
通过推荐算法定制生成的特征工程,对原始数据集(包括用户表、物料表和行为表等)进行处理,并生成新的特征表,以供后续的召回和排序使用。
前提条件
已开通PAI(Designer),并创建默认工作空间。具体操作,请参见开通PAI并创建默认工作空间。
已为工作空间绑定MaxCompute资源。具体操作,请参见管理工作空间计算资源。
已创建MaxCompute数据源,并将该数据源绑定为工作空间的引擎。具体操作,请参见创建MaxCompute数据源。
数据集
为了演示以下特征工程,本数据使用脚本模拟构造生成用户(user)表、物料(item)表和行为(behavior)表,并非真实数据集。
用户表:pai_online_project.rec_sln_demo_user_table
字段名 | 类型 | 描述 |
user_id | bigint | 用户唯一ID |
gender | string | 性别 |
age | bigint | 年龄 |
city | string | 城市 |
item_cnt | bigint | 创作内容数 |
follow_cnt | bigint | 关注数 |
follower_cnt | bigint | 粉丝数 |
register_time | bigint | 注册时间 |
tags | string | 用户标签 |
ds | string | 表分区列名 |
物料表:pai_online_project.rec_sln_demo_item_table
字段名 | 类型 | 描述 |
item_id | bigint | 物料ID |
duration | double | 视频时长 |
title | string | 标题 |
category | string | 一级标签 |
author | bigint | 作者 |
click_count | bigint | 累计点击数 |
praise_count | bigint | 累计点赞数 |
pub_time | bigint | 发布时间 |
ds | string | 表分区列名 |
行为表:pai_online_project.rec_sln_demo_behavior_table
字段名 | 类型 | 描述 |
request_id | bigint | 埋点ID/请求ID |
user_id | bigint | 用户唯一ID |
exp_id | string | 实验ID |
page | string | 页面 |
net_type | string | 网络类型 |
event_time | bigint | 行为事件发生的时间 |
item_id | bigint | 物品ID |
event | string | 行为事件类型 |
playtime | double | 播放时长/阅读时长 |
ds | string | 表分区列名 |
特征工程
步骤一:进入Designer页面
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型开发与训练 > 可视化建模(Designer),进入Designer页面。
步骤二:构建工作流
在Designer页面,单击预置模板页签。
在模板列表的推荐解决方案-特征工程区域,单击创建。
在新建工作流对话框,配置参数(可以全部使用默认参数)。
其中: 工作流数据存储配置为OSS Bucket路径,用于存储工作流运行中产出的临时数据和模型。
单击确定。
您需要等待大约十秒钟,工作流可以创建成功。
在工作流列表,双击推荐解决方案-特征工程工作流,进入工作流。
系统根据预置的模板,自动构建工作流,如下图所示。
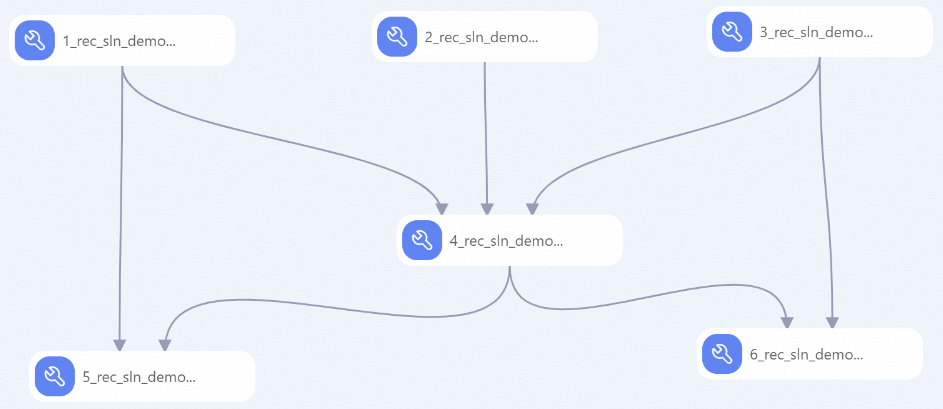
节点
描述
1
物料表预处理:
将Tag特征分隔符替换为
chr(29)供后续特征生成步骤(FG)使用。产出是否是新上架物料的特征。
2
行为表预处理:产出day_h、week_day等行为时间的衍生特征。
3
用户表预处理:
产出是否是新注册用户的特征。
将Tag特征分隔符替换为
chr(29)供后续特征生成步骤(FG)使用。
4
关联行为表、用户表和物料表,形成带统计属性的行为日志宽表。
5
生成物料特征表,包含一段时间的物料统计特征:
item__{event}_cnt_{N}d:N天内该物料上发生某行为的数目,表征物料热门程度。item__{event}_{itemid}_dcnt_{N}d:N天内该物料上发生某行为的唯一用户数,表征物料热门程度。item__{min|max|avg|sum}_{field}_{N}d:N天内发生在该物料的正向行为中,用户某数值属性上的统计分布,表征物料被哪种数值属性的用户偏好。item__kv_{cate}_{event}_{N}d:N天内发生在该物料上的某行为中,用户某类目属性的统计,表征物料被哪种类目属性的用户偏好。
6
生成用户特征表,包含一段时间的用户统计特征。
步骤三:添加函数
新建业务流程。具体操作,请参见创建业务流程。
右键单击新建的业务流程下的MaxCompute,选择新建资源>Python,新建一个名称为count_cates_kvs.py的python脚本资源。具体操作,请参见创建并使用MaxCompute资源。
右键单击新建的业务流程下的MaxCompute,选择新建函数。新建一个名称为COUNT_CATES_KVS的MaxCompute函数。其中类名配置为
count_cates_kvs.CountCatesKVS,资源列表配置为count_cates_kvs.py。具体操作,请参见创建并使用自定义函数。
步骤四:运行工作流并查看输出结果
本数据集默认使用的是45天的数据,将会运行较长时间。如果希望更快地完成运行,需要进行如下操作:
更新执行时间窗口参数,使用更少时间内的数据。
分别单击以下节点,将右侧参数设置页签的执行时间窗口参数由默认的
(-45,0]改为(-9,0]:1_rec_sln_demo_item_table_preprocess_v22_rec_sln_demo_behavior_table_preprocess_ v23_rec_sln_demo_user_table_preprocess_v24_rec_sln_demo_behavior_table_preprocess_wide_v2
分别单击以下节点,将右侧参数设置页签的执行时间窗口参数由默认的
(-31,0]改为(-8,0]:5_rec_sln_demo_item_table_preprocess_all_feature_v26_rec_sln_demo_user_table_preprocess_all_feature_v2
修改SQL脚本代码,选取一部分用户。
单击节点
2_rec_sln_demo_behavior_table_preprocess_ v2,将右侧参数设置页签的SQL脚本参数配置代码的第32行由WHERE ds = '${pai.system.cycledate}'改为WHERE ds = '${pai.system.cycledate}' and user_id %10=1。单击节点
3_rec_sln_demo_user_table_preprocess_v2,将右侧参数设置页签的SQL脚本参数配置代码的第38行由WHERE ds = '${pai.system.cycledate}'改为WHERE ds = '${pai.system.cycledate}' and user_id %10=1。
单击Designer工作流画布上方的运行按钮
 。
。工作流运行结束后,查看以下MaxCompute表是否有30天的数据:
物料特征表:
rec_sln_demo_item_table_preprocess_all_feature_v2行为日志宽表:
rec_sln_demo_behavior_table_preprocess_v2用户特征表:
rec_sln_demo_user_table_preprocess_all_feature_v2
您可以在SQL查询页面,查询上述表数据。具体操作,请参见使用DataWorks连接。
说明表所属项目禁止了分区表全表扫描,需要指定分区条件。如果查询表数据的SQL需要进行全表扫描,您可以在SQL语句前加
set odps.sql.allow.fullscan=true;语句并一起提交运行。全表扫描会导致输入量增加从而使成本增加。