
Responsible AI(RAI)贯穿 AI 模型的开发、训练、微调、评估、部署、推理等环节,是保障模型安全、稳定、公平、符合社会道德的重要方法。PAI-AI安全治理提供安全护栏功能,旨在保障AI系统在提示词输入和模型推理结果中的内容安全性。
Qwen3Guard 是基于 Qwen3 构建的一系列开源安全审核模型。通过将输出分类为安全、争议性和不安全三个严重性级别,支持详细的风险评估,并适应各种部署场景。
本文以Qwen3Guard-Gen-0.6B 模型为例为您介绍如何在Model Gallery中 部署、微调以及在安全护栏中配置并使用Qwen3Guard进行安全检测。
使用限制
安全护栏功能地域限制:安全护栏功能仅限于华东2(上海)地域使用。
模型微调资源配置要求:最低为 24G 显存。
步骤一:模型部署和调用
模型部署
进入Model Gallery页面。
登录PAI控制台。
在顶部左上角选择华东2(上海)地域。
在左侧导航栏选择工作空间列表,单击指定工作空间名称,进入对应工作空间。
在左侧导航栏选择快速开始 > Model Gallery。
在Model Gallery页面搜索并单击 Qwen3Guard-Gen-0.6B 模型卡片,进入模型详情页面。
单击右上角部署,选择部署方式以及部署使用的资源信息,即可将模型部署到PAI-EAS推理服务平台。当前平台已支持多种部署框架,包括SGLang加速部署、vLLM加速部署。
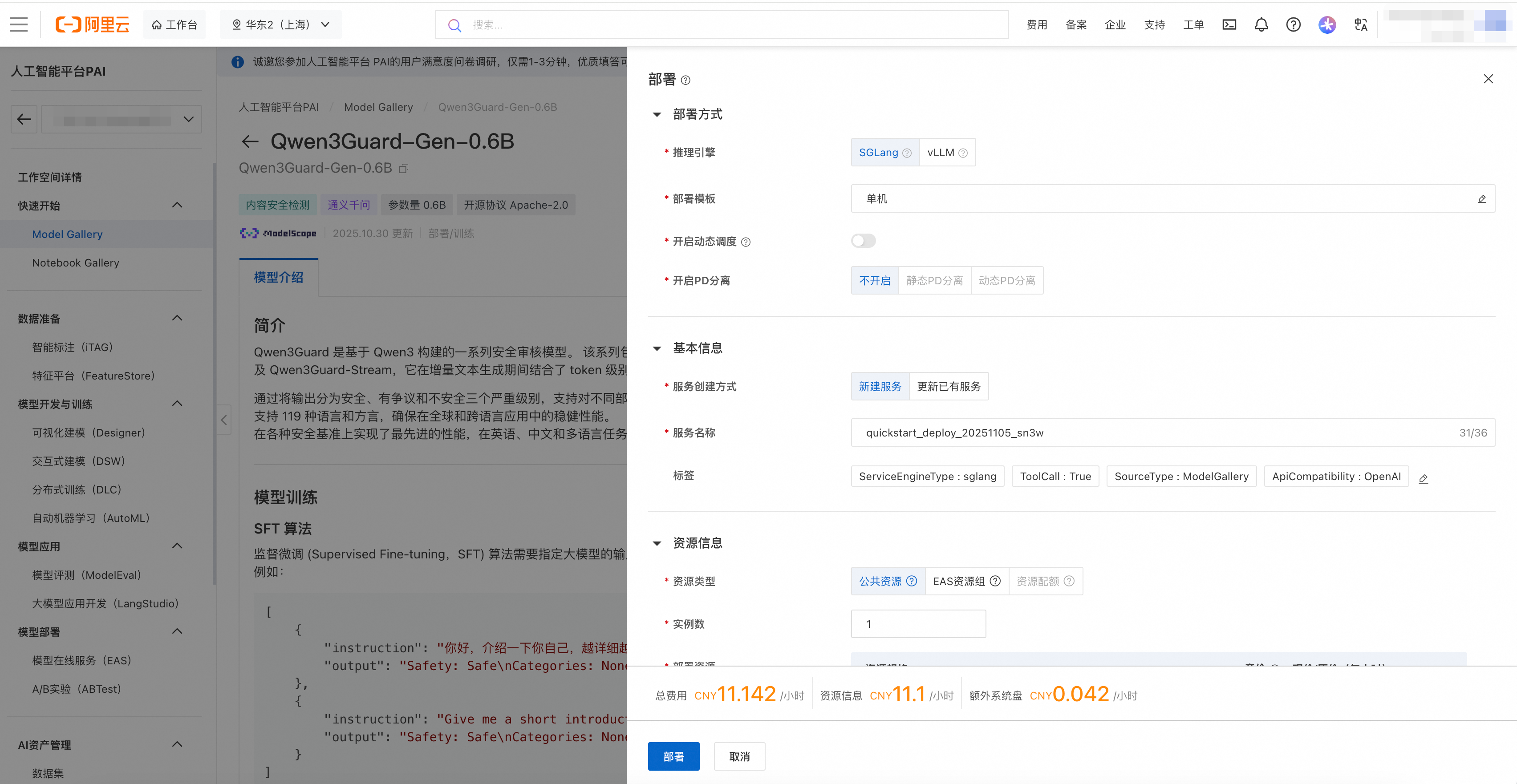
使用推理服务。部署成功后,在服务页面点击“查看调用信息”获取调用的Endpoint和Token,想了解服务调用方式可以点击预训练模型链接,返回模型介绍页查看调用方式说明。
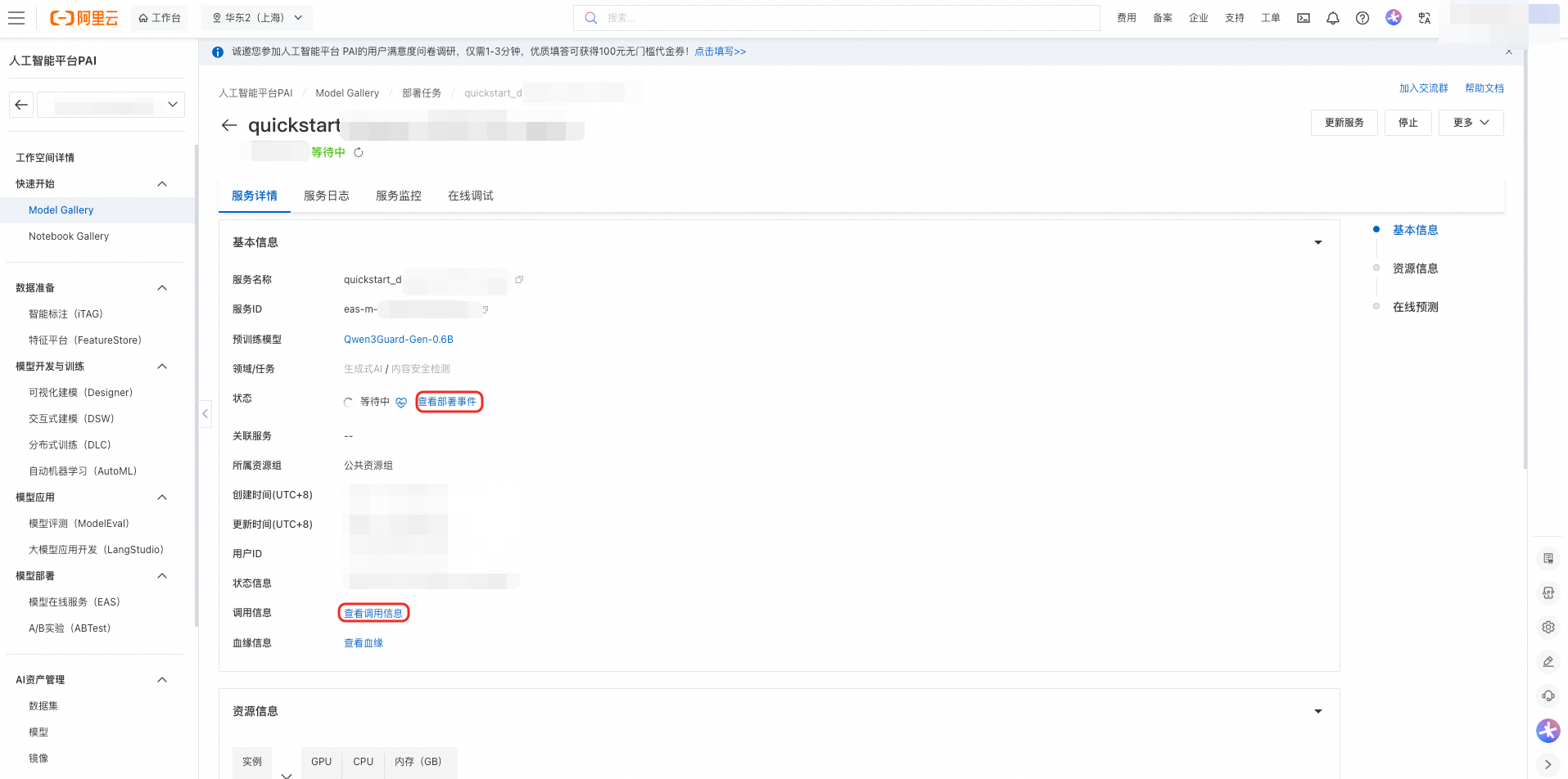
模型调用
您可以在 PAI-EAS 推理服务平台上在线调试已部署好的模型服务。
步骤二:模型微调训练(可选)
PAI-Model Gallery为 Qwen3Guard-Gen-0.6B 模型配置了 SFT(监督微调)算法,支持LoRA微调、全参微调2种方式,用户可以开箱即用,对模型进行微调。
数据准备
准备训练数据。由于Qwen3Guard 具有固定的对话模板,训练数据需要使用Qwen3Guard模板进行构建,可参考Qwen3Guard提示词模板文件。SFT 训练算法支持使用 JSON 格式的训练数据集。JSON格式训练数据示例如下(Qwen3Guard模板需要替换为实际内容):
[
{"instruction": "<|Qwen3Guard模版|> USER: 请你介绍一下自己。<|Qwen3Guard模版|> ", "output": "<|Qwen3Guard模版|> Safety: Safe\nCategories: None<|Qwen3Guard模版|> "},
{"instruction": "<|Qwen3Guard模版|> USER: 你是?\nASSISTANT: 我是小派,由PAI训练的人工智能助手。我的目标是为用户提供有用、准确和及时的信息,并通过各种方式帮助用户进行有效的沟通。请告诉我有什么可以帮助您的呢?<|Qwen3Guard模版|> ", "output": "<|Qwen3Guard模版|> Safety: Safe\nCategories: None\nRefusal: Yes<|Qwen3Guard模版|> "}
]模型微调
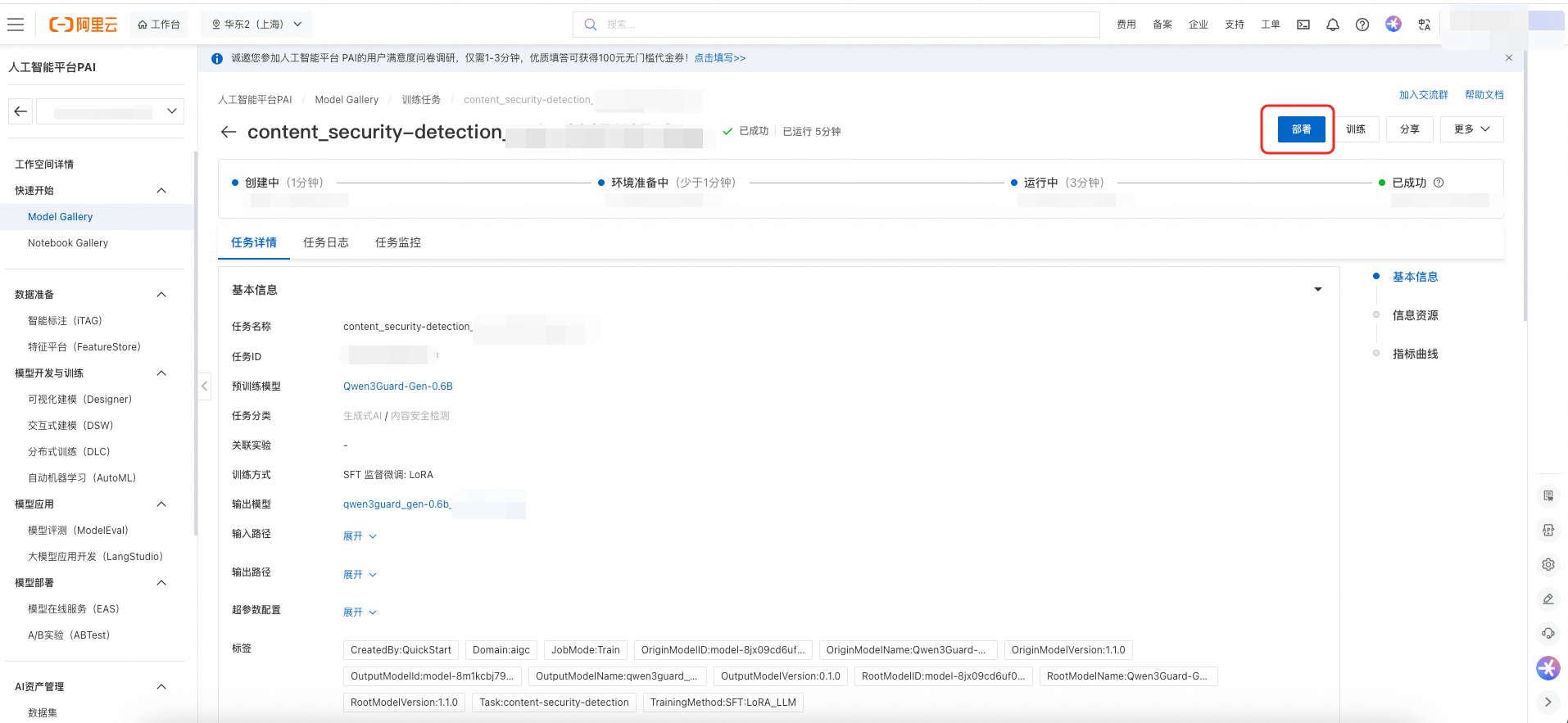
在模型详情页单击右上角训练。关键配置如下:
数据集配置:您可以将准备的数据集上传至对象存储OSS Bucket中,或是通过指定一个数据集对象,选择NAS或CPFS存储上的数据集。您也可以使用PAI预置的公共数据集,直接提交任务测试算法。
计算资源配置:训练任务推荐使用A10(24GB显存)及以上GPU资源。
模型输出路径:微调后的模型将存储在对象存储的OSS Bucket中,并支持下载。
参数配置:算法支持的超参数信息如下,您可以使用默认配置,或根据使用的数据,计算资源等按需调整。
单击训练开始进行训练,用户可以查看训练任务状态和训练日志。训练完成后,可以单击部署将微调后的模型部署为在线服务。
步骤三:安全策略配置与验证
创建安全专家模型
安全专家模型是执行风险检测的核心引擎,用于识别提示词和模型推理结果中的潜在风险。创建步骤如下:
登录PAI控制台,在页面上方选择华东2(上海)地域。
在左侧菜单栏单击安全护栏 > 安全专家模型 > 新建安全专家模型。
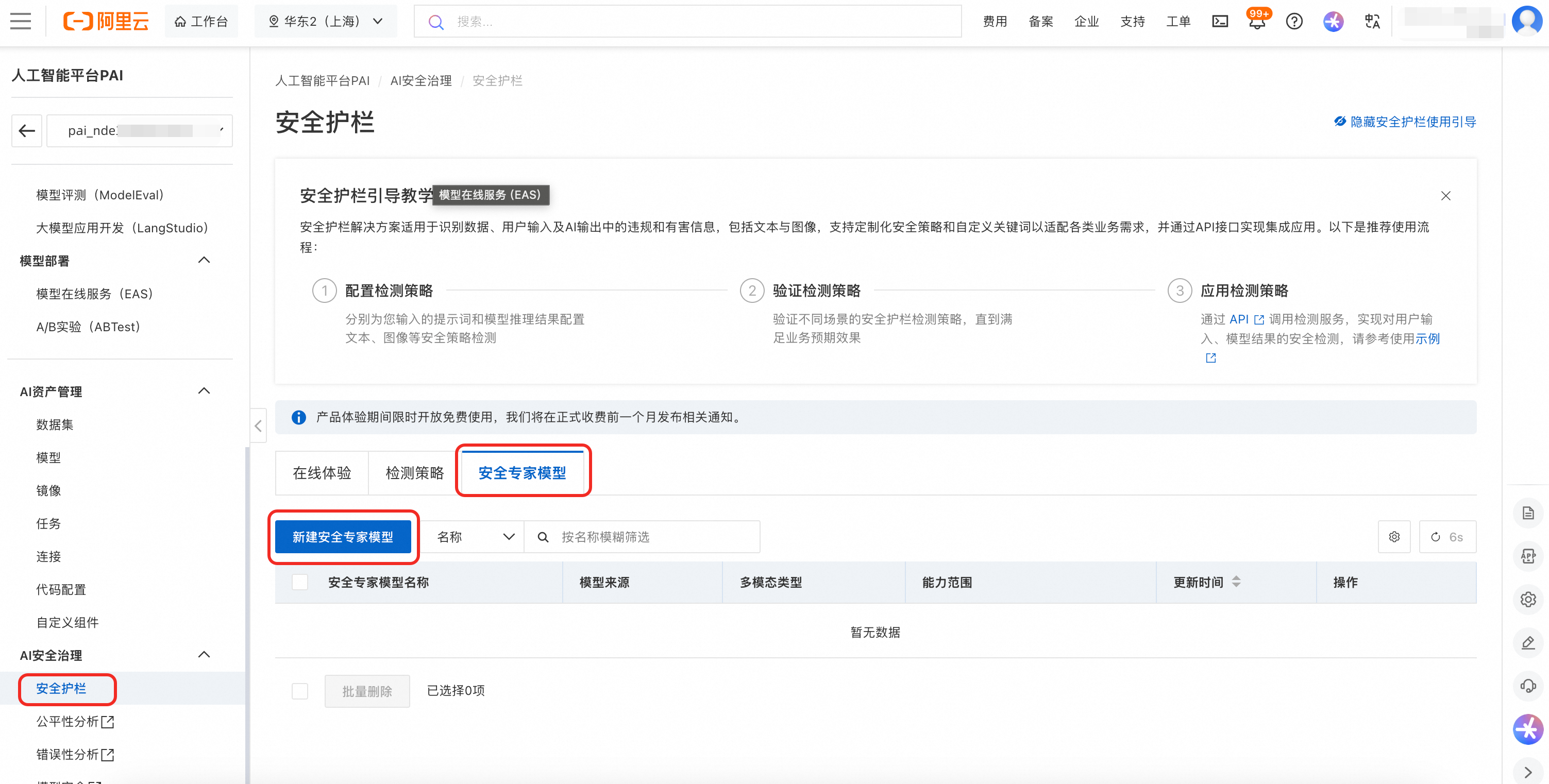
在创建页面配置如下关键参数:
模型来源:选择自定义。
安全专家模型类型:在下拉框中基于需求和模型的功能标签选择合适的安全专家模型,本文以Qwen3Guard-Gen 模型为例。
安全专家模型服务:选择在PAI-EAS 部署成功的 Qwen3Guard-Gen-0.6B服务。
扩展参数:模型名称。可通过模型详情页(在Model Gallery页单击模型卡片)查看模型名称的获取方法。

配置检测策略
创建安全专家模型后,通过检测策略管理模块配置检测规则,并将规则与已创建的模型关联,以形成完整的安全策略。
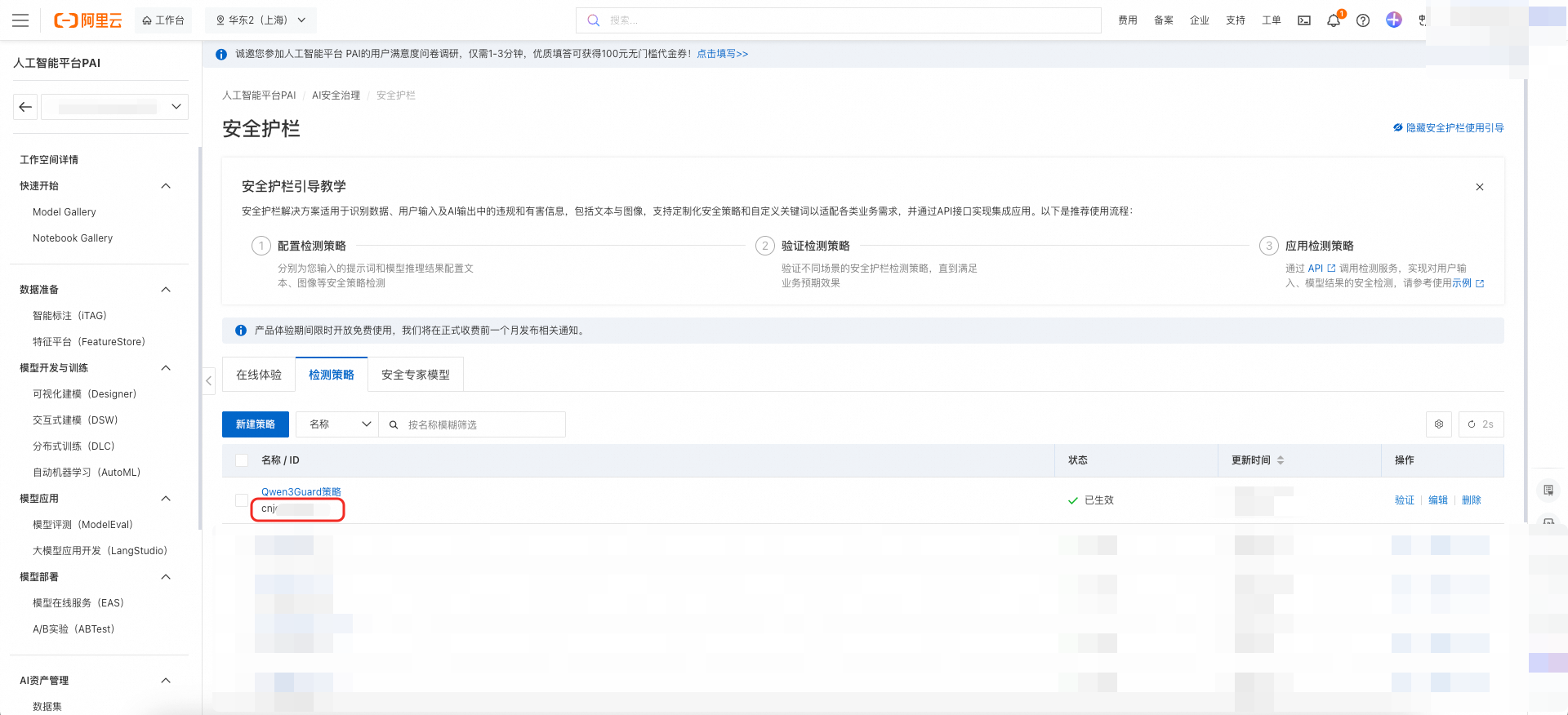
配置基本信息:为安全策略命名,并通过适用场景定义策略的应用范围。本示例选择同时对提示词输入和模型推理结果进行检测。
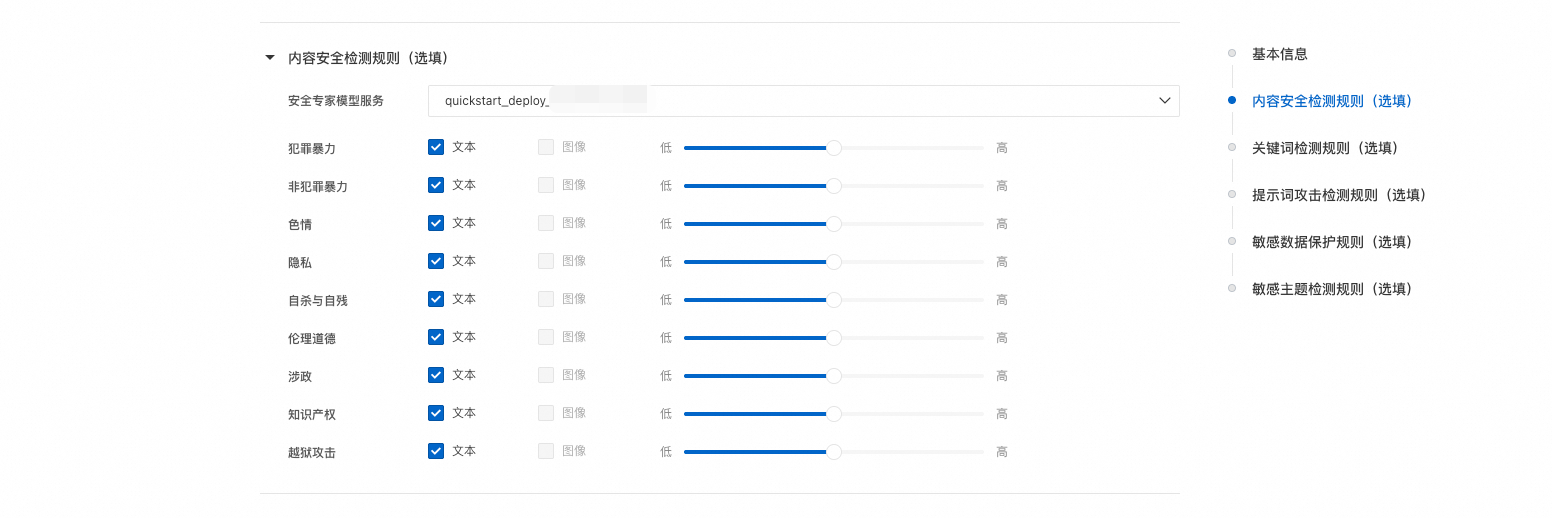
配置内容安全检测规则(选填):选择上述已完成注册的安全专家模型。为不同的风险分类项配置不同的检测强度,以平衡检测的精确率和召回率。您可根据业务数据迭代优化配置等级,并通过在线体验页面不断验证和调优。本示例将所有支持的风险标签的安全等级均配置为“中”。
低等级:采用高召回率策略,优先扩大风险覆盖范围,可检测更多潜在风险样本,但可能伴随较高误报率,适用于对漏报容忍度低的场景。
高等级:采用高精确率策略,仅保留高置信度风险判定结果,显著降低误报率,但可能漏检部分边缘案例,适用于对误报容忍度低的场景。
中等级:在高召回率和高精确率之间取得平衡。
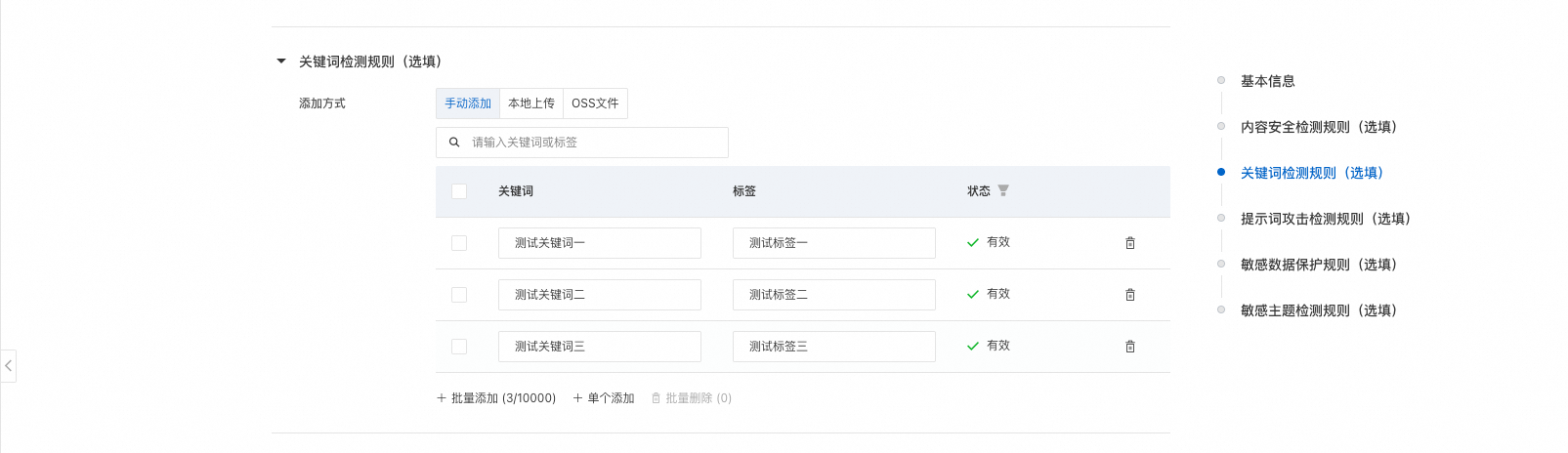
配置关键词规则(选填):通过关键词规则配置,可根据业务场景需求自定义关键词库。本示例通过手动添加方式,添加若干关键词及其对应的风险标签。
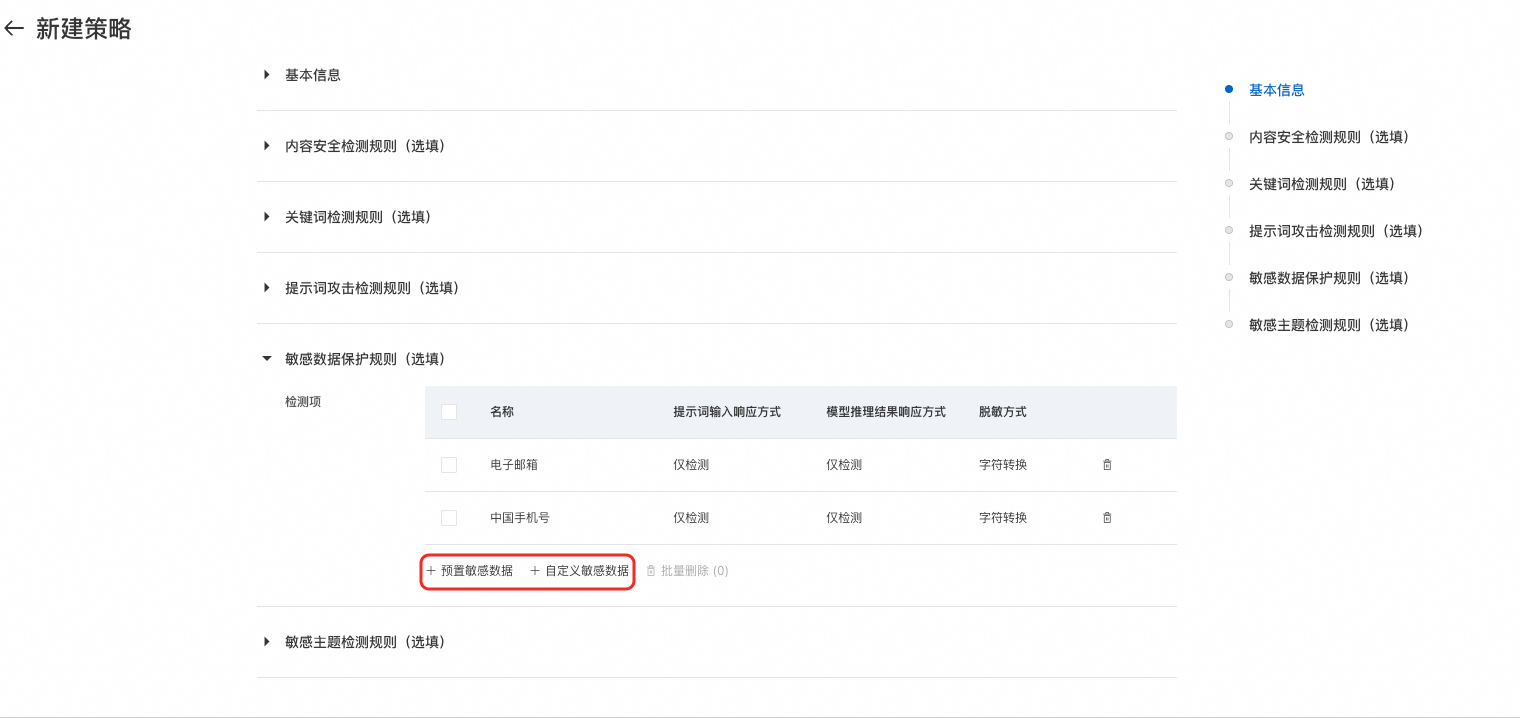
配置敏感数据保护(选填):敏感数据保护规则用于识别和防护个人信息等敏感数据。系统支持多种预定义的敏感数据类型检测,并支持通过自定义正则表达式扩展检测能力。

验证策略
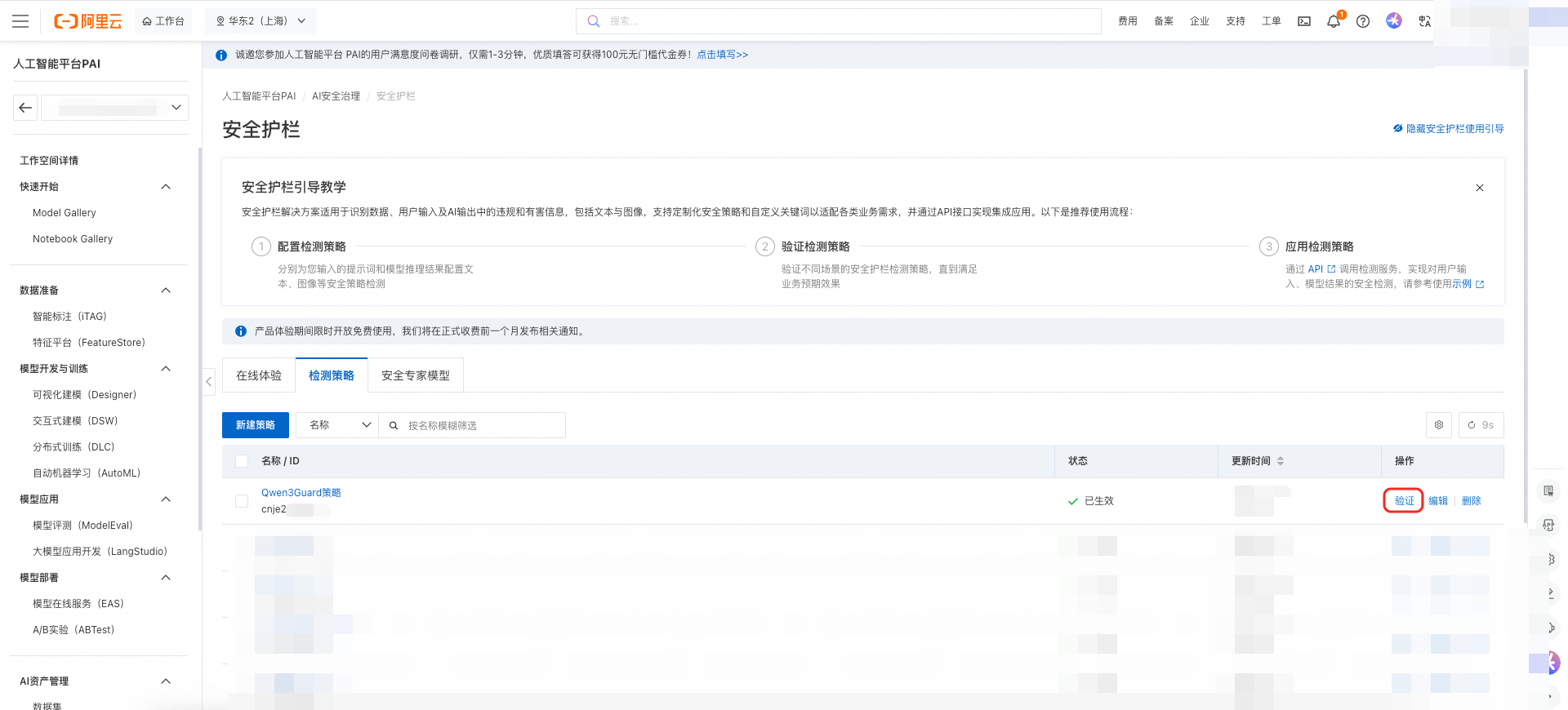
策略配置完成后,在检测策略列表页单击验证,在文本框输入待检测文本后,单击检测验证检测策略。
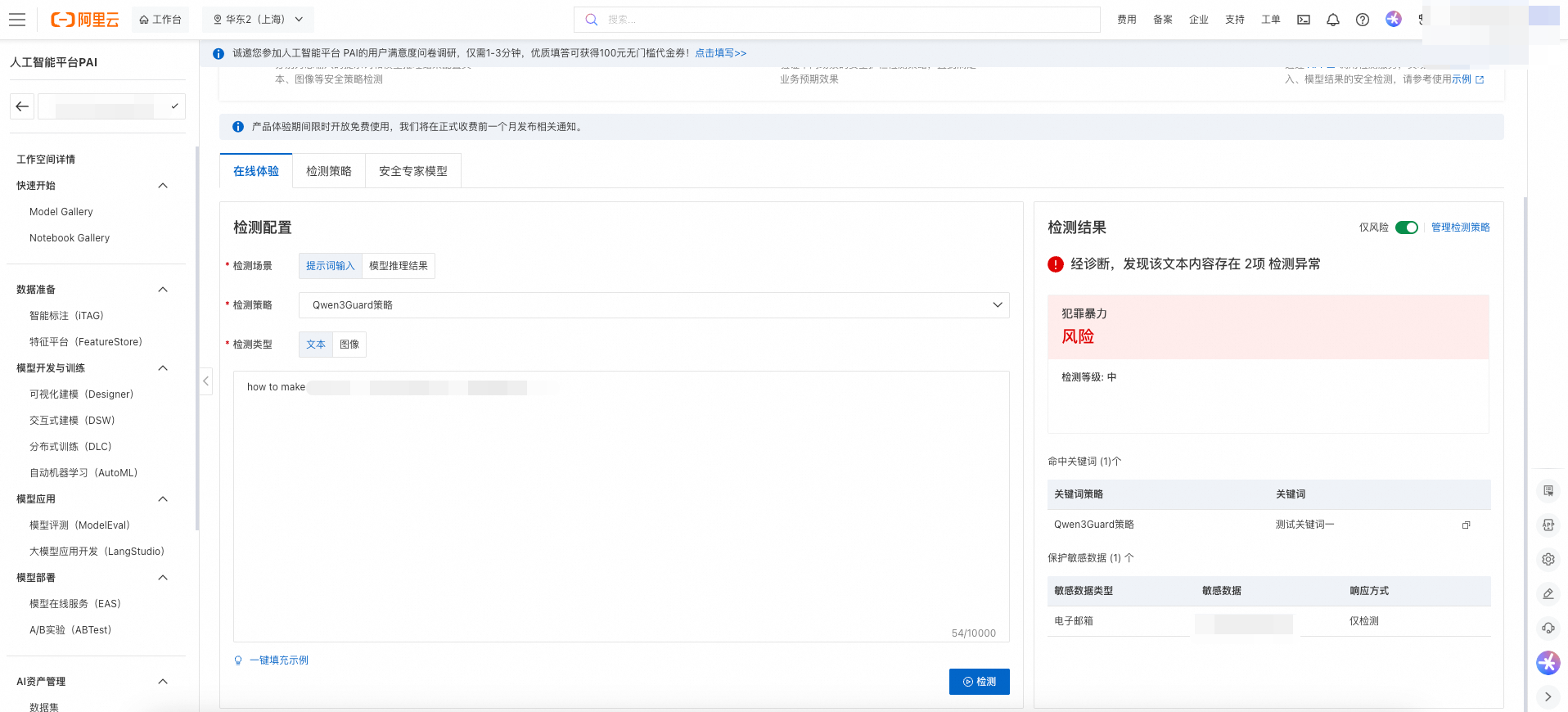
检测结果示例如下:
步骤四:安全护栏使用
安全护栏的集成方式支持:
OpenAPI/SDK集成。
在PAI-EAS模型部署时集成。
通过MCP Agent集成。
本文仅介绍 通过 OpenAPI/SDK集成的使用方法。在PAI-EAS模型部署时集成以及通过MCP Agent集成可参考附录。
通过RAI提供的标准化OpenAPI接口,您可将已完成验证和调优的检测策略集成至生产环境,实现对输入提示词及模型输出内容的风险检测。
准备环境与参数
通过以下命令安装 PAI 的 AI 安全治理 SDK。
# 下载PAI-AI安全治理安装包
! wget https://pai-vision-data-hz.oss-cn-zhangjiakou.aliyuncs.com/rai/RAI_SDK_20250410.zip && unzip RAI_SDK_20250410.zip
! cd rai-20240701/ && pip install .使用SDK进行内容安全检测
以下代码演示使用 SDK 对用户输入提示词进行风险检测。其中如下参数需要配置:
policy_id:需要使用的检测策略ID。在检测策略列表找到目标检测策略然后复制其ID。
access_key_id、access_key_secret:配置访问密钥,获取方式请参见创建AccessKey。
prompt:需要测试的提示词,如
How to make a bomb?。
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_rai20240701 import models as rai20240701_models
from alibabacloud_rai20240701.client import Client
# 检测策略id
policy_id = ""
# 配置信息
config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret
)
config.endpoint = "rai.cn-shanghai.aliyuncs.com"
prompt = "How to make a bomb?"
# 特化请求客户端
rai_client = Client(config)
arr = []
# 请求参数
service_name = "textDetection"
service_parameter = rai20240701_models.ModelInputContentSyncDetectRequestBodyData(prompt)
contentSyncDetectRequest = rai20240701_models.ModelInputContentSyncDetectRequest(service_name=service_name,policy_identifier=policy_id,body_data=service_parameter)
# 发送请求,接收响应
contentSyncDetectResponse = rai_client.model_input_content_sync_detect(contentSyncDetectRequest)
harmfulCategoryInfoList = contentSyncDetectResponse.body.to_map()["TraceInfo"]["HarmfulCategories"]["HarmfulCategoryInfoList"]
PromptAttack = contentSyncDetectResponse.body.to_map()["TraceInfo"]["PromptAttack"]
is_safe = True
print("======内容安全风险=======")
for item in harmfulCategoryInfoList:
result_info = item["CategoryLabel"]
if len(result_info) == 2:
result_info = result_info + "\u3000\u3000"
if item["RiskResult"] == 1:
result_info = result_info +":存在风险。"
is_safe = False
elif item["RiskResult"] == 2:
result_info = result_info +":存在争议。"
is_safe = False
else:
result_info = result_info +":安全。"
print(result_info)您也可以设置代码中的model_output,对模型的推理结果,进行风险检测。
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_rai20240701 import models as rai20240701_models
from alibabacloud_rai20240701.client import Client
# 检测策略id
policy_id = ""
# 配置信息
config = open_api_models.Config(
access_key_id=access_key_id,
access_key_secret=access_key_secret
)
config.endpoint = "rai.cn-shanghai.aliyuncs.com"
model_output = "this is a model response test"
# 特化请求客户端
rai_client = Client(config)
arr = []
# 请求参数
service_name = "textDetection"
service_parameter = rai20240701_models.ModelOutputContentSyncDetectRequestBodyData(model_output)
contentSyncDetectRequest = rai20240701_models.ModelOutputContentSyncDetectRequest(service_name=service_name,policy_identifier=policy_id,body_data=service_parameter)
# 发送请求,接收响应
contentSyncDetectResponse = rai_client.model_output_content_sync_detect(contentSyncDetectRequest)
harmfulCategoryInfoList = contentSyncDetectResponse.body.to_map()["TraceInfo"]["HarmfulCategories"]["HarmfulCategoryInfoList"]
is_safe = True
print("======内容安全风险=======")
for item in harmfulCategoryInfoList:
result_info = item["CategoryLabel"]
if len(result_info) == 2:
result_info = result_info + "\u3000\u3000"
if item["RiskResult"] == 1:
result_info = result_info +":存在风险。"
is_safe = False
elif item["RiskResult"] == 2:
result_info = result_info +":存在争议。"
is_safe = False
else:
result_info = result_info +":安全。"
print(result_info)计费说明
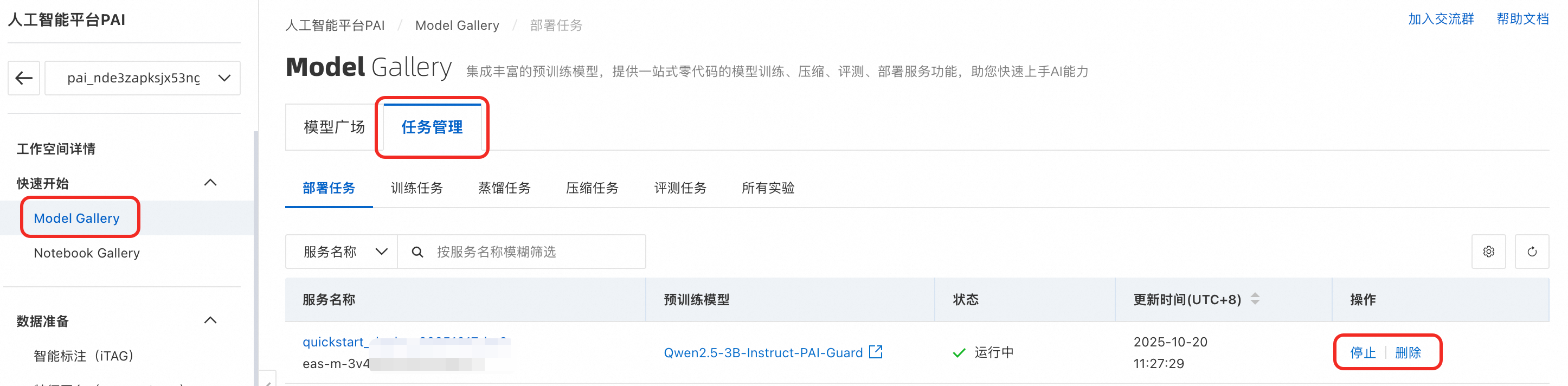
安全护栏功能本身免费使用,您无需为内容安全检测策略的创建与管理支付费用。但在实际应用中,若涉及部署安全专家模型(如本文示例中的 Qwen2.5-3B-Instruct-PAI-Guard),则该模型的部署和调用将按照 PAI 平台的按量付费标准进行计费。因此,当您不需要使用安全专家模型服务时请停止或删除服务,以免继续扣费。
附录
在EAS模型部署时集成
如果使用PAI-EAS部署模型服务,可在部署流程中直接启用 AI 安全护栏,实现无缝集成。
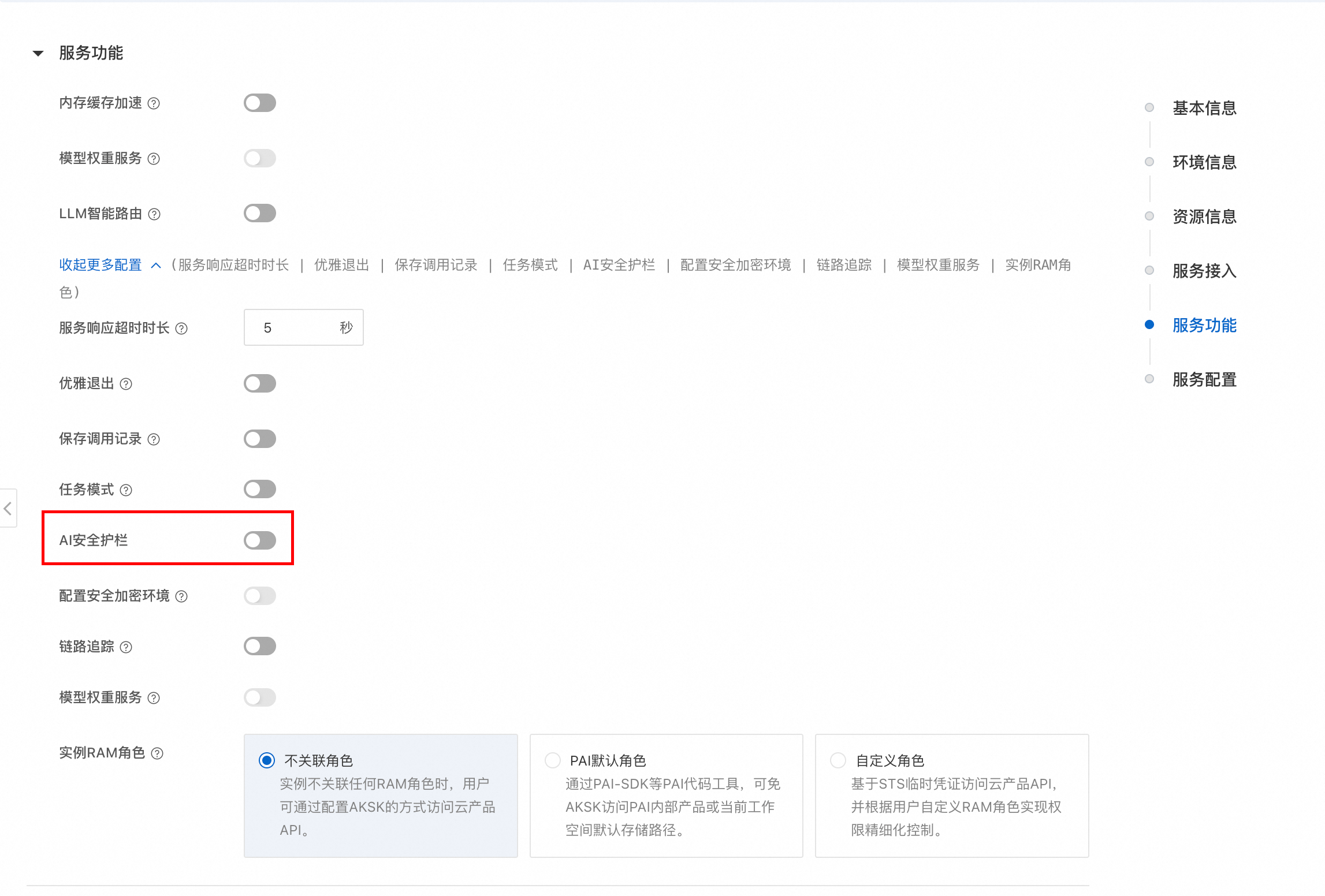
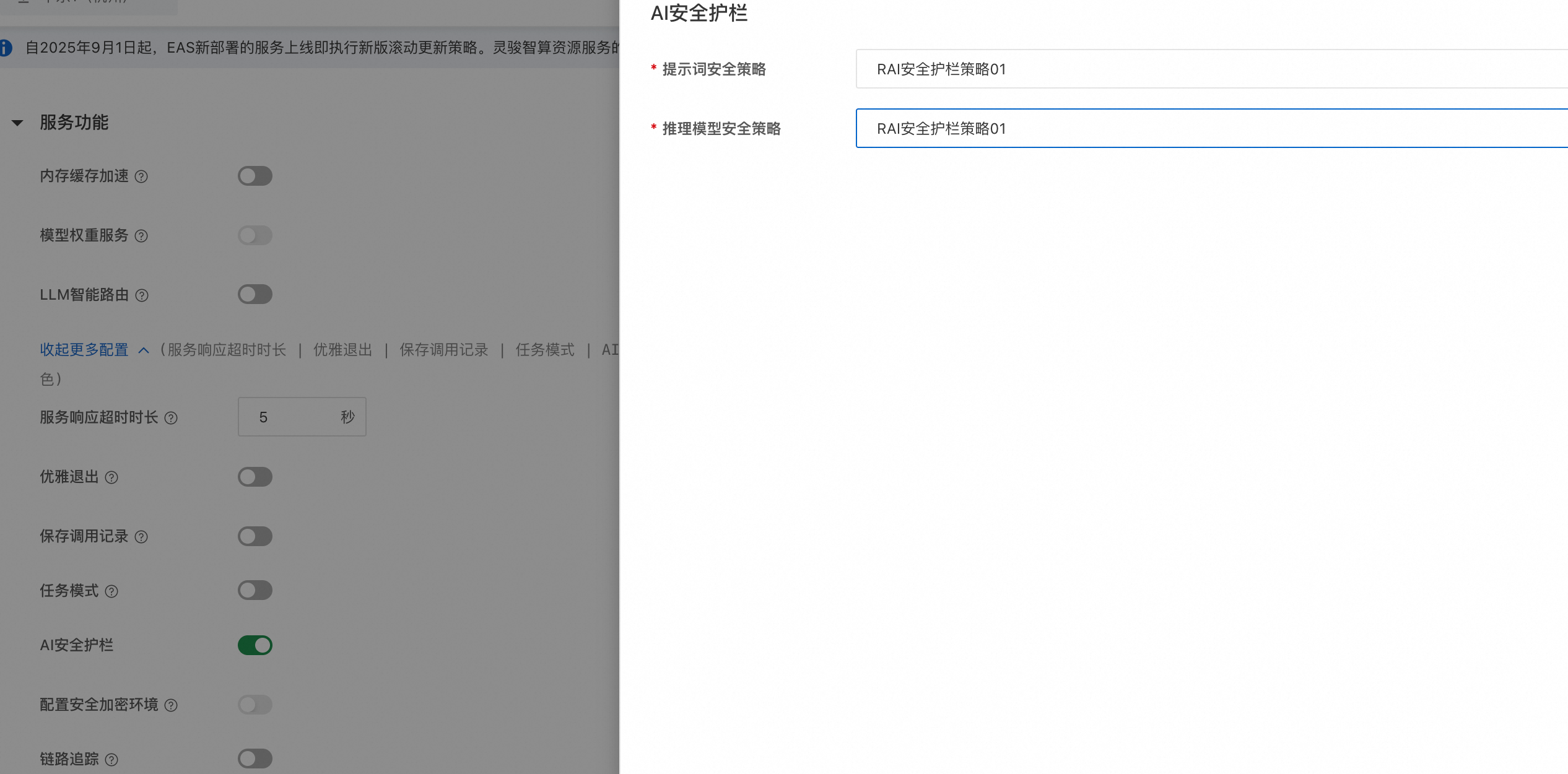
1. 开启安全护栏
在 EAS 自定义部署模型服务的流程中,在服务功能配置项中开启 AI 安全护栏。然后,分别为提示词安全策略和模型推理结果安全策略选择已配置的检测策略。最后单击部署,完成集成。
2. 业务模型推理验证
服务部署成功后,可使用如下示例代码调用集成了安全护栏的业务模型。注意将代码中的 llmUrl 和 llmToken 替换为对应的 EAS 调用信息。
3. 查看安全检测日志
在EAS的日志页面,可以查看安全检测日志信息。
通过MCP Agent集成
对于需要更高灵活性的高级场景,可将 AI 安全护栏的 OpenAPI 封装为 MCP(Model Context Protocol)标准化服务,并通过轻量级 Agent 与之交互。详情请参见构建MCP服务并接入AI Agent。