
随着 RAG 和语义搜索需求的增长,向量检索系统常面临两类挑战:
多租户隔离:SaaS 服务商为大量企业客户提供知识库,或企业内部各部门拥有独立知识库,要求数据严格隔离。
超大规模数据:单索引数据量达到千万甚至亿级时,检索延迟显著增加,难以满足实时性要求。
OSS Vectors 支持同一账号在同一地域创建大量向量索引(Index)。通过多索引架构,可以按租户或业务维度拆分数据,兼顾隔离性和检索性能。
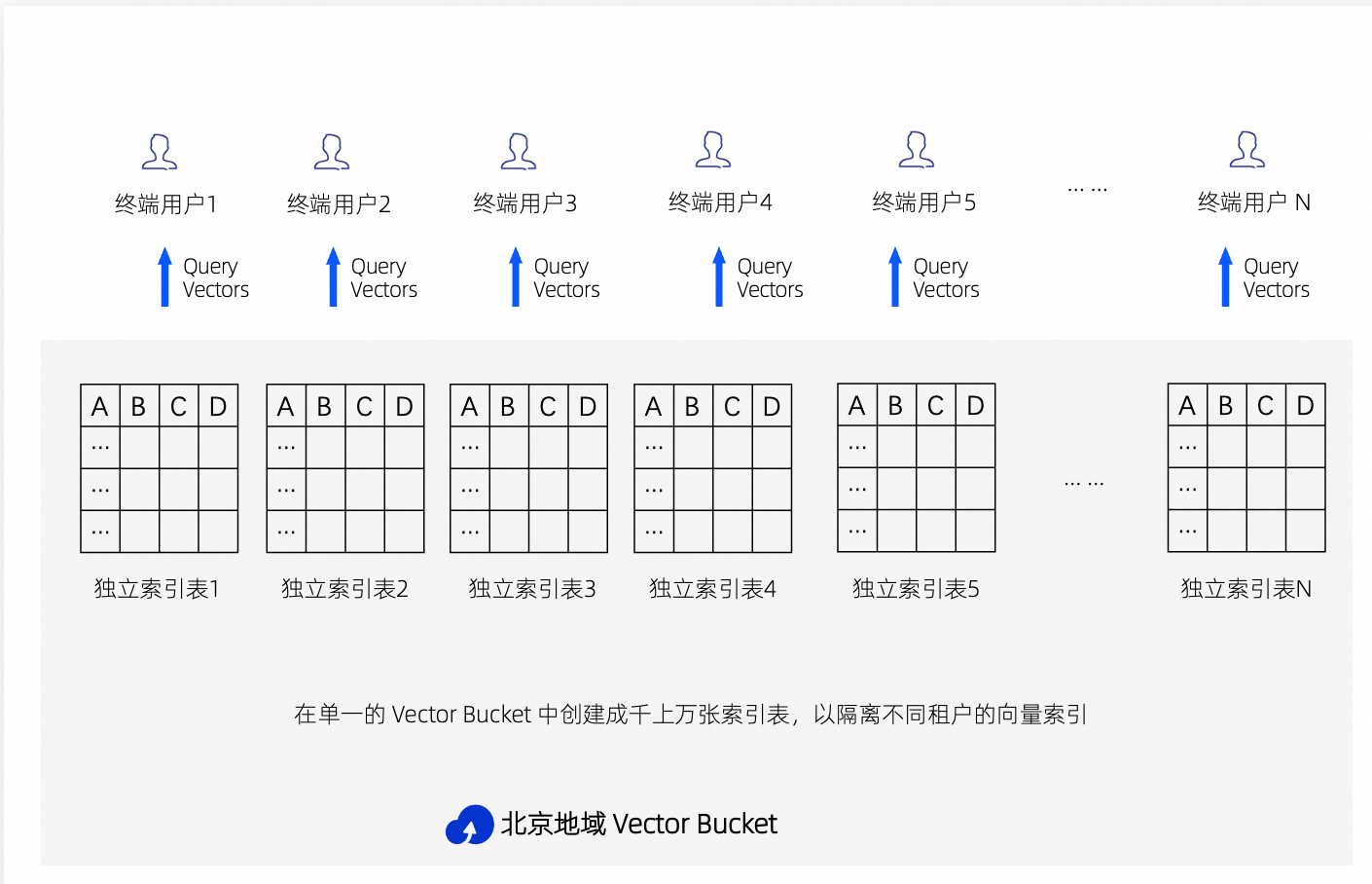
多索引架构的优势
数据隔离:不同租户或业务的数据存放在独立索引中,从底层避免跨租户数据泄露。
检索提速:将大表拆分为多张小表,缩小单次检索范围;配合并发检索多个索引再合并结果,可有效降低总响应耗时。
运维灵活:不同索引可独立配置维度、模型、相似度算法。删除某个租户的数据只需删除对应索引,无需逐条过滤删除。
通过 CLI 按租户导入数据
oss-vectors-embed CLI 工具支持将指定文件写入指定索引,实现按租户或业务维度的定向导入。
安装方式请参见使用OSS Vectors Embed CLI工具写入和检索向量数据。
开始前,请确保满足以下条件:
已配置环境变量
OSS_ACCESS_KEY_ID、OSS_ACCESS_KEY_SECRET和DASHSCOPE_API_KEY。已创建向量 Bucket 和各租户对应的向量索引。
将以下示例中的占位符替换为实际值:
占位符 | 说明 |
| 阿里云账号 ID |
| 向量 Bucket 名称 |
按租户写入不同索引
将不同租户的数据写入各自独立的索引,实现数据隔离。
# 将租户 A 的文档写入租户 A 的索引
oss-vectors-embed \
--account-id "<your-account-id>" \
--vectors-region cn-hangzhou \
put \
--vector-bucket-name "<your-vector-bucket>" \
--index-name "tenantcompanya" \
--model-id text-embedding-v4 \
--text-value "租户A的知识库文档内容" \
--key "doc_001" \
--metadata '{"tenant": "company_a", "category": "faq"}'
# 将租户 B 的文档写入租户 B 的索引
oss-vectors-embed \
--account-id "<your-account-id>" \
--vectors-region cn-hangzhou \
put \
--vector-bucket-name "<your-vector-bucket>" \
--index-name "tenantcompanyb" \
--model-id text-embedding-v4 \
--text-value "租户B的知识库文档内容" \
--key "doc_001" \
--metadata '{"tenant": "company_b", "category": "manual"}'按租户定向检索
检索时只查询目标租户的索引,天然实现数据隔离。
# 仅在租户 A 的索引中检索
oss-vectors-embed \
--account-id "<your-account-id>" \
--vectors-region cn-hangzhou \
query \
--vector-bucket-name "<your-vector-bucket>" \
--index-name "tenantcompanya" \
--model-id text-embedding-v4 \
--text-value "常见问题" \
--top-k 5 \
--return-metadata通过 SDK 构建多索引架构
Python SDK
开始前请安装 alibabacloud-oss-v2 SDK:
pip install alibabacloud-oss-v2确保已配置环境变量 OSS_ACCESS_KEY_ID 和 OSS_ACCESS_KEY_SECRET。
创建多租户索引
以租户 ID 为后缀命名索引,批量创建独立的向量索引。
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
ACCOUNT_ID = "<your-account-id>"
REGION = "cn-hangzhou"
BUCKET = "<your-vector-bucket>"
def create_vector_client():
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
cfg = oss.config.load_default()
cfg.credentials_provider = credentials_provider
cfg.region = REGION
cfg.account_id = ACCOUNT_ID
return oss_vectors.Client(cfg)
client = create_vector_client()
# 批量为租户创建索引
tenant_ids = ["companya", "companyb", "companyc"]
for tenant_id in tenant_ids:
index_name = f"tenant{tenant_id}"
result = client.put_vector_index(oss_vectors.models.PutVectorIndexRequest(
bucket=BUCKET,
index_name=index_name,
dimension=1024,
data_type="float32",
distance_metric="cosine",
))
print(f"索引 {index_name} 创建完成,status_code={result.status_code}")运行后输出:
索引 tenantcompanya 创建完成,status_code=200
索引 tenantcompanyb 创建完成,status_code=200
索引 tenantcompanyc 创建完成,status_code=200按租户写入数据
将不同租户的数据写入各自的索引。
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
ACCOUNT_ID = "<your-account-id>"
REGION = "cn-hangzhou"
BUCKET = "<your-vector-bucket>"
def create_vector_client():
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
cfg = oss.config.load_default()
cfg.credentials_provider = credentials_provider
cfg.region = REGION
cfg.account_id = ACCOUNT_ID
return oss_vectors.Client(cfg)
client = create_vector_client()
# 向租户 A 的索引写入数据
result = client.put_vectors(oss_vectors.models.PutVectorsRequest(
bucket=BUCKET,
index_name="tenantcompanya",
vectors=[
{
"key": "faq_001",
"data": {"float32": [0.1] * 1024}, # 向量维度需与索引一致
"metadata": {"tenant": "company_a", "category": "faq"}
}
]
))
print(f"租户 A 写入完成,status_code={result.status_code}")
# 向租户 B 的索引写入数据
result = client.put_vectors(oss_vectors.models.PutVectorsRequest(
bucket=BUCKET,
index_name="tenantcompanyb",
vectors=[
{
"key": "manual_001",
"data": {"float32": [0.2] * 1024}, # 向量维度需与索引一致
"metadata": {"tenant": "company_b", "category": "manual"}
}
]
))
print(f"租户 B 写入完成,status_code={result.status_code}")运行后输出:
租户 A 写入完成,status_code=200
租户 B 写入完成,status_code=200并发检索多个索引并合并结果
将大表拆分为多张小表后,通过并发检索多个索引再合并排序,降低总响应耗时。
from concurrent.futures import ThreadPoolExecutor, as_completed
import alibabacloud_oss_v2 as oss
import alibabacloud_oss_v2.vectors as oss_vectors
ACCOUNT_ID = "<your-account-id>"
REGION = "cn-hangzhou"
BUCKET = "<your-vector-bucket>"
def create_vector_client():
credentials_provider = oss.credentials.EnvironmentVariableCredentialsProvider()
cfg = oss.config.load_default()
cfg.credentials_provider = credentials_provider
cfg.region = REGION
cfg.account_id = ACCOUNT_ID
return oss_vectors.Client(cfg)
def search_index(client, index_name, query_vector, top_k=10):
"""检索单个索引"""
result = client.query_vectors(oss_vectors.models.QueryVectorsRequest(
bucket=BUCKET,
index_name=index_name,
query_vector=query_vector,
return_metadata=True,
return_distance=True,
top_k=top_k,
))
return {
"index": index_name,
"status_code": result.status_code,
"vectors": result.vectors or [ ],
}
def parallel_search(index_names, query_vector, top_k=10):
"""并发检索多个索引并合并结果"""
client = create_vector_client()
all_vectors = [ ]
with ThreadPoolExecutor(max_workers=len(index_names)) as executor:
futures = {
executor.submit(search_index, client, idx, query_vector, top_k): idx
for idx in index_names
}
for future in as_completed(futures):
result = future.result()
print(f"索引 {result['index']} 返回 {len(result['vectors'])} 条结果")
all_vectors.extend(result["vectors"])
# 按 distance 升序排序(距离越小越相似),取全局 TopK
all_vectors.sort(key=lambda v: v.get("distance", float("inf")))
return all_vectors[:top_k]
# 并发检索 3 个分表索引
indices = ["tenantcompanya", "tenantcompanyb", "tenantcompanyc"]
query_vec = {"float32": [0.1] * 1024} # 向量维度需与索引一致
results = parallel_search(indices, query_vec, top_k=5)
print(f"\n合并后全局 Top5:")
for v in results:
print(f" key={v.get('key')}, distance={v.get('distance')}, metadata={v.get('metadata')}")运行后输出:
索引 tenantcompanya 返回 1 条结果
索引 tenantcompanyb 返回 1 条结果
索引 tenantcompanyc 返回 0 条结果
合并后全局 Top5:
key=faq_001, distance=0.0, metadata={'tenant': 'company_a', 'category': 'faq'}
key=manual_001, distance=0.19999998807907104, metadata={'tenant': 'company_b', 'category': 'manual'}说明:并发检索多个索引后,在客户端按 distance 排序合并结果。如需更高精度,可引入 Rerank 模型进行二次精排。
Go SDK
开始前请安装 alibabacloud-oss-go-sdk-v2 SDK:
go get github.com/aliyun/alibabacloud-oss-go-sdk-v2确保已配置环境变量 OSS_ACCESS_KEY_ID 和 OSS_ACCESS_KEY_SECRET。
创建多租户索引
package main
import (
"context"
"fmt"
"log"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/vectors"
)
const (
region = "cn-hangzhou"
bucketName = "<your-vector-bucket>"
accountId = "<your-account-id>"
)
func main() {
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region).
WithAccountId(accountId)
client := vectors.NewVectorsClient(cfg)
// 批量为租户创建索引
tenantIDs := [ ]string{"companya", "companyb", "companyc"}
for _, tenantID := range tenantIDs {
indexName := fmt.Sprintf("tenant%s", tenantID)
result, err := client.PutVectorIndex(context.TODO(), &vectors.PutVectorIndexRequest{
Bucket: oss.Ptr(bucketName),
IndexName: oss.Ptr(indexName),
Dimension: oss.Ptr(1024),
DataType: oss.Ptr("float32"),
DistanceMetric: oss.Ptr("cosine"),
})
if err != nil {
log.Printf("索引 %s 创建失败: %v", indexName, err)
continue
}
fmt.Printf("索引 %s 创建完成,status_code=%d\n", indexName, result.StatusCode)
}
}运行后输出:
索引 tenantcompanya 创建完成,status_code=200
索引 tenantcompanyb 创建完成,status_code=200
索引 tenantcompanyc 创建完成,status_code=200并发检索多个索引并合并结果
package main
import (
"context"
"fmt"
"log"
"sort"
"sync"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/credentials"
"github.com/aliyun/alibabacloud-oss-go-sdk-v2/oss/vectors"
)
const (
region = "cn-hangzhou"
bucketName = "<your-vector-bucket>"
accountId = "<your-account-id>"
dimension = 1024
)
func makeVector(val float32, dim int) [ ]float32 {
v := make([ ]float32, dim)
for i := range v {
v[i] = val
}
return v
}
func main() {
cfg := oss.LoadDefaultConfig().
WithCredentialsProvider(credentials.NewEnvironmentVariableCredentialsProvider()).
WithRegion(region).
WithAccountId(accountId)
client := vectors.NewVectorsClient(cfg)
indices := [ ]string{"tenantcompanya", "tenantcompanyb", "tenantcompanyc"}
queryVector := map[string]any{"float32": makeVector(0.1, dimension)}
var mu sync.Mutex
var allVectors [ ]map[string]any
var wg sync.WaitGroup
for _, indexName := range indices {
wg.Add(1)
go func(idx string) {
defer wg.Done()
result, err := client.QueryVectors(context.TODO(), &vectors.QueryVectorsRequest{
Bucket: oss.Ptr(bucketName),
IndexName: oss.Ptr(idx),
QueryVector: queryVector,
ReturnMetadata: oss.Ptr(true),
ReturnDistance: oss.Ptr(true),
TopK: oss.Ptr(10),
})
if err != nil {
log.Printf("索引 %s 检索失败: %v", idx, err)
return
}
fmt.Printf("索引 %s 返回 %d 条结果\n", idx, len(result.Vectors))
mu.Lock()
allVectors = append(allVectors, result.Vectors...)
mu.Unlock()
}(indexName)
}
wg.Wait()
// 按 distance 升序排序,取全局 Top5
sort.Slice(allVectors, func(i, j int) bool {
di, _ := allVectors[i]["distance"].(float64)
dj, _ := allVectors[j]["distance"].(float64)
return di < dj
})
topK := 5
if len(allVectors) < topK {
topK = len(allVectors)
}
fmt.Printf("\n合并后全局 Top%d:\n", topK)
for _, v := range allVectors[:topK] {
fmt.Printf(" key=%v, distance=%v, metadata=%v\n", v["key"], v["distance"], v["metadata"])
}
}运行后输出:
索引 tenantcompanya 返回 1 条结果
索引 tenantcompanyc 返回 0 条结果
索引 tenantcompanyb 返回 1 条结果
合并后全局 Top2:
key=faq_001, distance=0, metadata=map[category:faq tenant:company_a]
key=manual_001, distance=0.19999998807907104, metadata=map[category:manual tenant:company_b]最佳实践
索引命名规范:以租户 ID 或业务维度作为索引名称的后缀(如
tenant{tenantid})。索引名仅支持小写字母和数字,不支持下划线和连字符。租户数较多时:直接利用索引名称进行逻辑隔离。OSS 向量索引的创建是秒级的,管理开销极低。
追求极低延迟时:当单索引超过千万级数据量,按业务逻辑(如时间、类别)进行水平拆分,通过并发检索多个索引再合并结果。
结果重排(Rerank):多索引表的检索结果合并后,可以根据距离相似度进行简单重排,也可引入 Rerank 模型进行二次排序。
索引清理:删除某个租户或业务的数据只需调用
DeleteVectorIndex删除对应索引,无需逐条过滤删除。