
本文介绍 LangStudio 视频知识库解决方案,通过高精度 ASR 转录、语义切片、多模态向量检索与大模型问答的深度协同,实现知识型视频的智能问答与精准定位。
一、方案概述
1.1 背景
知识型视频(如在线课程、学术讲座、技术培训等)以系统化传递知识为核心,通常具有内容密度高、语音主导、时长较长(常超30分钟)等特点。用户在长视频中定位特定知识点面临四大核心挑战:
导航缺失:缺乏细粒度目录,用户只能手动拖拽进度条低效查找。
检索浅层:现有搜索仅限标题/简介,无法深入视频内容进行语义检索与精准定位。
闭环断裂:问答结果缺乏视频片段回溯,用户难以验证与深化理解。
工程瓶颈:大模型受上下文窗口限制,机械拆分视频易割裂语义,损害问答准确性。
LangStudio 视频知识库通过 高精度 ASR 转录、语义切片、多模态向量检索与大模型问答的深度协同,实现“提问即定位,答案可回溯”,构建“看 → 问 → 定 → 懂”的完整知识获取闭环。
1.2 适用场景
应用场景 | 核心价值 | 视频类型 |
教育培训 | 精准定位知识点并支持问答 | 在线课程、公开课、学术讲座录像 |
企业知识 | 提取会议/培训中的关键信息 | 内部培训、技术分享会、会议录像 |
医疗专业 | 快速定位关键操作与诊疗讲解 | 手术教学、病例分析录像 |
媒体创作 | 按语义高效检索复用素材 | 纪录片素材库、专题节目制作 |
智驾 / 安防 | 精准检索特定事件或目标片段 | 行车记录仪、监控录像 |
工业制造 | 提取故障处理与标准化操作指导 | 设备维修、操作示范录像 |
法律政务 | 定位关键证词与政策解读 | 庭审录像、政策宣讲视频 |
二、核心技术架构
2.1 架构图
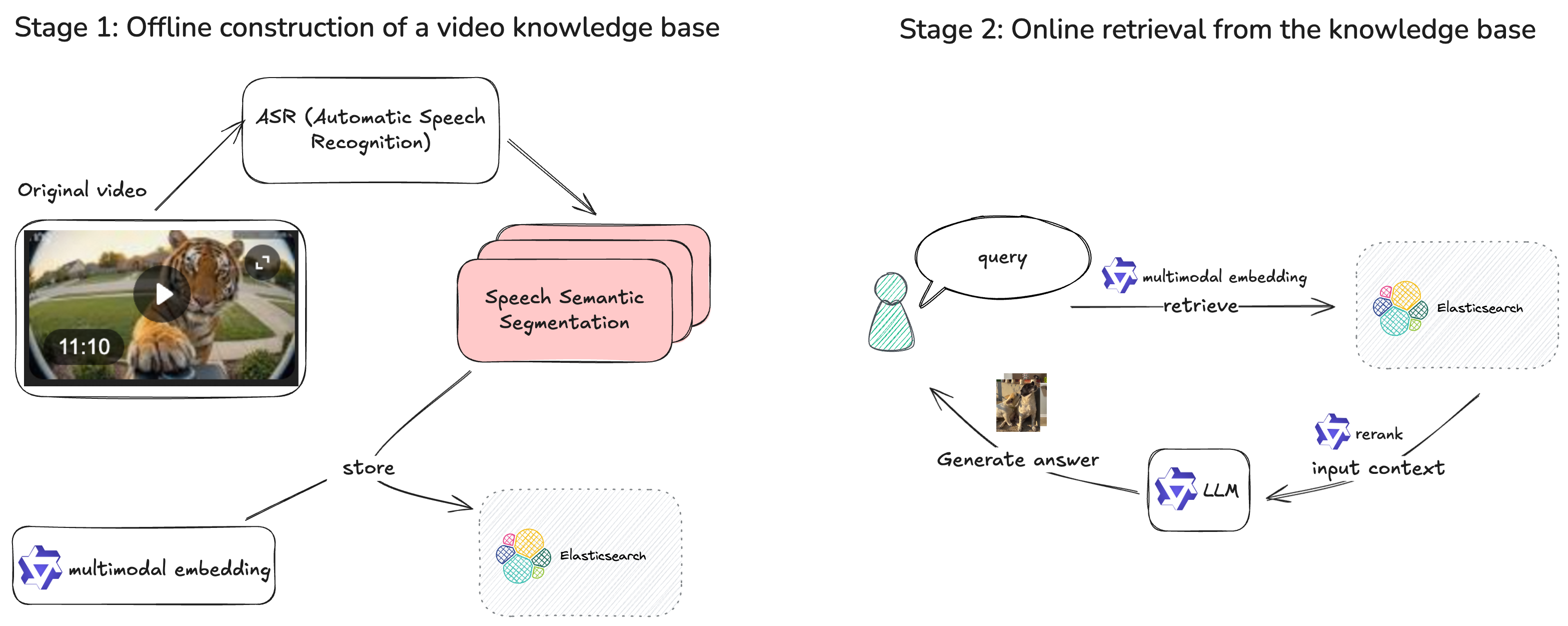
2.2 方案优势
ASR 更准:高精度多语种语音转录
基于 QWEN3-ASR 语音识别模型,支持多语种识别
提供稳定、高质量的语音转文字能力
检索更精:语义 + 关键词混合检索
多模态 Embedding:支持 DashScope 多模态 Embedding 及 PAI-EAS 自定义服务,生成高质量语义向量
混合检索:默认开启 Dense + BM25 Sparse 双路检索,支持 RRF (Reciprocal Rank Fusion)与加权融合排序,兼顾语义相似性和关键词匹配
多存储引擎:支持 Elasticsearch 和 Milvus 两种向量存储后端,可根据业务规模灵活选择
问答更优:Rerank 重排 + Query Rewrite 改写
Rerank 重排:对召回的视频片段进行二次重排,确保 Top-K 结果与用户意图高度匹配。支持 DashScope 、PAI-EAS 及阿里云 OpenSearch AI 搜索开放平台等多种来源的Rerank模型
Query Rewrite 改写:基于多轮对话上下文,将模糊、指代性或省略性提问改写为完整检索查询(如将"怎么到那里?"改写为"怎么到撒哈拉沙漠?"),解决上下文丢失问题
相似度阈值过滤:支持配置相似度阈值,自动过滤低相关性片段,避免噪声内容影响回答质量
溯源更准:时间戳级精准定位
每个切片携带精确时间元数据(
chunk_start、chunk_end、chunk_seq),检索结果可直接关联到具体时间区间一键跳转到对应讲解片段,实现"提问 → 检索 → 定位 → 回看"的完整闭环,降低知识验证成本
三、使用指南
3.1 创建知识库 & 上传视频文件
创建视频类型的知识库。关键参数配置如下,其他参见知识库管理。
知识库类型:选择视频。
切分方式:建议选择语音语义切片,会对视频语音进行 ASR,提取为切片文本内容。
说明默认切片仅根据视频内容切片,忽略语音内容。
导入文档。进入知识库,切换到视频页签,单击上传。支持从本地上传视频到知识库的数据源 OSS 路径。
切换画廊视图/表格视图查看数据源 OSS 目录里的视频源信息。
3.2 更新文件索引 & 查看处理结果
上传完数据后单击更新索引,配置更新索引任务的计算资源和专有网络。
说明请确保选择的VPC网络与知识库的Embedding服务和向量数据库服务的VPC网络连通,建议使用相同的VPC以简化配置。
单击操作记录查看索引任务的执行详情。
单击目标任务操作列的查看任务,查看工作流任务日志中的Job URL(跳转查看索引更新的 DLC 任务)。
若任务失败,在 DLC 任务日志中定位具体的报错原因。
更新成功后单击查看任务结果,可以看到本次任务的更新文档/chunk 统计。
知识库索引更新成功后,视频文件状态从【未索引】更新为【已索引】。单击具体视频文件,可查看视频切片和转录文稿。单击视频切片,可启用或屏蔽该切片在检索中的生效状态。
3.3 元数据管理 & 索引自动更新
元数据管理
视频文档的元数据可作为检索时的过滤条件或排序依据,通过元数据过滤,可排除不相关的文档,避免将无关内容引入生成模型。
编辑自定义元数据。元数据分为自定义 / 系统预置两种类型。
在知识库概览页面的元数据区域可以看到自定义元数据的类型/引用次数/值的个数。
单击 编辑,可以添加/删除自定义元数据。
为视频切片打标。进入具体的视频文件,单击编辑元数据,对该视频的所有切片进行元数据打标。后续可以在知识库检索时添加上指定元数据标签的条件过滤,直接定位到最相关的视频切片。
索引自动更新
进入知识库详情页,在文件索引自动更新区域单击编辑,配置自动更新任务的计算资源和专有网络,需与索引更新任务保持一致。
启动自动更新后,系统会自动在事件总线创建事件规则并转发OSS文件变更消息,从而自动创建索引任务。
说明配置生效存在分钟级的延迟,请等待3分钟之后再操作OSS文件。
3.4 切片召回测试
在知识库召回测试页面,提出需要检索的问题,系统会返回与问题最相关的若干个文本片段。
左侧检索设置里可以配置本次召回测试的参数情况,通常选择检索模式为混合检索,并开启结果重排。
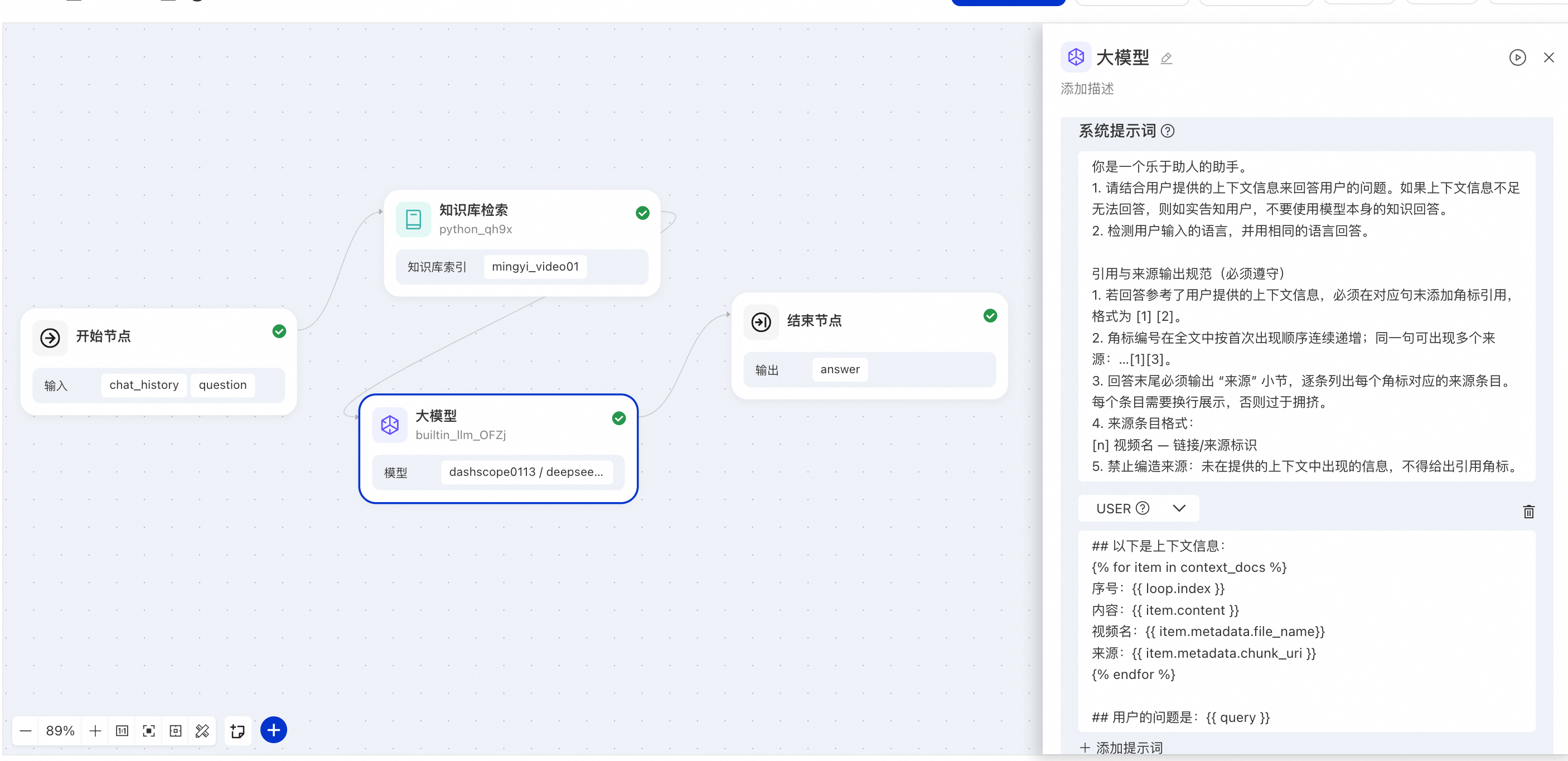
3.5 搭建视频智能问答工作流
示例工作流
开始节点 -> 知识库检索 -> 大模型 -> 结束节点
应用示例
场景 1:教学长视频知识点问答
问题: 请问C语言中,运算符的优先级是怎样的呢?
结果:将返回该概念在教学视频中的完整定义说明,并给出对应的视频切片信息。
场景 2:基于科普视频的问题对抽取
该能力在科普/教培/学习等场景中可用于快速出题、知识点复习及学生自检学习效果,显著提升教学与学习效率。
节点配置:在知识库检索节点中使用元数据file_name 指定教学视频。
问题:帮我从视频中总结出常见 Q&A 对
结果:将基于视频内容生成有价值的问题及答案,并关联相应的视频切片,便于回溯与理解。
场景 3:视频关键结论问答 & 整体总结
知识问答将基于视频内容提炼相关结论与拆分项,明确区分视频内容区间,并关联对应的视频切片。扩展到会议/讨论/复盘等场景,可以确认会议细节与行动项/待办项,明确各人员责任分工等。
节点配置:在知识库检索节点中使用元数据的自定义标签class 指定视频类型。
问题:运算符和变量之间的关系是什么
结果:可跨视频文件总结。