
使用 OSS 的数据索引功能,可以为网络摄像机(IPC)设备采集的视频构建智能语义检索系统,对采集的视频进行语义检索,适用于智能安防等场景。
方案概览

搭建智能语义检索系统,只需两步:
创建 Bucket 并上传视频:创建用于存储原始 IPC 设备采集的视频文件的 Bucket,并上传待处理的视频文件,为后续视频检索提供有力支持。
开启向量检索功能:为 Bucket 开启向量检索功能,以支持基于自然语言描述的智能检索。
方案优势
语义化检索:支持基于自然语言描述和多条件组合的精准检索,能够快速定位目标画面,满足复杂场景下的检索需求。
多模态检索:提供视频、图像、文本等数据统一管理与检索能力,降低技术门槛与运维成本。
横向扩展:OSS 容量无限、弹性扩展,可轻松应对海量数据增长。
1. 创建Bucket并上传视频
登录OSS管理控制台。
进入Bucket列表页面,并点击创建Bucket。
在创建Bucket页面,填写Bucket名称(建议使用业务相关的名称,如
ipc-videos-oss-metaquery-demo),其余参数可保持默认配置。单击完成创建,在创建成功的页面,点击进入Bucket。
在文件列表页面,点击,选择待上传的视频文件(如视频A.mp4、视频B.mp4和视频C.mp4),其余参数保留默认配置,点击上传文件。
(可选)为上传的视频文件配置标签:在目标文件右侧操作栏下,选择
 > 标签,在弹出的对话框中添加标签键值对(如设置键为
> 标签,在弹出的对话框中添加标签键值对(如设置键为need-seek,值为true,用于后续索引建立的过滤条件;设置键为camera,值为camera-a,用于后续索引查询的过滤条件),点击确定。通过为视频添加标签,可以在后续索引和检索时实现更精准的筛选。
2. 开启向量检索功能
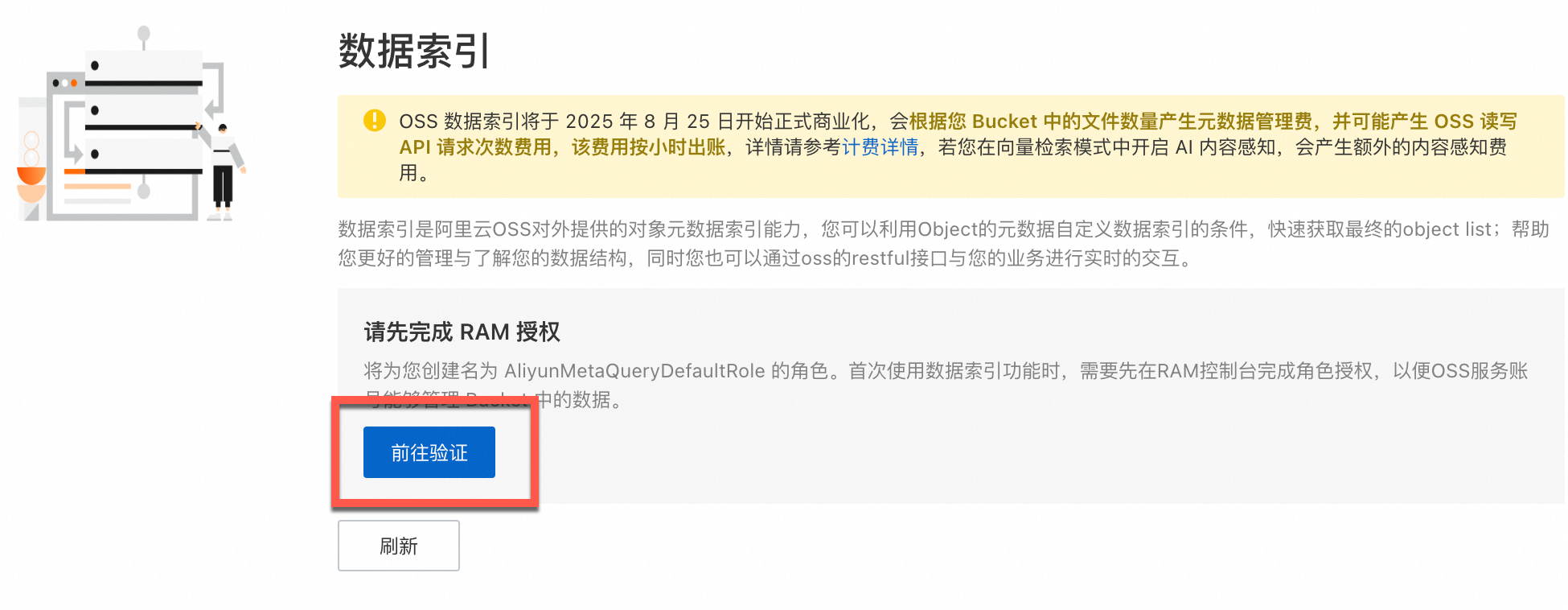
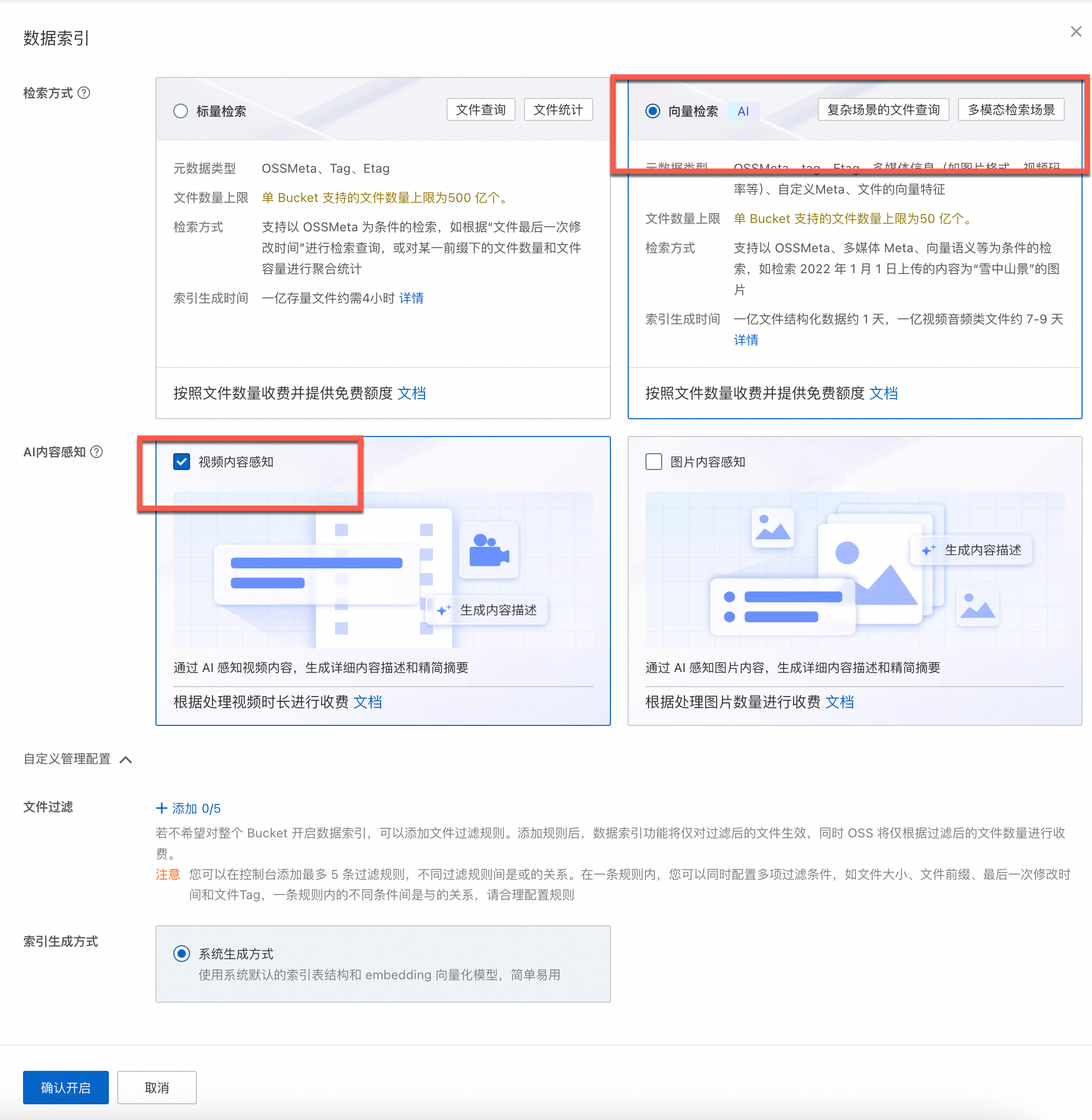
为Bucket开启向量检索功能,支持对视频进行基于自然语言描述和多条件组合的精准检索。
说明 构建元数据索引需要等待一定的时间,具体等待时长取决于Bucket中Object的数量。若开启时间过久可通过刷新来查看开启状态。 |
|
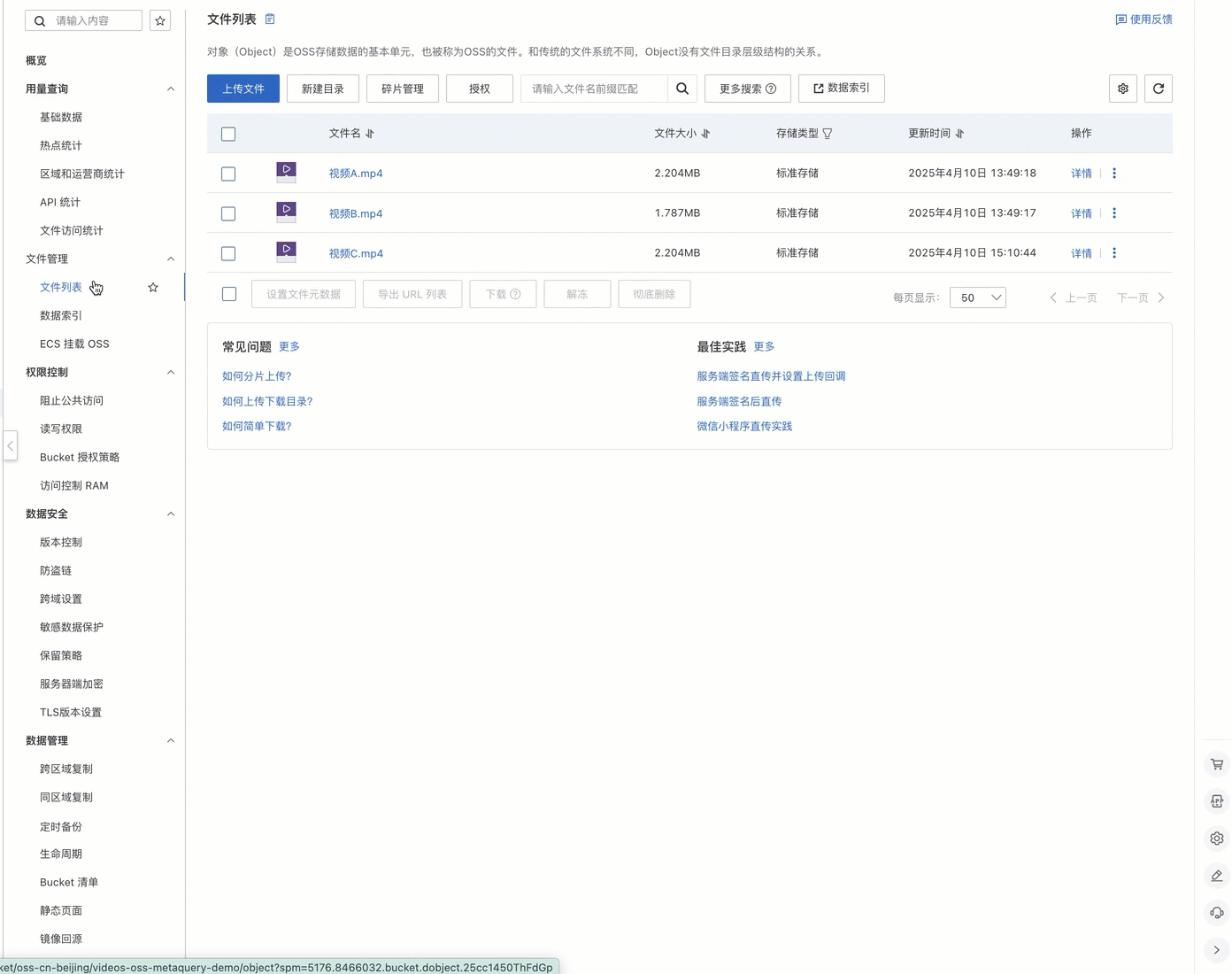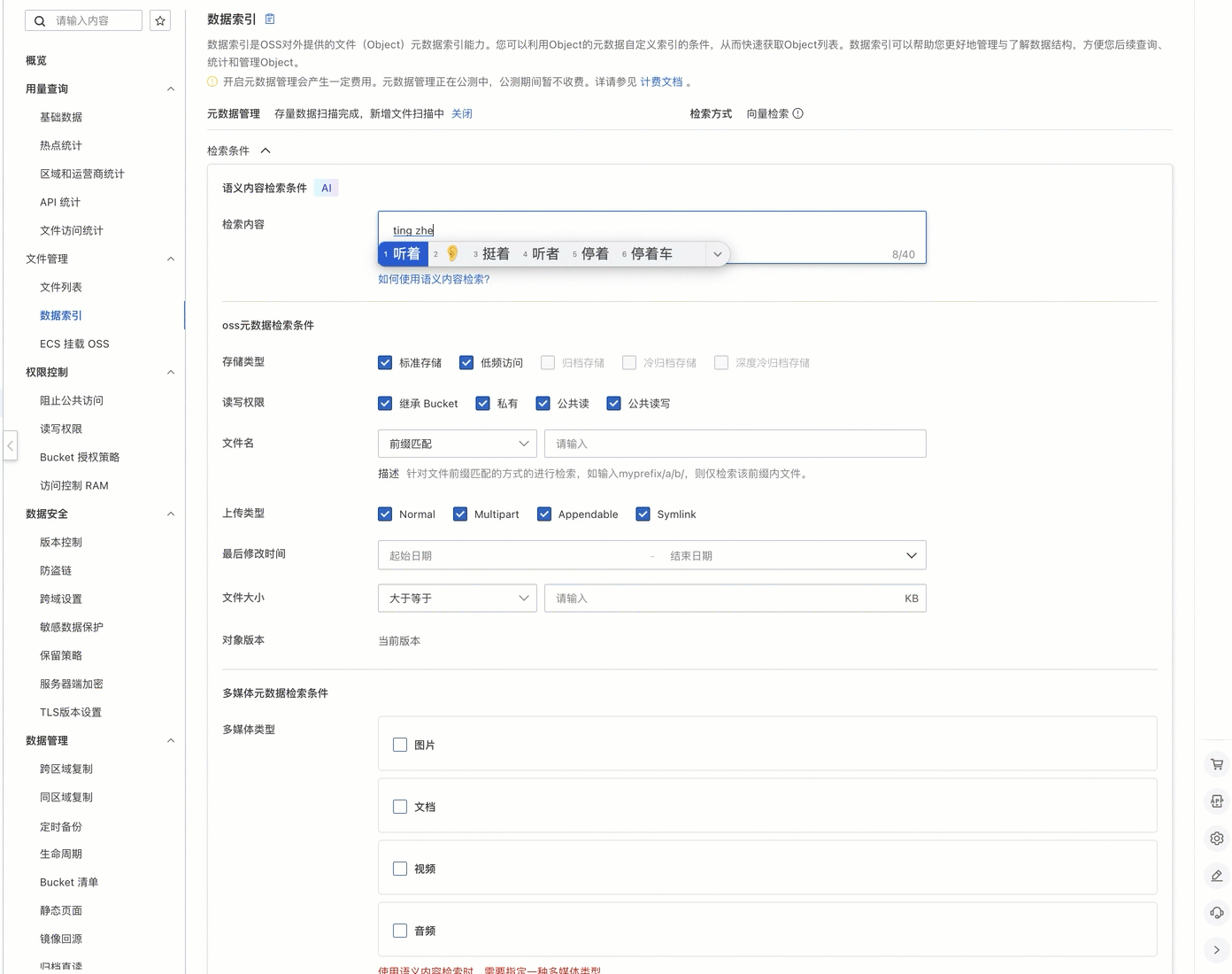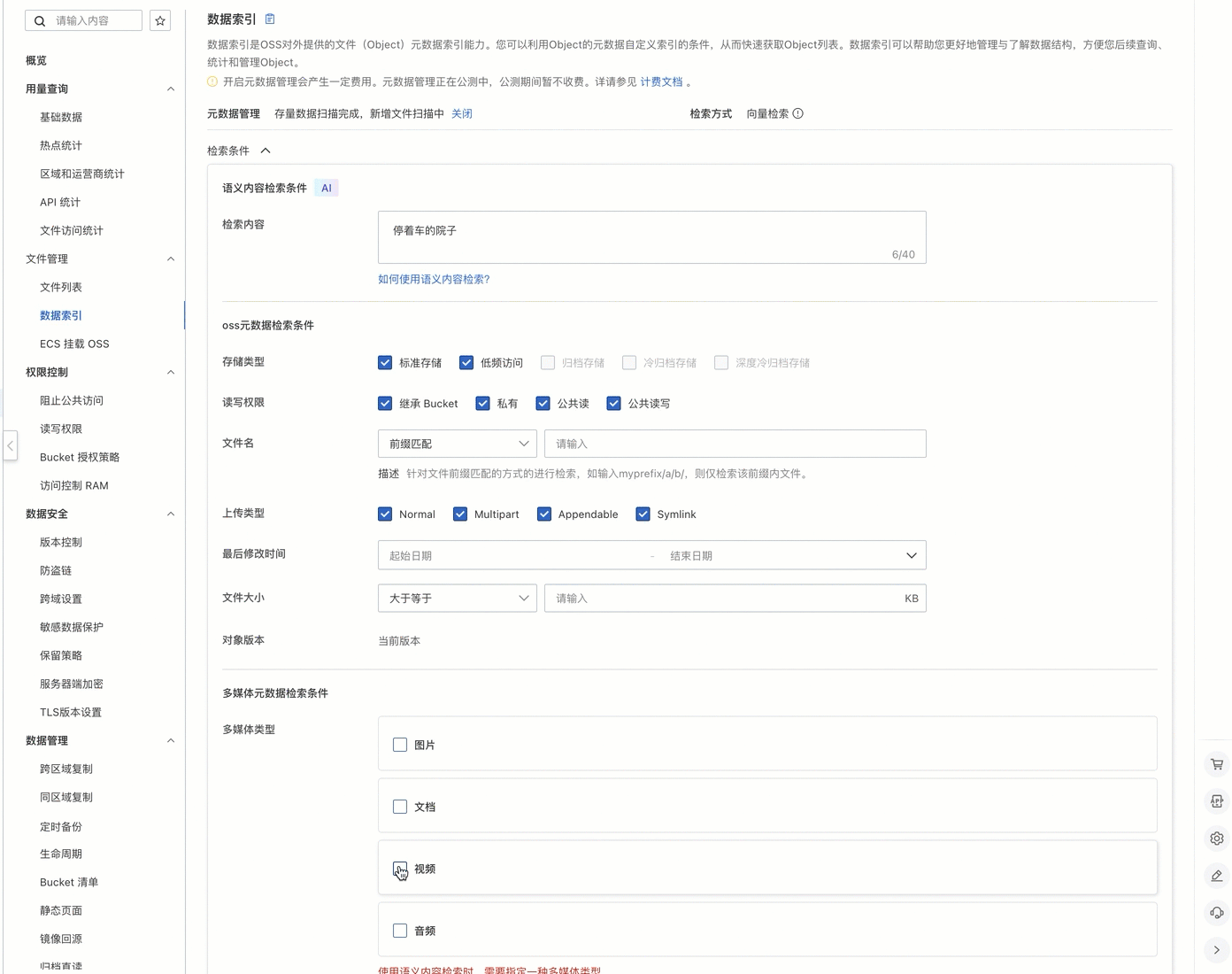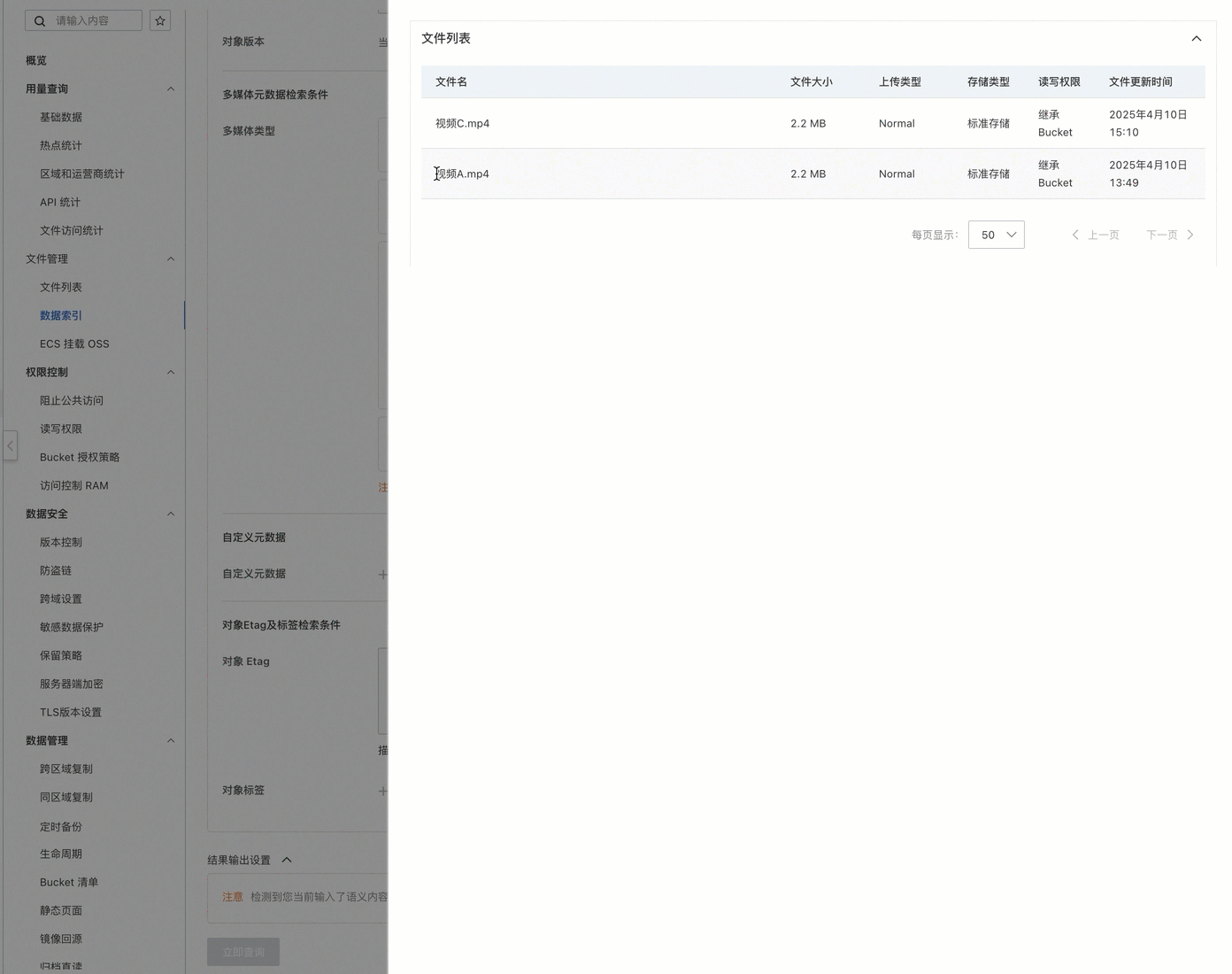
结果验证
只需输入描述性文字,例如停着车的院子,系统便会返回与描述相符的关键视频。
|
|
应用于生产环境
当您需要将此能力集成到生产环境中时,请考虑以下方面:
生产数据接入
在实际业务场景中,监控设备(如 IPC 摄像头)会持续产生大量视频数据,建议集成 OSS SDK,将录制完成的视频片段实时上传至指定的 Bucket,以确保数据上传的稳定性与时效性,提升整体系统的可用性和实时处理能力。
下面示例利用 OSS Python SDK 调用文件上传管理器上传视频供参考:
检索能力集成
在生产环境中,建议将检索功能集成到后端服务中,利用 OSS SDK 实现自动化调用,避免依赖控制台进行人工操作。
以下为示例代码,展示如何构建符合 OSS MetaQuery 规范的 XML 请求,获取检索结果:
运行该程序后,您可以输入描述性文字(例如停着车的院子)进行查询。系统根据数据索引,返回包含符合描述的检索结果,您可以直接通过URL链接查看视频详情。
共找到 1 个匹配结果:
文件 1:
URI: oss://ipc-videos-oss-metaquery-demo/视频A.mp4
文件名: 视频A.mp4
大小: 2311252
修改时间: 2025-05-23T17:38:10+08:00
ContentType: video/mp4
MediaType: video
文件地址 (预签名URL): https://ipc-videos-oss-metaquery-demo.oss-cn-beijing.aliyuncs.com/%E8%A7%86%E9%A2%91A.mp4?x-oss-signature-version=OSS4-HMAC-SHA256&x-oss-date=20250523T094511Z&x-oss-expires=900&x-oss-credential=LTAI********************%2F20250523%2Fcn-beijing%2Foss%2Faliyun_v4_request&x-oss-signature=0bf38092c42a179ff0e8334c8bea3fd92f5a78599038e816e2ed3e02755542af
--------------------设置标签过滤
面对海量视频数据,单纯靠文件路径管理往往难以高效检索和分类。建议使用 OSS 的标签功能,为文件添加键值对标签,以根据业务需求快速筛选和分类数据,例如按摄像头 ID、地理区域等维度进行过滤。
假设系统中有三个待分析的视频文件(如视频A.mp4、视频B.mp4、视频C.mp4)如下:
视频A.mp4 | 视频B.mp4 | 视频C.mp4 |
|
|
|
后院视频,标记为camera-a拍摄 | 售货视频,标记为camera-b拍摄 | 后院视频,和视频A内容近似,标记为camera-c拍摄 |


标签支持在文件上传时直接设置,也支持在上传后进行动态管理,满足不同业务场景的需求。
上传时设置标签
在上传视频文件的同时设置标签,实现上传和标签管理操作的一体化,提升数据管理效率。
以下示例演示如何使用 OSS Python SDK 的文件上传管理器上传视频文件并同时设置标签:
上传后管理标签
如果文件已经上传,依然可以随时为文件添加或修改标签,确保数据标签的动态维护和准确性。
以 Python SDK 为例调用相应接口添加标签示例如下:
结合标签筛选检索
以下示例展示了如何调用OSS Python SDK发起一次结合语义理解和标签筛选的组合查询请求:
运行该程序后,如需筛选出包含停放车辆的院子的视频内容,可以:
在描述性字段输入检索关键词:
停着车的院子设置标签筛选条件:
camera = camera-a
在当前视频文件中,视频 A 与视频 C 均拍摄了符合停着车的院子的描述场景,但由于设置了标签筛选(仅保留camera-a标记的视频检索结果),最终检索结果仅包含视频A。
发送 DoMetaQuery 请求...
请求成功,HTTP 状态码: 200
从OSS获取到 2 个初步匹配结果,开始进行客户端标签过滤...
[1] 文件 '视频A.mp4' 符合所有条件:
文件地址:https://ipc-videos-oss-metaquery-demo.oss-cn-beijing.aliyuncs.com/%E8%A7%86%E9%A2%91A.mp4?x-oss-signature-version=OSS4-HMAC-SHA256&x-oss-date=20250526T054908Z&x-oss-expires=900&x-oss-credential=LTAI********************%2Fcn-beijing%2Foss%2Faliyun_v4_request&x-oss-signature=01bbf29790763d8e0f177d4cb0469cb00ae1c69d565219edb3866f75110b37ab
文件路径:视频A.mp4
-----------------------
客户端过滤完成,共找到 1 个最终匹配结果。