
本文档介绍了如何进行音色克隆,并进行管理。
概念介绍
通过大模型技术进行特征提取,从而完成声音的复刻,且无需训练过程。仅需提供时长较短的音频,即可迅速生成高度相似且听感自然的定制声音。
功能入口
进入智能外呼机器人控制台,选择大模型场景管理,进入声音克隆页面。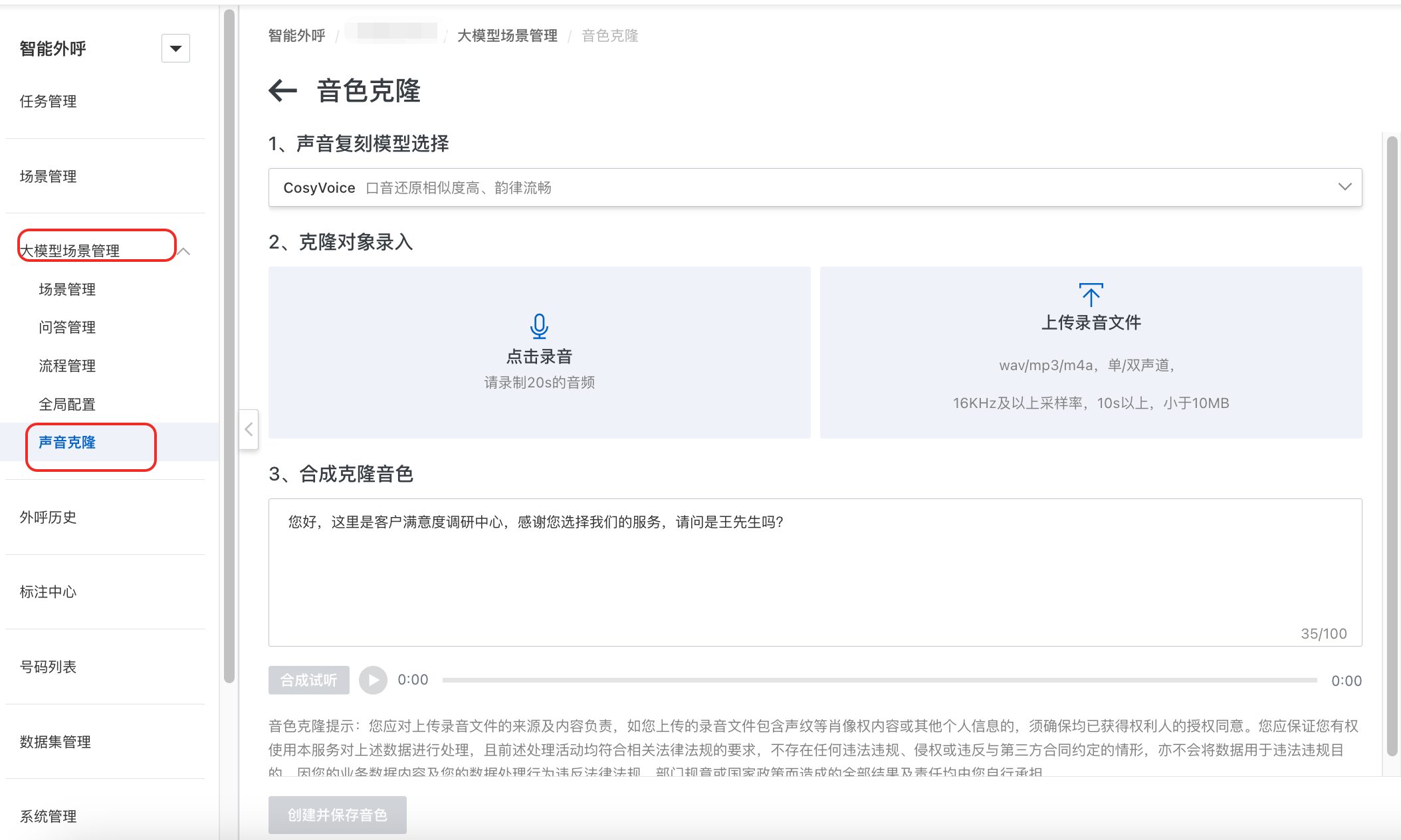
功能说明
声音复刻模型选择
支持Qwen3、CosyVoice 的声音克隆能力模型选择,即在音色克隆页面中可以自定义选择声音复刻模型,可根据具体场景选择适合的克隆音色模型。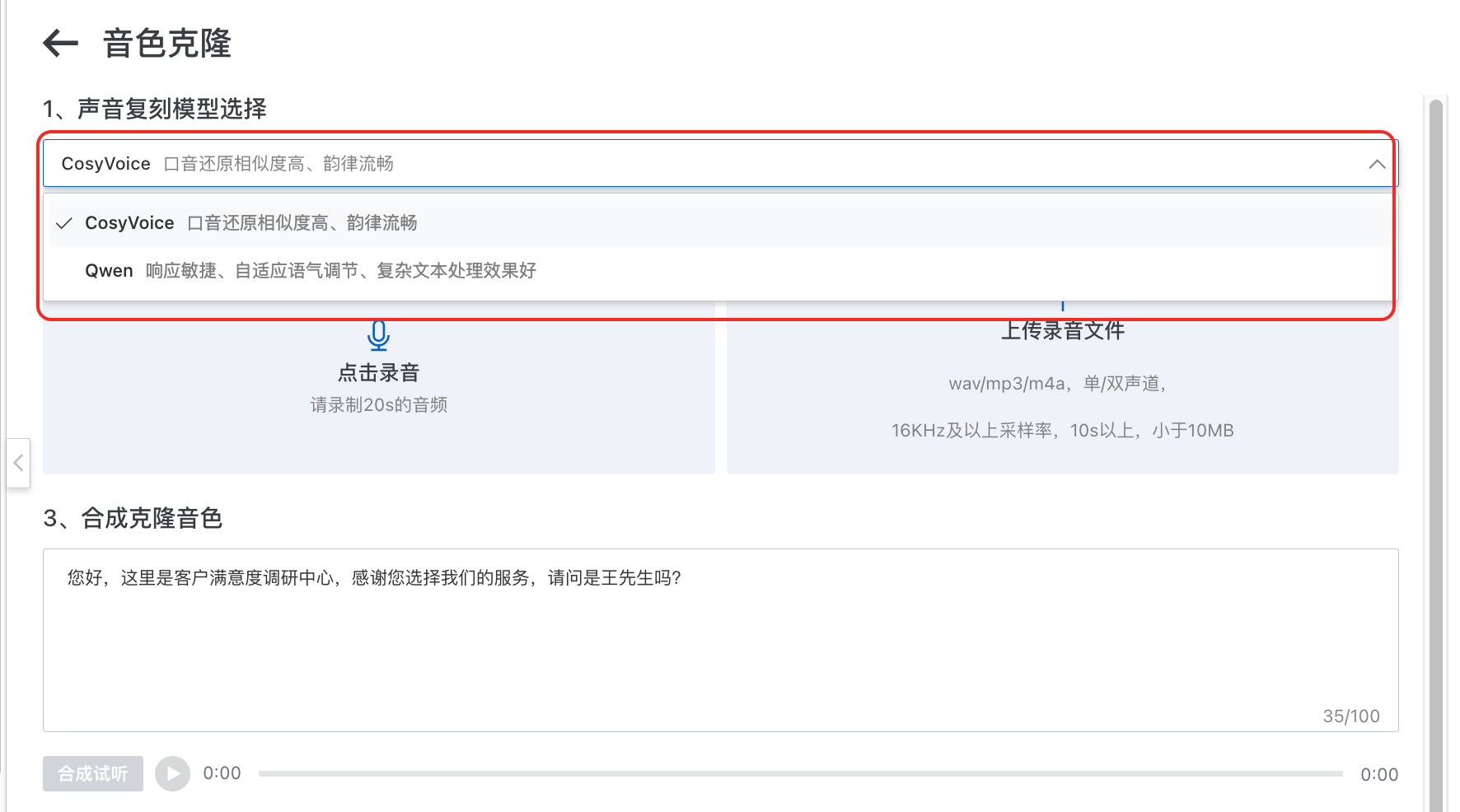
克隆对象录入
使用声音克隆时可以通过点击录音、上传录音文件两种方式作为需要克隆的对象。
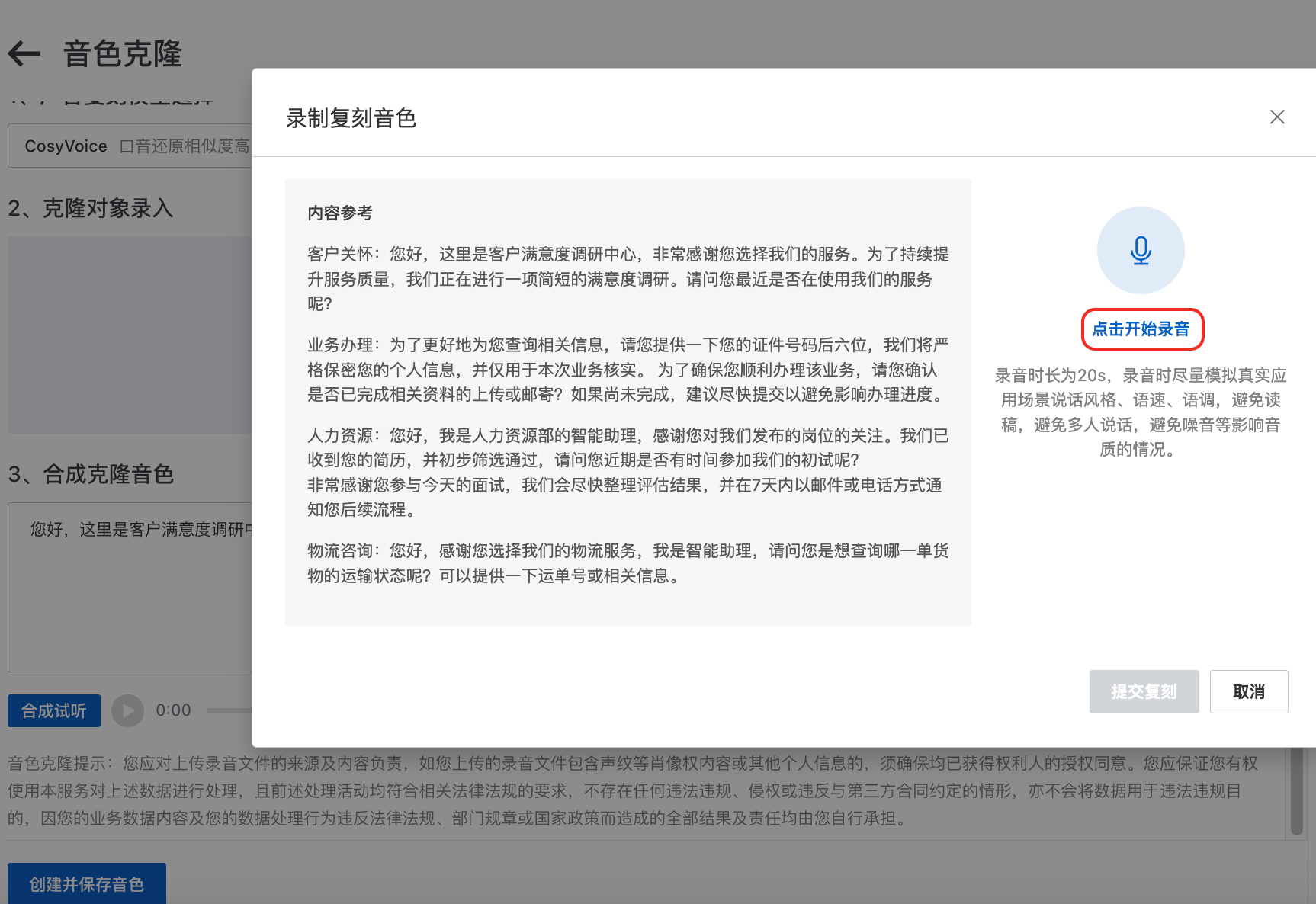
点击录音:当选择点击开启录音后,可以根据参考内容进行朗读进行声音录制,录制完成后点击提交复刻按钮即可。
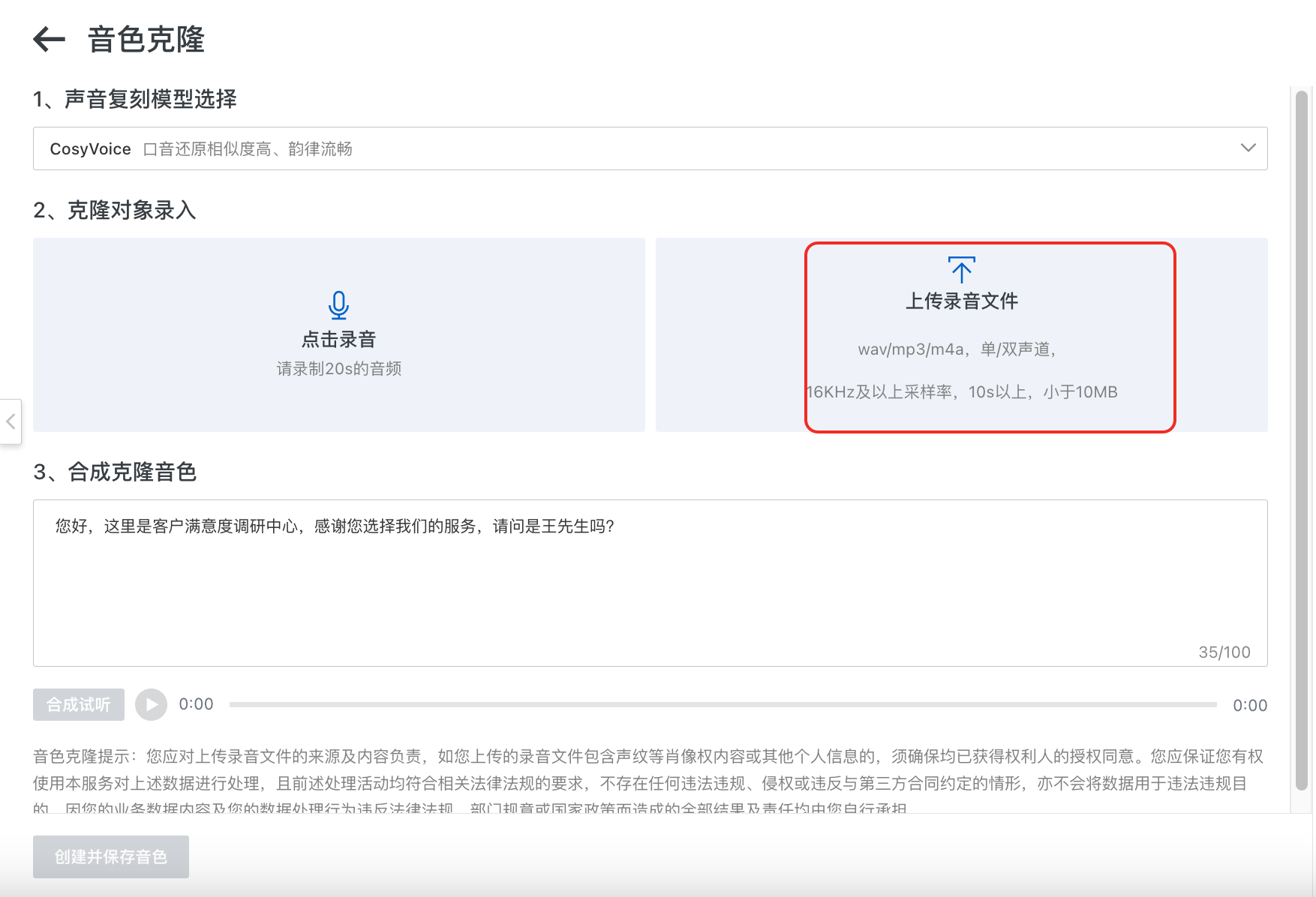
上传录音文件:支持wav、mp3、m4a格式,支持单、双声道录音文件。音频采样率,默认值:16000Hz。音频最好在10s以上,并且音频文件须小于10MB。
合成克隆音色
复刻后的声音可以通过书写测试文本,再进行点击合成试听按钮进行试听。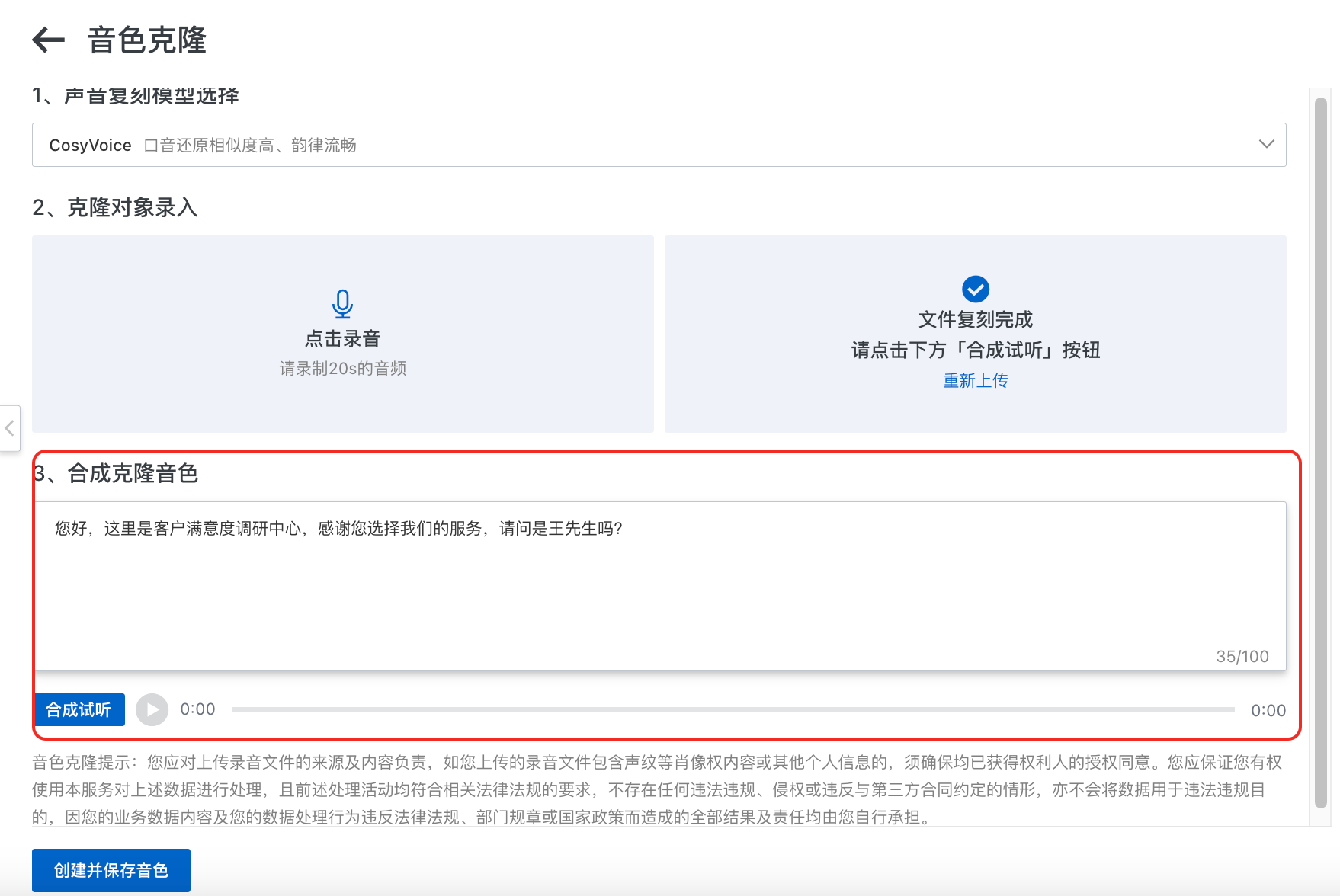
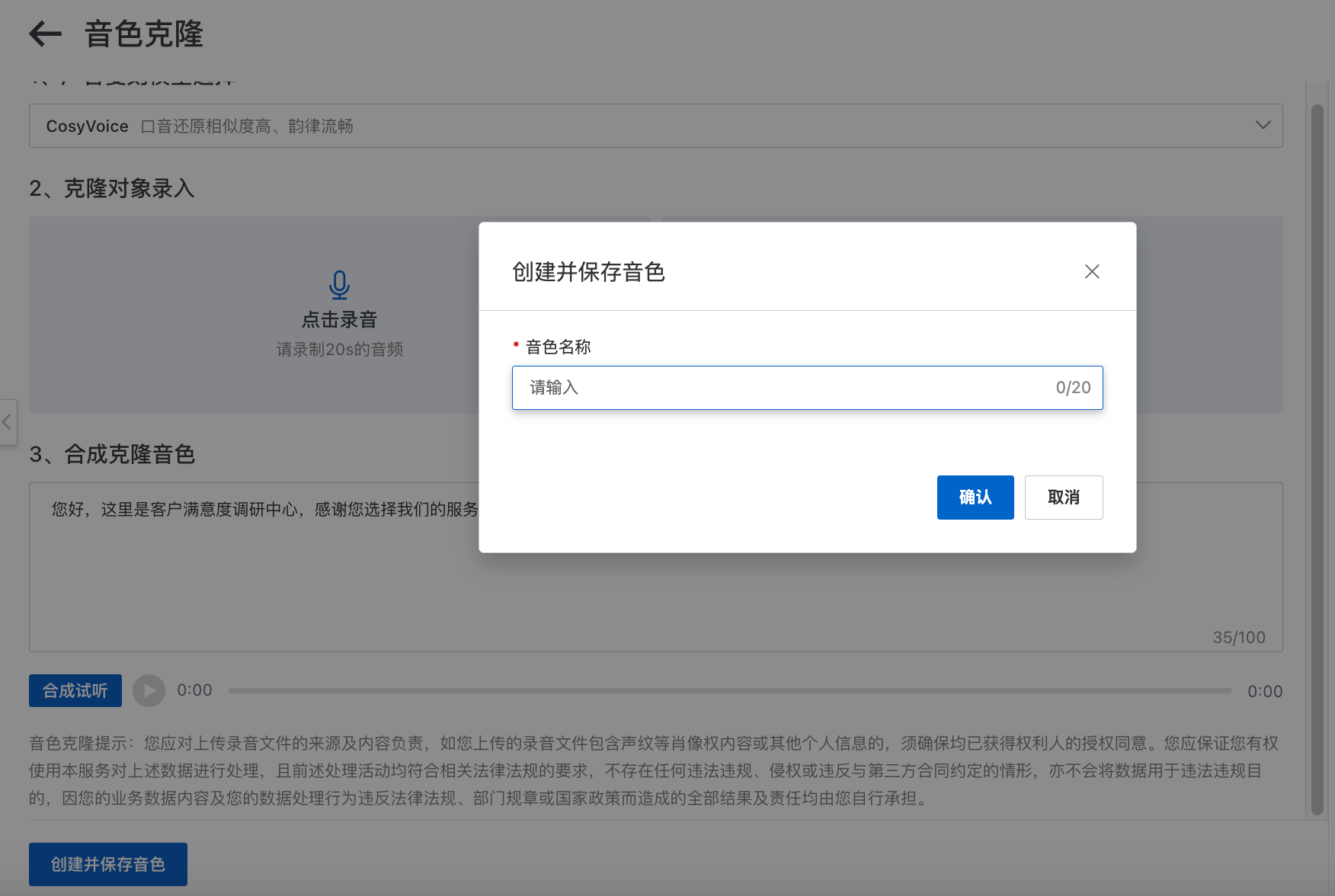
保存克隆音色
当音色克隆完成后,并且通过试听后觉得该克隆音色符合要求,即可点击创建并保存音色按钮进行保存。
说明
声音克隆保存时,需注意已保存的音色总数是否达到5个,当达到5个时,会导致保存失败。
克隆音色列表
在界面的右侧列表中,可以查看已保存的音色列表。同时支持试听与删除。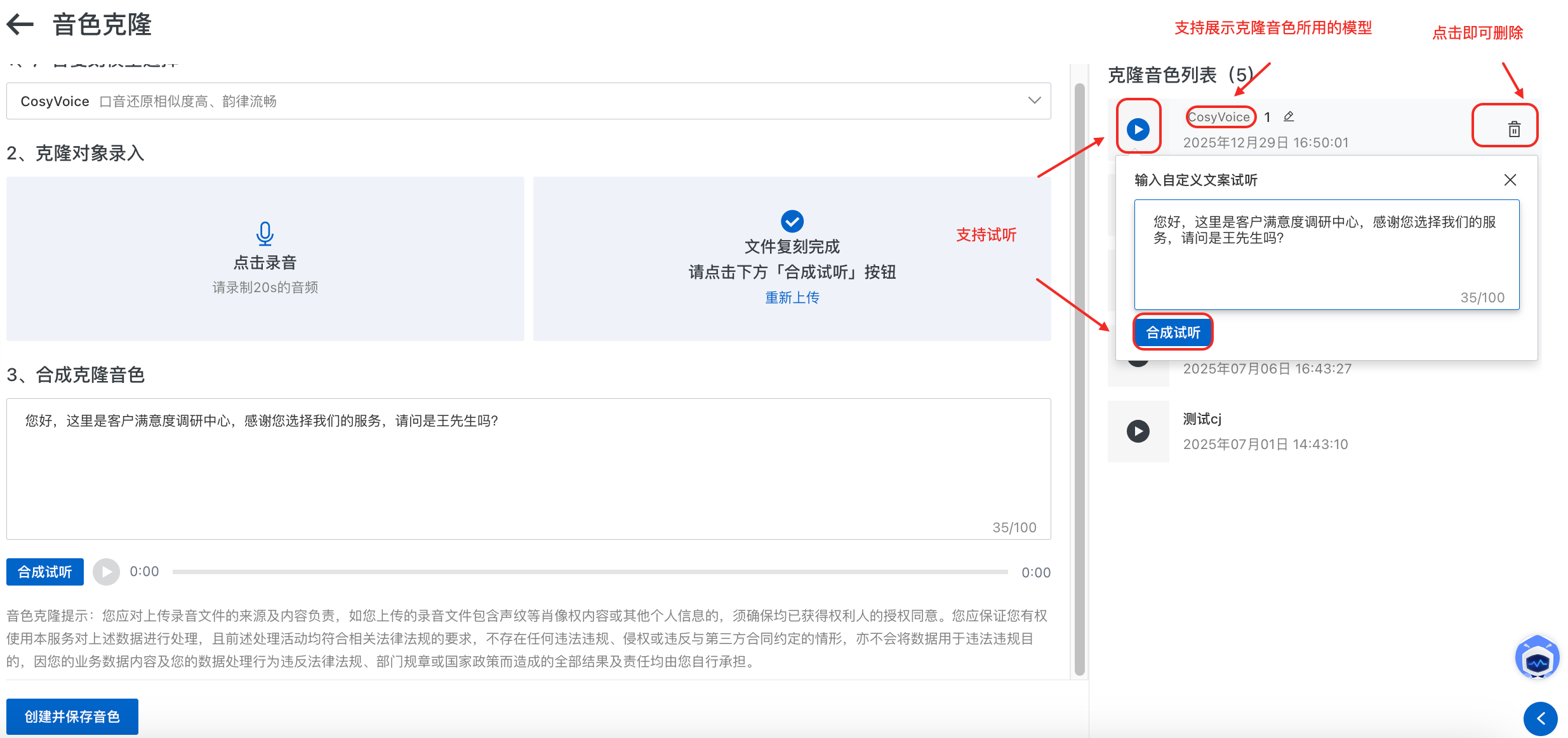
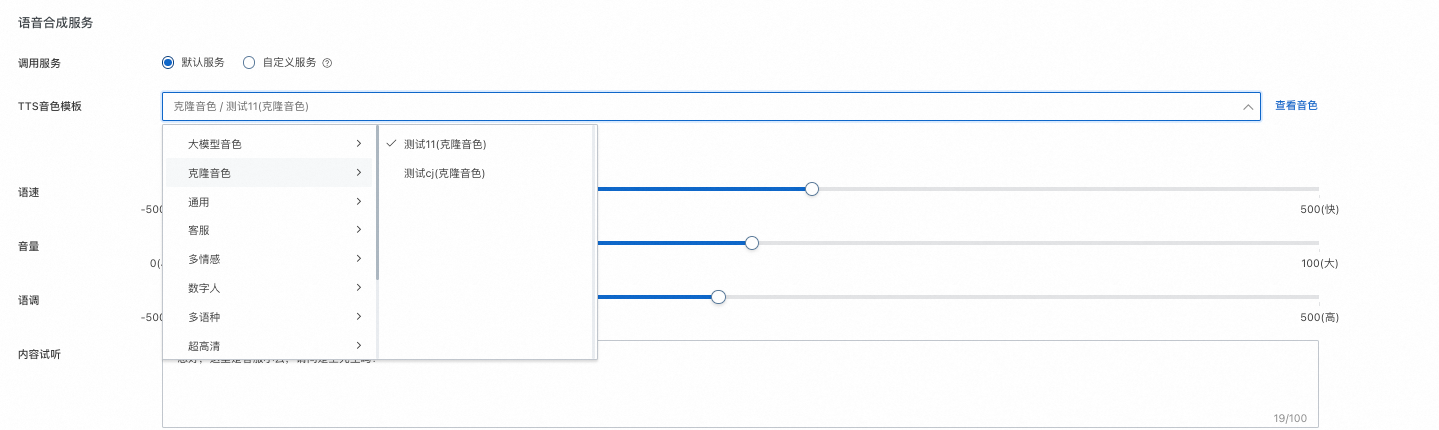
克隆音色的使用
在配置外呼场景时,可在场景中的语音&VUI的语音合成服务中进行选择配置。在TTS音色模板中选择克隆音色,即可使用。
该文章对您有帮助吗?