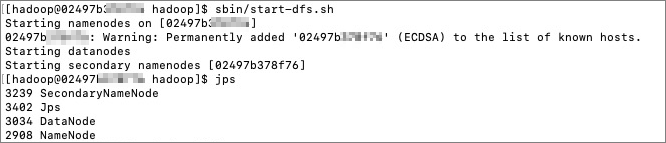
完成上述步骤后,即可建立HDFS守护进程。由于HDFS本身具备HTTP面板,您可以通过浏览器访问http://{ip}:9870,查看HDFS面板以及详细信息。
测试Hadoop是否安装成功。
执行hadoop version命令,如果正常返回版本信息,表明安装成功。
步骤三:切换本地HDFS到云上OSS-HDFS服务
下载JindoSDK JAR包。
切换至目标目录。
cd /usr/lib/下载最新版本的JindoSDK JAR包。下载地址,请参见GitHub。
解压JindoSDK JAR包。
tar zxvf jindosdk-x.x.x-linux.tar.gz说明x.x.x表示JindoSDK JAR包版本号。
配置环境变量。
编辑配置文件。
vim /etc/profile配置环境变量。
export JINDOSDK_HOME=/usr/lib/jindosdk-x.x.x-linux配置HADOOP_CLASSPATH。
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:${JINDOSDK_HOME}/lib/*执行以下命令使环境变量配置生效。
. /etc/profile
配置JindoSDK DLS实现类及AccessKey。
将JindoSDK DLS实现类配置到Hadoop的core-site.xml中。
<configuration> <property> <name>fs.AbstractFileSystem.oss.impl</name> <value>com.aliyun.jindodata.oss.JindoOSS</value> </property> <property> <name>fs.oss.impl</name> <value>com.aliyun.jindodata.oss.JindoOssFileSystem</value> </property> </configuration>将已开启HDFS服务的Bucket对应的accessKeyId、accessKeySecret预先配置在Hadoop的core-site.xml中。
<configuration> <property> <name>fs.oss.accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.oss.accessKeySecret</name> <value>xxx</value> </property> </configuration>
配置OSS-HDFS服务的Endpoint。
访问OSS-HDFS服务时需要配置Endpoint。推荐访问路径格式为
oss://<Bucket>.<Endpoint>/<Object>,例如oss://examplebucket.cn-shanghai.oss-dls.aliyuncs.com/exampleobject.txt。配置完成后,JindoSDK会根据访问路径中的Endpoint访问对应的OSS-HDFS服务接口。除上述提到的在访问路径中指定Endpoint的方式以外,您还可以通过其他配置OSS-HDFS服务的Endpoint。更多信息,请参见配置Endpoint的其他方式。
步骤四:访问OSS-HDFS服务
新建目录
在目标存储空间examplebucket下创建名为dir/的目录,示例如下:
hdfs dfs -mkdir oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/dir/上传文件
将本地examplefile.txt文件上传至目标存储空间examplebucket,示例如下:
hdfs dfs -put /root/workspace/examplefile.txt oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/examplefile.txt查看目录信息
查看目标存储空间examplebucket下目录dir/的信息,示例如下:
hdfs dfs -ls oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/dir/查看文件信息
查看目标存储空间examplebucket下文件examplefile.txt的信息,示例如下:
hdfs dfs -ls oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/examplefile.txt查看文件内容
查看目标存储空间examplebucket下文件examplefile.txt的内容,示例如下:
重要执行以下命令后,文件内容将以纯文本形式打印在屏幕上。如果文件存在特定格式的编码,请使用HDFS的Java API读取文件内容,然后进行解码操作后即可获取对应的文件内容。
hdfs dfs -cat oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/examplefile.txt拷贝目录或文件
将目标存储空间examplebucket下根目录subdir1拷贝到目录subdir2下,且根目录subdir1所在的位置、根目录下的文件和子目录结构和内容保持不变,示例如下:
hdfs dfs -cp oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/subdir1/ oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/subdir2/subdir1/移动目录或文件
将目标存储空间根目录srcdir及其包含的文件或者子目录移动至另一个根目录destdir下,示例如下:
hdfs dfs -mv oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/srcdir/ oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/destdir/下载文件
将目标存储空间examplebucket下的exampleobject.txt下载到本地根目录文件夹/tmp下,示例如下:
hdfs dfs -get oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/exampleobject.txt /tmp/删除目录或文件
删除目标存储空间examplebucket下目录destfolder/及其目录下的所有文件,示例如下:
hdfs dfs -rm oss://examplebucket.cn-hangzhou.oss-dls.aliyuncs.com/destfolder/