通过 Hadoop OSS Connector V2 + OSS 数据加速器(Data Accelerator) 的组合,企业可在阿里云上构建高性能、高可用、低成本的现代化数据湖平台。该方案兼容 Spark、Hive、Presto 等主流大数据计算引擎,支持 s3a:// 协议无缝对接 AWS S3 生态,帮助企业实现跨云迁移与云原生数据架构平滑演进。
应用场景
大规模 TPC-DS / TPC-H 基准测试
交互式 BI 查询(Tableau、Superset 接入 Spark Thrift Server)
湖仓一体架构中的统一存储层
多租户数据分析平台
1. Hadoop OSS Connector V2 简介
Hadoop OSS Connector V2是阿里云为 Hadoop 生态系统打造的新一代高性能对象存储接入组件,支持将 Alibaba Cloud OSS(Object Storage Service)作为原生文件系统无缝集成到 Spark、Hive、Presto 等主流大数据计算引擎中。
相比早期版本,V2 在性能、稳定性与功能丰富性方面实现显著提升,特别针对大规模数据湖场景进行深度优化,能够满足高并发、低延迟的数据分析工作负载需求。
核心能力
支持标准
oss://bucket/path和兼容 S3 协议的s3a://访问高性能多线程分片上传/下载,支持大文件高效处理
自动重试机制与智能连接池管理,提升容错能力
支持 Prefetch(预取)机制,显著提升顺序读性能
支持双域加速架构(OSS + Data Accelerator)
兼容 Hadoop 3.3.5 版本(目前仅针对Hadoop 3.3.5 版本完成了兼容性验证)。
当前版本限制:
暂不支持为不同 Bucket 配置独立 endpoint(如
fs.oss.<bucket>.endpoint),所有 Bucket 共享全局fs.oss.endpoint设置。当前版本仅支持v4鉴权。
2. 整体架构与方案说明
采用典型的"存算分离"数据湖架构设计,通过解耦存储与计算实现弹性扩展和成本优化:

组件 | 角色 |
OSS | 统一数据湖底座,负责持久化存储原始数据与中间结果 |
Hive Metastore | 元数据管理中心,统一维护表结构、分区、Schema 等信息 |
Spark on YARN | 分布式计算引擎,负责执行 SQL 查询与数据处理任务 |
2.1 数据存储:OSS 作为数据湖底座
所有数据以开放格式(Parquet、ORC、CSV、JSON)存储于 OSS,确保跨引擎兼容性。
统一使用标准路径格式访问数据,便于不同组件间的数据共享。
充分利用 OSS 的高可用、高扩展、低成本优势,支持 PB 级数据规模的弹性存储。
2.2 元数据管理:Hive Metastore 统一维护 Schema
表结构、分区信息、列统计等元数据由 Hive Metastore Service (HMS) 统一管理。
HMS 后端数据库使用 MySQL 存储元数据(生产环境严禁使用 Derby 内存数据库)。
通过标准 DDL 创建外部表,直接指向
oss://路径,无需数据迁移即可实现表访问。示例:创建兼容 OSS 协议的外部表
CREATE EXTERNAL TABLE ods_user ( id BIGINT, name STRING, dt STRING ) PARTITIONED BY (dt STRING) STORED AS PARQUET LOCATION 'oss://my-data-lake-bucket/dw/ods/user_info/';同样支持
s3a://协议访问:LOCATION 's3a://my-data-lake-bucket/dw/ods/user_info/';通过统一元数据层管理,用户可灵活选择访问协议,实现与 AWS S3 生态的平滑迁移与完全兼容。
2.3 计算引擎:Spark 实现高效查询与分析
采用 Spark on YARN 模式部署计算集群,实现资源动态调度。
Spark Driver 与 Executors 通过 Hadoop OSS Connector V2 直接读写 OSS 数据,减少中间层开销。
查询结果可直接回写至 OSS,形成派生数据集供后续分析使用。
3. 安装与配置
3.1 前置准备
在部署前,请确保完成以下准备工作:
项目 | 要求 |
开通服务 | 已开通OSS并创建目标 Bucket |
地域一致性 | ECS 实例与 OSS Bucket 处于同一地域(如华东1),确保内网访问和最低延迟 |
内网访问 | ECS 可通过内网域名访问 OSS(如 |
加速器开通 | 开通 OSS 数据加速器(Data Accelerator),获取加速域名(如 |
环境准备 | 准备运行环境组件: 文档验证环境使用 Hadoop 3.3.5、Spark 3.5.3、Hive MetaStore 3.1.3 |
权限配置 | 创建 RAM 子账号 AccessKey,并授予对目标 Bucket 的读写权限 |
数据准备 | 生成 TPC-DS 5TB 测试数据并上传至 OSS,用于性能基准测试验证 |
3.2 下载 JAR 包
Hadoop OSS Connector V2 已发布至 Maven 中央仓库,支持 Maven 依赖引用或手动下载部署两种方式。
Maven 依赖(用于打包应用)
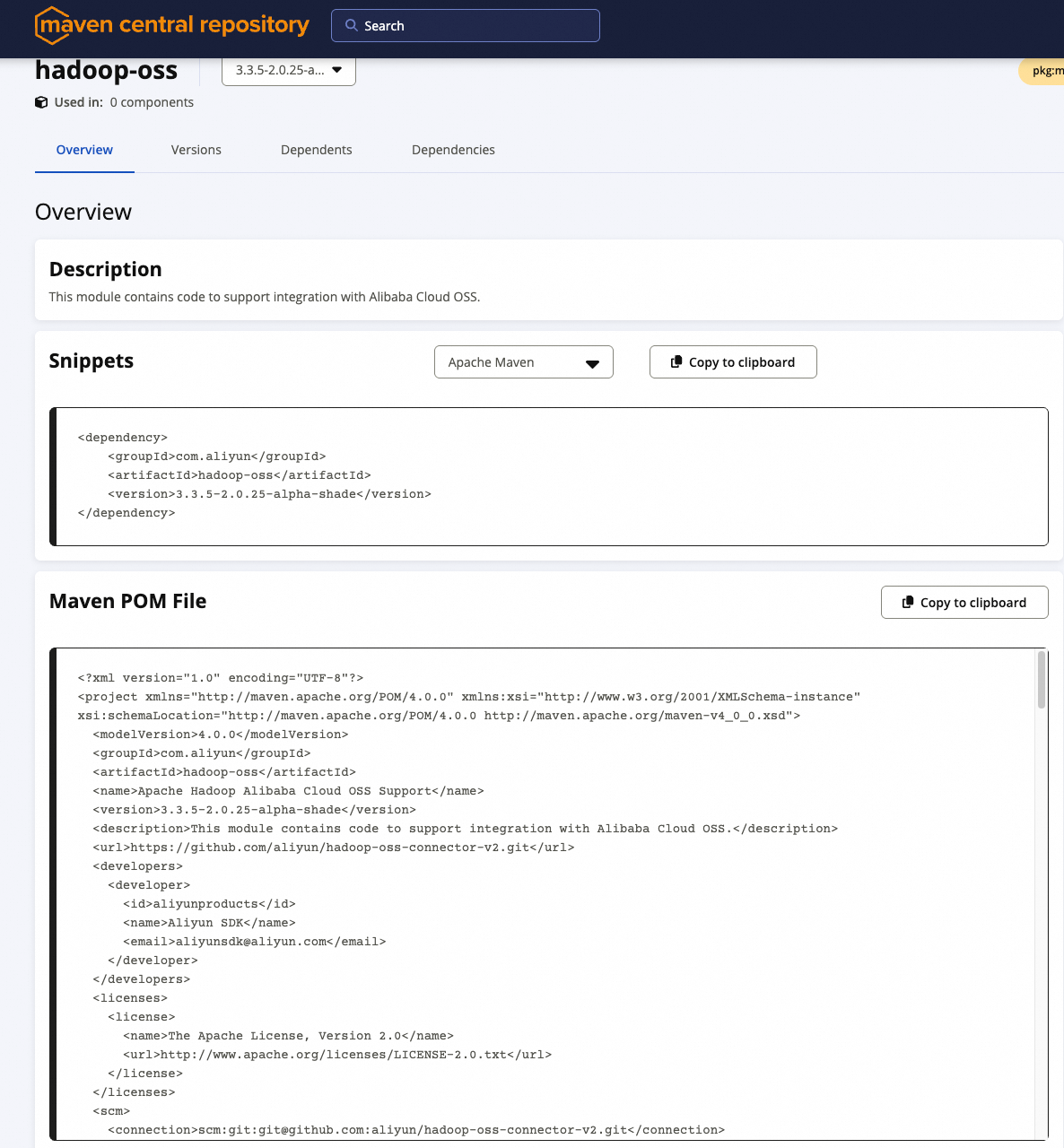
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>hadoop-oss</artifactId>
<version>3.3.5-2.0.25-alpha-shade</version>
</dependency>
手动下载 JAR 包(适用于集群部署)
下载地址:https://central.sonatype.com/artifact/com.aliyun/hadoop-oss
将以下 JAR 文件放入
$HADOOP_HOME/share/hadoop/common/lib/和$SPARK_HOME/jars/目录:hadoop-oss-3.3.5-2.0.25-alpha-shade.jar(推荐使用 shade 版本,已包含核心依赖)
说明Spark 作业提交时也需确保这些 JAR 在 classpath 中,建议统一预置到各节点环境。
3.3 核心配置
在 $HADOOP_HOME/etc/hadoop/core-site.xml 中添加以下配置:
<configuration>
<!-- OSS 访问凭证 -->
<property>
<name>fs.oss.accessKeyId</name>
<value>YourAccessKeyId</value>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>YourAccessKeySecret</value>
</property>
<!-- OSS 内网 Endpoint(强烈建议使用内网,降低延迟与流量费用) -->
<property>
<name>fs.oss.endpoint</name>
<value>oss-cn-hangzhou-internal.aliyuncs.com</value>
</property>
<!-- 连接参数优化 -->
<property>
<name>fs.oss.connection.maximum</name>
<value>64</value>
</property>
<property>
<name>fs.oss.connection.timeout</name>
<value>200000</value>
</property>
<property>
<name>fs.oss.attempts.maximum</name>
<value>10</value>
</property>
<!-- 分片上传设置(大于 20MB 启用 Multipart Upload) -->
<property>
<name>fs.oss.multipart.upload.threshold</name>
<value>20971520</value> <!-- 20MB -->
</property>
<property>
<name>fs.oss.multipart.upload.size</name>
<value>104857600</value> <!-- 100MB per part -->
</property>
<!-- Prefetch 加速大文件顺序读 -->
<property>
<name>fs.oss.prefetch.version</name>
<value>v2</value>
</property>
<property>
<name>fs.oss.prefetch.block.size</name>
<value>131072</value> <!-- 128KB -->
</property>
<property>
<name>fs.oss.prefetch.block.count</name>
<value>8</value>
</property>
<property>
<name>fs.oss.prefetch.io.threshold</name>
<value>2097152</value> <!-- 2MB -->
</property>
<!-- Buffer 目录(建议使用 SSD) -->
<property>
<name>fs.oss.buffer.dir</name>
<value>/data/oss-buffer,/mnt/disk2/oss-buffer</value>
</property>
</configuration>
重要配置说明
4. 验证安装结果
4.1 基础文件操作测试
通过基础 Hadoop 命令验证读写功能是否正常:
# 列出 OSS 目录内容
hadoop fs -ls oss://my-data-lake-bucket/test/
# 上传小文件
hadoop fs -copyFromLocal /tmp/test.txt oss://my-data-lake-bucket/test/
# 删除文件
hadoop fs -rm oss://my-data-lake-bucket/test/test.txt
预期输出正常即表示基础功能可用。
4.2 大文件上传与下载性能测试
测试 20GB 大文件的 I/O 性能表现:
# 生成测试文件
dd if=/dev/zero of=/tmp/large-file-20G bs=1M count=20480
# 上传至 OSS(支持 oss:// 或 s3a://)
hadoop fs -D io.file.buffer.size=4194304 -copyFromLocal -f /tmp/large-file-20G oss://your-bucket/path/20GB-file.img
# 下载测试
hadoop fs -D io.file.buffer.size=4194304 -copyToLocal -f oss://your-bucket/path/20GB-file.img /dev/null
执行结果:

4.3 TPC-DS 基准测试(端到端能力验证)
步骤 1:加载 TPC-DS 5TB 数据
使用
dsdgen工具生成数据并上传至 OSS。在 Hive Metastore 中建表,指向
s3a://或oss://路径。
步骤 2:执行标准查询
$SPARK_HOME/bin/beeline -u jdbc:hive2://localhost:10001/tpcds_bin_partitioned_orc_5000 -f q9.sql执行结果:

5. 高级配置
5.1 使用加速器提升查询性能
5.1.1 细粒度 IO 加速能力

OSS 数据加速器(Data Accelerator)是阿里云提供的一种基于SSD的加速服务,能够基于规则对特定访问模式的数据进行缓存和加速。Hadoop OSS Connector V2 支持与其深度集成,实现按需加速。
核心加速优势
显著降低小文件、元数据文件及随机 I/O 的访问延迟;
利用边缘节点缓存机制,减少回源次数,提升整体吞吐;
特别适合交互式查询、BI 报表、元数据扫描等 I/O 密集型场景。
IO 类型 | 描述 | 适用场景 | 配置示例 |
前缀匹配加速 | 对指定路径前缀(如 | 热点查询中间结果 | |
后缀匹配加速 | 匹配特定扩展名(如 | 统一格式表文件 | |
文件大小范围加速 | 仅对 0~10MB 的小文件加速 | 元数据、小分区文件 | |
操作类型加速 | 当前仅支持 | 读密集型任务 | |
Tail/Head 访问优化 | 对文件头(元信息)和尾部(日志追加)访问进行缓存 | 结构化文件解析 | |
注意,目前仅支持 getObject 操作的加速。配置加速器参数
在 core-site.xml 中增加:
<!-- 加速器 Endpoint(内网专用) -->
<property>
<name>fs.oss.acc.endpoint</name>
<value>https://cn-hangzhou-j-internal.oss-data-acc.aliyuncs.com</value>
</property>
<!-- 加速规则:对小文件、热点数据启用加速 -->
<property>
<name>fs.oss.acc.rules</name>
<value><![CDATA[
<rules>
<rule>
<keyPrefixes>
<keyPrefix>tpcds/q9/</keyPrefix>
</keyPrefixes>
<ioSizeRanges>
<!-- 缓存前 2MB:适用于文件头元信息 -->
<ioSizeRange>
<ioType>HEAD</ioType>
<ioSize>2097152</ioSize>
</ioSizeRange>
<!-- 缓存末尾 2MB:适用于 Parquet/ORC Footer -->
<ioSizeRange>
<ioType>TAIL</ioType>
<ioSize>2097152</ioSize>
</ioSizeRange>
<!-- 缓存小 I/O 请求(0~50MB) -->
<ioSizeRange>
<ioType>SIZE</ioType>
<minIOSize>0</minIOSize>
<maxIOSize>52428800</maxIOSize>
</ioSizeRange>
</ioSizeRanges>
<operations><operation>getObject</operation></operations>
</rule>
</rules>
]]></value>
</property>
标签命名敏感性
<ioSizeRanges>和<ioSizeRange>是区分大小写的,请严格按照文档使用; 子标签必须嵌套在<IOSizeRanges>内,不能直接放在<rule>下。ioType 取值说明
ioType含义
配合字段
HEAD从文件开头读取数据
ioSizeTAIL从文件末尾向前读取
ioSizeSIZE任意位置但请求长度落在
[minIOSize, maxIOSize]内minIOSize,maxIOSize说明SIZE不表示文件总大小,而是指 单次 I/O 请求的数据量大
5.2 本地下载缓存
本地下载缓存机制:预取数据持久化到磁盘
为了进一步提升重复读取性能,Hadoop OSS Connector V2 支持将 Prefetch(预取)过程中下载但尚未使用的数据块缓存至本地磁盘,供后续访问复用。
工作机制
当开启 Prefetch(
fs.oss.prefetch.version=v2)时,系统会提前从 OSS 下载后续数据块;数据块可在内存中临时缓存,也可落盘至本地磁盘(由
fs.oss.buffer.prefetch.dir指定);若发生 seek 或再次读取相同区域,优先从本地磁盘加载,避免重复网络请求。
关键配置参数
参数名称 | 说明 |
| 每个预取块大小,默认 128KB |
fs.oss.prefetch.block.count | 单流预取块数量,默认 8 块(约 1MB) |
| 每个流最多缓存到磁盘的块数,默认为 16(设置为0即为关闭)。 建议设为 |
| 本地缓存目录,默认 |
场景示例: 在执行 TPC-DS 查询时,若某 Parquet 文件被多次扫描,第二次读取可完全命中本地磁盘缓存,I/O 延迟下降 60% 以上。
使用注意事项:
仅建议在具备本地 SSD 存储空间的环境中开启;
确保
fs.oss.buffer.prefetch.dir所在磁盘空间充足(建议预留 ≥ 128GB)。
5.3 跨云兼容:与 S3 协议无缝对接
为支持企业从 AWS S3 或其他兼容 S3 的存储平台平滑迁移至阿里云 OSS,Hadoop OSS Connector V2 提供了完整的 S3 协议兼容能力。通过配置 s3a:// 协议访问 OSS 资源,用户可在不修改元数据、脚本或作业代码的前提下,实现“零改动”上云。
这一特性对于已有基于 S3 构建的数据湖环境尤为重要——尤其是 Hive Metastore 中大量表的 LOCATION 已配置为 s3a://bucket/path 的场景,无需批量更新元数据即可直接读取阿里云 OSS 上的数据。
核心优势
支持使用
s3a://URI 访问 OSS 存储;Hive Meta 元数据无需变更,实现"应用无感知"的存储层切换;
统一调用模型,降低运维复杂度和迁移成本。
配置方式
在 $HADOOP_HOME/etc/hadoop/core-site.xml 中添加以下配置,启用 S3A 到 OSS 的映射:
<configuration>
<!-- 启用 S3A 兼容模式下的 OSS 实现-->
<property>
<name>fs.AbstractFileSystem.s3a.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.v2.OSSWithS3A</value>
</property>
<!-- 指定 s3a 文件系统实现类 -->
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.v2.AliyunOSSPerformanceFileSystem</value>
</property>
<!-- S3A 访问密钥(使用阿里云 AccessKey) -->
<property>
<name>fs.s3a.access.key</name>
<value>YourAccessKeyId</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>YourAccessKeySecret</value>
</property>
<!-- OSS Endpoint(建议使用内网地址以提升性能) -->
<property>
<name>fs.s3a.endpoint</name>
<value>oss-cn-hangzhou-internal.aliyuncs.com</value>
</property>
<!-- 可选:关闭 SSL 以避免证书问题 -->
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
</configuration>
fs.AbstractFileSystem.s3a.impl配置选项说明:
OSSWithS3A:支持以 s3a:// 访问 OSS 上的数据
OSS:支持以 oss:// 访问 OSS 上的数据
使用示例
假设已在 Hive Metastore 中创建了如下外部表(典型 S3 场景):
CREATE EXTERNAL TABLE ods_user (
id BIGINT,
name STRING,
dt STRING
)
PARTITIONED BY (dt STRING)
STORED AS PARQUET
LOCATION 's3a://my-data-lake-bucket/dw/ods/user_info/';
完成上述配置后,Spark 或 Hive 查询将自动通过 Hadoop OSS Connector V2 读取对应路径下的 OSS 数据,无需修改任何表定义或 SQL 脚本。
执行查询:
SELECT count(*) FROM ods_user WHERE dt = '20250405';→ 自动从 oss://my-data-lake-bucket/dw/ods/user_info/ 加载数据。
兼容性限制
限制项目 | 说明 |
协议限制 | 目前仅支持 |
行为一致性 | 大部分 S3A 参数(如连接池、超时等)均生效,行为与原生 S3A 客户端保持一致 |
总结:
通过 s3a:// 协议兼容机制,Hadoop OSS Connector V2 极大降低了跨云迁移的技术门槛。无论是新建数据湖还是存量系统迁移,都可以借助该能力实现灵活、安全、高效的统一存储接入。
生产环境建议结合加速器与 Prefetch 配置,进一步提升 s3a:// 查询性能。
6. 性能测试对比与优化建议
6.1 20GB 文件下载吞吐对比
版本 | 平均吞吐 |
Hadoop OSS Connector V1 (Hadoop社区版本) | 40 MB/s |
Hadoop OSS Connector V2 | 232 MB/s |
Hadoop OSS Connector V2 + OSS 加速器 | 476 MB/s |
结论: 通过 Prefetch 和连接优化大幅提升吞吐;启用 OSS 加速器后性能表现更优,在顺序大量读取数据场景下表现尤为突出。
6.2 TPC-DS 查询性能对比(SQL 99 总耗时)
版本 | 总耗时(秒) |
Hadoop OSS V1(Hadoop社区版本) | 37,816 |
Hadoop OSS V2 | 27,057 |
Hadoop OSS V2 + OSS 加速器 | 23,598 |
结论: OSS Connector V2 + OSS 加速器 组合相较 V1 性能提升 37.6%,相较 V2 提升 12.8%,显著优化查询响应时间,尤其适用于高频访问的 OLAP 场景。
6.3 优化建议总结
为充分发挥 Hadoop OSS Connector V2 在云上数据湖场景中的性能潜力,结合实际生产经验,我们总结了以下关键优化建议。
核心配置优化
优化类别 | 最佳实践 | 说明 |
存储协议兼容性 | 使用 | 实现与 AWS S3 生态无缝对接,无需修改元数据 |
Prefetch 预取优化 | 启用 | 提升大文件顺序读性能,需配合 buffer size > 2MB |
连接与缓冲调优 | 合理设置连接数与 buffer 目录 |
|
加速与缓存策略
策略类别 | 最佳实践 | 说明 |
OSS加速器启用 | 缓存频繁读取的热数据,降低访问带宽 | 显著降低小文件、元数据访问延迟 |
提高预取效率 | 使用 SSD 作为预取缓存盘(可选) |
如本地无高速缓存介质,建议关闭该功能。 |
IO 加速规则场景化配置建议
应用场景 | 推荐规则组合 | 配置说明 |
读取 Parquet/ORC 表 |
| 缓存文件 footer 与小 I/O 请求 |
日志分析(tail -f) |
| 缓存最后 1~2MB |
元数据文件频繁读取 |
| 加速 |
高频维度表访问 |
| 细粒度路径匹配加速 |
综合优化建议清单
优化项目 | 推荐配置 |
存储协议 | 优先使用 |
本地缓存 |
|
Prefetch 配置 | 开启 |
热数据共享缓存 |
|
本地缓存 | 有 SSD 则开,无 SSD 则关闭,避免性能反降 |
建议在 TPC-DS 或真实业务负载下进行压测调优,持续迭代配置以达到最优效果。