
简介
在大模型训练场景中,为提升模型的精确度和性能,常需要引入第三方高质量数据进行联合训练。此类训练数据往往包含敏感信息,若处理不当,易引发数据泄露等合规与业务风险。
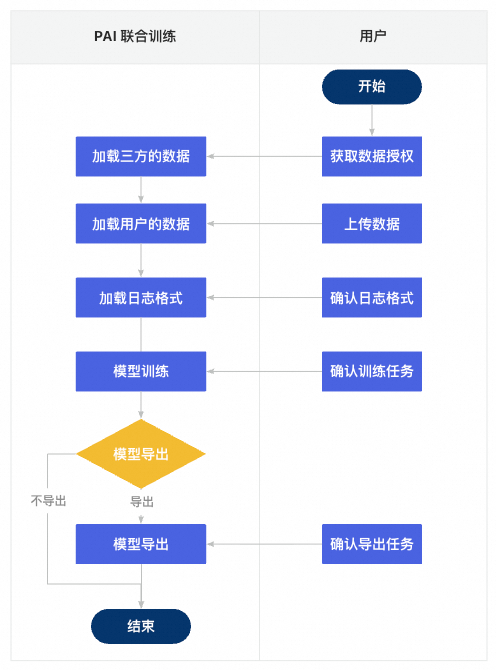
因此,PAI 平台提供了安全合规的联合训练机制,确保在不暴露原始数据的前提下使用,实现“数据可用不可见、价值可共享不可复制”的核心目标。其核心安全机制包括:
-
跨账号授权:数据提供者通过阿里云跨账号授权机制,将训练数据授权给模型训练者。训练数据仅限在 PAI-DLC 提供的受控沙盒环境中使用,模型训练者无法访问、下载或查看未被授权的训练数据。
-
训练数据过滤:对训练过程中生成的日志数据进行严格过滤,防止训练数据通过日志泄露。
-
模型导出安全扫描:在模型可导出的场景中,对待导出的模型文件进行安全扫描,检测并阻断模型中可能残留的训练数据,防止训练数据泄露。
前提条件
请联系您的商务经理完成以下准备工作:
-
授权使用第三方训练数据:提供云账号UID、PAI工作空间ID、数据使用期限和次数。
-
提供原始训练模型的信息:提供模型的基本信息(如模型结构概述、关键性能指标等),以便我们适配相应的模型安全扫描策略。
-
确认日志输出格式:提供模型训练日志的基本信息(如训练框架等),以便我们适配相应的训练日志输出规则。
使用流程
步骤一:提交训练作业
-
查看数据提供者分享的数据集。登录PAI 控制台,在左上角选择目标地域和工作空间,在左侧导航栏选择AI资产管理 > 数据集,在列表中确认数据提供者分享的数据集是否可见。
-
创建DLC任务。在左侧导航栏选择模型开发与训练 > 分布式训练(DLC),然后单击新建任务。
-
配置DLC任务参数。关键参数配置如下,其他参数如:作业名称、镜像及资源按需配置即可。
-
数据集挂载:添加自定义数据集,选择跨账号分享的数据集和自己的数据集。所有选中的数据集都需要打开只读模式,否则提交作业时会报错。
-
模型名称:必填。该名称将用于本次作业训练的模型子目录,以及训练结束后注册到模型中心的模型名称。
在数据集挂载区域,挂载跨账号分享的数据集时需开启是否只读开关;挂载自有数据集时,同样建议开启只读模式。挂载了跨账号分享的数据集后,模型名称为必填项。
参数配置完成后,单击确定创建任务。
-
-
查看作业详情及训练日志。
提交作业后查看作业详情。
作业详情页的概览Tab展示以下信息:顶部时间线呈现任务各阶段(任务创建、排队、环境准备、任务运行、任务停止)及对应耗时;基本信息区显示任务名称和ID;环境信息区显示节点镜像、数据集挂载、模型配置、执行命令和环境变量;资源信息区显示资源类型(灵骏智算)、资源配额、框架(PyTorch)、优先级以及Worker节点的数量、GPU、CPU、内存配置;网络信息区显示专有网络配置、安全组和交换机。
查看训练日志内容。
在任务详情页面,顶部进度条展示任务生命周期各阶段(任务创建→排队→环境准备→任务运行→任务成功),并标注各阶段耗时与时间戳。单击日志页签,在用户日志中可查看训练配置参数(如
world_size=8、weight_decay=0.01、v_head_dim=128等)及训练迭代进度(如iteration 1/30、每迭代耗时、吞吐量、checkpoint 保存记录和 validation loss)。左下方实例列表显示实例状态为已成功。
步骤二:扫描&导出模型
训练成功后,PAI平台会自动在模型中心注册一个模型,模型名称为提交作业时填写的模型名称。
-
在 PAI 控制台左侧导航栏,选择AI资产管理 > 模型,在模型列表中找到在作业中填写的模型名称命名的模型。
-
点击模型,进入模型详情。
模型详情页面展示模型基本信息,包括模型名称、模型ID、最新版本、创建时间、版本数量、可见范围及模型描述。标签区域显示
PAIExportModelEnabled : true,表示模型已启用导出功能。下方模型版本列表展示各版本的版本号、创建时间、版本来源、模型地址和准入状态(如待定(Pending)),操作列提供详情、部署至EAS、导出、删除等入口。页面右上角提供新增版本、查看导出、公开模型、删除按钮。 -
单击导出,填写输出配置,资源配置和超参数配置,完成模型导出。
-
model_file:需要导出的模型文件目录。
-
model_name:模型文件类型。
资源配置中,资源类型选择灵骏智算,资源来源选择资源配额,资源配额选择灵骏智算-shared。任务资源需填写节点数量、GPU(卡数)、CPU(核数)、内存(GiB)、共享内存(GiB)。超参数中model_file填写为
/workspace/Qwen3-VL-2B-Instruct,model_name填写为Qwen3-VL-2B-Instruct,完成后单击导出。 -